牛客网-专项练习
牛客网刷题记录
文章目录
- 1. 数据结构
- 2. 数学和逻辑
- 2.1. 组合数学
- 2.2. 概率统计
- 合格品的题目
- 贝叶斯
- 前后有概率
- 抛硬币:胜利条件不同
- 独立事件和判断
- u检验的应用条件是
- 2.3. 智力题
- 3. 计算机基础
- 3.1. 数据库
- 在数据库的三级模式结构中,描述数据库中全体数据的全局逻辑结构和特征的是(模式)。
- 关系规范化中的插入操作异常是指 。
- 实体是信息世界中的术语,与之对应的数据库术语为( )。
- 概念模型是()
- 按所使用的数据模型来分,数据库可分为 三种模型( )。
- 在概念模型中,客观存在并可以相互区别的事物称为( C )**
- 用树型结构来表示实体之间联系的模型称为( A )**
- 数据库管理系统是()。
- 在数据库设计中,用E-R图来描述信息结构但不涉及信息在计算机中的表示,它是数据库设计的( )阶段。**
- 用户 user 要收回 user1 用户具有对 book 表修改的权限,正确的语句是 ( )。**
- 有一名为“列车运营”实体,含有:车次、日期、实际发车时间、实际抵达时间、情况摘要等属性,该实体主码是( )
- 现有表user,字段:userid,username, salary, deptid,email; 表department,字段:deptid, deptname;下面应采用检查约束来实现?
- 设有关系 R ( A , B , C )的值如下,函数依赖
- 数据库管理系统的工作不包括? ( )
- 以下()不是Access的数据库对象。
- 在SQL中,删除视图用( )。
- 下列SQL 语句中,修改表结构的是()。
- 在 E-R图中,一个联系可以是孤立存在的。
- 关系数据模型的三个组成部分中,不包括()。
- 事务的持续性是指?
- 关于锁的说法,以下正确的是( )
- 候选码中的属性可以有( )
- 数据库管理系统(DBMS)是一种应用软件。请问这句话的说法是正确的吗?
- 在数据库系统的组织结构中,下列( )映射把用户数据库与概念数据库联系起来。
- 已知T1和T2的字段定义完全相同,T1有5条不同数据,T2有5条不同数据,其中T1有2条数据存在表T2中,语句“SELECT * FROM T1 UNION SELECT * FROM T2”返回的行数为()
- 同一个关系模型的任两个元组值( )。
- 假设Students表中有主键SCode,Score表中有外键 stuNo列,stuNo引入Scode列来实施引用完整性约束,此时如果使用SQL
- DBMS提供DML实现对数据的操作。嵌入高级语言中使用的 DML称为()
- 并发操作会带来哪些数据不一致性()
- Web程序通常采用MVC架构来设计,数据库相关操作属于()?
- 3.2. 编程基础
- 4. 软件开发
- 4.1. 软件工程
- 4.2. Linux
- 4.3. 数理统计
- 4.4. 机器学习
- 下列属于无监督学习的是:
- 在其他条件不变的前提下,以下哪种做法容易引起机器学习中的过拟合问题()
- 在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计()
- 下面有关序列模式挖掘算法的描述,错误的是?
- 数据清理中,处理缺失值的方法是?
- 在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本为10w条数据,负样本只有1w条数据,以下最合适的处理方法是()
- 下列哪些方法可以用来对高维数据进行降维:
- 深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为m*n,n*p,p*q,且m
1. 数据结构
2. 数学和逻辑
2.1. 组合数学
2.2. 概率统计
合格品的题目
某种产品,合格品率为0.96,一个合格品被检查成次品的概率是0.02,一个次品被检查成合格品的概率为0.05,问题:求一个被检查成合格品的产品确实为合格品的概率()
0.9978
0.9991
0.9855
0.96
正确答案: A 解析:
题目所求的是被检查是合格品的物品确实是合格品的概率,即分析物品被检查为合格品包括哪几种情况,第一:合格品被检查为合格品;第二:次品被检查为合格品。
所求概率为(合格,检查正确)/((合格,检查正确)+(不合格,检查错误))=(0.960.98)/((0.960.98)+(0.04*0.05))=0.9978
贝叶斯
S市A,B共有两个区,人口比例为3:5,据历史统计A的犯罪率为0.01%,B区为0.015%,现有一起新案件发生在S市,那么案件发生在A区的可能性有多大?()
- 贝叶斯公式
- 含有%的概率题,可以实例化是最好的方式。故而,B区5000人,A区3000人,A区30个罪犯,B区75个罪犯。那么狠显然30/(30+75)=0.2857,就是C。
前后有概率
一个英雄基础攻击力为100,携带了三件暴击武器,武器A有40%的概率打出2倍攻击,武器B有20%的概率打出4倍攻击,武器C有10%概率打出6倍攻击,各暴击效果触发是独立事件,但是多个暴击效果在一次攻击中同时触发时只有后面武器的暴击真正生效,例如一次攻击中武器A判定不暴击,武器B和武器C都判定触发暴击,那么这次攻击实际是600攻击力。那么这个英雄攻击力的数学期望是____。
186.6
200
232.8
256.8
320
332.6
正确答案: C
解析
(600 * 10%) // 使用武器C
+(400* 90% * 20% ) // 使用武器B,需要保证没有使用武器C,否则因为多个暴击效果在一次攻击中同时触发时只有后面武器的暴击真正生效,武器B不生效
+(200 * 90% * 80% * 40%) // 同理,使用武器A,需要保证武器B和C都没有使用
+(100*60%*80%*90%)// 没有使用任何武器
= 232.8
抛硬币:胜利条件不同
【1】硬币游戏:连续扔硬币,直到某一人获胜。A获胜条件是先正后反,B获胜是出现连续两次反面,问AB游戏时A获胜概率是()?
