手工获取SARIMA模型参数的简介
背景:SARIMA,简单说就是AR+MA+差分+季节性因素+趋势。所以参数在statsmodels.tsa.statespace.sarimax.SARIMAX里边,用3个指标涵盖核心参数,
order(p,d,q)、seasonal_order(P,D,Q,s)和trend.
Seasonal AutoRegessive Integrated Moving Average with eXogenous regressors model
一、步骤的文字描述:
"""准备阶段"""
# 第一、定义一个待传入参数的模型,及模型评分
# 第二、定义一组要测试的参数组合
"""开始"""
# 第三、定义一个函数,记录各个参数组合及传入模型后的评分
# 第四、选择评分最优的一组参数组合,组成模型
# 第五、使用模型
二、代码:(在原文基础上有调整)
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.metrics import mean_squared_error
import pandas as pd
import warnings
import joblib
from multiprocessing import cpu_count
def walk_forward_validation(data, n_test, cfg):
# 定义一个给一套参数cfg打分的函数
predictions = []
train, test = data[:-n_test], data[-n_test:]
history = [i for i in train]
for x in range(len(test)):
order, sorder, trend = cfg
model = SARIMAX(history,
order=order, seasonal_order=sorder, trend=trend,
enforce_stationarity=False,
enforce_invertibility=False)
model.fit(disp=False)
yhat = model_fit.predict(len(history), len(history))
predicions.append(yhat)
history.append(test[x])
error = mean_squared_error(test, predictions)
return error
def score_model(data, n_test, cfg, debug=False):
# 记录下一套参数,以及该参数下模型的得分
key = str(cfg)
if debug:
error = walk_forward_validation(data, n_test, cfg)
else:
try:
with warnings.catch_warnings():
warnings.filterwarnings('ignore')
error = warlk_forward_validation(data, n_test, cfg)
except:
error=None
if error is not None:
print(f'> Model{key} {error:.3f}')
return key, error
def grid_search(data, cfg_list, n_test, parallel=True):
# 把所有参数组合一一带入模型,并把所有参数组合及其对应模型得分记录下来,排序。
if parallel:
executor = joblib.Parallel(n_jobs=cpu_count(),
backend='multiprocessing')
tasks = (joblib.delayed(score_model)(data, n_test, cfg) for cfg in cfg_list)
scores = executor(tasks)
else:
scores = [score_model(data, n_test, cfg) for cfg in cfg_list]
scores = [r for r in scores if r[1] != None]
scores.sort(key=lambda tup: tup[1)
return scores
def sarima_config():
# 造出自己预估的所有参数组合list
cfg_list = []
p_params = [0, 1, 2]
d_params = [0, 1]
q_params = [0, 1, 2]
P_params = [0, 1, 2]
D_params = [0, 1]
Q_params = [0, 1, 2]
s = [2, 4, 12]
t = ['n', 'c', 't', 'ct']
for p in p_params:
for d in d_params:
for q in q_params:
for P in P_params:
for D in D_params:
for Q in Q_params:
for s in s:
for t in t:
cfg = [(p,d,q), (P,D,Q,s),t]
cfg_list.append(cfg)
return cfg_list
if __name__ == '__main__':
df = pd.read_csv('filepath+filename.csv')
data = df.values
n_test = number_of_test
cfg_list = sarima_config()
scores = grid_search(data, cfg_list, n_test)
print('Done')
for cfg, error in scores[:5]: # 取出前5个最优的参数组合及对应的模型得分
print(cfg, error)
三、其他
pmdarima.arima.aotu_arima()可以自动使用训练数据集得到参数。但是很多人都不用它,应该是因为它找到的参数并不怎么好的缘故。
例如,如下的原始数据使用pmdarima.arima.auto_arima(),没有手工测试得到的好:
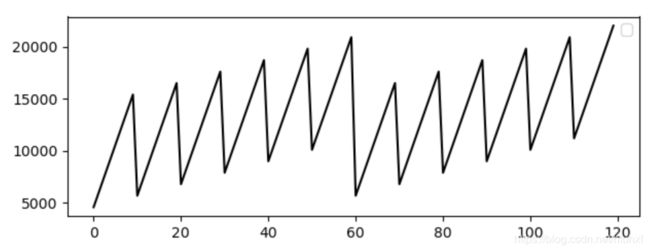 直接使用的话并不好
直接使用的话并不好
import numpy as np
import pmdarima as pm
import matplotlib.pyplot as plt
from pmdarima.model_selection import train_test_split
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('path+filename')
y = df.values
train, test = train_test_split(y, train_size=0.7)
model = pm.arima.auto_arima(train, seasonal=True, m=10)
# m等于(P,D,Q,s)的s。m=10是通过线图,肉眼观察得到的。(原始数据x是时间)
print(model.summary())
forecasets = model.predict(len(test))
x = np.arange(len(train))
plt.plot(x, y, c='black')
plt.plot(x[len(train):], forecasets, c='blue')
plt.show()
结果&图如下:
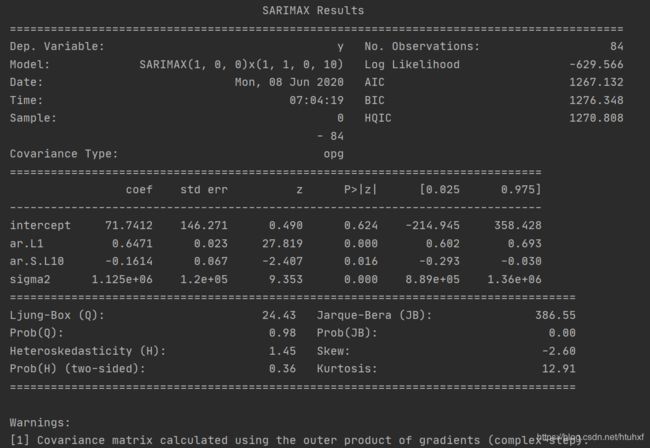
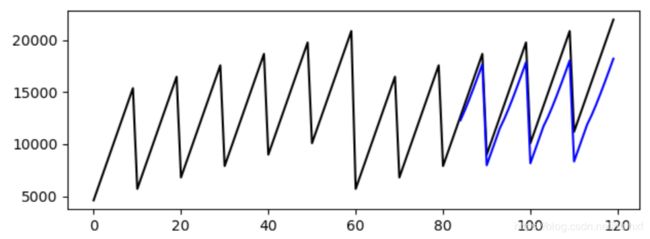
,作为对比使用最上边得到的参数貌似更好些,从AIC/BIC/HQIC看:
 代码如下
代码如下
from statsmodels.tsa.statespace.sarimax import SARIMAX
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from pmdarima.model_selection import train_test_split
import warnings
df = pd.read_csv('path+filename')
y = df.values
x = np.arange(len(y))
warnings.filterwarings('ignore')
train, test = trains_test_split(y, train_size=0.7)
model = SARIMAX(train,
order = (0, 1, 0),
seasonal_order=(2, 1, 0, 10),
trend='n') # 利用我们手动测试出来的最优参数组合
model_fit = model.fi(disp=False)
print(model_fit.summery())
f = model_fit.predict(1, end=len(y)+10)
plt.plot(x, y, c='black')
plt.plot(np.arange(len(y)+10), f, c='blue')
plt.show()
