大数据基础Hadoop 3.1.1 的高可用HA安装~踩坑记录
最近负责的项目准备上大数据平台存储,主要还是围绕Hadoop平台来实现,虽然打算上cdh版本的hadoop,但是为了前期方便开发还是先使用原声的hadoop进行开发,后期再准备更好的环境进行扩展。
环境准备
三台服务器系统环境是建立在Centos7.6基础上。并且是建立在root账户上运行的,如果需要使用其他用户操作,注意权限的问题
基础机器分配
在三台新购买的服务器上进行搭建。服务器规划如下
| hostname | ip | 说明 |
|---|---|---|
| tidb1 | 192.168.108.66 | namenode与datanode |
| tidb2 | 192.168.108.67 | namenode与datanode |
| tidb3 | 192.168.108.68 | namenode与datanode |
搭建大数据集群基础机器配置是三台,真实环境部署建议namenode与datanode进行分开,两台机器专门做namenode节点,其他三台做datanode节点。
每台机器安装内容如下:
| tidb1 | tidb2 | tidb3 | |
|---|---|---|---|
| NameNode | √ | √ | |
| DataNode | √ | √ | √ |
| ResourceManager | √ | √ | |
| NodeManager | √ | √ | √ |
| Zookeeper | √ | √ | √ |
| journalnode | √ | √ | √ |
| zkfc | √ | √ |
在3.0版本以上,我们可以进行安装多个NameNode节点,来保证更高的高可用方案。但是作为基础的测试环境开发这样就是可以了,更多机器扩展也在此进行扩展即可。
防火墙
三台机器都需要这么做
部署集群之前将集群的防火墙进行关闭,否则部署出现,访问端口访问不到的情景。
centos 系统中存在两种防火墙,firewall 与iptables , 7.0以后默认是firewall 防火墙,但是也在网上看到其他朋友遇见过 7.0系统上存在两种防火墙策略导致布置程序端口一直访问不到的情况。
firewall
- 查看防火墙的状态
[root@tidb1 sbin]# firewall-cmd --state
running
- 停止防火墙
systemctl stop firewalld.service
- 禁止开机启动
systemctl disbale firewalld.service
执行以上三步之后,程序再开机之后不再出现防火墙的配置问题。
iptabel
如果是这个防火墙的配置,我们也需要进行防火墙的关闭,如果熟悉的话其实打开对应的端口策略即可。
- 查看防火墙的状态
service iptables status
- 停止防火墙
service iptables stop
Redirecting to /bin/systemctl stop iptables.service
- 禁止开机启动
chkconfig iptables off
对于安装在其他系统上的集群环境,按照对应的策略进行关闭防火墙。
Selinux
三台机器都需要这么做
关于这个增强型Linux,网上很多都建议关闭,在这里搜索下了相关资料,主要是没有人进行专门的维护运营白名单导致的。
测试环境上我们也进行关闭,方便我们集群的搭建。正式上线根据运维的需要进行部署执行。
- 查看SELinux当前状态:
getenforce
- 修改SELinux状态(临时修改,重启机器后失效)
setenforce 0 #将SELinux修改为Permissive状态(遇到违反安全策略的,会采取警告,允许通过)
setenforce 1 #将SELinux状态修改为Enforcing状态(遇到违反安全策略的,不允许通过)
- 修改SELinuxw为禁用状态 (永久性,重启机器后保持生效)
打开文件: /etc/selinux/config 修改 SELINUX = disabled
重启机器后生效,重启机器命令:reboot
ip固定
三台机器都需要这么做
在企业环境中,如果是真实的服务器,不是利用云服务器,那么我们使用服务器之前需要进行ip的固定,不然服务器出现意外重启,会导致我们ip变动,集群就不能正常启动。
固定ip,两种执行方案:
- 有专门的人员路由器端进行固定分配,这样是最简单的操作步骤。建议这么做
- 给专门的网卡进行固定ip,很多时候服务器是有双网卡与光口的,其参考以下步骤,仅供参考
- 查看网卡(文件 ifcfg-enp* 为网卡文件)
ls /etc/sysconfig/network-scripts/
- 配置网卡ip
vi /etc/sysconfig/network-scripts/ifcfg-enp*
