大数据学习笔记之项目(二):离线平台部署
文章目录
- 离线平台部署
- 项目开发流程
- 项目调研
- 项目需求分析
- 1.3、方案设计
- 1.3.1、概要设计
- 1.3.2、详细设计
- 编码实现
- 1.4.1、单元测试
- 1.4.2、集成测试
- 1.4.3、压力测试
- 1.4.4、用户测试
- 二、大数据常用应用
- 2.1、数据出售
- 2.2、数据分析
- 2.2.1、百度统计
- 2.2.2、友盟
- 2.2.3、其他统计分析组织
- 2.3、搜索引擎
- 2.3.1、solr
- 2.3.2、luence
- 2.3.3、luence & solr对比
- 2.4、推荐系统
- 2.4.1、技术
- 2.4.2、算法
- 2.5、精准营销
- 2.5.1、广告推送流程简述
- 2.5.2、涉及技术点
- 2.6、数据预测
- 2.7、人工智能
- 2.8、用户画像
- 三、大数据分析平台
- 3.1、离线大数据分析平台
- 3.2、实时大数据分析平台
- 四、大数据业务处理方式
- 4.1、使用第三方产品
- 4.1.1、优势
- 4.1.2、劣势
- 4.2、自己研发大数据平台
- 4.2.1、优势
- 4.2.2、劣势
- 五、数据分析平台数据来源
- 5.1、服务器日志
- 5.2、业务日志
- 5.3、用户行为数据
- 5.4、购买第三方数据
- 5.5、网络爬虫数据
- 六、数据处理的流程
- 6.1、数据收集
- 6.2、数据处理
- 6.3、数据结果可视化
- 6.3.1、Zeppelin
- 6.3.2、Datawei
- 6.3.3、Echarts
- 6.3.4、HighCharts
- 6.4、数据结果应用
- 6.4.1、用户画像
- 七、项目集群规模
- 7.1、数据量级
- 7.2、集群规模
- 7.3、Job运行时间
- 八、需求分析
- 8.1、目标
- 8.2、核心关注
- 8.2.1、购买率
- 8.2.2、复购率
- 8.2.3、订单数量&订单金额&订单类型情况
- 8.2.4、成功订单数量&成功订单金额&成功订单类型情况
- 8.2.5、退款订单数量&退款订单金额&退款订单类型情况
- 8.2.6、访客/会员数量
- 8.2.7、访客转会员比率
- 8.2.8、广告推广效果
- 8.2.9、网站内容(跳出率等)
- 8.3、概念理解
- 8.3.1、用户/访客
- 8.3.2、会员
- 8.3.3、会话
- 8.3.4、跳出率
- 8.3.5、外链
- 8.3.6、Page View
- 8.3.7、Unique Visitor
- 8.3.8、Page Depth
- 8.3.9、维度(Dimensionality)
- 8.3.10、分析指标:
- 8.3.11、模块分析
- 九、技术架构
- 9.1、数据收集层
- 9.2、数据处理层
- 9.3、数据结果可视化层
- 在这里插入图片描述 十、技术选型
- 10.1、Hadoop
- 10.2、组件服务
- 10.2.1、Hadoop 1.x
- 10.2.2、Hadoop 2.x
- 10.2、HDFS
- 10.2.1、特点
- 10.2.2、常见面试题
- 10.3、YARN
- 10.3.1、特点
- 10.3.2、常见面试题
- 10.4、MapReduce
- 10.4.1、特点
- 10.4.2、常见面试题
- 10.5、HBase
- 10.5.1、特点
- 10.5.2、常见面试题
- 10.6、Hive
- 10.6.1、特点
- 10.6.2、常见面试题
- 10.7、Flume
- 10.7.1、特点
- 10.7.2、常用操作
- 10.8、Oozie
- 10.9、Sqoop
- 10.10、Zookeeper
- 十一、Nginx
- 11.1、介绍
- 11.2、常见其他Web服务器
- 11.3、版本
- 11.4、Nginx安装
- \$ mkdir /opt/modules/nginx
- \# wget http://tengine.taobao.org/download/tengine-2.0.2.tar.gz
- \$ tar -zxf tengine-2.0.2.tar.gz /opt/modules/nginx
- \# yum -y install gcc openssl-devel zlib-devel pcre-devel
- 11.5、目录结构
- 11.6、操作命令
- 十二、Mysql
- 12.1、介绍
- 12.2、关系型数据库(SQL)种类
- 12.3、特征
- 12.4、术语
- 12.4、与非关系型数据库比较(Not Only SQL)
- 12.4.1、种类
- 12.4.2、特征
- 12.4.3、总结
- 十三、数据收集
- 13.1、收集方式
- 13.2、数据的事件类型
- 13.2.1、Launch事件
- 13.2.2、PageView事件
- 13.2.3、Event事件
- 13.2.4、ChargeRequest事件
- 13.2.5、ChargeSuccess事件
- 13.2.6、ChargeRefund事件
- 13.3、Nginx日志收集服务器
- 13.3.1、字段信息
- 13.3.2、Nginx日志格式
- 13.3.3、Nginx配置
- 13.4、Flume数据采集
- 13.4.1、编写Flume脚本上传日志文件到HDFS
- 13.4.2、将core-site.xml和hdfs-site.xml文件软连接到flume的conf文件夹中
- 13.5、启动采集测试
- 十四、工程JS/JAVA SDK讲解
- 十五、Flume故障之手动上传数据
- 15.1、分割Nginx日志,按天保存
- 15.1.1、脚本编写
- 15.1.2、其他环境准备
- 15.1.2、定时任务
- 15.2、手动上传Nginx日志
- 15.2.1、脚本编写
- 15.2.2、测试脚本
- 十六、数据处理
- 16.1、ETL操作
- 16.2、HBase设计
- 16.2.1、每天1张表
- 16.2.2、倒叙或在前缀上加数字
- 16.2.3、预分区
- 16.3、MapReduce分析过程
- 16.4、Hive分析
- 16.5、Mysql表结构设计
- 16.5.1、常用关系型数据库表模型
- 16.5.2、表结构
- 数据处理的数据准备
- 十七、工具代码导入
- 十八、业务ETL实现
- 18.1、功能
- 18.2、数据
- 18.2.1、上传方式
- 18.2.2、流程
- 18.2.3、细节分析
- 18.3、代码实现
- 18.3.1、日志解析
- 18.3.2、IP地址解析补全
- 18.3.3、浏览器信息解析
- 18.3.4、ETL代码编写
- 18.4、测试
- 18.4.1、上传测试数据
- 18.4.2、打包集群运行
- 十九、创建数据库表
- 19.1、使用Navicat工具
- 19.2、通过SQL文件构件表(详细见操作)
- 二十、业务数据分析
- 20.1、统计表
- 在这里插入图片描述 20.2、目标
- 20.3、代码实现
- 20.3.1、Mapper
- 20.3.2、Reducer
- 20.3.3、Runner
- 20.3.4、测试:NewInstvavallUsers
- 二十一、Hive之Hourly分析
- 21.1、目标
- 21.2、目标解析
- 21.3、创建Mysql结果表
- 21.4、Hive分析
- 21.4.1、创建Hive外部表关联HBase数据表
- 21.4.2、创建临时表用于存放pageview和launch事件的数据(即存放过滤数据)
- 21.4.3、提取e\_pv和e\_l事件数据到临时表中
- 21.4.4、创建分析结果临时保存表
- 21.4.5、分析活跃访客数
- 21.4.6、分析会话长度
- 21.4.7、创建最终结果表
- 21.4.8、向结果表中插入数据
- 21.4.9、使用Sqoop导出 数据到Mysql,观察数据
- 通过jdbc直接写入到mysql中
- 项目总体分析
- 自定义OutputFormat
- End、备注
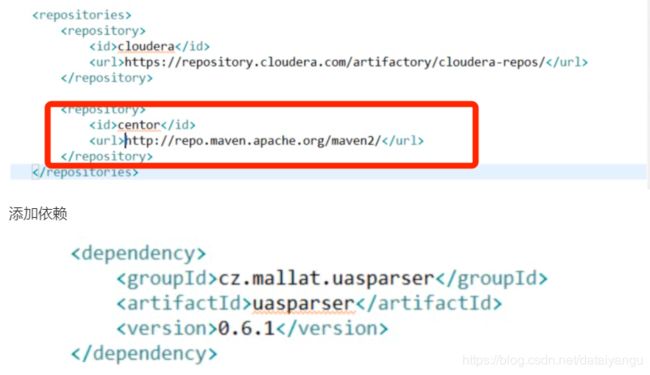
- 常用Maven仓库地址
离线平台部署
先看项目总体分析
-
项目开发流程
-
项目调研
-
了解项目的初始需求,以及完成该需求可能涉及到的市面上的常用的技术。
项目需求分析
明确项目到底需要做什么,以及最终做成什么样子,需求分析不明确,项目周期就不明朗,项目完成度无法把控,技术分控无法实现,而且也无法了解项目发展的主体方向。其中最令程序员头痛的是,需求在某个开发周期中,不停的频繁变更。项目完成效率降低。
1.3、方案设计
1.3.1、概要设计
从整体上进行技术框架的设计,比如容错,框架延展性,扩容,安全性等等。
1.3.2、详细设计
按照功能模块进行具体的设计,比如HBase,关系型数据库等表结构设计,数据字典设计,接口设计等等。
编码实现
项目的整体布局结束之后,即可对项目中的小功能模块开始编码细节。
1.4.1、单元测试
指对软件中的最小可测试单元进行检查和验证,一般使用工具Junit。
1.4.2、集成测试
集成测试,也叫组装测试或联合测试。在单元测试的基础上,将所有模块按照设计要求组装成为子系统或系统,进行集成测试。
1.4.3、压力测试
也称为强度测试、负载测试。压力测试是模拟实际应用的软硬件环境及用户使用过程的系统负荷,长时间或超大负荷地运行测试软件,来测试被测系统的性能、可靠性、稳定性等。
1.4.4、用户测试
用户体验测试顾名思义就是测试人员在将产品交付客户之前处于用户角度进行的一系列体验使用,如:界面是否友好(吸引用户眼球,给其眼前一亮)、操作是否流畅、功能是否达到用户使用要求等。
二、大数据常用应用
2.1、数据出售
这些公司一般主要以买卖数据为主要收入来源,爬虫是获取数据的主要来源,最终以HDFS存储。
2.2、数据分析
2.2.1、百度统计
[https://tongji.baidu.com/web/welcome/login]{.underline}
2.2.2、友盟
[https://www.umeng.com/]{.underline}
2.2.3、其他统计分析组织
GA(Google Analysis)
IBM analysis
2.3、搜索引擎
2.3.1、solr
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http
Get操作提出查找请求,并得到XML格式的返回结果。
2.3.2、luence
Lucene是一套用于全文检索和搜寻的开源程式库,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
2.3.3、luence & solr对比
*
Lucene是一套信息检索工具包,但并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此在使用Lucene时你仍需要关注搜索引擎系统,例如数据获取、解析、分词等方面的东西。*
而Solr是基于Lucene做的,的目标是打造一款企业级的搜索引擎系统,因此它更接近于我们认识到的搜索引擎系统,它是一个搜索引擎服务,通过各种API可以让你的应用使用搜索服务,而不需要将搜索逻辑耦合在应用中。而且Solr可以根据配置文件定义数据解析的方式,更像是一个搜索框架,它也支持主从、热换库等操作。还添加了飘红、facet等搜索引擎常见功能的支持。总结:
*
Lucene使用上更加灵活,但是你需要自己处理搜素引擎系统架构,以及其他附加附加功能的实现
*
Solr帮你做了更多,但是是一个处于高层的框架,Lucene很多新特性不能及时向上透传,所以有时候可能发现需要一个功能,Lucene是支持的,但是Solr上已经看不到相关接口。
2.4、推荐系统
2.4.1、技术
* Mahout
* Spark Mlib
2.4.2、算法
* Logistic Regression
* Bayesian
* SVM
* Random Forests
* K-means Clustering
* Fuzzy K-means等等
2.5、精准营销
2.5.1、广告推送流程简述
* 访问者访问页面
* JS 收集用户数据并发送给广告联盟
* 广告联盟将广告位发送给广告公司
*
广告公司根据用户数据决定是否报价(即决定是否出价购买这个广告位以及报价预算)
* 广告公司联盟选择一个最高的报价
* 广告展示
* 用户点击广告
* 发送一个点击的行为数据给广告联盟
* 广告联盟通知广告公司(中标的公司)
* 广告公司保存用户点击的数据
* 生成模型
2.5.2、涉及技术点
* HDFS
* 用户模型生成(R,Python,Spark Mlib,Mahout)
2.6、数据预测
2.6.1、天气预测
[http://typhoon.weather.gov.cn/web.html]{.underline}
2.6.2、路况预测
[http://map.baidu.com/]{.underline}
2.6.3、城市发展预测
2.7、人工智能
2.8、用户画像
三、大数据分析平台
主要用于分析处理收集得到的数据,根据最终的分析结果产生业务支持、进行业务调整等等。
3.1、离线大数据分析平台
对分析结果的时效性要求比较低,业务场景不要求很快,很及时的数据反馈,对机器的性能要求比较低,成本稍低。
可能会用到的技术:MapReduce,Hive,Pig,SparkCore(Spark on Yarn)等
3.2、实时大数据分析平台
是反馈的延迟要求很严格,一般都要求在毫秒,最多到秒级,对机器的性能要求会稍高一些,成本略高。
可能会用到的技术:Spark Streaming,Storm等
四、大数据业务处理方式
4.1、使用第三方产品
4.1.1、优势
简单,开发成本小
4.1.2、劣势
* 灵活度低
* 第三方收费比较高
* 己方公司对数据操作的权限高,后期很难根据数据进行处理,例如功能添加等
4.2、自己研发大数据平台
4.2.1、优势
* 数据在自己手里,安全度高,灵活度高
* 开发更自由,更方便
4.2.2、劣势
* 开发延迟相对较高
* 公司前期成本会比较大
* 人员招聘需要耗时,略有风险
五、数据分析平台数据来源
5.1、服务器日志
包括常用的例如nginx日志,apache日志,服务器系统日志等,一遍用于辅助运维工程师。
5.2、业务日志
包括log4j的日志,用于节点异常排查,业务异常排查,debug等。
5.3、用户行为数据
从前端收集到的用户操作行为的数据日志,比如浏览,点击,选择,收藏等。
5.4、购买第三方数据
5.5、网络爬虫数据
常用的爬虫技术,Java,Python爬虫,常用的第三方爬虫工具例如火车头采集器等等。
六、数据处理的流程
6.1、数据收集
数据一般最终会以压缩格式保存于HDFS之上,目前市场公司用snappy压缩较多一些。
6.2、数据处理
Extract-Transform-Load数据的清洗,过滤,转换等加工,根据指定的目标,计算数据指标的值,最终保存于数据库中SQL或者NoSQL。
6.3、数据结果可视化
展示分析数据结果
可视化框架或工具:
6.3.1、Zeppelin
[http://zeppelin.apache.org/]{.underline}
6.3.2、Datawei
[http://www.datawei.com]{.underline}
6.3.3、Echarts
[http://echarts.baidu.com/index.html]{.underline}
6.3.4、HighCharts
[https://www.highcharts.com/]{.underline}
6.4、数据结果应用
6.4.1、用户画像
简而言之,用户画像(persona
)为了让团队成员在产品设计的过程中能够抛开个人喜好,将焦点关注在目标用户的动机和行为上进行产品设计。
因为,产品经理为具体的人物做产品设计要远远优于为脑中虚构的东西做设计,也更来得容易。
* 用户画像要建立在真实的数据之上
*
当有多个用户画像的时候,需要考虑用户画像的优先级,通常建议不超过三个以上
* 用户画像是处在不断修正中的

七、项目集群规模
7.1、数据量级
每天数据量大约在500万~3000万条左右。
每个Job的数据输入一般会按照维度来划分,例如一天的数据,一周的数据,一个月的数据,甚至有时会有小时数据。Job总量大约在40个左右,自己编写的MapReduce任务大概30个左右,Hive占用一般不超过10个。
7.2、集群规模
2 (NN HA、RM HA、hive、HMaster)
10(DN、JN(5台左右)、NM、HRegionServer)
ZK(3),可以选择另开3个机器,也可以选择在上边的20~30台机器中选3台。
CPU:128核 内存:256g
NN、RM、DN、JN、NM、Hive、HMaster::1G
内存数大概:16~64G
HregionServer:16 - 24G
MR CPU/内:32-64/64-128G
网络:千兆或万兆
7.3、Job运行时间
ETL Job:一般不到10分钟就OK了,Mapper Task一般10~20个左右
MapReduce Job:每个Job任务运行时间大约是30分钟左右
Hive Job:大约30分钟左右,最终会将分析出来的结果数据Sqoop到Mysql中
并发:Oozie进行任务调度,同一时间允许的并发任务数一般为5个
定时:晚上12点开始执行,一般凌晨4~5点就能完成Job任务的运行
八、需求分析
8.1、目标
* 根据用户行为数据进行程序分析处理,得出结果保存到关系型数据库中
* 收集各个不同客户端的用户行为数据,最终保存到HDFS上
* 了解用户行为数据包含哪些字段
8.2、核心关注
8.2.1、购买率
8.2.2、复购率
8.2.3、订单数量&订单金额&订单类型情况
8.2.4、成功订单数量&成功订单金额&成功订单类型情况
8.2.5、退款订单数量&退款订单金额&退款订单类型情况
8.2.6、访客/会员数量
8.2.7、访客转会员比率
8.2.8、广告推广效果
8.2.9、网站内容(跳出率等)
8.3、概念理解
8.3.1、用户/访客
访问网站的用户,是自然人。
区分访客:
PC端:
*
采用IP地址来区分用户。由于代理、NAT等等技术,导致可能出现一种情况:多个用户对应一个ip地址
*
采用客户端种植cookie的方式,当用户第一次访问系统的时候,在cookie中种植一个唯一的uuid,过期时间设置为10年。
移动端:
* 采用手机的固定手机码识别。IMEI、MEID、S/N等等
*
采用客户端种植uuid(有时也叫作token)的方式,当用户第一次访问系统的时候,在磁盘中种植一个唯一的uuid,过期时间设置为10年。
指标:
新增访客数量:第一次访问系统的访客数量
活跃访客数量: 统计时间段内访问过系统的访客(不管是新访客、还是老访客)
总访客数量:迄今为止,新增访客数量的总和
流失访客数量:
上一个时间端访问过系统,但是当前统计时间段没有放过的访客数量
回流访客数量: 上一个时间段没有访问过,但是当前时间段访问过的访客数量。
访客分级别计算数量(新访客、活跃访客、周活跃访客…忠诚访客)
8.3.2、会员
指业务系统中的注册用户,直接使用业务系统中的会员唯一id来标识。
指标:
* 新增会员数量
* 活跃会员数量
* 总会员数量
* 流失会员数量
* 回流会员数量
* 访客转会员比率
* 新访客转会员比率
* 老访客转会员比率
8.3.3、会话
用户进入系统到离开系统的这一段时间被成为会话,这段时间的长度就叫做会话长度,一个会话中的所有操作都属于该会话。
区分会话:
PC端:
*
采用浏览器的session机制(cookie的过期时间设置为session、sessionstorage)
*
在cookie中种植上一个操作的时间,在操作的时候,进行判断时间是否过期,如果过期,重新生成会话,如果没有过期,更新cookie值。
移动端:
* 利用移动端的session机制
* 类似pc端种植上一个操作时间进行判断
指标:
* 会话数量
* 会话长度
* 跳出会话数量: 在一个会话中,只访问一次网站的会话数量
8.3.4、跳出率
离开网站的数量占进入网站数量的百分比
会话跳出率: 跳出会话数量/总会话数量
**页面跳出率:**从该页面离开后,进入不同类型的网页占进去该页面的会话总数量的百分比
* 离开系统会话数量 / 进入总会话
* 进入详情页面会话数量 / 进入总会话数量
8.3.5、外链
用户通过第三方的外部链接进入到我们的系统中,该第三方的链接称之为外链。
指标:
* 带来的会话数量
* 带来的访客数量
* 带来的订单数量
8.3.6、Page View
每次用户访问页面就计算一次,如果多次访问,就计算多次(不去重)。
8.3.7、Unique Visitor
唯一访客数量。
8.3.8、Page Depth
统计的是各个不同访问深度的访客/会话数量,它能够展示一个网站不同深度的页面的访问程度,结合跳出率可以更好的修饰一个网站的内容是否吸引人,用户体验是否到位等等。
8.3.9、维度(Dimensionality)
* 时间维度(Date):小时、天、周、月、季度、年
* 平台维度(Platform):PC端、android、ios、ipad等
* 浏览器维度(Browser):浏览器名称、浏览器版本
* 浏览器分辨率维度(Screen resolution):
* 操作系统维度(OS):操作系统名称、版本
* 地域维度(Location):国家、省份、城市
* 语言维度(Language):各个国家的语音支持
* 外链维度:百度、360、google等等
* 货币类型维度:各个国家的货币
* 支付方式维度:微信,银联,支付宝等等
* 版本维度:比如v1、v2等,一般用于多个版本之间的比较(AB测试)
8.3.10、分析指标:
维度+核心关注点+重要概念
8.3.11、模块分析
*
用户基本分析模块:分析用户/会员的基本信息,包括:新增、活跃、总、hourly分析
* 浏览器分析模块:在用户基本分析模块之上,加上浏览器维度
* 地域分析模块
* 外链分析模块
* 用户浏览深度分析模块
* 事件分析模块
* 订单分析模块
九、技术架构
9.1、数据收集层

