使用Jsoup解析网页
之前已经发表过一篇使用HtmlParser类来解析视频网站的教程
http://blog.csdn.net/gfd54gd5f46/article/details/54960538
我发现htmlparser类太旧了,而且用起来语法也不清晰。
所以我又找来一个更强大的解析网页的工具类:Jsoup 来帮助我们制作更强大的网络爬虫
下载Jsoup类
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jar包地址:
http://jsoup.org/packages/jsoup-1.8.1.jar
构建Maven项目自动下载jar包:
http://blog.csdn.net/gfd54gd5f46/article/details/54973954
Jsoup在线API文档:
http://tool.oschina.net/apidocs/apidoc?api=jsoup-1.6.3
Jsoup开发指南:
http://www.open-open.com/jsoup/attributes-text-html.htm
解析网页
我这里就找一个图片网站来进行测试
http://www.nipic.com/index.html
1、获取单张图片的下载地址
- 随便点击一张首页的图片
进去之后我们发现这个页面只是图片的列表,我们要获取的是单个图片的地址,所以还需要点击进去查找
点击第一张图片,查看到了单张图片
同样,我们要对这个页面进行分析,找到规律来获取这张图片的地址链接
F12进入调试页面
(调试页地址:http://www.nipic.com/show/16519633.html)
观察规律发现:
图片的下载地址在src属性下
图片有个唯一的id属性:J_worksImg
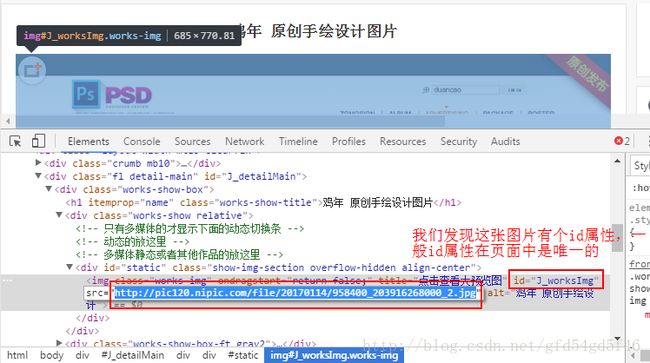
找到规律后,我们就来使用Jsoup来获取一下图片的下载地址
- 代码实现:
/**
* 通过子页面链接(图片网页)获取到图片下载地址
* "http://www.nipic.com/show/16519633.html"
* @return downloadPicUrl
*/
public static List getPicDownUrlFromAllPicPage(String url) {
//保存图片的下载地址
List list = new ArrayList();
try {
//通过传入一个url打开一个链接并且获取内容,将内容存到文件中
Document doc = Jsoup.connect(url).get();
//如果文档不为空 && 页面中没有出现 “唔,未找到任何页面!!!” 则认为该页面是个正常页面
if (doc != null && !Jsoup.connect(url).get().html().contains("唔,未找到任何页面!!!")) {
//获取到网页的唯一的id元素
Element element = doc.getElementById("J_worksImg");
//判断元素不为空 && src里面的内容不为空
if (element != null && !element.attr("src").equals("")) {
//将图片地址添加到集合中
list.add(element.attr("src"));
}
}
} catch (IOException e) {
e.printStackTrace();
}
//http://pic120.nipic.com/file/20170114/958400_203916268000_2.jpg
return list;
}
Main方法()
public static void main(String[] args) {
//程序第一个运行的时间(毫秒)
long begin = System.currentTimeMillis();
List list = getPicDownUrlFromAllPicPage("http://www.nipic.com/show/16519633.html");
for (String string : list) {
System.out.println("图片下载地址:" + string);
}
//输出程序最后所花费的时间
System.out.println("\n\n用时:" + (System.currentTimeMillis() - begin)/1000f + "s");
}
这样我们就拿到了图片的下载地址了

对下载地址进行切割
我们可以再写一个方法,将每个图片的下载链接进行切割,拿到图片名
/**
* 将图片下载地址进行切割,得到文件名
* 根据传入的url地址,获取文件的名称
* @param url
* @return name
*/
public static String getNameFromUrl(String url) {
//找到最后一个 "/" 的位置
int beginIndex = url.lastIndexOf("/");
//截取 "/" 后面的内容
String name = url.substring(beginIndex + 1);
return name;
}
将刚刚的图片下载地址放进去
System.out.println(getNameFromUrl("http://pic120.nipic.com/file/20170114/958400_203916268000_2.jpg"));
这样就拿到了图片名,方便后续保存工作

2、获取单个列表里面所有的图片介绍页面
既然我们能通过图片介绍页面来获取到图片的下载地址,那我们能不能把整一个图片列表的所有图片介绍页面都获取到呢?
我们分析一下图片列表的网页
http://www.nipic.com/topic/show_27036_1.html?ll
定位到第一张图片发现 这个介绍页面有一个class属性 ,并且有个值:block works-detail hover-none
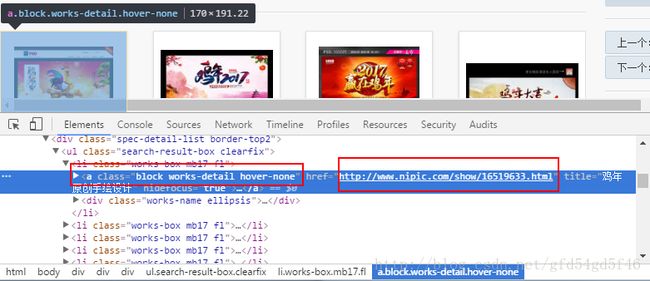
查找一下这个值发现 有40条数据,而且都是我们所关注的内容

