机器学习实践———朴素贝叶斯、决策树
目录
- 朴素贝叶斯分类器
- 决策树
- 1、构造决策树
- 2、控制决策树的复杂度
- 3、决策树可视化
- 4、树的特征重要性
- 决策树集成
- 1、随机森林
- 2、梯度提升回归树(梯度提升机)
朴素贝叶斯分类器
与线性模型相似,相比起来训练速度更快,但是模型泛化能力稍差。高效的原因是通过查看每个特征来学习参数,从每个特征中收集简单的类别统计数据。
sklearn中实现了3种朴素贝叶斯分类器:
- GuassianNB:高斯贝叶斯分类器,应用于任意连续数据。保存每个类别中每个特征的平均值和标准差。
- BernoulliNB:伯努利贝叶斯分类器,输入数据是二分类数据。计算每个类别中每个特征不为0的元素个数。
- MultinomialNB:多项式贝叶斯分类器,假定输入数据是计数数据。比如说一个词的出现次数。计算每个类别中每个特征的平均值。
BernoulliNB和MultinomialNB主要用在文本分类中。
具体可参考sklearn官方文档
决策树
决策树是从一层层的if/else问题中学习的,这些问题叫做测试。一系列问题可以表示为一棵决策树。
1、构造决策树
- 将所有数据当做一个根结点,通过测试对数据集进行划分。
- 若测试结果为真,将这个点分配到左边的结点,否则分配到右边。每个结点都包含一个测试。
- 对数据反复进行递归划分,直到每个叶结点只包含单一类别。若叶结点中数据点的目标值相同,则为纯叶结点。
2、控制决策树的复杂度
通常来说,如果叶结点都是纯的会导致模型非常复杂,因为它要去拟合每个数据,造成过拟合。
防止过拟合有两种常见的策略:
- 预剪枝:及早停止树的生长。可通过限制树的最大深度,限制叶结点的最大数目,规定一个结点中数据点的最小数目。
- 后剪枝:先构造树,随后删除或折叠信息少的结点。
sklearn实现决策树在DecisionTreeClassifier和DecisionTreeRegressor中。只实现了预剪枝,没有后剪枝。
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,stratify=cancer.target,random_state=42)
tree=DecisionTreeClassifier().fit(X_train,y_train)
print("train acc={}".format(tree.score(X_train,y_train)))
print("test acc={}".format(tree.score(X_test,y_test)))
输出:
train acc=1.0
test acc=0.9230769230769231可以看到训练集上的精度是100%,这棵树直到划分到纯叶结点才停止的。
它对测试集的数据泛化能力不好,接下来通过限制树的深度来停止生长,避免过拟合问题。
tree=DecisionTreeClassifier(max_depth=4).fit(X_train,y_train)#将深度设为4,意味着只可以连续问4个问题。
print("train acc={:.3f}".format(tree.score(X_train,y_train)))
print("test acc={:.3f}".format(tree.score(X_test,y_test)))
输出:
train acc=0.988
test acc=0.9443、决策树可视化
将决策树可视化有助于理解算法是如何预测的。
生成.dot文件
from sklearn.tree import export_graphviz#可视化树,生成一个.dot文件,保存图形的文本文件格式
export_graphviz(tree,out_file="tree.dot",class_names=["malignant","benign"],
feature_names=cancer.feature_names,impurity=False,filled=True)import graphviz
with open("tree.dot") as f:
dot_graph=f.read()
graphviz.Source(dot_graph)书上用这段代码实现可视化,不知道具体是怎么操作的,我用的是pycharm,直接运行后没有产生.png文件。于是在网上找了可视化方法。
生成dot文件后,在cmd命令下

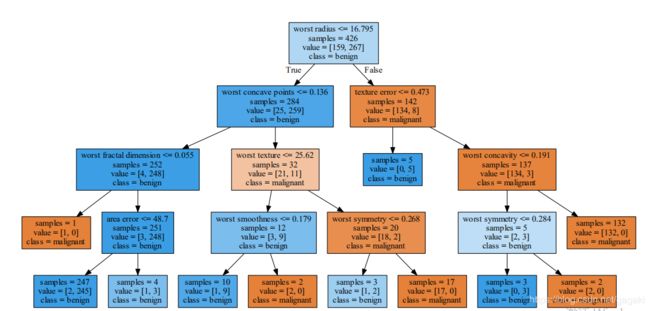
将dot文件转化成pdf文件,打开这个pdf就可以看到生成的决策树。
4、树的特征重要性
可以利用一些有用的属性来总结树的工作原理。最常用的是特征重要性,每个特征分布在【0,1】之间,数值越大,说明该特征对树越重要。特征重要性的求和为1.