9.2、数据处理层
9.3、数据结果可视化层

十、技术选型
10.1、Hadoop
起源于:GFS(Google FileSystem)、Map/Reduce、BigTable三篇论文。Doug
Cutting在开发Nutch爬虫的时候,网络数据量太大,从而开发出Hadoop。
10.2、组件服务
10.2.1、Hadoop 1.x
NN、DN、SNN、JT(JobTracker)、TaskTracker
存在的问题:
* NN单节点问题
* NN扩容问题
* JT管理资源以及任务调度监控对CPU压力比较大
* JT单节点
* 对于机器资源利用率低
10.2.2、Hadoop 2.x
NN(HA)、JN(Journal Node)、DN、RM、NM
问题的解决:
* NN高可用
*
Container资源容器的引用,在Hadoop1.x中资源被描述为slot,每台机器分别设置2个slot(2map
slot + 2 reduce slot),一个map
task默认就一个slot来进行执行;hadoop2.x中container将cpu、内存进行整合,明确出每个core包含多少cpu、内存,task分配资源的时候是分配core的个数。
* ApplicationMaster,任务调度管理器
* TaskAttempt(YarnChild),一个具体的MapReduce任务执行的实例。
10.2、HDFS
Hadoop Distributed Filesystem
10.2.1、特点
* 方便扩展,Federation联盟
* 高可靠,High Availability
10.2.2、常见面试题
* HDFS读写流程
* HDFS的文件备份机制是什么,在备份时机器是如何做出选择的
* 各个Node服务的功能
10.3、YARN
资源管理容器
10.3.1、特点
* Scheduler调度器: 当一个新job的产生的时候,决定如何分配资源。
* 公平调度器:FairScheduler.class,这是CDH-HADOOP默认的调度。
* 容量调度器:CapacityScheduler.class,这是Apache-HADOOP默认的调度。
*
ApplicationsMaster(注意不是AsM):整体性的应用管理器,监控AM的运行情况
10.3.2、常见面试题
* Yarn的任务调度。
* Yarn解决了Hadoop1.x中的哪些问题。
10.4、MapReduce
10.4.1、特点
* 分而治之
10.4.2、常见面试题
* MapReduce任务逻辑执行流程
InPut数据 – Map – shuffle – reduce --Output数据
* 二次排序
10.5、HBase
10.5.1、特点
分布式的、面向列的数据存储系统
HMaster、HregionServer
10.5.2、常见面试题
* HBase表结构设计
* HBase rowkey设计
* HBase mr整合
* HBase内部结构(物理结构、逻辑结构)
* HBase优化
10.6、Hive
10.6.1、特点
基于Hadoop的数据仓库,可以将结构化的数据存储为一张表,提供基本的SQL查询,操作简单、学习成本低。
10.6.2、常见面试题
* sortby、orderby、distinctby区别联系
* Hive和HBase整合(Hive读写HBase表)
* UDF编写
10.7、Flume
10.7.1、特点
通过配置source、channel、sink即可进行文件的流式采集。
10.7.2、常用操作
* 单Agent,Agent的流合并,Sink Group(官网的几张图)
10.8、Oozie
工作流控制框架
10.9、Sqoop
数据量特别大的情况更适合。
10.10、Zookeeper
分布式应用程序协调服务,需要了解Leader选举机制。
十一、Nginx
11.1、介绍
Nginx一个高性能的web服务器,对于静态资源的访问速度特别快,单台机器能够支持50000+并发服务,占用内存比较少、速度快、结构扩展容易;主要用于数据分流、服务器备份、静态资源的访问
11.2、常见其他Web服务器
* tomcat: 最常用的
* jetty: 内嵌数据库最常用的
* netty: 常用内嵌数据库
* IIS: windows集成的服务器
11.3、版本
http://tengine.taobao.org/ tengine-2.0.2
11.4、Nginx安装
Step1、在modules目录下创建nginx目录
$ mkdir /opt/modules/nginx
Step2、下载安装包
# wget http://tengine.taobao.org/download/tengine-2.0.2.tar.gz
Step3、解压
$ tar -zxf tengine-2.0.2.tar.gz /opt/modules/nginx
Step4、安装依赖服务
# yum -y install gcc openssl-devel zlib-devel pcre-devel
Step5、部署安装
±--------------------------------------------+
| # ./configure |
| |
| # make && make install |
| |
| # cd /usr/local/nginx/(查看安装是否成功) |
±--------------------------------------------+
11.5、目录结构
* 安装目录:/usr/local/nginx/
* 操作命令目录:/usr/local/nginx/sbin
* 配置文件目录:/usr/local/nginx/conf
* 默认的页面存储目录:/usr/local/nginx/html
11.6、操作命令
±----------------------------------------------+
| * 启动Nginx |
| |
| # sbin/nginx |
| |
| * 查看Nginx进程是否存在 |
| |
| # ps -ef | grep nginx |
| |
| * 关闭服务 |
| |
| # sbin/nginx -s stop |
| |
| * 重新加载配置项 |
| |
| # sbin/nginx -s reload |
| |
| * 校验conf文件夹中nginx.conf文件格式是否正确 |
| |
| # sbin/nginx -t |
| |
| * 帮助命令 |
| |
| # sbin/nginx -h |
±----------------------------------------------+
尖叫提示:如果出现如下错误,请下载对应依赖包
./configure: error: the HTTP rewrite module requires the PCRE library.
解决方案:yum install pcre-devel
十二、Mysql
12.1、介绍
一个非常常用的关系型数据库(RDBMS)
常用的引擎:
MyISAM:MySQL5.0之前默认引擎,插入/查询速度快,体积比较小,不支持事务。
InnoDB:MySQL5.x之后默认引擎,支持ACID事务,支持行级别的锁机制。
12.2、关系型数据库(SQL)种类
* MySQL: 体积小、开源
* Oracle: 功能强大、技术支持力度大
* SQLServer: Windows平台下的数据库
* PostgreSQL:
和MySQL类似,linux平台下稳定性强,开源,经常用于默认数据库
* Derby:
java编写的基于内存的数据,体积小,支持两种模式:内嵌+服务器模式,经常用于内嵌数据库
12.3、特征
* 支持Sql查询
* 支持ACID特性
* 数据有严格的schema
* 数据以表格的形式呈现
* 以行和列构成数据
* 行表示是事件的具体值
* 列表示的是对于值的数据域
* 若干行构成数据表
* 若干表构成数据库(database)
12.4、术语
* 数据库
* 数据表
* 列
* 行
* 冗余
* 主键
* 外键
* 索引: 唯一索引、复合索引等等
12.4、与非关系型数据库比较(Not Only SQL)
12.4.1、种类
*
键值对数据库:redis等,数据不是结构化,存储是一个key对应一个value,查询也是如此,一般基于内存,速度比较快,常用于缓存
* 列式存储数据库:HBase、Cassandra等
* 文档型数据库::MongoDB等
*** 图数据库:**Neo4j等, 常见应用:知识图谱
12.4.2、特征
* 不支持sql查询,每个数据库都有自己查询操作api
* 不支持事务,保证数据的最终一致性
* 不需要预定义模式,模式自由
* 分布式的、扩充简单
* 异步复制:基于操作日志进行数据复制
* 访问速度较快(特定的场景)
12.4.3、总结
关系型数据库和NoSQL整合使用,一般使用NoSQL作为部分场景的数据存储,使用sql作为持久化的存储,例如:mysql+redis
==> redis(做缓存)
十三、数据收集
13.1、收集方式
* PC端、移动Web端使用JS
* 移动端(Android、iOS、WinPhone)使用对应的SDK
* 后台程序使用对应的SDK,例如JavaSDK,PythonSDK等等
* 还有其他
13.2、数据的事件类型
13.2.1、Launch事件
Launch事件主要就是表示用户(访客)第一次到网站的事件类型,主要应用于计算新用户等类似任务的计算。
参数名 说明
en 事件名称,launch事件为:e_l
ver 版本号
pl 平台名称,launch事件中为website
sdk sdk版本号,website平台中为js
u_ud 用户id,唯一标识访客(用户)
u_mid 会员id,业务系统的用户id
u_sd 会话id,标识会话id
c_time 客户端时间
l 平台语言,window.navigator.language
b_iev 浏览器信息,window.navigator.userAgent
b_rst 浏览器屏幕大小,screen.width + “*” + screen.height
13.2.2、PageView事件
PageView事件是pc端的基本事件类型,主要是描述用户访问网站信息,应用于基本的各个不同计算任务。
参数 参数说明
en 事件名称,pageview事件为:e_pv
p_url 当前页面的url
p_ref 当前一个页面的url,如果没有前一个页面,那么值为空
tt 当前页面的标题
13.2.3、Event事件
event事件是专门记录用户对于某些特定事件/活动的触发行为,主要是用于计算各活动的活跃用户以及各个不同访问链路的转化率情况等任务。
参数 参数说明
en 事件名称,event事件为e_e
ca 事件的category值,即事件的种类名称,不为空
ac 事件的action值,即事件的活动名称,不为空
du 事件持续时间,可以为空
kv_ 事件自定义属性键值对。比如kv_keyname=value,这里的keyname和value就是用户自定义,支持在事件上定义多个属性键值对
13.2.4、ChargeRequest事件
该事件的主要作用是记录用户产生订单的行为/数据,为统计计算订单相关的统计结果提供基础数据。
参数 参数说明
en 事件名称,event事件为:e_crt
oid 订单id(order id)
on 订单名称(order name)
cua 订单金额(currency amount)
cut 订单支付货币类型(currency type)
pt 订单支付方式(payment type)
13.2.5、ChargeSuccess事件
该事件的主要作用是记录用户在产生订单后,支付订单的行为。为统计订单转化率提供基础数据的支持。
参数 参数说明
u_mid 会员id,业务系统的用户id
en 事件名称,ChargeSuccess事件为:e_cs
oid 订单id(order id)
c_time 客户端时间
ver 版本信息
pl 平台名称,后台平台名称为:java_server
sdk sdk名称,后台平台名称为jdk
13.2.6、ChargeRefund事件
该事件的主要作用是记录用户对应订单退款的相关行为。为统计订单退款率提供基础数据的支持。
参数 参数说明
en 事件名称,ChargeRefund事件为:e_cr
u_mid 会员id,业务系统的用户id
oid 订单id(order id)
c_time 客户端时间
ver 版本信息
pl 平台名称,后台平台名称为:java_server
sdk sdk名称,后台平台名称为:jdk
13.3、Nginx日志收集服务器
13.3.1、字段信息
字段 字段说明
IP地址 客户端的IP地址
服务器时间 访问服务器的时间(防止客户端时间发生异常)
浏览器是否支持Flash 浏览器是否支持Flash
浏览器信息 浏览器类型等等
客户端时间 访问浏览器的时候,方便进行缓存,例如当url没有变动时,浏览器将缓存,新的请求不会发送给服务器。
13.3.2、Nginx日志格式
* 分割字段:^A
* 格式举例:IP地址^A服务器时间^A请求参数
13.3.3、Nginx配置
参考文档:
[http://tengine.taobao.org/document/http_upstream_dynamic.html]{.underline}
Step1、备份conf目录下的nginx.conf
# cp nginx.conf nginx.conf.bak
Step2、配置nginx.conf如下
# http标签中添加如下
# 定义日志格式
log_format user_log_format '$remote_addr^A$msec^A$request_uri';
# server标签中添加如下
server_name hadoop-senior01 hadoop-senior01.itguigu.com;
# server标签中添加location标签如下
# 新增一个location,匹配所有以what.png结尾的请求
location ~ .*(what)\.(png)$ {
# 设置请求类型为图片请求
default_type image/png;
# 记录日志,存储到一个flume用户可以读取的文件夹中,需要修改权限
access_log /usr/local/nginx/user_logs/access.log user_log_format;
# 给定存储图片的服务器位置
root /usr/local/nginx/html;
}
Step3、修改nginx.conf用户以及用户组为root:root
# chown root:root nginx.conf
Step4、修改nginx.conf权限为644,即rw-r—r---
# chmod 644 nginx.conf
Step5、创建存储用户日志的文件夹/usr/local/nginx/user_logs,并将其权限修改为777
# mkdir user_logs/
# chmod 777 user_logs/
Step6、将what.png图片文件移动到/usr/local/nginx/html文件夹中,并修改用户及权限和该文件夹中的其他文件一样
# cp /opt/softwares/what.png /usr/local/nginx/html/
Step7、重启Nginx服务
方式一:
# cat /usr/local/nginx/logs/nginx.pid
# kill -9 xxxxx
方式二:
# ps -ef | grep nginx
# kill -9 xxxxx
方式三:
# sbin/nginx -s stop
重启:
# sbin/nginx
Step8、进行网页刷新测试,观察access_log下是否产生日志
13.4、Flume数据采集
13.4.1、编写Flume脚本上传日志文件到HDFS
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/nginx/user_logs/access.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.122.20:8020/event-logs/%Y/%m/%d
a1.sinks.k1.hdfs.filePrefix=FlumeData
a1.sinks.k1.hdfs.fileSuffix=.log
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 10000
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 0
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 131072000
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0
#当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重命名成目标文件
a1.sinks.k1.hdfs.idleTimeout = 60
#最小冗余数
a1.sinks.k1.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# 一般设置为2 * 1024 * 1024 * 100 = 209715200
a1.channels.c1.capacity = 5120000
# 单个进程的最大处理能力
a1.channels.c1.transactionCapacity = 512000
a1.channels.c1.keep-alive=60
a1.channels.c1.byteCapacityBufferPercentage=10
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
13.4.2、将core-site.xml和hdfs-site.xml文件软连接到flume的conf文件夹中
$ ln -s /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop/hdfs-site.xml conf/
$ ln -s /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop/core-site.xml conf/
13.5、启动采集测试
$ bin/flume-ng agent
--conf conf/
--conf-file conf/workspace/flume-load-log-2-hdfs.conf
--name a1 -Dflume.root.logger=INFO,console > logs/flume-load-log-2-hdfs.log 2>&1 &
十四、工程JS/JAVA SDK讲解
见代码
十五、Flume故障之手动上传数据
如果Flume实时上传日志的进程挂掉了,那么一般第二天我们需要手动上传前一天的日志,在上传之前,我们不能对所有的日志进行重复上传,所以需要对日志进行按天切割。
15.1、分割Nginx日志,按天保存
15.1.1、脚本编写
见脚本split_nginx_log.sh
#!/bin/bash
#实时日志存放地
LOGS_PATH="/usr/local/nginx/user_logs"
#生成旧日志存放地路径
OLD_LOGS_PATH=${LOGS_PATH}/logs/$(date -d "yesterday" +%Y)/$(date -d "yesterday" +%m)/$(date -d "yesterday" +%d)
#创建旧日志存放目录,如果目录不存在(1、先判断,再创建,否则可能出错。2、使用-p递归操作即使存在也不会报错)
mkdir -p ${OLD_LOGS_PATH}
#移动昨天的日志文件到指定目录
mv ${LOGS_PATH}/access.log ${OLD_LOGS_PATH}/access_$(date -d "yesterday" +%Y%m%d_%H%M%S).log
#重启Nigxin刷新文件句柄
kill -USR1 `cat /usr/local/nginx/logs/nginx.pid`
15.1.2、其他环境准备
Step1、创建该项目系列脚本存放的目录
$ mkdir -p /opt/modules/mysbin
Step2、将脚本移动到该目录下
$ mv split_nginx_log.sh /opt/modules/mysbin
Step3、确保脚本执行的用户拥有所需的权限
# chown root:root split_nginx_log.sh
# chmod u+x split_nginx_log.sh
15.1.2、定时任务
# crontab -e
编辑内容如下:
# .------------------------------------------minute(0~59)
# | .----------------------------------------hours(0~23)
# | | .--------------------------------------day of month(1~31)
# | | | .------------------------------------month(1~12)
# | | | | .----------------------------------day of week(0~6)
# | | | | | .--------------------------------command
# | | | | | |
# | | | | | |
0 0 * * * /opt/modules/mysbin/split_nginx_log.sh
15.2、手动上传Nginx日志
15.2.1、脚本编写
见脚本put_nginx_log_2_hdfs.sh
#!/bin/bash
#计算昨天的日期
yesterday=$(date --date='1 days ago' +'%Y/%m/%d')
#存放今天之前的所有的日志存放的目录
LOGS_PATH=/usr/local/nginx/user_logs/logs
#HDFS存放日志的目录
HDFS_LOGS_PATH=/event-logs/${yesterday}
export HADOOP_USER_NAME=admin
#递归创建HDFS存储目录
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -mkdir -p ${HDFS_LOGS_PATH}
#开始上传
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put -f -p ${LOGS_PATH}/$(date -d "yesterday" +"%Y")/$(date -d "yesterday" +"%m")/$(date -d "yesterday" +"%d")/access_*.log ${HDFS_LOGS_PATH}
15.2.2、测试脚本
Step1、修改HADOOP_USER_NAME对应的HDFS操作用户名称
# export HADOOP_USER_NAME=admin
dfs.permissions.enable
false
Step2、将脚本移动到mysbin目录下
# mv put_nginx_log_2_hdfs.sh /opt/modules/mysbin
Step3、修改权限(参考15.1修改权限部分)
Step4、执行脚本
# /opt/modules/mysbin/put_nginx_log_2_hdfs.sh
十六、数据处理
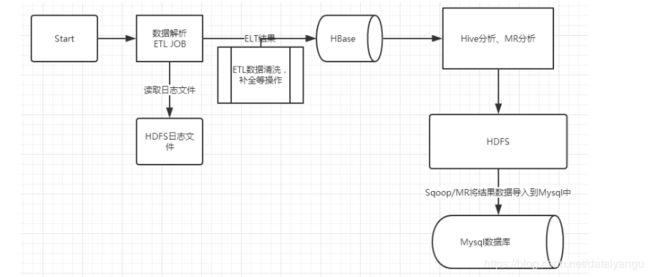
16.1、ETL操作
功能:清洗、过滤、补全
数据来源:存储在HDFS上的日志文件
数据处理方式:MapReduce
数据保存位置:HBase
16.2、HBase设计
16.2.1、每天1张表
即按天分表,一天的数据存放于一张表中,rowkey采用随机值,不需要有特定规律,尽可能的散列。
16.2.2、倒叙或在前缀上加数字
rowkey的设计要具体问题具体分析,有时会采取倒叙的原则,有时会采取rowkey前加上一个随机的数字。(该数字一般要和HregionServer的数量求模运算)
16.2.3、预分区
根据业务预估数据量,提前建好预分区,避免region频繁拆分合并造成的性能浪费。
16.3、MapReduce分析过程
操作流程:HBase读取数据 InputFormat map shuffle reduce OutputFormat
Mysql
16.4、Hive分析
数据源:使用Hive external table 创建关联HBase中的数据表
数据结果:保存于HDFS上(保存到Hive结果表中)
操作流程:Hive external table UDF编写 HQL分析语句编写
保存到Hive结果表中(其实也就是在HDFS上) Sqoop导出数据 Mysql
16.5、Mysql表结构设计
16.5.1、常用关系型数据库表模型
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。
* 星型模型
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家
A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B
的信息分别存储了两次,即存在冗余。