# 启用host-only网卡
cd /etc/sysconfig/network-scripts/
cp ifcfg-enp0s3 ifcfg-enp0s8
- 修改网卡为静态ip
- 修改BOOTPROTO为static
- 修改NAME为enp0s8
- 修改UUID(可以随意改动一个值,只要不和原先的一样)
- 添加IPADDR,可以自己制定,用于主机连接虚拟机使用。
- 添加NETMASK=255.255.255.0 (网管 也可以和网段一样 x.x.x.255)
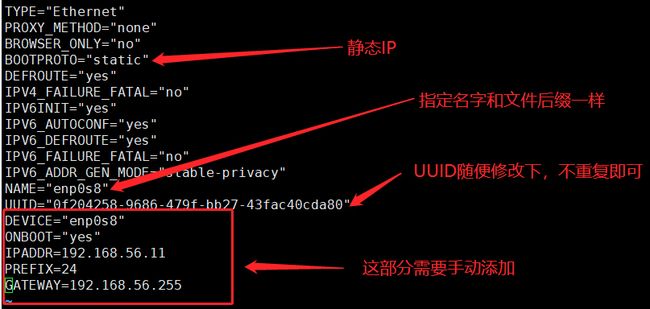
4. 重启网卡
service network restart
配置hosts
三台机器都需要这么做
重点注意,配置主节点Namenode的时候,需要将localhost 两行 注释掉,不然会出现找不到hostname的问题。其他节点可以存在
vim /etc/hosts
[root@tidb1 network-scripts]# cat /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.108.66 tidb1
192.168.108.67 tidb2
192.168.108.68 tidb3
配置免登陆
老生常态,集群之间需要通过ssh,互相通信,那么需要设置免登陆的情况。
步骤如下:
- 生成秘钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
- 写入authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys`
- 注意权限问题
chmod 0600 ~/.ssh/authorized_keys
- 拷贝到其他服务器上
ssh-copy-id root@tidb2
ssh-copy-id root@tidb3
- 尝试是否能互相免登陆
ssh tidb2
ssh tidb3
ssh tidb1
在每条机器上,都需要进行操作,实现免登陆,如果存在免登陆失败
- 检查配置的免登陆秘钥是否正确,一般是秘钥出现错误导致的。
- 秘钥没有问题,文件的权限是否正确 ,进行第三步权限的修改。
目录权限的问题,解决。
sudo chmod 700 ~
sudo chmod 700 ~/.ssh
sudo chmod 600 ~/.ssh/authorized_keys
准备需要安装的软件
hadoop HA版本我们需要使用zookeeper来实现,所以需要准备的软件就有这样三个了 hadoop ,zookeeper,jdk1.8版本。
1. 创建三个软件的存储位置
mkdir zookeeper
mkdir hadoop
mkdir java
2. 下载软件
移动到相应的目录下 下载软件
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.1.1/hadoop-3.1.1-src.tar.gz
jdk 去oracle 网站进行下载再上传到我们服务器的目录上。
3. 进行相应的解压
tar -zxvf zookeeper-3.4.13.tar.gz
tar -zxvf hadoop-3.1.1-src.tar.gz
tar -zxvf jdk1.8.tar.gz
安装
以上基础内容都配置好之后,我们就可以开始进行程序的安装了。首先在第一台机器上进行配置好之后在通过rsync 进行同步发送过去
rsync 安装
centos 上的安装,每台都需要进行安装
rpm -qa | grep rsync 检查是否安装无哦rsync
yum install -y rsync 使用yum安装rsync
Java环境的安装
- 进入解压的Java文件路径下
cd /home/bigdata/java/jdk1.8
pwd 找到路径信息
- 配置环境变量
JAVA_HOME=/home/bigdata/java/jdk1.8
JRE_HOME=/home/bigdata/java/jdk1.8/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
- 同步到其他服务器
tidb2:
rsync -avup /etc/profile root@tidb2:/etc/
tidb3:
rsync -avup /etc/profile root@tidb3:/etc/
- 执行生效
三台都执行
source /etc/profile
如果是使用的个人用户需要执行
source ~/.bashrc
zookeeper安装
- 进入到上面的解压的目录下
cd /home/bigdata/zookeeper/zookeeper-3.4.13