既然知道了规律之后,那我们就来获取一下这个列表下的所有图片介绍页面
- 代码实现:
/**
* 获取分页里的所有的子页面地址
* @param OnePage 传入一个图片列表页面
* "http://www.nipic.com/topic/show_27036_1.html"
*/
public static List getAllPicPageFromOnePage(String OnePage) {
List list = new ArrayList();
try {
Document doc = Jsoup.connect(OnePage).get();
//获取所有包括该class属性的元素
Elements elements = doc.getElementsByClass("block works-detail hover-none");
System.out.println("当前页面有:" + elements.size() + " 子页面\n");
for (Element element : elements) {
//将获取到的元素添加到集合
list.add(element.attr("href"));
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
Main方法
public static void main(String[] args) {
//程序第一个运行的时间(毫秒)
long begin = System.currentTimeMillis();
List list = getAllPicPageFromOnePage("http://www.nipic.com/topic/show_27036_1.html");
for (String string : list) {
System.out.println(string);
}
//输出程序最后所花费的时间
System.out.println("\n\n用时:" + (System.currentTimeMillis() - begin)/1000f + "s");
}
确实获取到了我们想要的这40个页面

3、获取所有的分页列表页面
既然我们能通过一个列表页面来获取所有的图片介绍页面,那么我们能不能获取到所有的列表页面的呢?
我们继续来分析页面
http://www.nipic.com/topic/show_27036_1.html?ll
从网页源码中可以发现,每个列表页面链接都有一个class属性,并且属性里面都包涵有“ eo-page-num“ 的内容
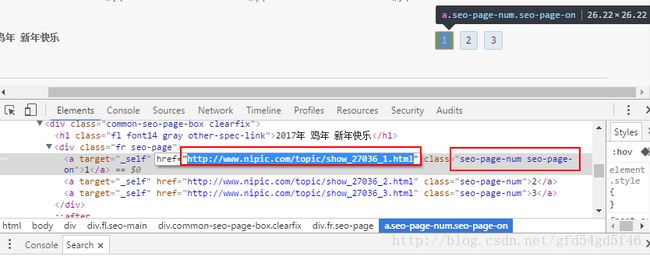
查找一下整个页面有多少包涵“eo-page-num”内容的数据
- 发现只有3个地方有这个页面(也就是说只有3个列表)
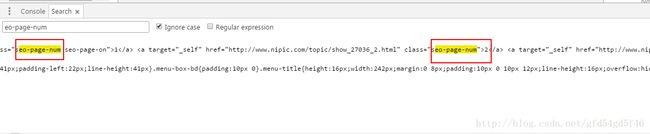
知道规律之后,我们就来获取一下这个页面的所有分页列表
- 代码实现
/**
* 获取所有的图片列表页面
* "http://www.nipic.com/topic/show_27036_1.html?ll"
*/
public static List getAllPicPage(String url) {
List list = new ArrayList();
try {
Document doc = Jsoup.connect(url).get();
//获取所有包括该class属性的元素
Elements elements = doc.getElementsByClass("seo-page-num");
System.out.println("共有:" + elements.size() + " 个分页");
for (Element element : elements) {
//将元素中的href值添加到集合中
list.add(element.attr("href"));
System.out.println(element.attr("href"));
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
Main方法()
public static void main(String[] args) {
//程序第一个运行的时间(毫秒)
long begin = System.currentTimeMillis();
List list = getAllPicPage("http://www.nipic.com/topic/show_27036_1.html");
for (String string : list) {
System.out.println(string);
}
//输出程序最后所花费的时间
System.out.println("\n\n用时:" + (System.currentTimeMillis() - begin)/1000f + "s");
}
确实获取到了所有的列表页面
http://www.nipic.com/topic/show_27036_1.html
http://www.nipic.com/topic/show_27036_2.html
http://www.nipic.com/topic/show_27036_3.html