* 雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的
" 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图
2,将地域维表又分解为国家,省份,城市等维表。它的优点是
: 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
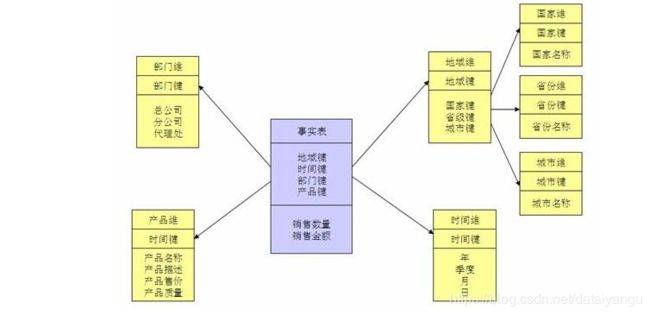
雪花模型加载数据集时,ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。星形模型加载维度表,不需要再维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。
16.5.2、表结构
维度表:dimension_table
事实表:stats_table
辅助表:主要用于协助ETL、数据分析等操作获取其他非日志数据,例如:保存会员id等
数据处理的数据准备
EventEnum 事件的枚举类
package com.z.transformer.common;
import org.apache.hadoop.hbase.util.Bytes;
/**
* 定义日志收集客户端收集得到的用户数据参数的name名称
* 以及event_logs这张hbase表的结构信息
* 用户数据参数的name名称就是event_logs的列名
*
*/
public class EventLogConstants {
/**
* 事件枚举类。指定事件的名称
*
*
*/
public static enum EventEnum {
LAUNCH(1, "launch event", "e_l"), // launch事件,表示第一次访问
PAGEVIEW(2, "page view event", "e_pv"), // 页面浏览事件
CHARGEREQUEST(3, "charge request event", "e_crt"), // 订单生产事件
CHARGESUCCESS(4, "charge success event", "e_cs"), // 订单成功支付事件
CHARGEREFUND(5, "charge refund event", "e_cr"), // 订单退款事件
EVENT(6, "event duration event", "e_e") // 事件
;
public final int id; // id 唯一标识
public final String name; // 名称
public final String alias; // 别名,用于数据收集的简写
private EventEnum(int id, String name, String alias) {
this.id = id;
this.name = name;
this.alias = alias;
}
/**
* 获取匹配别名的event枚举对象,如果最终还是没有匹配的值,那么直接返回null。
*
* @param alias
* @return
*/
public static EventEnum valueOfAlias(String alias) {
for (EventEnum event : values()) {
if (event.alias.equals(alias)) {
return event;
}
}
return null;
}
}
/**
* 平台名称常量类
*/
public static class PlatformNameConstants {
public static final String PC_WEBSITE_SDK = "website";
public static final String JAVA_SERVER_SDK = "java_server";
}
/**
* 表名称
*/
public static final String HBASE_NAME_EVENT_LOGS = "event-logs";
/**
* event_logs表的列簇名称
*/
public static final String EVENT_LOGS_FAMILY_NAME = "info";
/**
* event_logs表列簇对应的字节数组
*/
public static final byte[] BYTES_EVENT_LOGS_FAMILY_NAME = Bytes.toBytes(EVENT_LOGS_FAMILY_NAME);
/**
* 日志分隔符
*/
public static final String LOG_SEPARTIOR = "\\^A";
/**
* 用户ip地址
*/
public static final String LOG_COLUMN_NAME_IP = "ip";
/**
* 服务器时间
*/
public static final String LOG_COLUMN_NAME_SERVER_TIME = "s_time";
/**
* 事件名称
*/
public static final String LOG_COLUMN_NAME_EVENT_NAME = "en";
/**
* 数据收集端的版本信息
*/
public static final String LOG_COLUMN_NAME_VERSION = "ver";
/**
* 用户唯一标识符
*/
public static final String LOG_COLUMN_NAME_UUID = "u_ud";
/**
* 会员唯一标识符
*/
public static final String LOG_COLUMN_NAME_MEMBER_ID = "u_mid";
/**
* 会话id
*/
public static final String LOG_COLUMN_NAME_SESSION_ID = "u_sd";
/**
* 客户端时间
*/
public static final String LOG_COLUMN_NAME_CLIENT_TIME = "c_time";
/**
* 语言
*/
public static final String LOG_COLUMN_NAME_LANGUAGE = "l";
/**
* 浏览器user agent参数
*/
public static final String LOG_COLUMN_NAME_USER_AGENT = "b_iev";
/**
* 浏览器分辨率大小
*/
public static final String LOG_COLUMN_NAME_RESOLUTION = "b_rst";
/**
* 定义platform
*/
public static final String LOG_COLUMN_NAME_PLATFORM = "pl";
/**
* 当前url
*/
public static final String LOG_COLUMN_NAME_CURRENT_URL = "p_url";
/**
* 前一个页面的url
*/
public static final String LOG_COLUMN_NAME_REFERRER_URL = "p_ref";
/**
* 当前页面的title
*/
public static final String LOG_COLUMN_NAME_TITLE = "tt";
/**
* 订单id
*/
public static final String LOG_COLUMN_NAME_ORDER_ID = "oid";
/**
* 订单名称
*/
public static final String LOG_COLUMN_NAME_ORDER_NAME = "on";
/**
* 订单金额
*/
public static final String LOG_COLUMN_NAME_ORDER_CURRENCY_AMOUNT = "cua";
/**
* 订单货币类型
*/
public static final String LOG_COLUMN_NAME_ORDER_CURRENCY_TYPE = "cut";
/**
* 订单支付方式
*/
public static final String LOG_COLUMN_NAME_ORDER_PAYMENT_TYPE = "pt";
/**
* category名称
*/
public static final String LOG_COLUMN_NAME_EVENT_CATEGORY = "ca";
/**
* action名称
*/
public static final String LOG_COLUMN_NAME_EVENT_ACTION = "ac";
/**
* kv前缀
*/
public static final String LOG_COLUMN_NAME_EVENT_KV_START = "kv_";
/**
* duration持续时间
*/
public static final String LOG_COLUMN_NAME_EVENT_DURATION = "du";
/**
* 操作系统名称
*/
public static final String LOG_COLUMN_NAME_OS_NAME = "os";
/**
* 操作系统版本
*/
public static final String LOG_COLUMN_NAME_OS_VERSION = "os_v";
/**
* 浏览器名称
*/
public static final String LOG_COLUMN_NAME_BROWSER_NAME = "browser";
/**
* 浏览器版本
*/
public static final String LOG_COLUMN_NAME_BROWSER_VERSION = "browser_v";
/**
* ip地址解析的所属国家
*/
public static final String LOG_COLUMN_NAME_COUNTRY = "country";
/**
* ip地址解析的所属省份
*/
public static final String LOG_COLUMN_NAME_PROVINCE = "province";
/**
* ip地址解析的所属城市
*/
public static final String LOG_COLUMN_NAME_CITY = "city";
}
GlobalConstants 全局的常量类
package com.z.transformer.common;
/**
* 全局常量类
*
*/
public class GlobalConstants {
/**
* 一天的毫秒数
*/
public static final int DAY_OF_MILLISECONDS = 86400000;
/**
* 存储在HDFS路径上的日志文件前缀
*/
public static final String HDFS_LOGS_PATH_PREFIX = "/event-logs";
/**
* 定义的运行时间变量名
*/
public static final String RUNNING_DATE_PARAMES = "RUNNING_DATE";
/**
* 定义的运行时etl操作是否覆盖hbase表,如果为参数值为true,表示覆盖,那么表示重新创建,否则不进行重新创建
*/
public static final String RUNNING_OVERRIDE_ETL_HBASE_TABLE = "";
/**
* 默认值
*/
public static final String DEFAULT_VALUE = "unknown";
/**
* 维度信息表中指定全部列值
*/
public static final String VALUE_OF_ALL = "all";
/**
* 定义的output collector的前缀
*/
public static final String OUTPUT_COLLECTOR_KEY_PREFIX = "collector_";
/**
* 指定连接表配置为report
*/
public static final String WAREHOUSE_OF_REPORT = "report";
/**
* 批量执行的key
*/
public static final String JDBC_BATCH_NUMBER = "mysql.batch.number";
/**
* 默认批量大小
*/
public static final String DEFAULT_JDBC_BATCH_NUMBER = "500";
/**
* driver 名称
*/
public static final String JDBC_DRIVER = "mysql.%s.driver";
/**
* JDBC URL
*/
public static final String JDBC_URL = "mysql.%s.url";
/**
* username名称
*/
public static final String JDBC_USERNAME = "mysql.%s.username";
/**
* password名称
*/
public static final String JDBC_PASSWORD = "mysql.%s.password";
}
十七、工具代码导入
见代码
十八、业务ETL实现
18.1、功能
过滤内容:过滤无效数据
,比如缺少uuid,缺少会话ip,订单事件中缺少订单id
补全内容:IP地址信息补全地域信息(国家、省份、城市等)、浏览器相关信息补全,服务器时间补全等等
18.2、数据
18.2.1、上传方式
* Flume:在Flume工作正常的情况下,所有的日志均已Flume上传写入。
* Shell手动:当Flume进程出现异常,需要手动执行脚本的上传。
18.2.2、流程
使用MapReduce通过TextInputFormat的方式将HDFS中的数据读取到map中,最终通过TableOutputFormat到HBase中。
18.2.3、细节分析
* 日志解析
日志存储于HDFS中,一行一条日志,解析出操作行为中具体的key-value值,然后进行解码操作。
* IP地址解析/补全
* 浏览器信息解析
* HBase rowkey设计
注意规则:尽可能的短小,占用内存少,尽可能的均匀分布
* HBase表的创建
使用Java API创建
18.3、代码实现
关键类:
LoggerUtil.java
详情见代码

package com.z.transformer.util;
import java.net.URLDecoder;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.apache.log4j.Logger;
import com.z.transformer.common.EventLogConstants;
import com.z.transformer.util.IPSeekerExt.RegionInfo;
import cz.mallat.uasparser.UserAgentInfo;
public class LoggerUtil {
private static final Logger logger = Logger.getLogger(LoggerUtil.class);
/**
* 解析给定的日志行,如果解析成功返回一个有值的map集合,如果解析失败,返回一个empty集合
*
* @param logText
* @return
*/
public static Map<String, String> handleLogText(String logText) {
Map<String, String> result = new HashMap<String, String>();
// 1、开始解析
// hadoop集群中默认只有org.apache.commons.lang.StringUtils所在的jar包
if (StringUtils.isNotBlank(logText)) {
// 日志行非空,可以进行解析
String[] splits = logText.trim().split(EventLogConstants.LOG_SEPARTIOR);
if (splits.length == 3) {
// 日志格式是正确的,进行解析
String ip = splits[0].trim();
result.put(EventLogConstants.LOG_COLUMN_NAME_IP, ip);
long serverTime = TimeUtil.parseNginxServerTime2Long(splits[1].trim());
if (serverTime != -1L) {
// 表示服务器时间解析正确,而且serverTime就是对于的毫秒级的时间戳
result.put(EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME, String.valueOf(serverTime));
}
String requestBody = splits[2].trim();
int index = requestBody.indexOf("?"); // ?符号所在的位置
if (index >= 0 && index != requestBody.length() - 1) {
// 在请求参数中存在?,而且?不是最后一个字符的情况
requestBody = requestBody.substring(index + 1);
} else {
requestBody = null;
}
if (StringUtils.isNotBlank(requestBody)) {
// 非空,开始处理请求参数
handleRequestBody(result, requestBody);
// 补全ip地址
RegionInfo info = IPSeekerExt.getInstance().analysisIp(result.get(EventLogConstants.LOG_COLUMN_NAME_IP));
if(info != null){
result.put(EventLogConstants.LOG_COLUMN_NAME_COUNTRY, info.getCountry());
result.put(EventLogConstants.LOG_COLUMN_NAME_PROVINCE, info.getProvince());
result.put(EventLogConstants.LOG_COLUMN_NAME_CITY, info.getCity());
}
// 开始补全浏览器信息
UserAgentInfo uaInfo = UserAgentUtil.analyticUserAgent(result.get(EventLogConstants.LOG_COLUMN_NAME_USER_AGENT));
if(uaInfo != null){
//浏览器名称
result.put(EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME, uaInfo.getUaFamily());
//浏览器版本号
result.put(EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION, uaInfo.getBrowserVersionInfo());
//浏览器所在操作系统
result.put(EventLogConstants.LOG_COLUMN_NAME_OS_NAME, uaInfo.getOsFamily());
//浏览器所在操作系统的版本
result.put(EventLogConstants.LOG_COLUMN_NAME_OS_VERSION, uaInfo.getOsName());
}
} else {
// logger
logger.debug("请求参数为空:" + logText);
result.clear(); // 清空
}
} else {
// log记录一下
logger.debug("日志行内容格式不正确:" + logText);
}
} else {
logger.debug("日志行内容为空,无法进行解析:" + logText);
}
return result;
}
/**
* 处理请求参数
* 处理结果保存到参数clientInfo集合
*
* @param clientInfo
* 保存最终用户行为数据的map集合
* @param requestBody
* 请求参数中,用户行为数据,格式为:
* u_nu=1&u_sd=6D4F89C0-E17B-45D0-BFE0-059644C1878D&c_time=
* 1450569596991&ver=1&en=e_l&pl=website&sdk=js&b_rst=1440*900&
* u_ud=4B16B8BB-D6AA-4118-87F8-C58680D22657&b_iev=Mozilla%2F5.0%
* 20(Windows%20NT%205.1)%20AppleWebKit%2F537.36%20(KHTML%2C%
* 20like%20Gecko)%20Chrome%2F45.0.2454.101%20Safari%2F537.36&l=
* zh-CN&bf_sid=33cbf257-3b11-4abd-ac70-c5fc47afb797_11177014
*/
private static void handleRequestBody(Map<String, String> clientInfo, String requestBody) {
String[] parameters = requestBody.split("&");
for (String parameter : parameters) {
// 循环处理参数, parameter格式为: c_time=1450569596991, =只会出现一次
String[] params = parameter.split("=");
String key, value = null;
try {
// 使用utf8解码
key = URLDecoder.decode(params[0].trim(), "utf-8");
value = URLDecoder.decode(params[1].trim(), "utf-8");
// 添加到结果集合中
clientInfo.put(key, value);
} catch (Exception e) {
logger.warn("解码失败:" + parameter, e);
}
}
}
}
%有两种方法解决 一种是将%转化为%25,一种是将%的数据丢弃
loggerUtil的测试类

18.3.1、日志解析
18.3.2、IP地址解析补全
一共有三总方式
* 使用淘宝接口解析IP地址
官网:[http://ip.taobao.com/]{.underline}

REST
API:[http://ip.taobao.com/service/getIpInfo.php?ip=123.125.71.38]{.underline}
限制:10QPS(Query Per Second),每秒请求十次

* 使用第三方IP库
通过文件中已经存放的IP和地区的映射进行IP解析,由于更新不及时,可能会导致某些IP解析不正确(小概率事件)
第三方IPSeeker(将ip地址转换成十进制的工具,源码在csdn上)
* 使用自己的IP库
通过第三方的IP库,逐渐生成自己的IP库,自主管理。
表设计:
startip(起始ip)
endip(结束ip)
country(国家)
province(省份)
city(城市)
尖叫提示:判断某个IP是否在某个地域的起始IP和结束IP区间
ip地址的数据库,可以在百度搜索 “纯真”,下载ip数据库
对应的类中填写正确的地址
ip的解析,是先转换成十进制,然后通过十进制的落在了哪个范围,判断在哪个国家哪个城市,例如:

IP与Long的互转:
//将127.0.0.1形式的IP地址转换成十进制整数
public long IpToLong(string strIp){
long[] ip = new long[4];
int position1 = strIp.IndexOf(".");
int position2 = strIp.IndexOf(".", position1 + 1);
int position3 = strIp.IndexOf(".", position2 + 1);
// 将每个.之间的字符串转换成整型
ip[0] = long.Parse(strIp.Substring(0, position1));
ip[1] = long.Parse(strIp.Substring(position1 + 1, position2 - position1 - 1));
ip[2] = long.Parse(strIp.Substring(position2 + 1, position3 - position2 - 1));
ip[3] = long.Parse(strIp.Substring(position3 + 1));
//进行左移位处理
return (ip[0] << 24) + (ip[1] << 16) + (ip[2] << 8) + ip[3];
}
//将十进制整数形式转换成127.0.0.1形式的ip地址
public string LongToIp(long ip){
StringBuilder sb = new StringBuilder();
//直接右移24位
sb.Append(ip >> 24);
sb.Append(".");
//将高8位置0,然后右移16
sb.Append((ip & 0x00FFFFFF) >> 16);
sb.Append(".");
//将高16位置0,然后右移8位
sb.Append((ip & 0x0000FFFF) >> 8);
sb.Append(".");
//将高24位置0
sb.Append((ip & 0x000000FF));
return sb.ToString();
}
这里使用的是csdn的IPSooker的工具类,两个工具类的源码
IPSeeker
package com.z.transformer.util.ip;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.io.UnsupportedEncodingException;
import java.nio.ByteOrder;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.List;
/**
* * 用来读取QQwry.dat文件,以根据ip获得好友位置,QQwry.dat的格式是
* 一. 文件头,共8字节
* 1. 第一个起始IP的绝对偏移, 4字节
* 2. 最后一个起始IP的绝对偏移, 4字节
* 二. "结束地址/国家/区域"记录区 四字节ip地址后跟的每一条记录分成两个部分
* 1. 国家记录
* 2.地区记录 但是地区记录是不一定有的。而且国家记录和地区记录都有两种形式
* 1. 以0结束的字符串
* 2. 4个字节,一个字节可能为0x1或0x2
* a.为0x1时,表示在绝对偏移后还跟着一个区域的记录,注意是绝对偏移之后,而不是这四个字节之后
* b. 为0x2时,表示在绝对偏移后没有区域记录,不管为0x1还是0x2,后三个字节都是实际国家名的文件内绝对偏移
* 如果是地区记录,0x1和0x2的含义不明,但是如果出现这两个字节,也肯定是跟着3个字节偏移,如果不是 则为0结尾字符串 三.
* "起始地址/结束地址偏移"记录区
* 1. 每条记录7字节,按照起始地址从小到大排列
* a. 起始IP地址,4字节
* b. 结束ip地址的绝对偏移,3字节
*
* 注意,这个文件里的ip地址和所有的偏移量均采用little-endian格式,而java是采用 big-endian格式的,要注意转换
*
*/
public class IPSeeker {
public static final String ERROR_RESULT = "错误的IP数据库文件";
// 一些固定常量,比如记录长度等等
private static final int IP_RECORD_LENGTH = 7;
private static final byte AREA_FOLLOWED = 0x01;
private static final byte NO_AREA = 0x2;
// 用来做为cache,查询一个ip时首先查看cache,以减少不必要的重复查找
private Hashtable ipCache;
// 随机文件访问类
private RandomAccessFile ipFile;
// 内存映射文件
private MappedByteBuffer mbb;
// 单一模式实例
private static IPSeeker instance = null;
// 起始地区的开始和结束的绝对偏移
private long ipBegin, ipEnd;
// 为提高效率而采用的临时变量
private IPLocation loc;
private byte[] buf;
private byte[] b4;
private byte[] b3;
/** */
/**
* 私有构造函数
*/
protected IPSeeker(String ipFilePath) {
ipCache = new Hashtable();
loc = new IPLocation();
buf = new byte[100];
b4 = new byte[4];
b3 = new byte[3];
try {
ipFile = new RandomAccessFile(ipFilePath, "r");
} catch (FileNotFoundException e) {
System.out.println("IP地址信息文件没有找到,IP显示功能将无法使用");
ipFile = null;
}
// 如果打开文件成功,读取文件头信息
if (ipFile != null) {
try {
ipBegin = readLong4(0);
ipEnd = readLong4(4);
if (ipBegin == -1 || ipEnd == -1) {
ipFile.close();
ipFile = null;
}
} catch (IOException e) {
System.out.println("IP地址信息文件格式有错误,IP显示功能将无法使用");
ipFile = null;
}
}
}
/** */
/**
* @return 单一实例
*/
public static IPSeeker getInstance(String ipFilePath) {
if (instance == null) {
instance = new IPSeeker(ipFilePath);
}
return instance;
}
/** */
/**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/
public List getIPEntriesDebug(String s) {
List ret = new ArrayList();
long endOffset = ipEnd + 4;
for (long offset = ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) {
// 读取结束IP偏移
long temp = readLong3(offset);
// 如果temp不等于-1,读取IP的地点信息
if (temp != -1) {
IPLocation loc = getIPLocation(temp);
// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续
if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) {
IPEntry entry = new IPEntry();
entry.country = loc.country;
entry.area = loc.area;
// 得到起始IP
readIP(offset - 4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 得到结束IP
readIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 添加该记录
ret.add(entry);
}
}
}
return ret;
}
/** */
/**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/
public List getIPEntries(String s) {
List ret = new ArrayList();
try {
// 映射IP信息文件到内存中
if (mbb == null) {
FileChannel fc = ipFile.getChannel();
mbb = fc.map(FileChannel.MapMode.READ_ONLY, 0, ipFile.length());
mbb.order(ByteOrder.LITTLE_ENDIAN);
}
int endOffset = (int) ipEnd;
for (int offset = (int) ipBegin + 4; offset <= endOffset; offset += IP_RECORD_LENGTH) {
int temp = readInt3(offset);
if (temp != -1) {
IPLocation loc = getIPLocation(temp);
// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续
if (loc.country.indexOf(s) != -1 || loc.area.indexOf(s) != -1) {
IPEntry entry = new IPEntry();
entry.country = loc.country;
entry.area = loc.area;
// 得到起始IP
readIP(offset - 4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 得到结束IP
readIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);
// 添加该记录
ret.add(entry);
}
}
}
} catch (IOException e) {
System.out.println(e.getMessage());
}
return ret;
}
/** */
/**
* 从内存映射文件的offset位置开始的3个字节读取一个int
*
* @param offset
* @return
*/
private int readInt3(int offset) {
mbb.position(offset);
return mbb.getInt() & 0x00FFFFFF;
}
/** */
/**
* 从内存映射文件的当前位置开始的3个字节读取一个int
*
* @return
*/
private int readInt3() {
return mbb.getInt() & 0x00FFFFFF;
}
/** */
/**
* 根据IP得到国家名
*
* @param ip
* ip的字节数组形式
* @return 国家名字符串
*/
public String getCountry(byte[] ip) {
// 检查ip地址文件是否正常
if (ipFile == null)
return ERROR_RESULT;
// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);
// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件
if (ipCache.containsKey(ipStr)) {
IPLocation loc = (IPLocation) ipCache.get(ipStr);
return loc.country;
} else {
IPLocation loc = getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());
return loc.country;
}
}
/** */
/**
* 根据IP得到国家名
*
* @param ip
* IP的字符串形式
* @return 国家名字符串
*/
public String getCountry(String ip) {
return getCountry(IPSeekerUtils.getIpByteArrayFromString(ip));
}
/** */
/**
* 根据IP得到地区名
*
* @param ip
* ip的字节数组形式
* @return 地区名字符串
*/
public String getArea(byte[] ip) {
// 检查ip地址文件是否正常
if (ipFile == null)
return ERROR_RESULT;
// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);
// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件
if (ipCache.containsKey(ipStr)) {
IPLocation loc = (IPLocation) ipCache.get(ipStr);
return loc.area;
} else {
IPLocation loc = getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());
return loc.area;
}
}
/**
* 根据IP得到地区名
*
* @param ip
* IP的字符串形式
* @return 地区名字符串
*/
public String getArea(String ip) {
return getArea(IPSeekerUtils.getIpByteArrayFromString(ip));
}
/** */
/**
* 根据ip搜索ip信息文件,得到IPLocation结构,所搜索的ip参数从类成员ip中得到
*
* @param ip
* 要查询的IP
* @return IPLocation结构
*/
public IPLocation getIPLocation(byte[] ip) {
IPLocation info = null;
long offset = locateIP(ip);
if (offset != -1)
info = getIPLocation(offset);
if (info == null) {
info = new IPLocation();
info.country = "未知国家";
info.area = "未知地区";
}
return info;
}
/**
* 从offset位置读取4个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong4(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ret |= (ipFile.readByte() & 0xFF);
ret |= ((ipFile.readByte() << 8) & 0xFF00);
ret |= ((ipFile.readByte() << 16) & 0xFF0000);
ret |= ((ipFile.readByte() << 24) & 0xFF000000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/
private long readLong3(long offset) {
long ret = 0;
try {
ipFile.seek(offset);
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从当前位置读取3个字节转换成long
*
* @return
*/
private long readLong3() {
long ret = 0;
try {
ipFile.readFully(b3);
ret |= (b3[0] & 0xFF);
ret |= ((b3[1] << 8) & 0xFF00);
ret |= ((b3[2] << 16) & 0xFF0000);
return ret;
} catch (IOException e) {
return -1;
}
}
/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/
private void readIP(long offset, byte[] ip) {
try {
ipFile.seek(offset);
ipFile.readFully(ip);
byte temp = ip[0];
ip[0] = ip[3];
ip[3] = temp;
temp = ip[1];
ip[1] = ip[2];
ip[2] = temp;
} catch (IOException e) {
System.out.println(e.getMessage());
}
}
/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/
private void readIP(int offset, byte[] ip) {
mbb.position(offset);
mbb.get(ip);
byte temp = ip[0];
ip[0] = ip[3];
ip[3] = temp;
temp = ip[1];
ip[1] = ip[2];
ip[2] = temp;
}
/**
* 把类成员ip和beginIp比较,注意这个beginIp是big-endian的
*
* @param ip
* 要查询的IP
* @param beginIp
* 和被查询IP相比较的IP
* @return 相等返回0,ip大于beginIp则返回1,小于返回-1。
*/
private int compareIP(byte[] ip, byte[] beginIp) {
for (int i = 0; i < 4; i++) {
int r = compareByte(ip[i], beginIp[i]);
if (r != 0)
return r;
}
return 0;
}
/**
* 把两个byte当作无符号数进行比较
*
* @param b1
* @param b2
* @return 若b1大于b2则返回1,相等返回0,小于返回-1
*/
private int compareByte(byte b1, byte b2) {
if ((b1 & 0xFF) > (b2 & 0xFF)) // 比较是否大于
return 1;
else if ((b1 ^ b2) == 0)// 判断是否相等
return 0;
else
return -1;
}
/**
* 这个方法将根据ip的内容,定位到包含这个ip国家地区的记录处,返回一个绝对偏移 方法使用二分法查找。
*
* @param ip
* 要查询的IP
* @return 如果找到了,返回结束IP的偏移,如果没有找到,返回-1
*/
private long locateIP(byte[] ip) {
long m = 0;
int r;
// 比较第一个ip项
readIP(ipBegin, b4);
r = compareIP(ip, b4);
if (r == 0)
return ipBegin;
else if (r < 0)
return -1;
// 开始二分搜索
for (long i = ipBegin, j = ipEnd; i < j;) {
m = getMiddleOffset(i, j);
readIP(m, b4);
r = compareIP(ip, b4);
// log.debug(Utils.getIpStringFromBytes(b));
if (r > 0)
i = m;
else if (r < 0) {
if (m == j) {
j -= IP_RECORD_LENGTH;
m = j;
} else
j = m;
} else
return readLong3(m + 4);
}
// 如果循环结束了,那么i和j必定是相等的,这个记录为最可能的记录,但是并非
// 肯定就是,还要检查一下,如果是,就返回结束地址区的绝对偏移
m = readLong3(m + 4);
readIP(m, b4);
r = compareIP(ip, b4);
if (r <= 0)
return m;
else
return -1;
}
/**
* 得到begin偏移和end偏移中间位置记录的偏移
*
* @param begin
* @param end
* @return
*/
private long getMiddleOffset(long begin, long end) {
long records = (end - begin) / IP_RECORD_LENGTH;
records >>= 1;
if (records == 0)
records = 1;
return begin + records * IP_RECORD_LENGTH;
}
/**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
*
* @param offset
* @return
*/
private IPLocation getIPLocation(long offset) {
try {
// 跳过4字节ip
ipFile.seek(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();
if (b == AREA_FOLLOWED) {
// 读取国家偏移
long countryOffset = readLong3();
// 跳转至偏移处
ipFile.seek(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();
if (b == NO_AREA) {
loc.country = readString(readLong3());
ipFile.seek(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(ipFile.getFilePointer());
} else if (b == NO_AREA) {
loc.country = readString(readLong3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(ipFile.getFilePointer() - 1);
loc.area = readArea(ipFile.getFilePointer());
}
return loc;
} catch (IOException e) {
return null;
}
}
/**
* @param offset
* @return
*/
private IPLocation getIPLocation(int offset) {
// 跳过4字节ip
mbb.position(offset + 4);
// 读取第一个字节判断是否标志字节
byte b = mbb.get();
if (b == AREA_FOLLOWED) {
// 读取国家偏移
int countryOffset = readInt3();
// 跳转至偏移处
mbb.position(countryOffset);
// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = mbb.get();
if (b == NO_AREA) {
loc.country = readString(readInt3());
mbb.position(countryOffset + 4);
} else
loc.country = readString(countryOffset);
// 读取地区标志
loc.area = readArea(mbb.position());
} else if (b == NO_AREA) {
loc.country = readString(readInt3());
loc.area = readArea(offset + 8);
} else {
loc.country = readString(mbb.position() - 1);
loc.area = readArea(mbb.position());
}
return loc;
}
/**
* 从offset偏移开始解析后面的字节,读出一个地区名
*
* @param offset
* @return 地区名字符串
* @throws IOException
*/
private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();
if (b == 0x01 || b == 0x02) {
long areaOffset = readLong3(offset + 1);
if (areaOffset == 0)
return "未知地区";
else
return readString(areaOffset);
} else
return readString(offset);
}
/**
* @param offset
* @return
*/
private String readArea(int offset) {
mbb.position(offset);
byte b = mbb.get();
if (b == 0x01 || b == 0x02) {
int areaOffset = readInt3();
if (areaOffset == 0)
return "未知地区";
else
return readString(areaOffset);
} else
return readString(offset);
}
/**
* 从offset偏移处读取一个以0结束的字符串
*
* @param offset
* @return 读取的字符串,出错返回空字符串
*/
private String readString(long offset) {
try {
ipFile.seek(offset);
int i;
for (i = 0, buf[i] = ipFile.readByte(); buf[i] != 0; buf[++i] = ipFile.readByte())
;
if (i != 0)
return IPSeekerUtils.getString(buf, 0, i, "GBK");
} catch (IOException e) {
System.out.println(e.getMessage());
}
return "";
}
/**
* 从内存映射文件的offset位置得到一个0结尾字符串
*
* @param offset
* @return
*/
private String readString(int offset) {
try {
mbb.position(offset);
int i;
for (i = 0, buf[i] = mbb.get(); buf[i] != 0; buf[++i] = mbb.get())
;
if (i != 0)
return IPSeekerUtils.getString(buf, 0, i, "GBK");
} catch (IllegalArgumentException e) {
System.out.println(e.getMessage());
}
return "";
}
public String getAddress(String ip) {
String country = getCountry(ip).equals(" CZ88.NET") ? "" : getCountry(ip);
String area = getArea(ip).equals(" CZ88.NET") ? "" : getArea(ip);
String address = country + " " + area;
return address.trim();
}
/**
* * 用来封装ip相关信息,目前只有两个字段,ip所在的国家和地区
*
*
* @author swallow
*/
public class IPLocation {
public String country;
public String area;
public IPLocation() {
country = area = "";
}
public IPLocation getCopy() {
IPLocation ret = new IPLocation();
ret.country = country;
ret.area = area;
return ret;
}
}
/**
* 一条IP范围记录,不仅包括国家和区域,也包括起始IP和结束IP *
*
*/
public class IPEntry {
public String beginIp;
public String endIp;
public String country;
public String area;
public IPEntry() {
beginIp = endIp = country = area = "";
}
public String toString() {
return this.area + " " + this.country + "IP Χ:" + this.beginIp + "-" + this.endIp;
}
}
/**
* 操作工具类
*/
public static class IPSeekerUtils {
/**
* 从ip的字符串形式得到字节数组形式
*
* @param ip
* 字符串形式的ip
* @return 字节数组形式的ip
*/
public static byte[] getIpByteArrayFromString(String ip) {
byte[] ret = new byte[4];
java.util.StringTokenizer st = new java.util.StringTokenizer(ip, ".");
try {
ret[0] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[1] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[2] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
ret[3] = (byte) (Integer.parseInt(st.nextToken()) & 0xFF);
} catch (Exception e) {
System.out.println(e.getMessage());
}
return ret;
}
/**
* 对原始字符串进行编码转换,如果失败,返回原始的字符串
*
* @param s
* 原始字符串
* @param srcEncoding
* 源编码方式
* @param destEncoding
* 目标编码方式
* @return 转换编码后的字符串,失败返回原始字符串
*/
public static String getString(String s, String srcEncoding, String destEncoding) {
try {
return new String(s.getBytes(srcEncoding), destEncoding);
} catch (UnsupportedEncodingException e) {
return s;
}
}
/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/
public static String getString(byte[] b, String encoding) {
try {
return new String(b, encoding);
} catch (UnsupportedEncodingException e) {
return new String(b);
}
}
/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param offset
* 要转换的起始位置
* @param len
* 要转换的长度
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/
public static String getString(byte[] b, int offset, int len, String encoding) {
try {
return new String(b, offset, len, encoding);
} catch (UnsupportedEncodingException e) {
return new String(b, offset, len);
}
}
/**
* @param ip
* ip的字节数组形式
* @return 字符串形式的ip
*/
public static String getIpStringFromBytes(byte[] ip) {
StringBuffer sb = new StringBuffer();
sb.append(ip[0] & 0xFF);
sb.append('.');
sb.append(ip[1] & 0xFF);
sb.append('.');
sb.append(ip[2] & 0xFF);
sb.append('.');
sb.append(ip[3] & 0xFF);
return sb.toString();
}
}
/**
* 获取全部ip地址集合列表
*
* @return
*/
public List<String> getAllIp() {
List<String> list = new ArrayList<String>();
byte[] buf = new byte[4];
for (long i = ipBegin; i < ipEnd; i += IP_RECORD_LENGTH) {
try {
this.readIP(this.readLong3(i + 4), buf); // 读取ip,最终ip放到buf中
String ip = IPSeekerUtils.getIpStringFromBytes(buf);
list.add(ip);
} catch (Exception e) {
// nothing
}
}
return list;
}
}
IPSeekerExt
package com.z.transformer.util;
import com.z.transformer.common.GlobalConstants;
import com.z.transformer.util.ip.IPSeeker;
/**
* Ip解析工具类
*
*/
public class IPSeekerExt extends IPSeeker {
/**
* 保存纯真ip库的ip文件路径
*/
private static final String ipFilePath = "ip/qqwry.dat";
/**
* 静态的代码解析类对象,用于单例模式
*/
private static IPSeekerExt obj = new IPSeekerExt(ipFilePath);
/**
* 构造函数,private修饰,单例模式
*
* @param ipFilePath
*/
private IPSeekerExt(String ipFilePath) {
super(ipFilePath);
}
/**
* 获取ip解析对象
*
* @return
*/
public static IPSeekerExt getInstance() {
return obj;
}
/**
* 解析ip地址
* 如果解析正常,返回具体的值
* 如果无法解析,返回unknown
* 如果解析过程中出现异常信息,直接返回null
*
* @param ip
* 需要进行解析的ip地址库
* @return
*/
public RegionInfo analysisIp(String ip) {
RegionInfo info = new RegionInfo();
// 判断参数是否为空
if (ip != null && !"".equals(ip.trim())) {
// ip不为空
String country = super.getCountry(ip);
if (country == null || country.isEmpty()) {
// 数据库中没有找到ip,直接返回unknown
return info;
}
if (!ERROR_RESULT.equals(country)) {
// 能够正常解析出国家名称
if ("局域网".equals(country) || country.trim().endsWith("CZ88")) {
// 都可以认为是本地, 没有找到ip返回的值是空
info.setCountry("中国");
info.setProvince("局域网");
} else {
int length = country.length();
int index = country.indexOf("省");
if (index > 0) {
// 表示是国家的某个省份
info.setCountry("中国");
info.setProvince(country.substring(0, Math.min(index + 1, length)));
int index2 = country.indexOf('市', index);
if (index2 > 0) {
info.setCity(country.substring(index + 1, Math.min(index2 + 1, length)));
}
} else {
// 单独的处理, 自治区以及直辖市 特别行政区
String flag = country.substring(0, 2);
switch (flag) {
case "内蒙":
info.setCountry("中国");
info.setProvince("内蒙古自治区");
country = country.substring(3);
if (country != null && !country.isEmpty()) {
index = country.indexOf('市');
if (index > 0) {
info.setCity(country.substring(0, Math.min(index + 1, country.length())));
}
// :TODO 针对是旗、盟之类的不考虑
}
break;
case "广西":
case "宁夏":
case "西藏":
case "新疆":
info.setCountry("中国");
info.setProvince(flag);
country = country.substring(2);
if (country != null && !country.isEmpty()) {
index = country.indexOf('市');
if (index > 0) {
info.setCity(country.substring(0, Math.min(index + 1, country.length())));
}
}
break;
case "上海":
case "北京":
case "重庆":
case "天津":
info.setCountry("中国");
info.setProvince(flag + "市");
country = country.substring(3);
if (country != null && !country.isEmpty()) {
index = country.indexOf('区');
if (index > 0) {
char ch = country.charAt(index - 1);
if (ch != '小' && ch != '校') {
info.setCity(country.substring(0, Math.min(index + 1, country.length())));
}
}
}
if (GlobalConstants.DEFAULT_VALUE.equals(info.getCity())) {
// 没有区,可能是县
index = country.indexOf('县');
if (index > 0) {
info.setCity(country.substring(0, Math.min(index + 1, country.length())));
}
}
break;
case "香港":
case "澳门":
info.setCountry("中国");
info.setProvince(flag + "特别行政区");
break;
default:
info.setCountry(country); // 针对其他国家
break;
}
}
}
} else {
// 文件异常,直接返回null
info = null;
}
}
return info;
}
/**
* 地域描述信息内部类
*/
public static class RegionInfo {
private String country = GlobalConstants.DEFAULT_VALUE;
private String province = GlobalConstants.DEFAULT_VALUE;
private String city = GlobalConstants.DEFAULT_VALUE;
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "RegionInfo [country=" + country + ", province=" + province + ", city=" + city + "]";
}
}
}
18.3.3、浏览器信息解析
依赖查询:[http://mvnrepository.com/]{.underline}
依赖工具:uasparser第三方浏览器信息解析工具
UserAgentUtil.class
package com.z.transformer.util;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import cz.mallat.uasparser.OnlineUpdater;
import cz.mallat.uasparser.UASparser;
import cz.mallat.uasparser.UserAgentInfo;
/**
* 解析浏览器信息,解析useragent信息
* 根据第三方jar文件:uasparser.jar进行解析
*
*/
public class UserAgentUtil {
private static UASparser sparser = null;
// 初始化
static {
try {
sparser = new UASparser(OnlineUpdater.getVendoredInputStream());
} catch (IOException e) {
// nothings
}
}
/**
* 解析浏览器的user agent字符串,返回useragentinfo对象
* 如果字符串为空,返回null,解析失败,也返回null
*
* @param userAgent
* @return
*/
public static UserAgentInfo analyticUserAgent(String userAgent) {
if (StringUtils.isBlank(userAgent)) {
return null;
}
UserAgentInfo info = null;
try {
info = sparser.parse(userAgent);
} catch (IOException e) {
// nothing
}
return info;
}
}
这个工具类依赖于一个jar uasparser.jar
在maven中添加中央仓库
然后关注上面loggerUtil的部分代码
(StringUtils.isNotBlank(requestBody)) {
// 非空,开始处理请求参数
handleRequestBody(result, requestBody);
// 补全ip地址
RegionInfo info = IPSeekerExt.getInstance().analysisIp(result.get(EventLogConstants.LOG_COLUMN_NAME_IP));
if(info != null){
result.put(EventLogConstants.LOG_COLUMN_NAME_COUNTRY, info.getCountry());
result.put(EventLogConstants.LOG_COLUMN_NAME_PROVINCE, info.getProvince());
result.put(EventLogConstants.LOG_COLUMN_NAME_CITY, info.getCity());
}
将解析出的国家、省份、城市也添加进去

通过去淘宝上进行比对数据的正确性
注意上面如果是局域网的话相应的处理
if ("局域网".equals(country) || country.trim().endsWith("CZ88")) {
// 都可以认为是本地, 没有找到ip返回的值是空
info.setCountry("中国");
info.setProvince("局域网");
}
public static final String LOG_COLLUMN_NAME_USER_AGENT="biev";
这个在之前已经加到result中了
浏览器解析
// 开始补全浏览器信息
UserAgentInfo uaInfo = UserAgentUtil.analyticUserAgent(result.get(EventLogConstants.LOG_COLUMN_NAME_USER_AGENT));
if(uaInfo != null){
//浏览器名称
result.put(EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME, uaInfo.getUaFamily());
//浏览器版本号
result.put(EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION, uaInfo.getBrowserVersionInfo());
//浏览器所在操作系统
result.put(EventLogConstants.LOG_COLUMN_NAME_OS_NAME, uaInfo.getOsFamily());
//浏览器所在操作系统的版本
result.put(EventLogConstants.LOG_COLUMN_NAME_OS_VERSION, uaInfo.getOsName());
}
解析出来的数据