- 增加zoo.cfg文件
cd /home/bigdata/zookeeper/zookeeper-3.4.13/conf
cp zoo_sample.cfg zoo.cfg
mv zoo_sample.cfg bak_zoo_sample.cfg 备份文件
- 编辑zoo.cfg
修改之前 创建dataDir 文件 mkdir -p /home/bigdata/zookeeper/zookeeper-3.4.13/tmp
在原先的基础内容上增加server配置内容与配置dataDir文件内容
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
#修改的dataDir文件路径,配置临时文件路径内容即可,配置的文件路径需要提前创建好
# example sakes.
dataDir=/home/bigdata/zookeeper/zookeeper-3.4.13/tmp
# the port at which the clients will connect
clientPort=2181
# 配置server 几台机器就配置几台即可,注意server的数字,我们在后续需要用到
server.1=tidb1:2888:3888
server.2=tidb2:2888:3888
server.3=tidb3:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purg
上面的基本配置信息内容如下:
- tickTime: 心跳基本时间单位,毫秒级,ZK基本上所有的时间都是这个时间的整数倍。
- initLimit: tickTime的个数,表示在leader选举结束后,followers与leader同步需要的时间,如果followers比较多或者说leader的数据灰常多时,同步时间相应可能会增加,那么这个值也需要相应增加。当然,这个值也是follower和observer在开始同步leader的数据时的最大等待时间(setSoTimeout)
- syncLimit : tickTime的个数,这时间容易和上面的时间混淆,它也表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间。
- dataDir : 内存数据库快照存放地址,如果没有指定事务日志存放地址(dataLogDir),默认也是存放在这个路径下,建议两个地址分开存放到不同的设备上
- clientPort : 配置ZK监听客户端连接的端口
clientPort=2181
server.serverid=host:tickpot:electionport 固定写法
server:固定写法
serverid:每个服务器的指定ID(必须处于1-255之间,必须每一台机器不能重复)
host:主机名
tickpot:心跳通信端口
electionport:选举端口
- 创建需要的文件夹
mkdir -p /home/bigdata/zookeeper/zookeeper-3.4.13/tmp
echo 1 > /home/bigdata/zookeeper/zookeeper-3.4.13/tmp/myid
- 同步到其他服务器上
rsync -avup /home/bigdata/zookeeper root@tibd2:/home/bigdata/
rsync -avup /home/bigdata/zookeeper root@tibd3:/home/bigdata/
- 修改其他服务器上的myid
tidb2:
vim /home/bigdata/zookeeper/zookeeper-3.4.13/tmp/myid 将1改为2
tidb3:
vim /home/bigdata/zookeeper/zookeeper-3.4.13/tmp/myid 将1改为3
- 配置环境变量
JAVA_HOME=/home/bigdata/java/jdk1.8
JRE_HOME=/home/bigdata/java/jdk1.8/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
ZOOKEEPER_HOME=/home/bigdata/zookeeper/zookeeper-3.4.13
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$ZOOKEEPER_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH ZOOKEEPER_HOME
source /etc/profile
- 进行验证是否正常。
以上7个步骤执行完毕后,我们需要进行zookeeper的验证是否正确,将每台服务器上的zookpeer进行启动
小黑板,三台都需要执行
cd /home/bigdata/zookeeper/zookeeper-3.4.13/bin
执行 ./zkServer.sh start
检查是否启动
方式1 :
使用命令jps 检查是否执行成功,jps 不存在的执行下安装 检查是否 有这个配置export PATH=$PATH:/usr/java/jdk1.8/bin
85286 QuorumPeerMain 代表执行成功
方式2:
./zkServer.sh status
[root@tidb1 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/bigdata/zookeeper/zookeeper-3.4.13/bin/../conf/zoo.cfg
Mode: follower 代表是从节点
Mode: Leader 代表的是主节点
Hadoop 的安装
基础文件的创建
安装过程中我们需要一些目录文件进行存储我们的数据,日志文件,数据存储文件都是保存在不同的目录中,需要提前准备好
- 数据存储
每台机器上三个硬盘,需要三个目录进行创建
mkdir -p /media/data1/hdfs/data
mkdir -p /media/data2/hdfs/data
mkdir -p /media/data3/hdfs/data
- journal 内容存储
mkdir -p /media/data1/hdfs/hdfsjournal
- namenode 内容存储路径
mkdir -p /media/data1/hdfs/name
修改相关的配置文件
- 配置Java环境
编辑 hadoop中的hadoop-env.sh文件
vim /home/bigdata/hadoop/hadoop/etc/hadoop/hadoop-env.sh
配置 jdk环境 ,在这里还可以配置jvm内存大小等内容
export JAVA_HOME=/home/bigdata/java/jdk1.8
#export HADOOP_NAMENODE_OPTS=" -Xms1024m -Xmx1024m -XX:+UseParallelGC"
#export HADOOP_DATANODE_OPTS=" -Xms512m -Xmx512m"
#export HADOOP_LOG_DIR=/opt/data/logs/hadoop 配置日志文件
- 配置core-site.xml
vim /home/bigdata/hadoop/hadoop/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://cluster
hadoop.tmp.dir
/media/data1/hdfstmp
ha.zookeeper.quorum
tidb1:2181,tidb2:2181,tidb3:2181
- 配置hdfs-site.xml
vim /home/bigdata/hadoop/hadoop/etc/hadoop/hdfs-site.xml