1/3
1/2
2/3
3/4
解析:
从第一次抛硬币开始计算
假设第一次是:正,概率是1/2
第二次如果是 反 则A赢,如果是正,则都不赢,继续抛,直道出现 反 也就是A赢为止。也就是说在第一次结果为 正 的情况下A必赢
假设第一次是:反,概率是1/2。第二次如果是 反 则B赢,概率是1/2,如果是 正 则又出现A必赢的情况
所以A赢的概率是1/2+(1/2)(1/2)=3/4,B赢的概率是(1/2)(1/2)=1/4。
独立事件和判断
设A,B,C 为三个事件,且A,B 相互独立,则以下结论中不正确的是
A. 若PC=1,则AC与BC也独立.
B. 若PC=1,则A并C与B也独立.
C. 若PC=0,则A并C与B也独立.
D. 若C属于B,则A与C也独立.
正确答案:D
解析:
- C是全概率事件,A交C仍为A,B交C仍为B
- A并C实际上就是C。
P ( A ⋃ C ) = P ( C ) = 1 P ( B C ) = P ( B ⋂ C ) = P ( B ) = P ( B ) ∗ P ( C ) P(A \bigcup C)=P(C)=1 \\ P(BC)=P(B\bigcap C)=P(B)=P(B)*P(C) P(A⋃C)=P(C)=1P(BC)=P(B⋂C)=P(B)=P(B)∗P(C) - 类似第二选项。而A本来就和B独立。
P ( A ⋃ C ) = P ( A ) P(A \bigcup C)=P(A) P(A⋃C)=P(A) - 反例:如果C属于B,但是C不属于A和B的交集(也就是独立的部分),则A和C肯定无法交到一起。也就是 P ( A C ) = 0 P(AC)=0 P(AC)=0, P ( A ) P ( C ) ≠ 0 P(A)P(C) \neq 0 P(A)P(C)̸=0
u检验的应用条件是
样本例数n较大或样本例数数量虽小但总体标准差已知
两样本来自得总体符合正态分布
两样本来自得总体符合正态分布,且两样本来子的总体方差齐性
两样本方差相等
正确答案: A
解析:
u检验和t检验可用于样本均数与总体均数的比较以及两样本均数的比较。
理论上要求样本来自正态分布总体。但在实用时,只要样本例数n较大(样本标准差s作为总体标准差σ的估计值),或n小但总体标准差σ已知时,就可应用u检验;
n小且总体标准差σ未知时,可应用t检验,但要求样本来自正态分布总体。两样本均数比较时还要求两总体方差相等。
2.3. 智力题
3. 计算机基础
3.1. 数据库
在数据库的三级模式结构中,描述数据库中全体数据的全局逻辑结构和特征的是(模式)。
外模式
内模式
存储模式
模式
首先数据库的三级模式不包括C。
A.外模式是模式的一个子集,不同用户从不同角度部分看待数据库的方式,当前用户视图也是外模式,面向用户(对外)。
B.内模式,物理机构和存储方式的描述,比如存储范式是顺序的还是hash的等,面向物理存储器件(对内)。
D.模式,即概念模式/逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
对于C.存储模式,一般企业针对数据的安全性考虑,将存储模式分为DAS( Direct-Attached Storage )、NAS( Network-Attached Storage)、SAN( Storage Area Network )
关系规范化中的插入操作异常是指 。
不该删除的数据被删除
不该插入的数据被插入
应该删除的数据未被删除
应该插入的数据未被插入
解析:
在对数据库进行一些操作的时候我们可能会遇到以下的一些问题:
数据冗余(想修改一个属性,就要更新多行数据)
插入异常(想要插入数据,结构因为表设计的问题,导致不能成功插入)
删除异常(只想删除其中的某些数据 ,结果把不该删的也删了)------对应【不该删除的数据被删除】
更新异常(想更新一条数据,结果工作量大,还容易出错)
实体是信息世界中的术语,与之对应的数据库术语为( )。
文件
数据库
字段
记录
记录就是数据库的一行数据,比如(“张三”, “50”),对应的就是实体
一个实体有多个属性对应一条记录中的多个字段。
概念模型是()
硬件独立,软件独立
硬件独立,软件依赖
硬件依赖,软件独立
硬件依赖,软件依赖
按所使用的数据模型来分,数据库可分为 三种模型( )。
层次、关系和网状
网状、环状和链状
大型、中型和小型
独享、共享和分时
解析:
对象模型
层次模型(轻量级数据访问协议)
网状模型(大型数据储存)
关系模型
面向对象模型
半结构化模型
平面模型(表格模型,一般在形式上是一个二维数组。如表格模型数据Excel)
在概念模型中,客观存在并可以相互区别的事物称为( C )**
A、物体 B、物质 C、实体 D、个体
用树型结构来表示实体之间联系的模型称为( A )**
A、层次模型 B、关系模型 C、运算模型 D、网状模型
数据库管理系统是()。
操作系统的一部分
在操作系统支持下的系统软件
一种编译程序
一种操作系统
解析:
DB:大量数据的集合
DBS:系统软件
DBMS:包含DB、DBS、DBA等
在数据库设计中,用E-R图来描述信息结构但不涉及信息在计算机中的表示,它是数据库设计的( )阶段。**
需求分析
概念设计
逻辑设计
物理设计
解析:
E(实体)-R(关系)图、属于概念设计阶段。需求分析用到的是数据流(程)图,得到的数据字典。逻辑设计得到关系模式。
示例

用户 user 要收回 user1 用户具有对 book 表修改的权限,正确的语句是 ( )。**
revoke update on book to user
revoke update on book from user
revoke update on book to user1
revoke update on book from user1
授权修改权限:参考
1.GRANT OPTION 将自己的权限授予其他用户
2.MAX_QUERIES_PER_HOUR count 设置每小时最多可以执行多少次count查询
3.MAX_UPDATES_PER_HOUR count 设置每小时最多可以执行多少次count更新
4.MAX_CONNECTIONS_PER_HOUR count 设置没小时最大的连接数量
5.MAX_USER_CONNECTIONS 设置每个用户最大的建立连接数
6.授予user4有INSERT权限 GRANT INSERT ON . TO ‘user4’@‘localhost’;
7.创建一个具有insert和select权限的 user4普通用户密码为123
GRANT INSERT,SELECT ON . TO ‘user4’@‘localhost’ IDENTIFIED BY ‘123’ WITH GRANT OPTION;
8.查询账户权限:show grants for ‘user4’@‘localhost’\G
收回权限
收回INSERT权限:REVOKE INSERT ON . FROM ‘user4’@‘localhost’;
收回所有权限:REVOKE ALL PRIVILEGES,GRANT OPTION FROM ‘user4’@‘localhost’;
有一名为“列车运营”实体,含有:车次、日期、实际发车时间、实际抵达时间、情况摘要等属性,该实体主码是( )
车次
日期
车次+日期
车次+情况摘要
现有表user,字段:userid,username, salary, deptid,email; 表department,字段:deptid, deptname;下面应采用检查约束来实现?
若department中不存在deptid为2的纪录,则不允许在user表中插入deptid为2的数据行。
若user表中已经存在userid为10的记录,则不允许在user表中再次插入userid为10的数据行
User表中的salary(薪水)值必须在1000元以上。
若User表的email列允许为空,则向user表中插入数据时, 可以不输入email值。
解析:
选C:用检查约束(check)来检查输入数值的合法性
alter table user
add constraint CK_SALARY check(salary > 1000)
A:外键约束Foreign Key,选项中说明了department与user两张表的数据具有相关约束性
alter table user
add constraint CK_DEPID foreign key(depid) references department (depid)
B:唯一性约束Unique,确保userid字段不重复
add constraint CK_USERID unique(userid)
D:没用到约束
设有关系 R ( A , B , C )的值如下,函数依赖

函数依赖A→B在上述关系中成立
函数依赖BC→A在上述关系中成立
函数依赖B→A在上述关系中成立
函数依赖A→BC在上述关系中成立
解析:类似于函数映射
函数依赖成立需要某个属性集唯一决定另一个属性集
A中,2->2,2->3,A不能唯一决定B
B中,(2,3)->2,(3,4)->2,(2,5)->3,BC能唯一决定A,选B
C中,2->2,2->3,A不能唯一决定B
D中,2->(2,3),2->(3,4),A不能唯一决定BC
数据库管理系统的工作不包括? ( )
定义数据库
对已定义的数据库进行管理
为定义的数据库提供操作系统
数据通信
解析:
主要工作:
1.数据定义:DBMS提供数据定义语言DDL(Data Definition Language),供用户定义数据库的三级模式结构、两级映像以及完整性约束和保密限制等约束。DDL主要用于建立、修改数据库的库结构。DDL所描述的库结构仅仅给出了数据库的框架,数据库的框架信息被存放在数据字典(Data Dictionary)中。
2.数据操作:DBMS提供数据操作语言DML(Data Manipulation Language),供用户实现对数据的追加、删除、更新、查询等操作。
3.数据库的运行管理:数据库的运行管理功能是DBMS的运行控制、管理功能,包括多用户环境下的并发控制、安全性检查和存取限制控制、完整性检查和执行、运行日志的组织管理、事务的管理和自动恢复,即保证事务的原子性。这些功能保证了数据库系统的正常运行。
4.数据组织、存储与管理:DBMS要分类组织、存储和管理各种数据,包括数据字典、用户数据、存取路径等,需确定以何种文件结构和存取方式在存储级上组织这些数据,如何实现数据之间的联系。数据组织和存储的基本目标是提高存储空间利用率,选择合适的存取方法提高存取效率。