可视化特征重要性:
print("feacture importance:\n{}".format(tree.feature_importances_))
def plot_feature_importances_cancer(modle):
n_feature=cancer.data.shape[1]#30个特征
plt.barh(range(n_feature),modle.feature_importances_,align="center")
plt.yticks(np.arange(n_feature),cancer.feature_names)
plt.xlabel("feature importance")
plt.ylabel("feature")
plt.show()
plot_feature_importances_cancer(tree)
输出:
feacture importance:
[0. 0.01258462 0. 0. 0. 0.
0. 0.0141577 0. 0. 0. 0.04839825
0. 0. 0.0024156 0. 0. 0.
0.01019737 0. 0.72682851 0.03323127 0. 0.
0. 0. 0.018188 0.1221132 0.01188548 0. ]

可以看到 worst radius特征最重要,所以当根结点的测试条件按它来 在第一层划分时 就已经将两个类别区分的很好了。
树的回归和分类是类似的,但是DecisionTreeRegressor不能外推,也不能在训练数据范围之外预测。(不能预测训练集外的数据,那他有什么用呢?)
在RAM数据集上对比DecisionTreeRegressor和LinearRegression。
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
ram_prices=pd.read_csv("ram_price.csv")
data_train=ram_prices[ram_prices.date<2000]#将2000年前的数据作为训练集
data_test=ram_prices[ram_prices.date>=2000]
X_train=data_train.date[:,np.newaxis]#索引多维数组的某一列时,返回的仍然是列的结构
#print("Xtrain:{}".format(X_train))
y_train=np.log(data_train.price)#对价格取对数,使二者关系的线性更好。
tree=DecisionTreeRegressor().fit(X_train,y_train)
linear_reg=LinearRegression().fit(X_train,y_train)
X_all=ram_prices.date[:,np.newaxis]#对所有的数据进行预测
pre_tree=tree.predict(X_all)
pre_lin=linear_reg.predict(X_all)
#对数变换逆运算
price_tree=np.exp(pre_tree)
price_lin=np.exp(pre_lin)
plt.semilogy(data_train.date,data_train.price,label="tain data")
plt.semilogy(data_test.date,data_test.price,label="test data")
plt.semilogy(ram_prices.date,price_tree,label="Tree prediction")
plt.semilogy(ram_prices.date,price_lin,label="Linear prediction")
plt.legend()
plt.show()
从上图可以看出两者的差异:
- 在测试集上,线性回归可以较好的额拟合数据,预测结果,但是树没有给出结果。
- 在训练集上,树完美的拟合了每一个数据。
决策树不需要做数据预处理,它的主要缺点是容易过拟合,泛化性能很差,即使做了预剪枝。在大多数应用中,用集成树代替单棵树。
决策树集成
集成是合并多个机器学习模型来构建更强大模型方法。有两种集成模型被证明在大量的分类和回归数据集上是有效的,且都以决策树为基础。分别是随机森林和梯度提升决策树。
1、随机森林
本质上是很多树的集合,可以解决过拟合问题。
背后的思想:构造很多棵树,每棵树都可能会出现过拟合现象,但是以不同的方式过拟合,对这些树的结果取平均值可以降低过拟合。
森林中树的两种随机化方式:
-
选择构造树的数据点
-
选择每次划分测试的特征
构造随机森林:
先要确定构造树的棵树,然后对于每棵树: -
对数据进行自助采样(bootstrap)。比如样本中有30个数据集点,随机抽取一个后放回,再随机抽取一个数据,使样本容量保持30个,如此共抽30次,产生一个与原数据集大小相同的新数据集。因为每次抽完数据点会放回,所以会造成有些数据的缺失,而有些数据重复。
-
将新数据集用来构建决策树。每个结点处,算法随机选择特征的一个子集,对其中一个特征寻找最佳测试。比如鸢尾花的4个特征
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'],将特征的个数设置为2,算法会随机选择两个特征,并对其中的一个特征寻找最佳测试。