dfs.nameservices
cluster
dfs.permissions.enabled
false
dfs.ha.namenodes.cluster
nn1,nn2
dfs.namenorsync -avup hadoop-3.1.1 root@tidb2:/home/bigdata/hadoop/de.rpc-address.cluster.nn1
tidb1:9000
dfs.namenode.rpc-address.cluster.nn2
tidb2:9000
dfs.namenode.http-address.cluster.nn1
tidb1:50070
dfs.namenode.http-address.cluster.nn2
tidb2:50070
dfs.client.failover.proxy.provider.cluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
hdfs-site.xml
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/media/data1/hdfs/hdfsjournal
dfs.ha.automatic-failover.enabled
true
dfs.namenode.name.dir
/media/data1/hdfs/name
dfs.namenode.name.dir
/media/data1/hdfs/name
dfs.datanode.data.dir
/media/data1/hdfs/data,
/media/data2/hdfs/data,
/media/data3/hdfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
dfs.journalnode.http-address
0.0.0.0:8480
dfs.journalnode.rpc-address
0.0.0.0:8485
ha.zookeeper.quorum
tidb1:2181,tidb2:2181,tidb3:2181
- 修改mapred-site.xml
vim /home/bigdata/hadoop/hadoop/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
tidb1:10020
mapreduce.jobhistory.webapp.address
tidb1:19888 rsync -avup hadoop-3.1.1 root@tidb2:/home/bigdata/hadoop/
- yarn-site.xml
vim /home/bigdata/hadoop/hadoop/etc/hadoop/yarn-site.xm
yarn.resourcemanager.ha.id
rm1
yarn.nodemanager.aux-services
mapreduce_shuffle rsync -avup hadoop-3.1.1 root@tidb2:/home/bigdata/hadoop/
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
rmcluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
tidb1
yarn.resourcemanager.hostname.rm2
tidb2
rsync -avup hadoop-3.1.1 root@tidb2:/home/bigdata/hadoop/
yarn.resourcemanager.zk-address
tidb1:2181,tidb2:2181,tidb3:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
- workers
/home/bigdata/hadoop/hadoop/etc/hadoop/workers
#将数据节点加入到workers里面,如果namenode与datanode 节点是分开的,在这里 namenode的节点就不加入到这里。
#没有分开那么就需要加入
tidb1
tidb2
tidb3
- start-dfs.sh stop-dfs.sh
vim /home/bigdata/hadoop/hadoop/sbin/start-dfs.sh vim /home/bigdata/hadoop/hadoop/sbin/stop-dfs.sh
3.0版本以后需要增加以下内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
- start-yarn.sh stop-yarn.sh
vim /home/bigdata/hadoop/hadoop/sbin/start-yarn.sh vim /home/bigdata/hadoop/hadoop/sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 通过rsync 同步到其他机器上
rsync -avup hadoop-3.1.1 root@tidb2:/home/bigdata/hadoop/
rsync -avup hadoop-3.1.1 root@tidb3:/home/bigdata/hadoop/
同步完之后 如果配置的namenode的编号需要注意以下内容:
修改namenode上的id 编号,datanode 上的编号进行删除,
启动
上面的所有文件准备好之后,我们开始进行启动了。
Zookeeper->JournalNode->格式化NameNode->创建命名空间zkfs->NameNode->Datanode->ResourceManager->NodeManager
启动zookeeper
每台进入到安装的zookeeper目录下
./zkServer.sh start
启动journalnode
进入到hadoop的安装目录下 然后进到sbin 目录下
./hadoop-daemon.sh start journalnode 启动journalnode
格式化namenode
- 格式化
hadoop namenode -format
- 格式化同步内容到其他节点上,必须做,不然其他namenode启动不起来
同步的内容:配置hdfs-site.xml文件路径下的内容
dfs.namenode.name.dir
/media/data1/hdfs/name
进行同步
rsync -avup current root@tidb2:/media/data1/hdfs/name/
rsync -avup current root@tidb3:/media/data1/hdfs/name/
格式化zkfc
小黑板:只能在namenode上进行格式化namdenode1
./hdfs zkfs -formatZK
关闭journalnode
./hadoop-daemon.sh stop journalnode
启动 hadoop集群
hadoop 目录下的sbin目录执行
./start-all.sh 全部启动。
启动情况查看
- 使用命令查看
[root@tidb1 bin]# ./hdfs haadmin -getServiceState nn1
standby
[root@tidb1 bin]# ./hdfs haadmin -getServiceState nn2
active
- 界面查看
http://192.168.108.66:50070 # 注意这个端口是自定义的,不是默认端口
http://192.168.108.67:50070
```大数据基础Hadoop 3.1.1 的高可用HA安装~踩坑记录大数据基础Hadoop 3.1.1 的高可用HA安装~踩坑记录