5.数据库的保护:数据库中的数据是信息社会的战略资源,所以数据的保护至关重要。DBMS对数据库的保护通过4个方面来实现:数据库的恢复、数据库的并发控制、数据库的完整性控制、数据库安全性控制。DBMS的其他保护功能还有系统缓冲区的管理以及数据存储的某些自适应调节机制等。
6.数据库的维护:这一部分包括数据库的数据载入、转换、转储、数据库的重组合重构以及性能监控等功能,这些功能分别由各个使用程序来完成。
7.通信:DBMS具有与操作系统的联机处理、分时系统及远程作业输入的相关接口,负责处理数据的传送。对网络环境下的数据库系统,还应该包括DBMS与网络中其他软件系统的通信功能以及数据库之间的互操作功能。
以下()不是Access的数据库对象。
表
查询
窗体
宏操作
解析:
Access的数据库对象:
1、表:主要用于存储数据。
2、查询 主要用于提取数据。
3、窗体 用户与程序的交互。
4、报表, 主要用于展示数据。
5、页, 主要用于数据共享。
6、宏, 用于自动化完成。
宏和表,查询,窗体,报表一样都是Access数据库对象
宏是一系列操作的集合,每个操作都自动完成特定功能,D错在应该是宏,而不是宏操作
在SQL中,删除视图用( )。
DROP SCHEMA命令
CREATE TABLE命令
DROP VIEW命令
DROP INDEX命令
菜鸟-view视图的用法
SQL CREATE VIEW 语法
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
注释:视图总是显示最新的数据!每当用户查询视图时,数据库引擎通过使用视图的 SQL 语句重建数据。
Northwind 样本数据库的另一个视图会选取 “Products” 表中所有单位价格高于平均单位价格的产品:
CREATE VIEW [Products Above Average Price] AS
SELECT ProductName,UnitPrice
FROM Products
WHERE UnitPrice>(SELECT AVG(UnitPrice) FROM Products)
阿里云课件
CREATE SCHEMA:创建SCHEMA/DATABASE
CREATE TABLE:创建表
DROP SCHEMA:删除SCHEMA/DATABASE
DROP TABLE:删除表
SELECT:查询
MSCK REPAIR TABLE:同步OSS数据源上实际的数据分区信息到元数据中
SHOW SCHEMAS:查询用户所有的SCHEMA/DATABASE
SHOW TABLES:查询用户当前SCHEMA下的表
SHOW CREATE TABLE:查看建表语句
SHOW PARTITIONS:列出表的所有分区信息
SHOW QUERY_TASK:查询用户的查询任务信息
GRANT:为账号授权
REVOKE: 撤销账号权限
ALTER TABLE: 更改分区表分区
index索引的用法
您可以在表中创建索引,以便更加快速高效地查询数据。
用户无法看到索引,它们只能被用来加速搜索/查询。
注释:更新一个包含索引的表需要比更新一个没有索引的表更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
实例:
如果您希望以降序索引某个列中的值,您可以在列名称之后添加保留字 DESC:
CREATE INDEX PersonIndex
ON Person (LastName DESC)
假如您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:
CREATE INDEX PersonIndex
ON Person (LastName, FirstName)
下列SQL 语句中,修改表结构的是()。
ALTER
CREATE
UPDATE
INSERT
修改表结构包括:
增加字段、删除字段、增加约束、删除约束、修改缺省值、修改数据段类型、重命名字段、重命名表。所有这些字段都是ALTER TABLE执行的。
图表引用
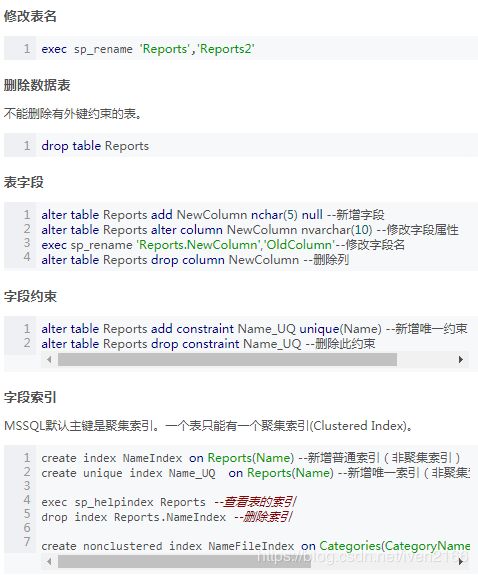
在 E-R图中,一个联系可以是孤立存在的。
正确
错误(我理解是,必定有两者,所以不会孤立存在一个联系的线)
关系数据模型的三个组成部分中,不包括()。
完整性规则
数据结构
数据操作
并发控制
关系数据模型的三个组成部分 完整性规则、 数据结构、 数据操作。
数据库管理系统中的并发控制:数据库管理系统(DBMS)中的并发控制的任务是确保在多个**事务(基本单位)**同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。下面举例说明并发操作带来的数据不一致性问题:
现有两处火车票售票点,同时读取某一趟列车车票数据库中车票余额为X。两处售票点同时卖出一张车票,同时修改余额为X -1写回数据库,这样就造成了实际卖出两张火车票而数据库中的却记录只少了一张。产生这种情况的原因是因为两个事务读入同一数据并同时修改,其中一个事务提交的结果破坏了另一个事务提交的结果,导致其数据的修改被丢失,破坏了事务的隔离性。并发控制要解决的就是这类问题。
并发控制引用



事务的持续性是指?