实战
下载所有列表的图片:
1、 获取所有的列表页面
2、 获取每个列表页面的所有图片介绍页面
3、 通过介绍页面获取下载地址
4、 对下载地址进行切割拿到图片名
5、 通过下载链接跟图片名,将所有的图片下载到images目录
在项目下创建一个images目录用来保存图片
- 代码实现
package com.lingdu.jsoup;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 下载图片Demo
* 2017-2-10
* LingDu
*/
public class GetPicDemo {
/**
* 5、下载图片
* 到nipic网站下载图片
* 传入图片下载地址即可下载到images目录下
*/
public static void downloadPic(String myUrl) {
if (!myUrl.equals("")) {
try {
URL url = new URL(myUrl);
BufferedInputStream bis = new BufferedInputStream(url.openConnection().getInputStream());
byte myArray[] = new byte[1024*1024];
int len = 0;
String fileName = getNameFromUrl(myUrl);
//System.out.println(fileName);
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("images/" + fileName));
while((len = bis.read(myArray)) != -1){
bos.write(myArray, 0, len);
}
bos.flush();
bos.close();
bis.close();
System.out.println("图片:" + fileName +" ------>下载成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 4、将图片下载地址进行切割,得到文件名
* 根据传入的url地址,获取文件的名称
* @param url
* @return name
*/
public static String getNameFromUrl(String url) {
//找到最后一个 "/" 的位置
int beginIndex = url.lastIndexOf("/");
//截取 "/" 后面的内容
String name = url.substring(beginIndex + 1);
return name;
}
/**
* 3、通过子页面链接(图片网页)获取到图片下载地址
* "http://www.nipic.com/show/16519633.html"
* @return downloadPicUrl
*/
public static List getPicDownUrlFromAllPicPage(String url) {
//保存图片的下载地址
List list = new ArrayList();
try {
//通过传入一个url打开一个链接并且获取内容,将内容存到文件中
Document doc = Jsoup.connect(url).get();
//如果文档不为空 && 页面中没有出现 “唔,未找到任何页面!!!” 则认为该页面是个正常页面
if (doc != null && !Jsoup.connect(url).get().html().contains("唔,未找到任何页面!!!")) {
//获取到网页的唯一的id元素
Element element = doc.getElementById("J_worksImg");
//判断元素不为空 && src里面的内容不为空
if (element != null && !element.attr("src").equals("")) {
//将图片地址添加到集合中
list.add(element.attr("src"));
}
}
} catch (IOException e) {
e.printStackTrace();
}
//http://pic120.nipic.com/file/20170114/958400_203916268000_2.jpg
return list;
}
/**
* 2、获取分页里的所有的子页面地址
* @param OnePage 传入一个图片列表页面
* "http://www.nipic.com/topic/show_27036_1.html"
*/
public static List getAllPicPageFromOnePage(String OnePage) {
List list = new ArrayList();
try {
Document doc = Jsoup.connect(OnePage).get();
//获取所有包括该class属性的元素
Elements elements = doc.getElementsByClass("block works-detail hover-none");
System.out.println("当前页面有:" + elements.size() + " 子页面\n");
for (Element element : elements) {
//将获取到的元素添加到集合
list.add(element.attr("href"));
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
/**
* 1、获取所有的图片列表页面
* "http://www.nipic.com/topic/show_27036_1.html?ll"
*/
public static List getAllPicPage(String url) {
List list = new ArrayList();
try {
Document doc = Jsoup.connect(url).get();
//获取所有包括该class属性的元素
Elements elements = doc.getElementsByClass("seo-page-num");
System.out.println("共有:" + elements.size() + " 个分页");
for (Element element : elements) {
//http://www.nipic.com/topic/show_27036_1.html
//http://www.nipic.com/topic/show_27036_2.html
//http://www.nipic.com/topic/show_27036_3.html
//将元素中的href值添加到集合中
list.add(element.attr("href"));
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
/**
* 这个方法处理所有逻辑
*/
public static void downloadAll() {
//拿到图片列表页面
List picPagelist = new ArrayList();
//拿到所有图片下载页面
List allPicPageList = new ArrayList();
//拿到图片的下载地址
List picDownUrlList = new ArrayList();
picPagelist = getAllPicPage("http://www.nipic.com/topic/show_27036_1.html?ll");
for (String str : picPagelist) {
System.out.println("\n页面:----------------->" + str);
allPicPageList = getAllPicPageFromOnePage(str);
for (String str1 : allPicPageList) {
try {
picDownUrlList = getPicDownUrlFromAllPicPage(str1);
for (String str2 : picDownUrlList) {
downloadPic(str2);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
//程序第一个运行的时间(毫秒)
long begin = System.currentTimeMillis();
//调用所有方法的整合体
downloadAll();
//输出程序最后所花费的时间
System.out.println("\n\n用时:" + (System.currentTimeMillis() - begin)/1000f + "s");
}
}
这样就下载到了所有的图片了

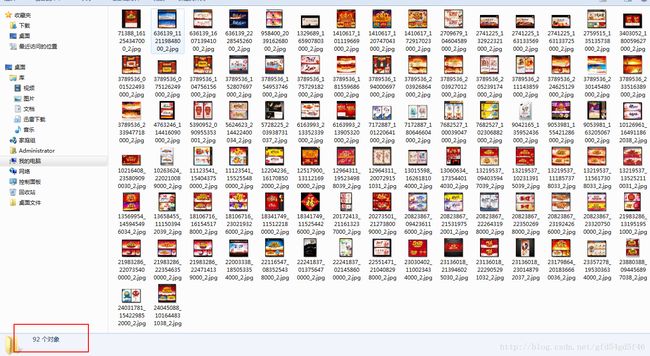
查看一下images目录 ,确实把所有列表的图片都下载下来了,总共有92张图片
实现原理
分析网页找到规律
依次往下嵌套循环即可获取到下载地址
最终完成下载