上面的b_iev这个键值对可以删除了
18.3.4、ETL代码编写
ps:上面写的工具类最终还是要在hdfs上运行的,也就是我们即将写的MapReduce
新建类:
开始写MapReduce
AnalysisDataMapper.java
package com.z.transformer.mr.etl;
import java.io.IOException;
import java.util.Map;
import java.util.zip.CRC32;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.log4j.Logger;
import com.z.transformer.common.EventLogConstants;
import com.z.transformer.common.EventLogConstants.EventEnum;
import com.z.transformer.util.LoggerUtil;
import com.z.transformer.util.TimeUtil;
//第一个是偏移量,
//第二个是text
//第三个不需要聚合,直接把数据拿出来放到hbase里面,key是rowkey,这里给null
//第四个是hbase中的put
public class AnalysisDataMapper extends Mapper<Object, Text, NullWritable, Put>{
private static final Logger logger = Logger.getLogger(AnalysisDataMapper.class);
private CRC32 crc32 = null;
private byte[] family = null;
private long currentDayInMills = -1;
@Override
protected void setup(Mapper<Object, Text, NullWritable, Put>.Context context) throws IOException, InterruptedException {
crc32 = new CRC32();
this.family = EventLogConstants.BYTES_EVENT_LOGS_FAMILY_NAME;
currentDayInMills = TimeUtil.getTodayInMillis();
}
//1、覆写map方法
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//2、将原始数据通过LoggerUtil解析成Map键值对
Map<String, String> clientInfo = LoggerUtil.handleLogText(value.toString());
//2.1、如果解析失败,则Map集合中无数据
if(clientInfo.isEmpty()){
logger.debug("日志解析失败:" + value.toString());
return;
}
//3、根据解析后的数据,生成对应的Event事件类型
EventEnum event = EventEnum.valueOfAlias(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME));
if(event == null){
//4、无法处理的事件,直接输出事件类型
logger.debug("无法匹配对应的事件类型:" + clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME));
}else{
//5、处理具体的事件
handleEventData(clientInfo, event, context, value);
}
}
/**
* 处理具体的事件
* @param clientInfo
* @param event
* @param context
* @param value
* @throws InterruptedException
* @throws IOException
*/
public void handleEventData (Map<String, String> clientInfo, EventEnum event, Context context, Text value) throws IOException, InterruptedException{
//6、事件成功通过过滤,则处理事件
if(filterEventData(clientInfo, event)){
outPutData(clientInfo, context);
}else{
//事件没有通过过滤,输出
logger.debug("事件格式不正确:" + value.toString());
}
}
//6、事件成功通过过滤,则处理事件
//判断当前的事件能不能存,hbase只存能够处理的事件
public boolean filterEventData(Map<String, String> clientInfo, EventEnum event){
//事件数据全局过滤
boolean result = StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME))
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_PLATFORM));
//后面几乎全部是&&操作,只要有一个false,那么该Event事件就无法处理
// public static final String PC_WEBSITE_SDK = "website";
// public static final String JAVA_SERVER_SDK = "java_server";
switch (clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_PLATFORM)) {
case EventLogConstants.PlatformNameConstants.JAVA_SERVER_SDK:
//Java Server发来的数据
//判断会员ID是否存在
result = result && StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_MEMBER_ID));
switch (event) {
case CHARGEREFUND:
//退款事件
break;
case CHARGESUCCESS:
//订单支付成功
result = result && StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_ORDER_ID));
break;
default:
logger.debug("无法处理指定事件:" + clientInfo);
result = false;
break;
}
break;
case EventLogConstants.PlatformNameConstants.PC_WEBSITE_SDK:
//WebSite发来的数据
switch (event) {
case CHARGEREQUEST:
//下单
result = result
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_ORDER_ID))
// && StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_CURRENT_URL))
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_ORDER_CURRENCY_TYPE))
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_ORDER_PAYMENT_TYPE))
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_ORDER_CURRENCY_AMOUNT));
break;
case EVENT:
//Event事件
result = result
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_EVENT_CATEGORY))
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_EVENT_ACTION));
break;
case LAUNCH:
//Launch访问事件
break;
case PAGEVIEW:
//PV事件
result = result
&& StringUtils.isNotBlank(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_CURRENT_URL));
break;
default:
logger.debug("无法处理指定事件:" + clientInfo);
result = false;
break;
}
break;
default:
result = false;
logger.debug("无法确定的数据来源:" + clientInfo);
break;
}
return result;
}
//7,8、输出事件到HBase
public void outPutData (Map<String, String> clientInfo, Context context) throws IOException, InterruptedException{
String uuid = clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_UUID);
long serverTime = Long.valueOf(clientInfo.get(EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME));
//因为浏览器信息已经解析完成,所以此时删除原始的浏览器信息
clientInfo.remove(EventLogConstants.LOG_COLUMN_NAME_USER_AGENT);
//创建rowKey
byte[] rowkey = generateRowKey(uuid, serverTime, clientInfo);
Put put = new Put(rowkey);
//map集合里面每个键值对都是一列
for(Map.Entry<String, String> entry : clientInfo.entrySet()){
if(StringUtils.isNotBlank(entry.getKey()) || StringUtils.isNotBlank(entry.getValue())){
put.add(family, Bytes.toBytes(entry.getKey()), Bytes.toBytes(entry.getValue()));
}
}
context.write(NullWritable.get(), put);
}
//9、用为向HBase中写入数据依赖Put对象,Put对象的创建依赖RowKey,所以如下方法
/**
* crc32
* 1、uuid
* 2、clientInfo
* 3、时间timeBytes + 前两步的内容
* @return
*/
public byte[] generateRowKey(String uuid, long serverTime, Map<String, String> clientInfo){
//清空crc32集合中的数据内容
//因为crc32.update()能调用很多次
crc32.reset();
if(StringUtils.isNotBlank(uuid)){
this.crc32.update(Bytes.toBytes(uuid));
}
this.crc32.update(Bytes.toBytes(clientInfo.hashCode()));
//当前数据访问服务器的时间-当天00:00点的时间戳 8位数字 -- 4字节
byte[] timeBytes = Bytes.toBytes(serverTime - this.currentDayInMills);
byte[] uuidAndMapDataBytes = Bytes.toBytes(this.crc32.getValue());
//综合字节数组
byte[] buffer = new byte[timeBytes.length + uuidAndMapDataBytes.length];
//数组合并
//参数讲解:将那个数据拷贝,从哪个位置拷贝,拷贝到哪个数据,从哪个位置开始,到哪个位置结束
System.arraycopy(timeBytes, 0, buffer, 0, timeBytes.length);
System.arraycopy(uuidAndMapDataBytes, 0, buffer, timeBytes.length, uuidAndMapDataBytes.length);
//roekey是uuid+时间差
return buffer;
}
}
AnalysisDataRunner.java
package com.z.transformer.mr.etl;
import java.io.File;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import com.z.transformer.common.EventLogConstants;
import com.z.transformer.common.GlobalConstants;
import com.z.transformer.util.TimeUtil;
public class AnalysisDataRunner implements Tool{
private Configuration conf = null;
public static void main(String[] args) {
try {
int resultCode = ToolRunner.run(new AnalysisDataRunner(), args);
if(resultCode == 0){
System.out.println("Success!");
}else{
System.out.println("Fail!");
}
System.exit(resultCode);
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
}
@Override
public void setConf(Configuration conf) {
this.conf = HBaseConfiguration.create(conf);
}
@Override
public Configuration getConf() {
return this.conf;
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
//处理 时间参数,默认或不合法时间则直接使用昨天日期
this.processArgs(conf, args);
//开始创建Job
Job job = Job.getInstance(conf, "Event-ETL");
//设置Job参数
job.setJarByClass(AnalysisDataRunner.class);
//Mapper参数设置
job.setMapperClass(AnalysisDataMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Put.class);
//Reducer参数设置
job.setNumReduceTasks(0);
//配置数据输入
this.initJobInputPath(job);
//设置输出到HBase的信息
initHBaseOutPutConfig(job);
// job.setJar("target/transformer-0.0.1-SNAPSHOT.jar");
//Job提交
return job.waitForCompletion(true) ? 0 : 1;
}
/**
* 初始化Job数据输入目录
* @param job
* @throws IOException
*/
private void initJobInputPath(Job job) throws IOException{
Configuration conf = job.getConfiguration();
//获取要执行ETL的数据是哪一天的数据
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
//格式化文件路径
String hdfsPath = TimeUtil.parseLong2String(TimeUtil.parseString2Long(date), "yyyy/MM/dd");
if(GlobalConstants.HDFS_LOGS_PATH_PREFIX.endsWith("/")){
hdfsPath = GlobalConstants.HDFS_LOGS_PATH_PREFIX + hdfsPath;
}else{
//注意这里的“File.separator”,不要写成“/”,因为
//File.separatord能够根据操作系统自动得到文件分割符号,
//linux和windows的文件分割符号是不一样的。
hdfsPath = GlobalConstants.HDFS_LOGS_PATH_PREFIX + File.separator + hdfsPath;
}
FileSystem fs = FileSystem.get(conf);
Path inPath = new Path(hdfsPath);
if(fs.exists(inPath)){
FileInputFormat.addInputPath(job, inPath);
}else{
throw new RuntimeException("HDFS中该文件目录不存在:" + hdfsPath);
}
}
/**
* 设置输出到HBase的一些操作选项
* @throws IOException
*/
private void initHBaseOutPutConfig(Job job) throws IOException{
Configuration conf = job.getConfiguration();
//获取要ETL的数据是哪一天
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
//格式化HBase后缀名
String tableNameSuffix = TimeUtil.parseLong2String(TimeUtil.parseString2Long(date), TimeUtil.HBASE_TABLE_NAME_SUFFIX_FORMAT);
//构建表名
String tableName = EventLogConstants.HBASE_NAME_EVENT_LOGS + tableNameSuffix;
//指定输出
TableMapReduceUtil.initTableReducerJob(tableName, null, job);
HBaseAdmin admin = null;
admin = new HBaseAdmin(conf);
TableName tn = TableName.valueOf(tableName);
HTableDescriptor htd = new HTableDescriptor(tn);
//设置列族
htd.addFamily(new HColumnDescriptor(EventLogConstants.EVENT_LOGS_FAMILY_NAME));
//判断表是否存在
if(admin.tableExists(tn)){
//存在,则删除
if(admin.isTableEnabled(tn)){
//将表设置为不可用
admin.disableTable(tn);
}
//删除表
admin.deleteTable(tn);
}
//创建表,在创建的过程中可以考虑预分区操作
//预分区 3个分区
//预分区的作用是rowkey在那个分区就往哪个分区里面落
// byte[][] keySplits = new byte[3][];
//(-∞, 1]
// keySplits[0] = Bytes.toBytes("1");
//(1, 2]
// keySplits[1] = Bytes.toBytes("2");
//(2, ∞]
// keySplits[2] = Bytes.toBytes("3");
// admin.createTable(htd, keySplits);
admin.createTable(htd);
admin.close();
}
//处理时间参数,如果没有传递参数的话,默认清洗前一天的。
/**
* Job脚本如下: bin/yarn jar ETL.jar com.z.transformer.mr.etl.AnalysisDataRunner -date 20170814
* @param args
*/
private void processArgs(Configuration conf, String[] args){
String date = null;
for(int i = 0; i < args.length; i++){
if("-date".equals(args[i])){
date = args[i+1];
break;
}
}
if(StringUtils.isBlank(date) || TimeUtil.isValidateRunningDate(date)){
//默认清洗昨天的数据到HBase
date = TimeUtil.getYesterday();
}
//将要清洗的目标时间字符串保存到conf对象中
conf.set(GlobalConstants.RUNNING_DATE_PARAMES, date);
}
}

如图上传需要分析的日志文件到hdfs,可以看到这里的日期是固定的,所以可以将代码中日期写死
然后这个eclipse是和hdfs在同一个linux服务器上的,可以直接运行
目标:读取HDFS中的数据,清洗后写入到HBase中
核心思路梳理:
Step1、创建AnalysisDataMapper类,复写map方法
Step2、在map方法中通过LoggerUtil.handleLogText方法将当前行数据解析成Map
Step3、获取当前行日志信息的事件类型,并根据获取到的事件类型去枚举类型中匹配生成EventEnum对象,如果没有匹配到对应的事件类型,则返回null。为什么会存在匹配不上的情况?访问的网站的前后端版本,等没有同步好,可能会出现这种情况。
根据网络请求中的en知道我们操作的是哪个网络时间
![]()
根据这个关键字匹配对应的枚举类型,封装成对应事件的对象
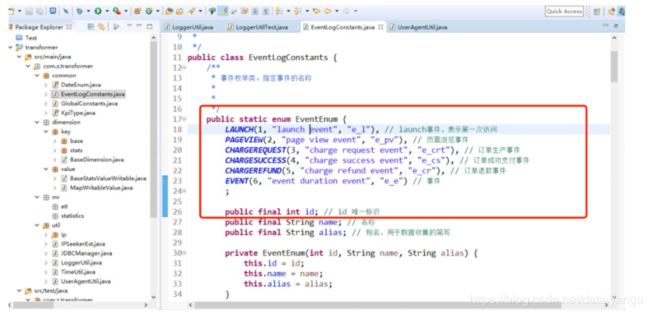
Step4、判断如果无法处理给定的事件类型,则使用log4j输出。
Step5、如果可以处理指定事件类型,则开始处理事件,创建handleEventData
(Map
Text value)方法处理事件。
Step6、在handleEventData方法中,我们需要过滤掉那些数据不合法的Event事件,通过
filterEventData(Map
方法过滤,规律规则:如果是java_server过来的数据,则会员id必须存在,如果是website过来的数据,则会话id和用户id必须存在。
就是说上面我们采集到的数据可能是从java后端采集过来的,也可能是从前端采集过来的。
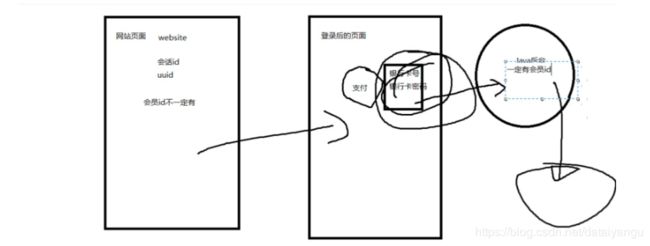
怎么判断数据是从哪里来的
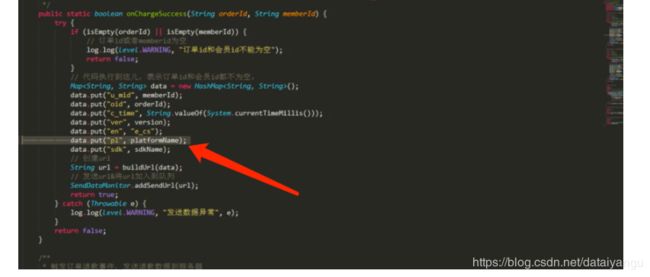
这个模拟的数据中有时按照javaserver的方式处理还是按照website的方式处理
AnalyticsEngineSDK .java 模拟数据的类
package com.z.logmake;
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;
import java.util.HashMap;
import java.util.Map;
import java.util.logging.Level;
import java.util.logging.Logger;
/**
* 分析引擎sdk java服务器端数据收集
*/
public class AnalyticsEngineSDK {
// 日志打印对象
private static final Logger log = Logger.getGlobal();
// 请求url的主体部分
public static final String accessUrl = "http://hadoop-senior01.itguigu.com/what.png";
private static final String platformName = "java_server";
private static final String sdkName = "jdk";
private static final String version = "1";
/**
* 触发订单支付成功事件,发送事件数据到服务器
*
* @param orderId
* 订单支付id
* @param memberId
* 订单支付会员id
* @return 如果发送数据成功(加入到发送队列中),那么返回true;否则返回false(参数异常&添加到发送队列失败).
*/
public static boolean onChargeSuccess(String orderId, String memberId) {
try {
if (isEmpty(orderId) || isEmpty(memberId)) {
// 订单id或者memberid为空
log.log(Level.WARNING, "订单id和会员id不能为空");
return false;
}
// 代码执行到这儿,表示订单id和会员id都不为空。
Map<String, String> data = new HashMap<String, String>();
data.put("u_mid", memberId);
data.put("oid", orderId);
data.put("c_time", String.valueOf(System.currentTimeMillis()));
data.put("ver", version);
data.put("en", "e_cs");
data.put("pl", platformName);
data.put("sdk", sdkName);
// 创建url
String url = buildUrl(data);
// 发送url&将url加入到队列
SendDataMonitor.addSendUrl(url);
return true;
} catch (Throwable e) {
log.log(Level.WARNING, "发送数据异常", e);
}
return false;
}
/**
* 触发订单退款事件,发送退款数据到服务器
*
* @param orderId
* 退款订单id
* @param memberId
* 退款会员id
* @return 如果发送数据成功,返回true。否则返回false。
*/
public static boolean onChargeRefund(String orderId, String memberId) {
try {
if (isEmpty(orderId) || isEmpty(memberId)) {
// 订单id或者memberid为空
log.log(Level.WARNING, "订单id和会员id不能为空");
return false;
}
// 代码执行到这儿,表示订单id和会员id都不为空。
Map<String, String> data = new HashMap<String, String>();
data.put("u_mid", memberId);
data.put("oid", orderId);
data.put("c_time", String.valueOf(System.currentTimeMillis()));
data.put("ver", version);
data.put("en", "e_cr");
data.put("pl", platformName);
data.put("sdk", sdkName);
// 构建url
String url = buildUrl(data);
// 发送url&将url添加到队列中
SendDataMonitor.addSendUrl(url);
return true;
} catch (Throwable e) {
log.log(Level.WARNING, "发送数据异常", e);
}
return false;
}
/**
* 根据传入的参数构建url
*
* @param data
* @return
* @throws UnsupportedEncodingException
*/
private static String buildUrl(Map<String, String> data) throws UnsupportedEncodingException {
StringBuilder sb = new StringBuilder();
sb.append(accessUrl).append("?");
for (Map.Entry<String, String> entry : data.entrySet()) {
if (isNotEmpty(entry.getKey()) && isNotEmpty(entry.getValue())) {
// key和value不为空
sb.append(entry.getKey().trim()).append("=").append(URLEncoder.encode(entry.getValue().trim(), "utf-8"))
.append("&");
// 解码
// URLDecoder.decode("需要解码的内容", "utf-8");
}
}
return sb.substring(0, sb.length() - 1);// 去掉最后&
}
/**
* 判断字符串是否为空,如果为空,返回true。否则返回false。
*
* @param value
* @return
*/
private static boolean isEmpty(String value) {
return value == null || value.trim().isEmpty();
}
/**
* 判断字符串是否非空,如果不是空,返回true。如果是空,返回false。
*
* @param value
* @return
*/
private static boolean isNotEmpty(String value) {
return !isEmpty(value);
}
}
Step7、如果没有通过过滤,则通过日志输出当前数据,如果通过过滤,则开始准备输出数据,创建方法outPutData
(Map
Step8、outputData方法中,我们可以删除一些无用的数据,比如浏览器信息的原始数据(因为已经解析过了)。同时需要创建一个生成rowkey的方法generateRowKey(String
uuid, long serverTime, Map
clientInfo),通过该方法生成的rowkey之后,添加内容到HBase表中。
Step9、generateRowKey方法主要用于rowKey的生成,通过拼接:时间+uuid的crc32编码+数据内容的hash码的crc32编码+作为rowkey,一共12个字节。
crc32是什么?是类似于MD5的东西。
18.4、测试
18.4.1、上传测试数据
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -mkdir -p /event-logs/2015/12/20
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/hdfs dfs -put ~/Desktop/20151220.log /event-logs/2015/12/20
18.4.2、打包集群运行
方案一:
修改etc/hadoop/hadoop-env.sh中的HADOOP_CLASSPATH配置信息
例如:
export
HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/*
方案二:
使用maven插件:maven-shade-plugin,将第三方依赖的jar全部打包进去
参数设置:
1、-P local clean package(不打包第三方jar)
2、-P dev clean package install(打包第三方jar)
尖叫提示:如果在打包的过程中org.apache.maven.plugins其中没有包含所依赖的jar包,则需要在HADOOP_CLASSPATH添加所需来的jar文件
例如:编写代码依赖了HBase,但是打包MR任务的时候,没有includeHBase的相关jar,则需要在hadoop-evn.sh中执行:
export
HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/*
执行的时候可能会报错
就是因为打jar包的时候没有把hbase的打进来,执行上面的export语句
最后执行
这里注意
不要做这个错误的例子,教程中,作者直接把windows上的项目传到了linux上,而没有import

任务运行成功之后,进入hbase进行查看


十九、创建数据库表
19.1、使用Navicat工具
前提:需要在Linux中对Mysql的访问授权。
grant all on *.* to root@'%' identified by '123456';
flush privileges;
exit;
雪花模型:
联合主键(primary key union )当一个主键无法表示一条数据的时候就需要联合主键表示

19.2、通过SQL文件构件表(详细见操作)
二十、业务数据分析
20.1、统计表
stats_user date_dimension_id
platform_dimension_id
new_install_users
stats_device_browser date_dimension_id
platform_dimension_id
browser_dimension_id
new_install_users
通过表结构可以发现,只要维度id确定了,那么new_install_users也就确定了。
思路梳理:
目标:统计新增用户
描述:未读信息+新增用户数
建表:dimension_browser dimension_date dimension_platform stats_device_browser stats_user
表结构描述:
stats_device_browser
日期维度
平台维度
浏览器维度
共同描述新增用户数
stats_user
日期维度
平台维度
共同描述新增用户数
业务:
总体描述:Hbase读取数据–》HbaseInputFormat–》Mapper–》reducer–》DBOutPutFormat–》直接写入到Mysql中
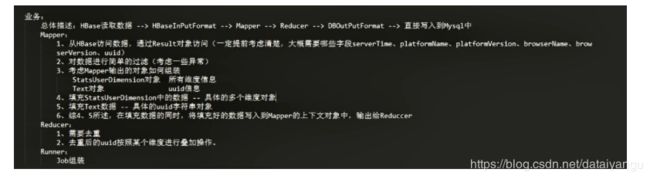
20.2、目标
按照不同维度统计新增用户。
20.3、代码实现
20.3.1、Mapper

Step1、创建NewInstallUsersMapper类,OutPutKey为StatsUserDimension,OutPutValue为Text。定义全局变量,Key和Value的对象
Step2、覆写map方法,在该方法中读取HBase中待处理的数据,分别要包含维度的字段信息以及必有的字段信息。serverTime、platformName、platformVersion、browserName、browserVersion、uuid
Step3、数据过滤以及时间字符串转换
Step4、构建维度信息:天维度,周维度,月维度,platform维度[(name,version)(name,all)(all,all)],browser维度[(browser,all)
(browser,version)]
Step5、设置outputValue的值为uuid
Step6、按照不同维度设置outputKey
相同的平台维度包括不同的浏览器维度,所以下面平台维度循环的时候里面执行了两次浏览器维度