事务中包括的所有操作要么都做,要么不做
事务一旦提交,对数据库的改变时永久的
一个事务内部的操作及使用的数据对并发的其他事务是隔离的
事务必须是使数据库从一个一致性状态变到另一个一致性状态
解析:
- 原子性(ATOMIC) 整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节
- 一致性(Consistency)在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏
- 隔离性(Isolation)两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时中间某一时刻的数据
- 持久性(Durability)在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
非过程化:“我”让“某物”干什么事情。
过程化:“让某物怎么样去干事情”
仅仅是个人的理解:非过程化其实就是:不需要你告诉数据库管理系统(也就是常说的SQLServer、db2、Oracle、mysql那些),怎么去做,你只要告诉它们:你要做这个东西了,它们就会自己内部处理,形象一点就是你在查数据的时候不需要告诉他们到哪个物理文件,甚至哪个扇区的磁道上读数据。这里其实突出的是“高度”。而不仅仅是过程化。一般的过程化更多的是像C++的指针那种。还要细化到堆栈等等。如何循环读每一条数据,读出来还要干什么。不过我觉得真正的过程化语言可能就是机器语言或者汇编
关于锁的说法,以下正确的是( )
A.事务遵守两段锁协议是可串行化调度的充分条件而非必要条件
B.三级封锁协议可以保证并发执行一定是可串行化的
C.二级封锁协议可以防止并发控制中“不可重复读”的问题
D.事务T1(Lock(A),Lock(B),unLock(A),Lock(C),unLock(B),unLock(C))遵守两段锁协议
解析:
A. 若并发事务的一个调度是可串行化的,不一定所有事务都符合两段锁协议 。(非必要的解释)
B. 改为“遵守两阶段封锁协议的并发事务一定是可串行化的 ”。
若并发事务都遵守两段锁协议,则对这些事务的任何并发调度策略都是可串行化的 。
C. 三级封锁协议可以防止并发控制中“不可重复读”的问题
D. 应该为
例
事务Ti遵守两段锁协议,其封锁序列是 :
Slock A Slock B XlockC Unlock B Unlock A UnlockC;
|← 扩展阶段 →| |← 收缩阶段 →|
事务Tj不遵守两段锁协议,其封锁序列是:
Slock A Unlock A Slock B XlockC UnlockC Unlock B;
(事务分为两个阶段
第一阶段是获得封锁,也称为扩展阶段 。
事务可以申请获得任何数据项上的任何类型的锁,但是不能释放任何锁 。
第二阶段是释放封锁,也称为收缩阶段 。
事务可以释放任何数据项上的任何类型的锁,但是不能再申请任何锁。)
一级封锁协议是:事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。
一级封锁协议可以防止丢失修改,并保证事务T是可恢复的。使用一级封锁协议可以解决丢失修改问题。 它不能保证可重复读和不读“脏”数据。
二级封锁协议是:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后方可释放S锁。二级封锁协议除防止了丢失修改,还可以进一步防止读“脏”数据。但在二级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
三级封锁协议是:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。 三级封锁协议除防止了丢失修改和不读“脏”数据外,还进一步防止了不可重复读。
候选码中的属性可以有( )
0个
1个
1个或多个
多个
C
解析:
候选码就是可以区别一个元组(即表中的一行数据)的属性或属性的集合,比如学生表student(id,name,age,sex,deptno),其中的id是可以唯一标识一个元组的,所以id是可以作为候选码的,既然id都可以做候选码了,那么id和name这两个属性的组合可不可以唯一区别一个元组呢?显然是可以的,此时的id可以成为码,id和name的组合也可以成为码,但是id和name的组合不能称之为候选码,因为即使去掉name属性,剩下的id属性也完全可以唯一标识一个元组,就是说,候选码中的所有属性都是必须的,缺少了任何一个属性,就不能唯一标识一个元组了。
候选码下一个精确的定义就是:可以唯一标识一个元组的最少的属性集合
主属性,一个表可以有多个候选码,那么对于某个属性来说,如果这个属性存在于所有的候选码中(无法缺少它),它就称之为主属性。
数据库管理系统(DBMS)是一种应用软件。请问这句话的说法是正确的吗?
