视觉注意力机制在分类网络中的应用——SENet、CBAM、SKNet(阅读笔记)
原文
将软注意力机制分为三大注意力预:
(1) 空间域——对空间进行掩码的生成,进行打分,代表是Spatial Attention Module。忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络层其他层的可解释性不强。
(2) 通道域——对通道生成掩码mask,进行打分,代表是senet, Channel Attention Module。对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息。
(3) 混合域——同时对通道注意力和空间注意力进行评价打分,代表的有BAM, CBAM。
1 Squeeze-and-Excitation Networks(SENet)
通道域
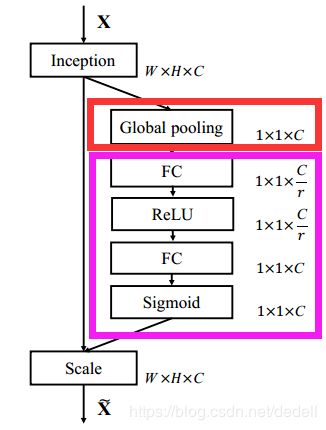
对C张feature map先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程),输出的1x1xC数据。
再经过两级全连接(图中的Fex(.),作者称为Excitation过程,非线性变换)。参数r的目的是为了减少全连接层的参数。
最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
2 Convolutional Block Attention Module(CBAM)
依次应用通道和空间注意模块,来来增加表现力,关注重要特征并抑制不必要的特征。

2.1通道注意力模块

CBAM在S步采取了全局平均池化以及全局最大池化(即对每张特征图求mean及max),提取的高层次特征更加丰富。接着在E步同样通过两个全连接层和相应的激活函数建模通道之间的相关性,合并两个输出得到各个特征通道的权重。最后,得到特征通道的权重之后,通过乘法逐通道加权到原来的特征上,完成在通道维度上的原始特征重标定。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
2.2空间注意力模块

在通道这个维度上把所有输入通道池化成2个实数,由(hwc)形状的输入得到两个(hw1)的特征图。接着使用一个 77 的卷积核,卷积后形成新的(hw*1)的特征图。注意力模块特征与得到的新特征图相乘得到经过双重注意力调整的特征图。
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)
2.3 整体代码
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # 广播机制
out = self.sa(out) * out # 广播机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
3 Selective Kernel Networks(SKNet)
Selective Kernel Networks(SKNet)发表在CVPR 2019,是对Momenta发表于CVPR 2018上论文SENet的改进。是针对卷积核的注意力机制研究。
SKNet对不同图像使用的卷积核权重不同,即一种针对不同尺度的图像动态生成卷积核。
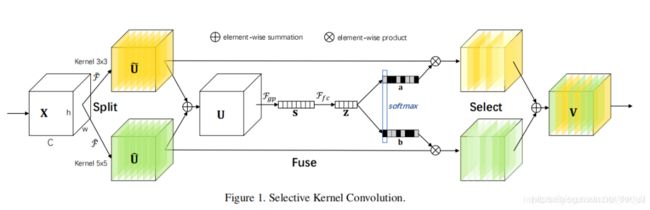
 网络主要由Split、Fuse、Select三部分组成。
网络主要由Split、Fuse、Select三部分组成。
-
Split
对原特征图经过不同大小的卷积核部分进行卷积的过程,这里可以有多个分支。
对输入X使用不同大小卷积核分别进行卷积操作(图中的卷积核size分别为3x3和5x5两个分支,但是可以有多个分支)。操作包括卷积、efficient grouped/depthwise convolutions、BN。 -
Fuse
计算每个卷积核权重的部分。
将两部分的特征图按元素求和
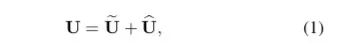
U通过全局平均池化(GAP)生成通道统计信息。得到的Sc维度为C * 1

经过全连接生成紧凑的特征z(维度为d * 1), δ是RELU激活函数,B表示批标准化(BN),z的维度为卷积核的个数,W维度为d×C, d代表全连接后的特征维度,L在文中的值为32,r为压缩因子。
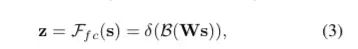
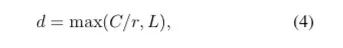
-
Select
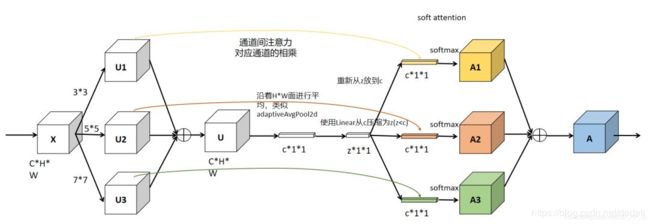
根据不同权重卷积核计算后得到的新的特征图。进行softmax计算每个卷积核的权重,计算方式如下图所示。如果是两个卷积核,则 ac + bc = 1。z的维度为(d * 1)A的维度为(C * d),B的维度为(C * d),则a = A x z的维度为1 * C。
Ac、Bc为A、B的第c行数据(1 * d)。ac为a的第c个元素,这样分别得到了每个卷积核的权重。

将权重应用到特征图上。其中V = [V1,V2,…,VC], Vc 维度为(H x W),如果

select中softmax部分可参考下图(3个卷积核)

class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1, L=32):
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
# 使用不同kernel size的卷积
self.convs.append(
nn.Sequential(
nn.Conv2d(features,
features,
kernel_size=3 + i * 2,
stride=stride,
padding=1 + i,
groups=G), nn.BatchNorm2d(features),
nn.ReLU(inplace=False)))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(nn.Linear(d, features))
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
fea_U = torch.sum(feas, dim=1)
fea_s = fea_U.mean(-1).mean(-1)
fea_z = self.fc(fea_s)
for i, fc in enumerate(self.fcs):
print(i, fea_z.shape)
vector = fc(fea_z).unsqueeze_(dim=1)
print(i, vector.shape)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector],
dim=1)
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v