NewInstallUsersMapper
package com.z.transformer.mr.statistics;
import java.io.IOException;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.log4j.Logger;
import com.z.transformer.common.DateEnum;
import com.z.transformer.common.EventLogConstants;
import com.z.transformer.common.GlobalConstants;
import com.z.transformer.common.KpiType;
import com.z.transformer.dimension.key.base.BrowserDimension;
import com.z.transformer.dimension.key.base.DateDimension;
import com.z.transformer.dimension.key.base.KpiDimension;
import com.z.transformer.dimension.key.base.PlatformDimension;
import com.z.transformer.dimension.key.stats.StatsCommonDimension;
import com.z.transformer.dimension.key.stats.StatsUserDimension;
import com.z.transformer.util.TimeUtil;
/**
* 思路:HBase读取数据 --> HBaseInPutFormat --> Mapper --> Reducer --> DBOutPutFormat --> 直接写入到Mysql中
*/
public class NewInstallUsersMapper extends TableMapper<StatsUserDimension, Text>{
private static final Logger logger = Logger.getLogger(NewInstallUsersMapper.class);
private byte[] family = EventLogConstants.BYTES_EVENT_LOGS_FAMILY_NAME;
//维度 key
private StatsUserDimension outputKey = new StatsUserDimension();
//将OutPutKey那个维度中存放的公共维度提取出来,方便后续组装的操作
private StatsCommonDimension statsCommonDimension = outputKey.getStatsCommon();
//定义时间变量
private long date, endOfDate;//描述当前天的起始时间和结束时间
private long firstThisWeekOfDate, endThisWeekOfDate;//传入日期所在周的起始和结束时间
private long firstThisMonthOfDate, firstDayOfNextMonth;//传入日期所在月的起始和结束时间
//创建Kpi指标
private KpiDimension newInstallUsersKpiDimension = new KpiDimension(KpiType.NEW_INSTALL_USER.name);
private KpiDimension browserNewInstallUsersKpiDimension = new KpiDimension(KpiType.BROWSER_NEW_INSTALL_USER.name);
//浏览器维度占位符
private BrowserDimension defaultBrowserDimension = new BrowserDimension("", "");
@Override
protected void setup(Mapper<ImmutableBytesWritable, Result, StatsUserDimension, Text>.Context context)
throws IOException, InterruptedException {
//1、配置对象初始化
Configuration conf = context.getConfiguration();
//2、提取传入的参数时间
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
//3、生成对应的时间戳
// date, endOfDate;//描述当前天的起始时间和结束时间
// private long firstThisWeekOfDate, endThisWeekOfDate;//传入日期所在周的起始和结束时间
// private long firstThisMonthOfDate, firstDayOfNextMonth;//传入日期所在月的起始和结束时间
//传入的时间的毫秒数,该参数是当天0点0分0秒的毫秒数
this.date = TimeUtil.parseString2Long(date);
this.endOfDate = this.date + GlobalConstants.DAY_OF_MILLISECONDS;
firstThisWeekOfDate = TimeUtil.getFirstDayOfThisWeek(this.date);
endThisWeekOfDate = TimeUtil.getFirstDayOfNextWeek(this.date);
firstThisMonthOfDate = TimeUtil.getFirstDayOfThisMonth(this.date);
firstDayOfNextMonth = TimeUtil.getFirstDayOfNextMonth(this.date);
}
//uuid value
private Text outputValue = new Text();
@Override
protected void map(ImmutableBytesWritable key,
Result value,
Mapper<ImmutableBytesWritable,
Result,
StatsUserDimension, Text>.Context context)
throws IOException, InterruptedException {
//1、读取HBase中的数据 serverTime、platformName、platformVersion、browserName、browserVersion、uuid
String serverTime = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME)));
String platformName = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_PLATFORM)));
String platformVersion = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_VERSION)));
String browserName = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME)));
String browserVersion = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION)));
String uuid = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_UUID)));
//5、设置输出的Value-uuid
this.outputValue.set(uuid);
//2、简单过滤,如果platform和uuid不存在,则数据无效
if(StringUtils.isBlank(platformName) || StringUtils.isBlank(uuid)){
logger.debug("服务器数据异常:" + platformName + "," + uuid);
return;
}
//3、数据过滤以及时间字符串转换
long longOfServerTime = 0L;
try {
longOfServerTime = Long.valueOf(serverTime);
} catch (Exception e) {
logger.debug("时间格式不正确:" + serverTime);
return;
}
//4、设置输出的Key-维度
//4.1、构建维度信息
DateDimension dayOfDimenssion = DateDimension.buildDate(longOfServerTime, DateEnum.DAY);
DateDimension weekOfDimenssion = DateDimension.buildDate(longOfServerTime, DateEnum.WEEK);
DateDimension monthOfDimenssion = DateDimension.buildDate(longOfServerTime, DateEnum.MONTH);
//4.2、构建platform维度
List<PlatformDimension> platforms = PlatformDimension.buildList(platformName, platformVersion);
//4.3、构建browser维度
List<BrowserDimension> browsers = BrowserDimension.buildList(browserName, browserVersion);
for(PlatformDimension pf : platforms){
//设置浏览器维度
this.outputKey.setBrowser(defaultBrowserDimension);
//设置platform维度
this.statsCommonDimension.setPlatform(pf);
//设置Kpi维度
this.statsCommonDimension.setKpi(this.newInstallUsersKpiDimension);
//开始设置时间维度
/*
* longOfServerTime:当前消息产生的服务器时间
* this.date:传入参数的时间
*/
if(longOfServerTime >= this.date && longOfServerTime < this.endOfDate){
//设置时间维度为分析当日
this.statsCommonDimension.setDate(dayOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisWeekOfDate && longOfServerTime < endThisWeekOfDate){
this.statsCommonDimension.setDate(weekOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisMonthOfDate && longOfServerTime < firstDayOfNextMonth){
this.statsCommonDimension.setDate(monthOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
//设置Kpi维度
this.statsCommonDimension.setKpi(this.browserNewInstallUsersKpiDimension);
for(BrowserDimension bd : browsers){
this.outputKey.setBrowser(bd);
//时间维度
if(longOfServerTime >= this.date && longOfServerTime < this.endOfDate){
//设置时间维度为分析当日
this.statsCommonDimension.setDate(dayOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisWeekOfDate && longOfServerTime < endThisWeekOfDate){
this.statsCommonDimension.setDate(weekOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisMonthOfDate && longOfServerTime < firstDayOfNextMonth){
this.statsCommonDimension.setDate(monthOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
}
}
// //6、输出数据
// context.write(outputKey, outputValue);
}
}
这里的mapper把各种维度相当于排列组合的方式封装到了rowkey中,传给reducer
20.3.2、Reducer
Step1、创建NewInstallUserReducer
Step2、统计uuid出现的次数,并且去重。
Step3、将数据拼装到outputValue中。
Step4、设置数据业务KPI类型,最终输出数据。
NewInstallUserReducer
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package com.z.transformer.mr.statistics;
import com.z.transformer.common.KpiType;
import com.z.transformer.dimension.key.stats.StatsUserDimension;
import com.z.transformer.dimension.value.MapWritableValue;
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class NewInstallUserReducer extends Reducer<StatsUserDimension, Text, StatsUserDimension, MapWritableValue> {
private Set<String> distinctUUIDSet = new HashSet();
private MapWritableValue outputValue = new MapWritableValue();
public NewInstallUserReducer() {
}
protected void reduce(StatsUserDimension key, Iterable<Text> values, Reducer<StatsUserDimension, Text, StatsUserDimension, MapWritableValue>.Context context) throws IOException, InterruptedException {
Iterator var5 = values.iterator();
//uuid去重
while(var5.hasNext()) {
Text text = (Text)var5.next();
this.distinctUUIDSet.add(text.toString());
}
//组装输出的value, mapWritableValue
MapWritable map = new MapWritable();
//map中键是1的值,value是uuid的个数
map.put(new IntWritable(1), new IntWritable(this.distinctUUIDSet.size()));
this.outputValue.setValue(map);
//设置outputvalue数据对应的描述的业务指标(kpi)
//为什么把kpi设置到outputvalue中?因为要输出到mysql
if (KpiType.BROWSER_NEW_INSTALL_USER.name.equals(key.getStatsCommon().getKpi().getKpiName())) {
this.outputValue.setKpi(KpiType.BROWSER_NEW_INSTALL_USER);
} else if (KpiType.NEW_INSTALL_USER.name.equals(key.getStatsCommon().getKpi().getKpiName())) {
this.outputValue.setKpi(KpiType.NEW_INSTALL_USER);
}
context.write(key, this.outputValue);
}
}
20.3.3、Runner
Step1、创建NewInstallUserRunner类,实现Tool接口
Step2、添加时间处理函数,用来截取参数
Step3、组装Job
Step4、设置HBase InputFormat(设置从HBase中读取的数据都有哪些)
Step5、自定义OutPutFormat并设置之
NewInstallUserRunner
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package com.z.transformer.mr.statistics;
import com.z.transformer.common.EventLogConstants;
import com.z.transformer.common.EventLogConstants.EventEnum;
import com.z.transformer.dimension.key.stats.StatsUserDimension;
import com.z.transformer.dimension.value.MapWritableValue;
import com.z.transformer.mr.TransformerMySQLOutputFormat;
import com.z.transformer.util.TimeUtil;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class NewInstallUserRunner implements Tool {
private Configuration conf = null;
public NewInstallUserRunner() {
}
public static void main(String[] args) {
try {
int status = ToolRunner.run(new NewInstallUserRunner(), args);
System.exit(status);
if (status == 0) {
System.out.println("运行成功");
} else {
System.out.println("运行失败");
}
} catch (Exception var2) {
System.out.println("运行失败");
var2.printStackTrace();
}
}
public void setConf(Configuration conf) {
this.conf = HBaseConfiguration.create(conf);
}
public Configuration getConf() {
return this.conf;
}
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
this.processArgs(conf, args);
Job job = Job.getInstance(conf);
job.setJarByClass(NewInstallUserRunner.class);
this.setHBaseInputConfig(job);
job.setReducerClass(NewInstallUserReducer.class);
job.setOutputKeyClass(StatsUserDimension.class);
job.setOutputValueClass(MapWritableValue.class);
job.setOutputFormatClass(TransformerMySQLOutputFormat.class);
return job.waitForCompletion(true) ? 0 : 1;
}
private void setHBaseInputConfig(Job job) {
Configuration conf = job.getConfiguration();
String dateStr = conf.get("RUNNING_DATE");
List<Scan> scans = new ArrayList();
FilterList filterList = new FilterList(new Filter[0]);
filterList.addFilter(new SingleColumnValueFilter(EventLogConstants.BYTES_EVENT_LOGS_FAMILY_NAME, Bytes.toBytes("en"), CompareOp.EQUAL, Bytes.toBytes(EventEnum.LAUNCH.alias)));
String[] var10000 = new String[]{"pl", "ver", "browser", "browser_v", "s_time", "u_ud", "en"};
//4访问Habase数值
//这块代 码的意思是,假如当前日期是七月十九日,lastdayofweek是23
//lastdayofmonth是31,如果当前的时间大于其中的任意一者的话,取这两者中的最大的,就是31,
//firstDayOfWeek,firstDayOfMonth 17和1,取小的就是1
//所以这里取得就是七月整个月的指标
//传入参数的时间毫秒数:当天起始时间
long date = TimeUtil.parseString2Long(dateStr);
//传入参数当天的最后时刻,当天结束时间
long endOfDate = date + 86400000L;
long firstDayOfWeek = TimeUtil.getFirstDayOfThisWeek(date);
long lastDayOfWeek = TimeUtil.getFirstDayOfNextWeek(date);
long firstDayOfMonth = TimeUtil.getFirstDayOfThisMonth(date);
long lastDayOfMonth = TimeUtil.getFirstDayOfNextMonth(date);
//TimeUtil.getTodayMills返回系统当天时间0点0纷纷0秒毫秒数:
//执行代码是,系统的当前时间
long startDate = Math.min(firstDayOfWeek, firstDayOfMonth);
long endDate = TimeUtil.getTodayInMillis() + 86400000L;
if (endDate <= lastDayOfWeek && endDate <= lastDayOfMonth) {
endDate = endOfDate;
} else {
endDate = Math.max(lastDayOfMonth, lastDayOfWeek);
}
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(conf);
//要构建多张表,所以构建多个scan对象
for(long begin = startDate; begin < endDate; begin += 86400000L) {
String tableNameSuffix = TimeUtil.parseLong2String(begin, "yyyyMMdd");
String tableName = "event-logs" + tableNameSuffix;
if (admin.tableExists(Bytes.toBytes(tableName))) {
Scan scan = new Scan();
scan.setAttribute("scan.attributes.table.name", Bytes.toBytes(tableName));
scan.setFilter(filterList);
scans.add(scan);
}
}
//访问hbase中的数据
if (scans.isEmpty()) {
throw new RuntimeException("没有找到任何对应的数据!");
}
//注意这里,如果是在windows上的话,参数最后加一个false,
//如果是false的话,意思是不把hbase里面所依赖的jar包,弄到里面运行
//如果打成jar包,在集群上运行的话,这里必须是true,这里默认也是true
//
//TableMapReduceUtil.initTableMapperJob(scans, NewInstallUsersMapper.class, StatsUserDimension.class, MapWritableValue.class, job,false);
TableMapReduceUtil.initTableMapperJob(scans, NewInstallUsersMapper.class, StatsUserDimension.class, MapWritableValue.class, job);
} catch (IOException var37) {
var37.printStackTrace();
} finally {
try {
admin.close();
} catch (IOException var36) {
var36.printStackTrace();
}
}
}
private void processArgs(Configuration conf, String[] args) {
String date = null;
for(int i = 0; i < args.length; ++i) {
if ("-date".equals(args[i])) {
date = args[i + 1];
break;
}
}
if (StringUtils.isBlank(date) || TimeUtil.isValidateRunningDate(date)) {
date = TimeUtil.getYesterday();
}
conf.set("RUNNING_DATE", date);
}
}
20.3.4、测试:NewInstvavallUsers
Maven打包参数:-P dev clean package install
Hadoop环境依赖导入:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/*
提交运行:
/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin/yarn jar ~/Desktop/transformer-0.0.1-SNAPSHOT.jar com.z.transformer.mr.statistics.NewInstallUserRunner -date 2015-12-20
二十一、Hive之Hourly分析
21.1、目标
分析一天24个时间段的新增用户、活跃用户、会话个数和会话长度四个指标,最终将结果保存到HDFS中,使用sqoop导出到Mysql。
21.2、目标解析
新增用户:分析launch事件中各个不同时间段的uuid数量
活跃用户:分析pageview事件中各个不同时间段的uuid数量
会话个数:分析pageview事件中各个不同时间段的会话id数量
会话长度:分析pageview事件中各个不同时间段内所有会话时长的总和
21.3、创建Mysql结果表
21.4、Hive分析
21.4.1、创建Hive外部表关联HBase数据表
create external table
event_logs20151220(
key string,
pl string,
ver string,
en string,
u_ud string,
u_sd string,
s_time bigint)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping" = ":key, info:pl,info:ver,info:en,info:u_ud,info:u_sd,info:s_time")
tblproperties("hbase.table.name" = "event_logs20151220");
21.4.2、创建临时表用于存放pageview和launch事件的数据(即存放过滤数据)
create table stats_hourly_tmp1(pl string, ver string, en string, s_time bigint, u_ud string, u_sd string, hour int, date string) row format delimited fields terminated by '\t';;
21.4.3、提取e_pv和e_l事件数据到临时表中
from event_logs20151220
insert overwrite table stats_hourly_tmp1
select
pl,ver,
en,
s_time,
u_ud,
u_sd,
hour(from_unixtime(cast(s_time/1000 as int), 'yyyy-MM-dd HH:mm:ss')),
from_unixtime(cast(s_time/1000 as int), 'yyyy-MM-dd')
where en = 'e_pv' or en = 'e_l';
21.4.4、创建分析结果临时保存表
create table stats_hourly_tmp2(pl string, ver string, date string,hour int, kpi string, value int) row format delimited fields terminated by '\t';;
21.4.5、分析活跃访客数
Step1、具体平台,具体平台版本(platform:name, version:version)
from stats_hourly_tmp1
insert overwrite table stats_hourly_tmp2
select
pl,
ver,
date,
hour,
'active_users',
count(distinct u_ud) as active_users
where
en = 'e_pv'
group by
pl,
ver,
date,
hour;
Step2、具体平台,所有版本(platform:name, version:all)
from stats_hourly_tmp1
insert into table stats_hourly_tmp2
select
pl,
'all',
date,
hour,
'active_users',
count(distinct u_ud) as active_users
where en = 'e_pv'
group by
pl,
date,
hour;
Step3、所有平台,所有版本(platform:all, version:all)
from stats_hourly_tmp1
insert into table stats_hourly_tmp2
select
'all',
'all',
date,
hour,
'active_users',
count(distinct u_ud) as active_users
where en = 'e_pv'
group by
date,
hour;
21.4.6、分析会话长度
将每个会话的长度先要计算出来,然后统计一个时间段的各个会话的总和
Step1、具体平台,具体平台版本(platform:name, version:version)
from (
select
pl,ver,
date,
hour,
u_sd,
(max(s_time) - min(s_time)) as s_length
from
stats_hourly_tmp1
where en='e_pv'
group by
pl,ver,
date,
u_sd,
hour
) as tmp
insert into table stats_hourly_tmp2
select
pl,
ver,
date,
hour,
'sessions_lengths',
cast(sum(s_length) / 1000 as int)
group by
pl,
ver,
date,
hour;
Step2、具体平台,所有版本(platform:name, version:all)
from (
select
pl,
date,
hour,
u_sd,
(max(s_time) - min(s_time)) as s_length
from
stats_hourly_tmp1
where en='e_pv'
group by
pl,
date,
u_sd,
hour
) as tmp
insert into table stats_hourly_tmp2
select
pl,
'all',
date,
hour,
'sessions_lengths',
cast(sum(s_length) / 1000 as int)
group by
pl,
date,
hour;
Step3、所有平台,所有版本(platform:all, version:all)
from (
select
date,
hour,
u_sd,
(max(s_time) - min(s_time)) as s_length
from
stats_hourly_tmp1
where en='e_pv'
group by
date,
u_sd,
hour
) as tmp
insert into table stats_hourly_tmp2
select
'all',
'all',
date,
hour,
'sessions_lengths',
cast(sum(s_length) / 1000 as int)
group by
date,
hour;
21.4.7、创建最终结果表
我们在这里需要创建一个和Mysql表结构一致的Hive表,便于后期使用Sqoop导出数据到Mysql中。
create table stats_hourly(
platform_dimension_id int,
date_dimension_id int,
kpi_dimension_id int,
hour_00 int,
hour_01 int,
hour_02 int,
hour_03 int,
hour_04 int,
hour_05 int,
hour_06 int,
hour_07 int,
hour_08 int,
hour_09 int,
hour_10 int,
hour_11 int,
hour_12 int,
hour_13 int,
hour_14 int,
hour_15 int,
hour_16 int,
hour_17 int,
hour_18 int,
hour_19 int,
hour_20 int,
hour_21 int,
hour_22 int,
hour_23 int
) row format delimited fields terminated by '\t';
21.4.8、向结果表中插入数据
我们需要platform_dimension_id int, date_dimension_id int,
kpi_dimension_id int三个字段,所以我们需要使用UDF函数生成对应的字段。
Step1、编写UDF函数,见代码
Step2、编译打包UDF函数代码
编译参数:-P dev clean package install
导入HBase依赖:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/*
Step3、上传UDF代码jar包到HDFS
$ bin/hadoop fs -mkdir -p /event_logs/
$ bin/hadoop fs -mv /event-logs/* /event_logs/
尖叫提示:记得修改Flume的HDFS SINK路径以及手动上传脚本命令
$ bin/hadoop fs -rm -r /event-logs/
上传脚本:
$ bin/hadoop fs -mkdir -p /udf_jar/transformer
$ bin/hadoop fs -put ~/Desktop/transformer-0.0.1-SNAPSHOT.jar /udf_jar/transformer
Step4、使用UDF的jar
create function date_converter as 'com.z.transformer.udf.DateDimensionConverterUDF' using jar 'hdfs://hadoop-senior01.itguigu.com:8020/udf_jar/transformer/transformer-0.0.1-SNAPSHOT.jar';
create function kpi_converter as 'com.z.transformer.udf.KpiDimensionConverterUDF' using jar 'hdfs://hadoop-senior01.itguigu.com:8020/udf_jar/transformer/transformer-0.0.1-SNAPSHOT.jar';
create function platform_converter as 'com.z.transformer.udf.PlatformDimensionConverterUDF' using jar 'hdfs://hadoop-senior01.itguigu.com:8020/udf_jar/transformer/transformer-0.0.1-SNAPSHOT.jar';
Step5、执行最终数据统计
insert overwrite table stats_hourly
select
default.platform_converter(pl,ver),
default.date_converter(date,'day'),
default.kpi_converter(kpi),
max(case when hour=0 then value else 0 end) as hour_00,
max(case when hour=1 then value else 0 end) as hour_01,
max(case when hour=2 then value else 0 end) as hour_02,
max(case when hour=3 then value else 0 end) as hour_03,
max(case when hour=4 then value else 0 end) as hour_04,
max(case when hour=5 then value else 0 end) as hour_05,
max(case when hour=6 then value else 0 end) as hour_06,
max(case when hour=7 then value else 0 end) as hour_07,
max(case when hour=8 then value else 0 end) as hour_08,
max(case when hour=9 then value else 0 end) as hour_09,
max(case when hour=10 then value else 0 end) as hour_10,
max(case when hour=11 then value else 0 end) as hour_11,
max(case when hour=12 then value else 0 end) as hour_12,
max(case when hour=13 then value else 0 end) as hour_13,
max(case when hour=14 then value else 0 end) as hour_14,
max(case when hour=15 then value else 0 end) as hour_15,
max(case when hour=16 then value else 0 end) as hour_16,
max(case when hour=17 then value else 0 end) as hour_17,
max(case when hour=18 then value else 0 end) as hour_18,
max(case when hour=19 then value else 0 end) as hour_19,
max(case when hour=20 then value else 0 end) as hour_20,
max(case when hour=21 then value else 0 end) as hour_21,
max(case when hour=22 then value else 0 end) as hour_22,
max(case when hour=23 then value else 0 end) as hour_23
from stats_hourly_tmp2 group by pl,ver,date,kpi;
21.4.9、使用Sqoop导出 数据到Mysql,观察数据
$ bin/sqoop export --connect jdbc:mysql://hadoop-senior01.itguigu.com:3306/report
--username root
--password 123456
--table stats_hourly
--num-mappers 1
--export-dir /user/hive/warehouse/stats_hourly
--input-fields-terminated-by "\t"
通过jdbc直接写入到mysql中
上面通过hdfs+scoop加长了时间的周期,这里直接通过jdbc写入到mysql中
NewInstallUserMapper
package com.z.transformer.mr.statistics;
import java.io.IOException;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.log4j.Logger;
import com.z.transformer.common.DateEnum;
import com.z.transformer.common.EventLogConstants;
import com.z.transformer.common.GlobalConstants;
import com.z.transformer.common.KpiType;
import com.z.transformer.dimension.key.base.BrowserDimension;
import com.z.transformer.dimension.key.base.DateDimension;
import com.z.transformer.dimension.key.base.KpiDimension;
import com.z.transformer.dimension.key.base.PlatformDimension;
import com.z.transformer.dimension.key.stats.StatsCommonDimension;
import com.z.transformer.dimension.key.stats.StatsUserDimension;
import com.z.transformer.util.TimeUtil;
/**
* 思路:HBase读取数据 --> HBaseInPutFormat --> Mapper --> Reducer --> DBOutPutFormat --> 直接写入到Mysql中
*/
public class NewInstallUsersMapper extends TableMapper<StatsUserDimension, Text>{
private static final Logger logger = Logger.getLogger(NewInstallUsersMapper.class);
private byte[] family = EventLogConstants.BYTES_EVENT_LOGS_FAMILY_NAME;
//维度 key
private StatsUserDimension outputKey = new StatsUserDimension();
//将OutPutKey那个维度中存放的公共维度提取出来,方便后续组装的操作
private StatsCommonDimension statsCommonDimension = outputKey.getStatsCommon();
//定义时间变量
private long date, endOfDate;//描述当前天的起始时间和结束时间
private long firstThisWeekOfDate, endThisWeekOfDate;//传入日期所在周的起始和结束时间
private long firstThisMonthOfDate, firstDayOfNextMonth;//传入日期所在月的起始和结束时间
//创建Kpi指标
private KpiDimension newInstallUsersKpiDimension = new KpiDimension(KpiType.NEW_INSTALL_USER.name);
private KpiDimension browserNewInstallUsersKpiDimension = new KpiDimension(KpiType.BROWSER_NEW_INSTALL_USER.name);
//浏览器维度占位符
private BrowserDimension defaultBrowserDimension = new BrowserDimension("", "");
@Override
protected void setup(Mapper<ImmutableBytesWritable, Result, StatsUserDimension, Text>.Context context)
throws IOException, InterruptedException {
//1、配置对象初始化
Configuration conf = context.getConfiguration();
//2、提取传入的参数时间
String date = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
//3、生成对应的时间戳
// date, endOfDate;//描述当前天的起始时间和结束时间
// private long firstThisWeekOfDate, endThisWeekOfDate;//传入日期所在周的起始和结束时间
// private long firstThisMonthOfDate, firstDayOfNextMonth;//传入日期所在月的起始和结束时间
//传入的时间的毫秒数,该参数是当天0点0分0秒的毫秒数
this.date = TimeUtil.parseString2Long(date);
this.endOfDate = this.date + GlobalConstants.DAY_OF_MILLISECONDS;
firstThisWeekOfDate = TimeUtil.getFirstDayOfThisWeek(this.date);
endThisWeekOfDate = TimeUtil.getFirstDayOfNextWeek(this.date);
firstThisMonthOfDate = TimeUtil.getFirstDayOfThisMonth(this.date);
firstDayOfNextMonth = TimeUtil.getFirstDayOfNextMonth(this.date);
}
//uuid value
private Text outputValue = new Text();
//reduce的作用就是将清洗后的数据按照不同的维度聚合
@Override
protected void map(ImmutableBytesWritable key,
Result value,
Mapper<ImmutableBytesWritable,
Result,
StatsUserDimension, Text>.Context context)
throws IOException, InterruptedException {
//1、读取HBase中的数据 serverTime、platformName、platformVersion、browserName、browserVersion、uuid
String serverTime = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME)));
String platformName = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_PLATFORM)));
String platformVersion = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_VERSION)));
String browserName = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME)));
String browserVersion = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION)));
String uuid = Bytes.toString(value.getValue(family, Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_UUID)));
//5、设置输出的Value-uuid
this.outputValue.set(uuid);
//2、简单过滤,如果platform和uuid不存在,则数据无效
//我们这里就是做用户人数的统计,如果连uuid都没有,怎么统计?
if(StringUtils.isBlank(platformName) || StringUtils.isBlank(uuid)){
logger.debug("服务器数据异常:" + platformName + "," + uuid);
return;
}
//3、数据过滤以及时间字符串转换
long longOfServerTime = 0L;
try {
longOfServerTime = Long.valueOf(serverTime);
} catch (Exception e) {
logger.debug("时间格式不正确:" + serverTime);
return;
}
//4、设置输出的Key-维度
//4.1、构建维度信息
DateDimension dayOfDimenssion = DateDimension.buildDate(longOfServerTime, DateEnum.DAY);
DateDimension weekOfDimenssion = DateDimension.buildDate(longOfServerTime, DateEnum.WEEK);
DateDimension monthOfDimenssion = DateDimension.buildDate(longOfServerTime, DateEnum.MONTH);
//4.2、构建platform维度
List<PlatformDimension> platforms = PlatformDimension.buildList(platformName, platformVersion);
//4.3、构建browser维度
List<BrowserDimension> browsers = BrowserDimension.buildList(browserName, browserVersion);
for(PlatformDimension pf : platforms){
//设置浏览器维度
this.outputKey.setBrowser(defaultBrowserDimension);
//设置platform维度
this.statsCommonDimension.setPlatform(pf);
//设置Kpi维度
this.statsCommonDimension.setKpi(this.newInstallUsersKpiDimension);
//开始设置时间维度
/*
* longOfServerTime:当前消息产生的服务器时间
* this.date:传入参数的时间
*/
if(longOfServerTime >= this.date && longOfServerTime < this.endOfDate){
//设置时间维度为分析当日
this.statsCommonDimension.setDate(dayOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisWeekOfDate && longOfServerTime < endThisWeekOfDate){
this.statsCommonDimension.setDate(weekOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisMonthOfDate && longOfServerTime < firstDayOfNextMonth){
this.statsCommonDimension.setDate(monthOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
//设置Kpi维度
this.statsCommonDimension.setKpi(this.browserNewInstallUsersKpiDimension);
for(BrowserDimension bd : browsers){
this.outputKey.setBrowser(bd);
//时间维度
if(longOfServerTime >= this.date && longOfServerTime < this.endOfDate){
//设置时间维度为分析当日
this.statsCommonDimension.setDate(dayOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisWeekOfDate && longOfServerTime < endThisWeekOfDate){
this.statsCommonDimension.setDate(weekOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
if(longOfServerTime >= firstThisMonthOfDate && longOfServerTime < firstDayOfNextMonth){
this.statsCommonDimension.setDate(monthOfDimenssion);
context.write(this.outputKey, this.outputValue);
}
}
}
// //6、输出数据
// context.write(outputKey, outputValue);
}
}
NewInstallUserRunner
package com.z.transformer.mr.statistics;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import com.z.transformer.common.EventLogConstants;
import com.z.transformer.common.GlobalConstants;
import com.z.transformer.common.EventLogConstants.EventEnum;
import com.z.transformer.dimension.key.stats.StatsUserDimension;
import com.z.transformer.dimension.value.MapWritableValue;
import com.z.transformer.mr.TransformerMySQLOutputFormat;
import com.z.transformer.util.TimeUtil;
public class NewInstallUserRunner implements Tool {
private Configuration conf = null;
public static void main(String[] args) {
try {
int status = ToolRunner.run(new NewInstallUserRunner(), args);
System.exit(status);
if(status == 0){
System.out.println("运行成功");
}else {
System.out.println("运行失败");
}
} catch (Exception e) {
System.out.println("运行失败");
e.printStackTrace();
}
}
@Override
public void setConf(Configuration conf) {
this.conf = HBaseConfiguration.create(conf);
}
@Override
public Configuration getConf() {
return this.conf;
}
@Override
public int run(String[] args) throws Exception {
//1、得到conf对象
Configuration conf = this.getConf();
this.processArgs(conf, args);
//2、创建Job
Job job = Job.getInstance(conf);
job.setJarByClass(NewInstallUserRunner.class);
//3、Mapper设置HBase的Mapper
this.setHBaseInputConfig(job);
//4、设置Reducer
job.setReducerClass(NewInstallUserReducer.class);
job.setOutputKeyClass(StatsUserDimension.class);
job.setOutputValueClass(MapWritableValue.class);
//5、设置job的输出
job.setOutputFormatClass(TransformerMySQLOutputFormat.class);
return job.waitForCompletion(true) ? 0 : 1;
}
/**
* 初始化HBase Mapper
*/
private void setHBaseInputConfig(Job job){
Configuration conf = job.getConfiguration();
String dateStr = conf.get(GlobalConstants.RUNNING_DATE_PARAMES);
List<Scan> scans = new ArrayList<>();
//1、构建Filter
FilterList filterList = new FilterList();
//2、构建过滤:只需要返回HBase表中Launch事件所代表的数据 en = e_l
//因为当前的任务是统计新增用户的任务,所以这里只拦截lanch事件
filterList.addFilter(new SingleColumnValueFilter(
EventLogConstants.BYTES_EVENT_LOGS_FAMILY_NAME,
Bytes.toBytes(EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME),
CompareOp.EQUAL,
Bytes.toBytes(EventEnum.LAUNCH.alias)));
//3、构建其他过滤规则,一会需要添加到Filter中
String[] columns = new String[]{
EventLogConstants.LOG_COLUMN_NAME_PLATFORM,//平台名称
EventLogConstants.LOG_COLUMN_NAME_VERSION,//平台版本
EventLogConstants.LOG_COLUMN_NAME_BROWSER_NAME,//浏览器名称
EventLogConstants.LOG_COLUMN_NAME_BROWSER_VERSION,//浏览器版本
EventLogConstants.LOG_COLUMN_NAME_SERVER_TIME,//服务器时间
EventLogConstants.LOG_COLUMN_NAME_UUID,//uuid 访客唯一标识符
EventLogConstants.LOG_COLUMN_NAME_EVENT_NAME,//事件名称
};
//4、访问HBase数据
long startDate, endDate;//scan表区间范围
//传入参数的时间毫秒数:当天起始时间
long date = TimeUtil.parseString2Long(dateStr);
//传如参数当天的最后时刻:当天结束时间
long endOfDate = date + GlobalConstants.DAY_OF_MILLISECONDS;
long firstDayOfWeek = TimeUtil.getFirstDayOfThisWeek(date);
long lastDayOfWeek = TimeUtil.getFirstDayOfNextWeek(date);
long firstDayOfMonth = TimeUtil.getFirstDayOfThisMonth(date);
long lastDayOfMonth = TimeUtil.getFirstDayOfNextMonth(date);
//TimeUtil.getTodayInMills返回系统当天时间0点0分0秒毫秒数:执行代码时,系统的当前时间
startDate = Math.min(firstDayOfWeek, firstDayOfMonth);
endDate = TimeUtil.getTodayInMillis() + GlobalConstants.DAY_OF_MILLISECONDS;
if(endDate > lastDayOfWeek || endDate > lastDayOfMonth){
endDate = Math.max(lastDayOfMonth, lastDayOfWeek);
}else{
endDate = endOfDate;
}
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(conf);
//构建Scan对象
for(long begin = startDate; begin < endDate; begin += GlobalConstants.DAY_OF_MILLISECONDS){
//表名组成:tablename = event-logs20170816
//拼接出来的结果是:20170816
String tableNameSuffix = TimeUtil.parseLong2String(begin, TimeUtil.HBASE_TABLE_NAME_SUFFIX_FORMAT);
String tableName = EventLogConstants.HBASE_NAME_EVENT_LOGS + tableNameSuffix;
//表是否存在
if (admin.tableExists(Bytes.toBytes(tableName))) {
Scan scan = new Scan();
scan.setAttribute(Scan.SCAN_ATTRIBUTES_TABLE_NAME, Bytes.toBytes(tableName));
//直接把filter放到scan对象里面,扫描表的时候,通过这个scan对象进行扫描
scan.setFilter(filterList);
scans.add(scan);
}
}
//访问HBase中的表中的数据
if(scans.isEmpty()){
throw new RuntimeException("没有找到任何对应的数据!");
}
TableMapReduceUtil.initTableMapperJob(
scans,
NewInstallUsersMapper.class,
StatsUserDimension.class,
MapWritableValue.class,
job);
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* Job脚本如下: bin/yarn jar ETL.jar com.z.transformer.mr.etl.AnalysisDataRunner -date 2017-08-14
*/
private void processArgs(Configuration conf, String[] args) {
String date = null;
for (int i = 0; i < args.length; i++) {
if ("-date".equals(args[i])) {
date = args[i + 1];
break;
}
}
if(StringUtils.isBlank(date) || TimeUtil.isValidateRunningDate(date)){
//默认清洗昨天的数据到HBase
date = TimeUtil.getYesterday();
}
//将要清洗的目标时间字符串保存到conf对象中
conf.set(GlobalConstants.RUNNING_DATE_PARAMES, date);
}
}
BaseDimension
package com.z.transformer.dimension.key;
import org.apache.hadoop.io.WritableComparable;
/**
* 维度信息类的基类
* 所有输出到mysql数据库中的自定义MR任务的自定义key均需要实现自该抽象类
*
* @author Jinji
*
*/
public abstract class BaseDimension implements WritableComparable<BaseDimension> {
// nothings
}
StatsDimension
package com.z.transformer.dimension.key.stats;
import com.z.transformer.dimension.key.BaseDimension;
/**
* 组合维度类的基类
*
* @author Jinji
*
*/
public abstract class StatsDimension extends BaseDimension {
}
StatsUserDimension
package com.z.transformer.dimension.key.stats;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import com.z.transformer.dimension.key.BaseDimension;
import com.z.transformer.dimension.key.base.BrowserDimension;
/**
* 进行用户分析(用户基本分析和浏览器分析)定义的组合维度
*
* @author Jinji
*
*/
public class StatsUserDimension extends StatsDimension {
/**
* 公用维度对象
*/
private StatsCommonDimension statsCommon = new StatsCommonDimension();
/**
* 浏览器维度对象
*/
private BrowserDimension browser = new BrowserDimension();
/**
* 依照一个已有对象克隆出一个新的组合维度对象
*
* @param dimension
* @return
*/
public static StatsUserDimension clone(StatsUserDimension dimension) {
/**
* 创建一个浏览器维度对象
*/
BrowserDimension browser = new BrowserDimension(dimension.browser.getBrowser(),
dimension.browser.getBrowserVersion());
/**
* clone一个新的StatsCommonDimension组合类对象
*/
StatsCommonDimension statsCommon = StatsCommonDimension.clone(dimension.statsCommon);
// 新建对象
return new StatsUserDimension(statsCommon, browser);
}
/**
* 无参构造方法,必须给定
*/
public StatsUserDimension() {
super();
}
/**
* 给定全部参数的构造方法
*
* @param statsCommon
* stats基本组合维度
* @param browser
* 浏览器维度
*/
public StatsUserDimension(StatsCommonDimension statsCommon, BrowserDimension browser) {
super();
this.statsCommon = statsCommon;
this.browser = browser;
}
public StatsCommonDimension getStatsCommon() {
return statsCommon;
}
public void setStatsCommon(StatsCommonDimension statsCommon) {
this.statsCommon = statsCommon;
}
public BrowserDimension getBrowser() {
return browser;
}
public void setBrowser(BrowserDimension browser) {
this.browser = browser;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((browser == null) ? 0 : browser.hashCode());
result = prime * result + ((statsCommon == null) ? 0 : statsCommon.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
StatsUserDimension other = (StatsUserDimension) obj;
if (browser == null) {
if (other.browser != null)
return false;
} else if (!browser.equals(other.browser))
return false;
if (statsCommon == null) {
if (other.statsCommon != null)
return false;
} else if (!statsCommon.equals(other.statsCommon))
return false;
return true;
}
public void write(DataOutput out) throws IOException {
this.statsCommon.write(out);
this.browser.write(out);
}
public void readFields(DataInput in) throws IOException {
this.statsCommon.readFields(in);
this.browser.readFields(in);
}
public int compareTo(BaseDimension o) {
if (this == o) {
return 0;
}
StatsUserDimension other = (StatsUserDimension) o;
int tmp = this.statsCommon.compareTo(other.statsCommon);
if (tmp != 0) {
return tmp;
}
tmp = this.browser.compareTo(other.browser);
return tmp;
}
}
TransformerMySQLOutputFormat
package com.z.transformer.mr;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.OutputCommitter;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.z.transformer.common.GlobalConstants;
import com.z.transformer.common.KpiType;
import com.z.transformer.converter.IDimensionConverter;
import com.z.transformer.converter.impl.DimensionConverterImpl;
import com.z.transformer.dimension.key.BaseDimension;
import com.z.transformer.dimension.value.BaseStatsValueWritable;
import com.z.transformer.util.JDBCManager;
public class TransformerMySQLOutputFormat extends OutputFormat<BaseDimension, BaseStatsValueWritable> {
@Override
public RecordWriter<BaseDimension, BaseStatsValueWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
// 构建属于当前outputforamt的数据输出器
// 1. 获取上下文
Configuration conf = context.getConfiguration();
// 2. 创建jdbc连接
Connection conn = null;
try {
// 根据上下文中配置的信息获取数据库连接
// 需要在hadoop的configuration中配置mysql的驱动连接信息
conn = JDBCManager.getConnection(conf, GlobalConstants.WAREHOUSE_OF_REPORT);
conn.setAutoCommit(false); // 关闭自动提交机制,方便我们进行批量提交
} catch (SQLException e) {
throw new IOException(e);
}
// 3. 构建对象并返回
return new TransformerRecordWriter(conf, conn);
}
@Override
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {
// 该方法的主要作用是检测输出空间的相关属性,比如是否存在之类的情况
// 如果说job运行前提的必须条件不满足,直接抛出一个exception。
}
@Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
// 使用的是FileOutputFormat中默认的方式
String name = context.getConfiguration().get(FileOutputFormat.OUTDIR);
Path output = name == null ? null : new Path(name);
return new FileOutputCommitter(output, context);
}
/**
* 自定义的具体将reducer输出数据输出到mysql表的输出器
*/
static class TransformerRecordWriter extends RecordWriter<BaseDimension, BaseStatsValueWritable> {
private Connection conn = null; // 数据库连接
private Configuration conf = null; // 上下文保存成属性
private Map<KpiType, PreparedStatement> pstmtMap = new HashMap<KpiType, PreparedStatement>();
private int batchNumber = 0; // 批量提交数据大小
private Map<KpiType, Integer> batch = new HashMap<KpiType, Integer>();
private IDimensionConverter converter = null; // 维度转换对象
/**
* 构造方法
*
* @param conf
* @param conn
*/
public TransformerRecordWriter(Configuration conf, Connection conn) {
this.conf = conf;
this.conn = conn;
this.batchNumber = Integer.valueOf(conf.get(GlobalConstants.JDBC_BATCH_NUMBER, GlobalConstants.DEFAULT_JDBC_BATCH_NUMBER));
this.converter = new DimensionConverterImpl();
}
@Override
public void write(BaseDimension key, BaseStatsValueWritable value) throws IOException, InterruptedException {
try {
// 每个分析的kpi值是不一样的,一样的kpi有一样的插入sql语句
KpiType kpi = value.getKpi();
int count = 0; // count表示当前PreparedStatement对象中需要提交的记录数量
// 1. 获取数据库的PreparedStatement对象
// 从上下文中获取kpi对应的sql语句
String sql = this.conf.get(kpi.name);
PreparedStatement pstmt = null;
// 判断当前kpi对应的preparedstatment对象是否存在
if (this.pstmtMap.containsKey(kpi)) {
// 存在
pstmt = this.pstmtMap.get(kpi); // 获取对应的对象
if (batch.containsKey(kpi)) {
count = batch.get(kpi);
}
} else {
// 不存在, 第一次创建一个对象
pstmt = conn.prepareStatement(sql);
// 保存到map集合中
this.pstmtMap.put(kpi, pstmt);
}
// 2. 获取collector类名称
String collectorClassName = this.conf.get(GlobalConstants.OUTPUT_COLLECTOR_KEY_PREFIX + kpi.name);
// 3. 创建class对象
Class<?> clz = Class.forName(collectorClassName); // 获取类对象
// 调用newInstance方法进行构成对象,要求具体的实现子类有默认无参构造方法
ICollector collector = (ICollector) clz.newInstance();
// 4. 设值参数
collector.collect(conf, key, value, pstmt, converter);
// 5. 处理完成后,进行累计操作
count++;
this.batch.put(kpi, count);
// 6. 执行,采用批量提交的方式
if (count > this.batchNumber) {
pstmt.executeBatch(); // 批量提交
conn.commit(); // 连接提交
this.batch.put(kpi, 0); // 恢复数据
}
} catch (Exception e) {
throw new IOException(e);
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
// 关闭资源
try {
// 1. 进行jdbc提交操作
for (Map.Entry<KpiType, PreparedStatement> entry : this.pstmtMap.entrySet()) {
try {
entry.getValue().executeBatch(); // 批量提交
} catch (SQLException e) {
// nothings
}
}
this.conn.commit(); // 数据库提交
} catch (Exception e) {
throw new IOException(e);
} finally {
// 2. 关闭资源
for (Map.Entry<KpiType, PreparedStatement> entry : this.pstmtMap.entrySet()) {
JDBCManager.closeConnection(null, entry.getValue(), null);
}
JDBCManager.closeConnection(conn, null, null);
}
}
}
}
项目总体分析
这部分在第30个视频