错误
它是系统软件。主要指用来运行或控制硬件所开发的计算机软件,如操作系统、解释器、编译器、数据库管理系统、公用程序等面向开发者的软件。
在数据库系统的组织结构中,下列( )映射把用户数据库与概念数据库联系起来。
外模式/模式
外模式/外模式
模式/内模式
内模式/模式
正确答案: A
解析:
数据库三级模式:外模式,(概念)模式,内模式。
用户级对应外模式,概念级对应概念模式,物理级对应内模式。
已知T1和T2的字段定义完全相同,T1有5条不同数据,T2有5条不同数据,其中T1有2条数据存在表T2中,语句“SELECT * FROM T1 UNION SELECT * FROM T2”返回的行数为()
8行
10行
3行
12行
正确答案: A
解析:
union 和union all的区别:
union会对结果集进行处理排除掉相同的结果(因此有2行相同的被删除掉),
union all 不会对结果集进行处理,不会处理掉相同的结果,
所以,union all 的效率会比union高,
另外,where也会对结果集进行处理掉相同的数据
同一个关系模型的任两个元组值( )。
https://www.nowcoder.com/test/question/done?tid=23039455&qid=86022#summary
正确答案: A 你的答案: 空 (错误)
不能全同
可全同
必须全同
以上都不是
假设Students表中有主键SCode,Score表中有外键 stuNo列,stuNo引入Scode列来实施引用完整性约束,此时如果使用SQL
https://www.nowcoder.com/test/question/done?tid=23039455&qid=86013#summary
Update Students set Scode = ‘001’ where scode = ‘002’ ___( )。
正确答案: A 你的答案: 空 (错误)
肯定会产生更新错误
可能会更新Students表中的两行数据
可能会更新Score表中的一行数据
可能会更新Students表中的一行数据
DBMS提供DML实现对数据的操作。嵌入高级语言中使用的 DML称为()
https://www.nowcoder.com/test/question/done?tid=23039455&qid=87802#summary
正确答案: C 你的答案: A (错误)
自主型
自含型
宿主型
交互型
并发操作会带来哪些数据不一致性()
https://www.nowcoder.com/test/question/done?tid=23039455&qid=92026#summary
正确答案: D 你的答案: D (正确)
丢失修改、不可重复读、脏读、死锁
不可重复读、脏读、死锁
丢失修改、脏读、死锁
丢失修改、不可重复读、脏读
Web程序通常采用MVC架构来设计,数据库相关操作属于()?
https://www.nowcoder.com/test/question/done?tid=23039455&qid=112875#summary
正确答案: A 你的答案: 空 (错误)
Model
Controller
都不属于
View
3.2. 编程基础
4. 软件开发
4.1. 软件工程
4.2. Linux
4.3. 数理统计
4.4. 机器学习
下列属于无监督学习的是:
k-means
SVM
最大熵
CRF
这题目CRF是一个干扰项,CRF是条件随机场,主要用在语音识别和文本识别【中文分词】,前提,一个标记了的观察序列,计算需要验证的标签序列的联合概率。这里就有了标记集合和识别集合的概念,所以是监督室学习
在其他条件不变的前提下,以下哪种做法容易引起机器学习中的过拟合问题()
增加训练集量
减少神经网络隐藏层节点数
删除稀疏的特征
SVM算法中使用高斯核/RBF核代替线性核
解析
造成过拟合的原因主要有:
1、训练数据不足,有限的训练数据
2、训练模型过度导致模型非常复杂,泛化能力差
选项A增加训练集可以解决训练数据不足的问题,防止过拟合
选项B对应使得模型复杂度降低,防止过拟合
选项C类似主成分分析,降低数据的特征维度,使得模型复杂度降低,防止过拟合
选项D使得模型的复杂化,会充分训练数据导致过拟合
径向基(RBF)核函数/高斯核函数的说明
这个核函数可以将原始空间映射到无穷维空间。对于参数 ,如果选的很大,高次特征上的权重实际上衰减得非常快,实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调整参数 ,高斯核实际上具有相当高的灵活性,也是 使用最广泛的核函数之一。
径向基参考1
核函数参考2
在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计()
EM算法
维特比算法
前向后向算法
极大似然估计
解析
EM算法: 只有观测序列,无状态序列时来学习模型参数,即Baum-Welch算法
维特比算法: 用动态规划解决HMM的预测问题,不是参数估计。(维特比算法解决的是给定一个模型和某个特定的输出序列,求最可能产生这个输出的状态序列。如通过海藻变化(输出序列)来观测天气(状态序列),是预测问题)
前向后向:用来算概率(隐马模型的评估问题即,在已知一个观察序列O=O1O2…OT,和模型μ=(A,B,π}的条件下,观察序列O的概率,即P(O|μ})
讲解
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数
故应选D
(参考李航《统计学习方法》)
下面有关序列模式挖掘算法的描述,错误的是?