这里有一个重要的参数 ,特征个数(max_features)。
如果它的个数等于总特征数,相当于特征选择过程没有添加随机性。
如果max_features=1,那么划分时只能对随机选择到的这个特征寻找测试。
因此(max_features)个数很大的话,树会相似,用最独特的特征可以拟合数据。若(max_features)较小,随机森林中的树差异会很大,为了很好的拟合数据,树的深度都要很大。
5棵树组成的随机森林应用到two_moon数据集
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=100,noise=25,random_state=3)
X_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y,random_state=42)
forest=RandomForestClassifier(n_estimators=5,random_state=2).fit(X_train,y_train)#5棵树
#树保存在estimator_属性中,将每棵树学到的决策边界可视化,将森林的预测可视化
fig,axes=plt.subplots(2,3,figsize=(20,10))
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
# 同时列出数据和数据下标,一般用在 for 循环当中。
#ravel()方法将数组维度拉成一维数组
for i,(ax,tree) in enumerate(zip(axes.ravel(),forest.estimators_)):
ax.set_title("Tree {}".format(i))
mglearn.plots.plot_tree_partition(X_train,y_train,tree,ax)#划分树
mglearn.plots.plot_2d_separator(forest,X_train,fill=True,ax=axes[-1,-1],alpha=.4)#绘制分界线,ax=axes[-1,-1]????
axes[-1,-1].set_title("random forest")
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)#画数据点
plt.show()
前5幅是森林中的树,最后一幅是平均后的随机森林决策边界。这5棵树的决策边界都大不相同,因为自助采样,一些点不在训练集中。
2、梯度提升回归树(梯度提升机)
采用连续的方式构造树,每棵树都试图纠正前一棵树的错误。与随机森林相比,对参数设置更加敏感,除了预剪枝和树的数量外,还有一个重要参数——学习率,控制纠正前一棵树错误的强度。
在乳腺癌数据集上应用梯度提升回归树,对比深度和学习率对模型的影响。GradientBoostingClassifier()默认使用100棵树,最大深度为3,学习率0.1.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0)
grbt=GradientBoostingClassifier(random_state=0).fit(X_train,y_train)
grbt1=GradientBoostingClassifier(random_state=0,max_depth=1).fit(X_train,y_train)#深度限制为1
grbt0=GradientBoostingClassifier(random_state=0,learning_rate=0.01).fit(X_train,y_train)#将学习率变为0.01
print("train acc: {:.3f}".format(grbt.score(X_train,y_train)))
print("test acc: {:.3f}\n".format(grbt.score(X_test,y_test)))
print("train acc: {:.3f}".format(grbt1.score(X_train,y_train)))
print("test acc: {:.3f}\n".format(grbt1.score(X_test,y_test)))
print("train acc: {:.3f}".format(grbt0.score(X_train,y_train)))
print("test acc: {:.3f}".format(grbt0.score(X_test,y_test)))
输出:
train acc: 1.000
test acc: 0.965
train acc: 0.991
test acc: 0.972
train acc: 0.988
test acc: 0.965
可以看出当使用默认值时,训练精度为1,所以很可能存在过拟合。所以为了降低过拟合,通过限制最大深度的方式来加强预剪枝,将max_depth设置为1,能缓解过拟合。减小树的深度提升了模型性能,降低学习率提高的泛化性能。
梯度提升决策树的主要缺点是要调参,主要参数有树的数量n_estimators和学习率learning_rate。