这里的flume往hdfs采集数据,如果出现异常就手动采集到hdfs。
loggerUtil的类:将采集的数据转化为键值对,方便将来在AnalysisDataMapper中进行操作,在AnalysisDataMapper中将map解析了出来Map还是在AnalysisDataMapper类中,在从输出事件到hbase的时候将b_iew这段数据扔掉了(原始数据中),因为已经解析出来了,已经不需要了,减小内存的占用
主要关注 ** AnalysisDataMapper ** 类,这里进行数据清洗,并写入到hbase
写入到hbase这里选择将uuid+当前时间+浏览器信息作为rowkey
通过context.write(NullWritable.get(), put); put对象在AnalysisDataMapper这个类中想数据写入到了hbase中,注意这里的输出类型是put
然后关注** AnalysisDataRunner **,关注this.initJobInputPath(job); 方法,方法中的FileInputFormat.addInputPath(job, inPath);是关键,整个方法都是为了这段做准备,为了拿到输入源的路径(根据日期),然后后是输出initHBaseOutPutConfig(job);(输出到habase),注意整个run方法中的都是初始化操作,都是在mapper之前进行额
额外补充 :hive不能有这样的文件名 “log-123”,因为hive中有数据处理的功能,会将-当做减号,但是hbase可以,因为hbase不存在数据处理
以上,是通过mapper把,数据保存到了habase里面。
然后通过**newInstallUserMapper** 类,读取hbase里面的数据,看map方法,setup方法,首先看map方法,倒着推,已经知道在reduce中做聚合叠加,现在是map阶段先不管怎么聚合叠加,但是知道这个reduce中肯定需要uuid,这个uuid是mapper传过去的,除了uuid,我们知道uuid在描述上面都需要维度, 所以mapper在输出的时候就一定要按照某个维度进行聚合,统计周就按照周进行聚合,统计天就按照天进行聚合,然后进行叠加,支持知道map方法的作用就是以维度聚合uuid。 然后我们需要知道tableMapper的输入键的类型和输入值得类型 是hbase某张表的那一行偏移量数据,reuslt是具体的内容