正确答案: C
AprioriAll算法和GSP算法都属于Apriori类算法,都要产生大量的候选序列
FreeSpan算法和PrefixSpan算法不生成大量的候选序列以及不需要反复扫描原数据库
在时空的执行效率上,FreeSpan比PrefixSpan更优
和AprioriAll相比,GSP的执行效率比较高
以下解释
解析:
- Apriori算法 :关联分析原始算法,用于从候选项集中发现频繁项集。两个步骤:进行自连接、进行剪枝。缺点:无时序先后性。
AprioriAll算法:AprioriAll算法与Apriori算法的执行过程是一样的,不同点在于候选集的产生,需要区分最后两个元素的前后。
AprioriSome算法:可以看做是AprioriAll算法的改进
AprioriAll算法和AprioriSome算法的比较:
(1)AprioriAll用 去计算出所有的候选Ck,而AprioriSome会直接用去计算所有的候选,因为包含,所以AprioriSome会产生比较多的候选。
(2)虽然AprioriSome跳跃式计算候选,但因为它所产生的候选比较多,可能在回溯阶段前就占满内存。
(3)如果内存占满了,AprioriSome就会被迫去计算最后一组的候选。
(4)对于较低的支持度,有较长的大序列,AprioriSome算法要好些。 - GPS算法:类Apriori算法。用于从候选项集中发现具有时序先后性的频繁项集。两个步骤:进行自连接、进行剪枝。缺点:每次计算支持度,都需要扫描全部数据集;对序列模式很长的情况,由于其对应的短的序列模式规模太大,算法很难处理。
- SPADE算法:改进的GPS算法,规避多次对数据集D进行全表扫描的问题。与GSP算法大体相同,多了一个ID_LIST记录,使得每一次的ID_LIST根据上一次的ID_LIST得到(从而得到支持度)。而ID_LIST的规模是随着剪枝的不断进行而缩小的。所以也就解决了GSP算法多次扫描数据集D问题。
- FreeSpan算法:即频繁模式投影的序列模式挖掘。核心思想是分治算法。基本思想为:利用频繁项递归地将序列数据库投影到更小的投影数据库集中,在每个投影数据库中生成子序列片断。这一过程对数据和待检验的频繁模式集进行了分割,并且将每一次检验限制在与其相符合的更小的投影数据库中。
优点:减少产生候选序列所需的开销。缺点:可能会产生许多投影数据库,开销很大,会产生很多的 - PrefixSpan 算法:从FreeSpan中推导演化而来的。收缩速度比FreeSpan还要更快些。
http://blog.csdn.net/ztf312/article/details/50889238
数据清理中,处理缺失值的方法是?
正确答案: A B C D
估算
整例删除
变量删除
成对删除
解析:
由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法有:估算,整例删除,变量删除和成对删除。
-
估算(estimation)。最简单的办法就是用某个变量的样本均值、中位数或众数代替无效值和缺失值。这种办法简单,但没有充分考虑数据中已有的信息,误差可能较大。另一种办法就是根据调查对象对其他问题的答案,通过变量之间的相关分析或逻辑推论进行估计。例如,某一产品的拥有情况可能与家庭收入有关,可以根据调查对象的家庭收入推算拥有这一产品的可能性。
-
整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
-
变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
-
成对删除(pairwise deletion)配对状态删除适用于两两配对的变量,如果某条记录在其中一个配对变量中的数据缺失,则在进行这对配对变量的统计量计算时把含有缺失值的数据删除,在计算其他变量的统计量时不受影响。这种方法可以用于计算配对变量在无缺失值的情况下其频数、均数、标准差、协方差、协方差矩阵和相关矩阵。
英文网站解释
链接:https://www.nowcoder.com/questionTerminal/f0edfb5a59a84f10bf57af0548e3ec02
来源:牛客网
在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本为10w条数据,负样本只有1w条数据,以下最合适的处理方法是()
将负样本重复10次,生成10w样本量,打乱顺序参与分类
直接进行分类,可以最大限度利用数据
从10w正样本中随机抽取1w参与分类
将负样本每个权重设置为10,正样本权重为1,参与训练过程
正确答案: A C D
解析:
参考
解决这类问题主要分重采样、欠采样、调整权值
- 重采样。
A可视作重采样的变形。改变数据分布消除不平衡,可能导致过拟合。 - 欠采样。
C的方案 提高少数类的分类性能,可能丢失多数类的重要信息。
如果1:10算是均匀的话,可以将多数类分割成为1000份。然后将每一份跟少数类的样本组合进行训练得到分类器。而后将这1000个分类器用assemble的方法组合位一个分类器。A选项可以看作此方式,因而相对比较合理。
另:如果目标是 预测的分布 跟训练的分布一致,那就加大对分布不一致的惩罚系数。 - 权值调整。
D方案也是其中一种方式。
下列哪些方法可以用来对高维数据进行降维:
LASSO
主成分分析法
聚类分析
小波分析法
线性判别法
拉普拉斯特征映射
正确答案: A B C D E F
解析:
lasso通过参数缩减达到降维的目的;
PCA可以降维;
线性鉴别法(linear discriminant analysis,LDA)亦称Fisher线性判别。通过找到一个空间使得类内距离最小类间距离最大所以可以看做是降维;
小波分析有一些变换的操作降低其他干扰可以看做是降维;
拉普拉斯请看这个参考
特别详解
关于线性回归的描述,以下正确的有:(老知识回顾)
基本假设包括随机干扰项是均值为0,方差为1的标准正态分布
基本假设包括随机干扰项是均值为0的同方差正态分布
在违背基本假设时,普通最小二乘法估计量不再是最佳线性无偏估计量
在违背基本假设时,模型不再可以估计
可以用DW检验残差是否存在序列相关性
多重共线性会使得参数估计值方差减小
正确答案: B C E
解析:
一元线性回归的基本假设有
1、随机误差项是一个期望值或平均值为0的随机变量;
2、对于解释变量的所有观测值,随机误差项有相同的方差;
3、随机误差项彼此不相关;
4、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
5、解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
6、随机误差项服从正态分布
违背基本假设的计量经济学模型还是可以估计的,只是不能使用普通最小二乘法进行估计。
当存在异方差时,普通最小二乘法估计存在以下问题: 参数估计值虽然是无偏的,但不是最小方差线性无偏估计。
杜宾-瓦特森(DW)检验,计量经济,统计分析中常用的一种检验序列一阶 自相关 最常用的方法。
所谓多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。影响
(1)完全共线性下参数估计量不存在
(2)近似共线性下OLS估计量非有效
多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF)
(3)参数估计量经济含义不合理
(4)变量的显著性检验失去意义,可能将重要的解释变量排除在模型之外
(5)模型的预测功能失效。变大的方差容易使区间预测的“区间”变大,使预测失去意义。
深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为mn,np,p*q,且m
(AB)C
AC(B)
A(BC)
所以效率都相同
解析:
ABC=(AB)C=A(BC).