mapper中的第一个参数,看需要什么维度的数据,比如,只在乎时间的指标,只需要拿一个dateDimension即可,只需要进行时间统计就可以了,注意这里的维度的类 StatsUserDimension
然后开始看map方法,从hbase中读取出uuid,平台维度,服务器时间等信息,构建不同的未读信息,这里有五个维度信息,然后进行排列组合,排列组合组装完数据之后,讲数据封装到text,然后传给了reducer
然后就到了**NewInstallUserReducer**,这个类输入时mapper的输出,输出是往mysql中输出。 统计uuid,至于最后reducer是怎么输出到mysql中的,通过写outputformate来实现
最后是**NewInstallserRunner**,组装任务,添加过滤,过滤是为了扫描表的时候减小开销,根据当天的时间和传入的时间进行比较,如果传入的时间比当前的时间还要大说明传入的是未来时间,就选当前的时间,如果传入的时间
在runner中这里到了**TransformerMySQLOutputFormat**,outputformat需要recodWriter对象,所以这里定义了一个DemoRecordWriter对象
自定义OutputFormat
好吧,这里在总体分析的下面有点不太合适
IDimensionConverter (getDimensionIdByValue()判断当前的维度在维度表里面有没有存在)
就像一条新的数据 360浏览器 1.2版本,这个时候,这条数据本身是没有id的是我们在reducer的时候加进去的,所以判断有没有id,如果没有的话就插入进去
DimensionConverterImpl继承上面的这个接口
package com.z.transformer.converter.impl;
import java.io.IOException;
import java.sql.Connection;
import java.sql.Date;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.z.transformer.converter.IDimensionConverter;
import com.z.transformer.dimension.key.BaseDimension;
import com.z.transformer.dimension.key.base.BrowserDimension;
import com.z.transformer.dimension.key.base.DateDimension;
import com.z.transformer.dimension.key.base.KpiDimension;
import com.z.transformer.dimension.key.base.PlatformDimension;
import com.z.transformer.util.JDBCManager;
/**
* 根据维度值获取维度id的具体实现类
*
*/
public class DimensionConverterImpl implements IDimensionConverter {
private static final Logger logger = LoggerFactory.getLogger(DimensionConverterImpl.class);
/**
* 线程局部缓存器,没有线程缓存一个属于当前线程的数据库连接
*/
private ThreadLocal<Connection> localConn = new ThreadLocal<Connection>();
/**
* 维度数据缓存器
*/
//这里map的key用来存所有的数据,integer用来存id
private Map<String, Integer> cache = new LinkedHashMap<String, Integer>() {
private static final long serialVersionUID = -3084359201061689731L;
@Override
protected boolean removeEldestEntry(Entry<String, Integer> eldest) {
// 缓存容量, 如果这里返回true,那么删除最早加入的数据
// 当集合的大小大于5000的情况下 ,返回true,删除最早加入的数据
return this.size() > 5000;
}
};
/**
* 构造函数,默认无参构造函数
*/
public DimensionConverterImpl() {
// 添加关闭的钩子,jvm关闭时,会触发该线程执行数据库链接关闭操作
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
logger.info("开始关闭数据库......");
JDBCManager.closeConnection(localConn.get(), null, null);
logger.info("关闭数据库成功!");
}
}));
}
@Override
public int getDimensionIdByValue(BaseDimension value) throws IOException {
/**
* 获取方式
* 1. 判断缓存中是否存储对于维度的维度id
* 2. 如果缓存中存在,那么直接返回;否则进行下一步
* 3. 查询数据库中是否存在对应的数据库维度id的记录,如果存在,直接返回id值;如果不存在,进行下一步
* 4. 将维度数据插入到关系型数据库中
* 5. 再重新获取维度id的值,此时维度id的值一定存在
*/
// 1. 创建cache key(缓存key)
String cacheKey = buildCacheKey(value); // 获取cache
// 2. 判断缓存中是否存在对于key的数据
if (this.cache.containsKey(cacheKey)) {
// 3. 缓存中存在对应数据,直接返回结果值
return this.cache.get(cacheKey);
}
try {
// 4. 创建sql语句数组,包括查询语句和插入数据语句,第一条为查询语句,第二条为插入数据语句
String[] sql = null; // 具体执行sql数组
if (value instanceof DateDimension) {
sql = this.buildDateSql();
} else if (value instanceof PlatformDimension) {
sql = this.buildPlatformSql();
} else if (value instanceof BrowserDimension) {
sql = this.buildBrowserSql();
} else if (value instanceof KpiDimension) {
sql = this.buildKpiSql();
} else {
throw new IOException("不支持此dimensionid的获取:" + value.getClass());
}
// 5. 获取数据库连接
Connection conn = this.getConnection(); // 获取连接
int id = 0;
// 6. 并发控制,每次只允许一个维度进行id获取操作
synchronized (this) {
id = this.executeSql(conn, cacheKey, sql, value);
}
// 7. 返回结果
return id;
} catch (Throwable e) {
logger.error("操作数据库出现异常", e);
throw new IOException(e);
}
}
/**
* 创建cache key
*
* @param dimension
* @return
*/
//通过Stringbuilder创建key
public static String buildCacheKey(BaseDimension dimension) {
StringBuilder sb = new StringBuilder();
// 1. 根据不同数据类型创建对于的cache key值
if (dimension instanceof DateDimension) {
sb.append("date_dimension");
DateDimension date = (DateDimension) dimension;
sb.append(date.getYear()).append(date.getSeason()).append(date.getMonth());
sb.append(date.getWeek()).append(date.getDay()).append(date.getType());
} else if (dimension instanceof PlatformDimension) {
sb.append("platform_dimension");
PlatformDimension platform = (PlatformDimension) dimension;
sb.append(platform.getPlatformName()).append(platform.getPlatformVersion());
} else if (dimension instanceof BrowserDimension) {
sb.append("browser_dimension");
BrowserDimension browser = (BrowserDimension) dimension;
sb.append(browser.getBrowser()).append(browser.getBrowserVersion());
} else if (dimension instanceof KpiDimension) {
sb.append("kpi_dimension");
KpiDimension kpiDimension = (KpiDimension) dimension;
sb.append(kpiDimension.getKpiName());
}
// 2. 如果cache值为空,那么直接抛出异常
if (sb.length() == 0) {
throw new RuntimeException("无法创建指定dimension的cachekey:" + dimension.getClass());
}
// 3. 返回cache key值
return sb.toString();
}
/**
* 获取数据库连接
* 如果在当前线程的缓存中没有找到对于的数据库连接,那么进行新建操作
*
* @return
* @throws SQLException
*/
private Connection getConnection() throws SQLException {
Connection conn = null;
synchronized (this) {
// 从缓存中获取对应的数据库连接值
conn = localConn.get();
if (conn == null || conn.isClosed() || !conn.isValid(3)) {
// 当为空,或者连接关闭的情况下,进行重新获取操作
// 1. 创建hadoop上下文,上下文中保存了jdbc的数据库连接信息
Configuration conf = HBaseConfiguration.create();
conf.addResource("output-collector.xml");
conf.addResource("query-mapping.xml");
conf.addResource("transformer-env.xml");
// 2. 开始获取数据库连接
try {
conn = JDBCManager.getConnection(conf, "report");
} catch (SQLException e) {
// 出现异常,关闭连接后重新获取
JDBCManager.closeConnection(conn, null, null);
conn = JDBCManager.getConnection(conf, "report");
}
}
// 将新生成的连接保存到当前线程所属的cache中
this.localConn.set(conn);
}
// 返回数据库连接
return conn;
}
/**
* 具体执行sql的方法
* 执行逻辑:
* 1. 查询数据库中是否存在对于维度的维度id
* 2. 存在则直接返回结果,不存在进行下一步
* 3. 将维度信息插入到数据库中
* 4. 重新获取维度id的值
*
* @param conn
* 数据库连接信息
* @param cacheKey
* 缓存key
* @param sqls
* 要执行的sql语句数组
* @param dimension
* 维度对象
* @return 维度对象对应的维度id
* @throws SQLException
*/
private int executeSql(Connection conn, String cacheKey, String[] sqls, BaseDimension dimension)
throws SQLException {
// 发送sql语句的对象
PreparedStatement pstmt = null;
// sql执行结果对象
ResultSet rs = null;
try {
// 1. 开始查询操作
pstmt = conn.prepareStatement(sqls[0]); // 创建查询sql的pstmt对象
// 设置参数
this.setArgs(pstmt, dimension);
// 执行查询操作
rs = pstmt.executeQuery();
if (rs.next()) {
// 数据存在,直接返回结果
return rs.getInt(1); // 返回值
}
// 关闭连接
JDBCManager.closeConnection(null, pstmt, rs);
// 2. 插入数据操作
// 代码运行到这儿,表示该dimension在数据库中不存在,进行插入
pstmt = conn.prepareStatement(sqls[1]);
// 设置参数
this.setArgs(pstmt, dimension);
// 执行更新操作
pstmt.executeUpdate();
// 关闭连接
JDBCManager.closeConnection(null, pstmt, rs);
// 3. 重新获取维度id的值
pstmt = conn.prepareStatement(sqls[0]); // 创建查询sql的pstmt对象
// 设置参数
this.setArgs(pstmt, dimension);
// 执行查询操作
rs = pstmt.executeQuery();
if (rs.next()) {
// 数据存在,直接返回结果
return rs.getInt(1); // 返回值
}
} finally {
// 关闭连接
JDBCManager.closeConnection(null, pstmt, rs);
}
throw new RuntimeException("从数据库获取id失败");
}
/**
* 设置参数
*
* @param pstmt
* @param dimension
* @throws SQLException
*/
private void setArgs(PreparedStatement pstmt, BaseDimension dimension) throws SQLException {
int i = 0;
if (dimension instanceof DateDimension) {
DateDimension date = (DateDimension) dimension;
pstmt.setInt(++i, date.getYear());
pstmt.setInt(++i, date.getSeason());
pstmt.setInt(++i, date.getMonth());
pstmt.setInt(++i, date.getWeek());
pstmt.setInt(++i, date.getDay());
pstmt.setString(++i, date.getType());
pstmt.setDate(++i, new Date(date.getCalendar().getTime()));
} else if (dimension instanceof PlatformDimension) {
PlatformDimension platform = (PlatformDimension) dimension;
pstmt.setString(++i, platform.getPlatformName());
pstmt.setString(++i, platform.getPlatformVersion());
} else if (dimension instanceof BrowserDimension) {
BrowserDimension browser = (BrowserDimension) dimension;
pstmt.setString(++i, browser.getBrowser());
pstmt.setString(++i, browser.getBrowserVersion());
} else if (dimension instanceof KpiDimension) {
KpiDimension kpi = (KpiDimension) dimension;
pstmt.setString(++i, kpi.getKpiName());
}
}
/**
* 创建date dimension相关sql
*
* @return
*/
private String[] buildDateSql() {
String querySql = "SELECT `id` FROM `dimension_date` WHERE `year` = ? AND `season` = ? AND `month` = ? AND `week` = ? AND `day` = ? AND `type` = ? AND `calendar` = ? order by `id`";
String insertSql = "INSERT INTO `dimension_date`(`year`, `season`, `month`, `week`, `day`, `type`, `calendar`) VALUES(?, ?, ?, ?, ?, ?, ?)";
return new String[] { querySql, insertSql };
}
/**
* 创建polatform dimension相关sql
*
* @return
*/
private String[] buildPlatformSql() {
String querySql = "SELECT `id` FROM `dimension_platform` WHERE `platform_name` = ? AND `platform_version` = ? order by `id`";
String insertSql = "INSERT INTO `dimension_platform`(`platform_name`, `platform_version`) VALUES(?, ?)";
return new String[] { querySql, insertSql };
}
/**
* 创建browser dimension相关sql
*
* @return
*/
private String[] buildBrowserSql() {
String querySql = "SELECT `id` FROM `dimension_browser` WHERE `browser_name` = ? AND `browser_version` = ? order by `id`";
String insertSql = "INSERT INTO `dimension_browser`(`browser_name`, `browser_version`) VALUES(?, ?)";
return new String[] { querySql, insertSql };
}
/**
* 创建kpi dimension相关sql
*
* @return
*/
private String[] buildKpiSql() {
String querySql = "SELECT `id` FROM `dimension_kpi` WHERE `kpi_name` = ? order by `id`";
String insertSql = "INSERT INTO `dimension_kpi`(`kpi_name`) VALUES(?)";
return new String[] { querySql, insertSql };
}
@Override
public void close() throws IOException {
logger.debug("进行关闭资源操作....");
JDBCManager.closeConnection(this.localConn.get(), null, null);
logger.debug("关闭资源操作完成");
}
}
TransformerMySQLOutputFormat
package com.z.transformer.mr;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.OutputCommitter;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.z.transformer.common.GlobalConstants;
import com.z.transformer.common.KpiType;
import com.z.transformer.converter.IDimensionConverter;
import com.z.transformer.converter.impl.DimensionConverterImpl;
import com.z.transformer.dimension.key.BaseDimension;
import com.z.transformer.dimension.value.BaseStatsValueWritable;
import com.z.transformer.util.JDBCManager;
public class TransformerMySQLOutputFormat extends OutputFormat<BaseDimension, BaseStatsValueWritable> {
@Override
public RecordWriter<BaseDimension, BaseStatsValueWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
// 构建属于当前outputforamt的数据输出器
// 1. 获取上下文
Configuration conf = context.getConfiguration();
// 2. 创建jdbc连接
Connection conn = null;
try {
// 根据上下文中配置的信息获取数据库连接
// 需要在hadoop的configuration中配置mysql的驱动连接信息
conn = JDBCManager.getConnection(conf, GlobalConstants.WAREHOUSE_OF_REPORT);
conn.setAutoCommit(false); // 关闭自动提交机制,方便我们进行批量提交
} catch (SQLException e) {
throw new IOException(e);
}
// 3. 构建对象并返回
return new TransformerRecordWriter(conf, conn);
}
@Override
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {
// 该方法的主要作用是检测输出空间的相关属性,比如是否存在之类的情况
// 如果说job运行前提的必须条件不满足,直接抛出一个exception。
}
@Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
// 使用的是FileOutputFormat中默认的方式
String name = context.getConfiguration().get(FileOutputFormat.OUTDIR);
Path output = name == null ? null : new Path(name);
return new FileOutputCommitter(output, context);
}
/**
* 自定义的具体将reducer输出数据输出到mysql表的输出器
*/
static class TransformerRecordWriter extends RecordWriter<BaseDimension, BaseStatsValueWritable> {
private Connection conn = null; // 数据库连接
private Configuration conf = null; // 上下文保存成属性
private Map<KpiType, PreparedStatement> pstmtMap = new HashMap<KpiType, PreparedStatement>();
private int batchNumber = 0; // 批量提交数据大小
private Map<KpiType, Integer> batch = new HashMap<KpiType, Integer>();
private IDimensionConverter converter = null; // 维度转换对象
/**
* 构造方法
*
* @param conf
* @param conn
*/
public TransformerRecordWriter(Configuration conf, Connection conn) {
this.conf = conf;
this.conn = conn;
this.batchNumber = Integer.valueOf(conf.get(GlobalConstants.JDBC_BATCH_NUMBER, GlobalConstants.DEFAULT_JDBC_BATCH_NUMBER));
this.converter = new DimensionConverterImpl();
}
@Override
//第一个参数是当前reduce输出的维度的对象,第二个参数是当前的reducer输出的维度的值,就是uuid的个数
public void write(BaseDimension key, BaseStatsValueWritable value) throws IOException, InterruptedException {
try {
// 每个分析的kpi值是不一样的,一样的kpi有一样的插入sql语句
KpiType kpi = value.getKpi();
int count = 0; // count表示当前PreparedStatement对象中需要提交的记录数量
// 1. 获取数据库的PreparedStatement对象
// 从上下文中获取kpi对应的sql语句
String sql = this.conf.get(kpi.name);
PreparedStatement pstmt = null;
// 判断当前kpi对应的preparedstatment对象是否存在
if (this.pstmtMap.containsKey(kpi)) {
// 存在
pstmt = this.pstmtMap.get(kpi); // 获取对应的对象
if (batch.containsKey(kpi)) {
count = batch.get(kpi);
}
} else {
// 不存在, 第一次创建一个对象
pstmt = conn.prepareStatement(sql);
// 保存到map集合中
this.pstmtMap.put(kpi, pstmt);
}
// 2. 获取collector类名称
String collectorClassName = this.conf.get(GlobalConstants.OUTPUT_COLLECTOR_KEY_PREFIX + kpi.name);
// 3. 创建class对象
Class<?> clz = Class.forName(collectorClassName); // 获取类对象
// 调用newInstance方法进行构成对象,要求具体的实现子类有默认无参构造方法
ICollector collector = (ICollector) clz.newInstance();
// 4. 设值参数
collector.collect(conf, key, value, pstmt, converter);
// 5. 处理完成后,进行累计操作
count++;
this.batch.put(kpi, count);
// 6. 执行,采用批量提交的方式
if (count > this.batchNumber) {
pstmt.executeBatch(); // 批量提交
conn.commit(); // 连接提交
this.batch.put(kpi, 0); // 恢复数据
}
} catch (Exception e) {
throw new IOException(e);
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
// 关闭资源
try {
// 1. 进行jdbc提交操作
for (Map.Entry<KpiType, PreparedStatement> entry : this.pstmtMap.entrySet()) {
try {
entry.getValue().executeBatch(); // 批量提交
} catch (SQLException e) {
// nothings
}
}
this.conn.commit(); // 数据库提交
} catch (Exception e) {
throw new IOException(e);
} finally {
// 2. 关闭资源
for (Map.Entry<KpiType, PreparedStatement> entry : this.pstmtMap.entrySet()) {
JDBCManager.closeConnection(null, entry.getValue(), null);
}
JDBCManager.closeConnection(conn, null, null);
}
}
}
}
然后最后就是Hive之Hourly分析这块内容。
End、备注
常用Maven仓库地址
中央库:http://repo.maven.apache.org/maven2/
cdh库:https://repository.cloudera.com/artifactory/cloudera-repos/