(AB)C = m*n*p + m*p*q,
A(BC)=n*p*q + m*n*q.
m*n*p
下列哪个不属于常用的文本分类的特征选择算法?
卡方检验值
互信息
信息增益
主成分分析
常采用特征选择方法。常见的六种特征选择方法:
- DF(Document Frequency) 文档频率
DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性
- MI(Mutual Information) 互信息法
互信息法用于衡量特征词与文档类别直接的信息量。
如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。
相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
- (Information Gain) 信息增益法
通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
- CHI(Chi-square) 卡方检验法
利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的
如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。
- WLLR(Weighted Log Likelihood Ration)加权对数似然
- WFO(Weighted Frequency and Odds)加权频率和可能性
- 主成分分析是特征转换算法(特征抽取),而不是特征选择
解决隐马模型中预测问题的算法是?
前向算法
后向算法
Baum-Welch算法
维特比算法
正确答案: D
解析:
A、B:前向、后向算法解决的是一个评估问题,即给定一个模型,求某特定观测序列的概率,用于评估该序列最匹配的模型。
C:Baum-Welch算法解决的是一个模型训练问题,即参数估计,是一种无监督的训练方法,主要通过EM迭代实现;
D:维特比算法解决的是给定 一个模型和某个特定的输出序列,求最可能产生这个输出的状态序列。如通过海藻变化(输出序列)来观测天气(状态序列),是预测问题,通信中的解码问题。
输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为:
95
96
97
98
99
100
解释池化:参考图片
在CNN网络中卷积池之后会跟上一个池化层,池化层的作用是提取局部均值与最大值,根据计算出来的值不一样就分为均值池化层与最大值池化层,一般常见的多为最大值池化层。池化的时候同样需要提供filter的大小、步长
参考1
M M M:输出层大小
N N N:输入层大小
p a d d i n g padding padding:原图像边缘上加入一层(多层)像素,也叫做补零。
k e r n a l kernal kernal:卷积核大小
s t r i d e stride stride:步长
卷积向下取整再加1,池化向上取整。

( 1 ) F l o o r [ ( 200 + 2 ∗ 1 − 5 ) / 2 ] + 1 = 98 + 1 = 99 ( 2 ) U p p e r [ ( 99 + 2 ∗ 0 − 3 ) / 1 ] + 1 = 96 + 1 = 97 ( 3 ) F l o o r [ ( 97 + 2 ∗ 1 − 3 ) / 1 ] + 1 = 97 (1) Floor[(200+2*1-5)/2]+1=98+1=99 \\ (2) Upper[(99 + 2*0 - 3)/1] + 1 = 96+1=97 \\ (3) Floor[(97 + 2*1-3)/1] +1 = 97 (1)Floor[(200+2∗1−5)/2]+1=98+1=99(2)Upper[(99+2∗0−3)/1]+1=96+1=97(3)Floor[(97+2∗1−3)/1]+1=97
因此选C(97)
以下描述错误的是(SVM等知识点):
A. SVM是这样一个分类器,他寻找具有最小边缘的超平面,因此它也经常被称为最小边缘分类器(minimal margin classifier)
B. 在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差。
C. 在决策树中,随着树中结点数变得太大,即使模型的训练误差还在继续减低,但是检验误差开始增大,这是出现了模型拟合不足的问题。
D. 聚类分析可以看作是一种非监督的分类。
解析:
A. 应该是最大间隔分类
B. 相反
C. 过拟合
D. 对的
影响聚类算法效果的主要原因有:( )?
特征选取
模式相似性测度
分类准则
已知类别的样本质量
正确答案: A B C
解析:
D之所以不正确,是因为聚类是对无类别的数据进行聚类,不使用已经标记好的数据。
A.
B. 参考 模式相似度测度指的是:欧氏距离等
以下()属于线性分类器最佳准则?
感知准则函数
贝叶斯分类
支持向量机
Fisher准则
正确答案: A C D
解析:
【线性分类器有三大类】感知器准则函数、SVM、Fisher准则,而贝叶斯分类器不是线性分类器。
- 感知器准则函数:代价函数J=-(W*X+w0),分类的准则是最小化代价函数。感知器是神经网络(NN)的基础,网上有很多介绍。
- SVM:支持向量机也是很经典的算法,优化目标是最大化间隔(margin),又称最大间隔分类器,是一种典型的线性分类器。(使用核函数可解决非线性问题)
- Fisher准则:更广泛的称呼是线性判别分析(linear discriminant analysis,LDA),将所有样本投影到一条远点出发的直线,使得同类样本距离尽可能小,不同类样本距离尽可能大,具体为最大化“广义瑞利商”。
- 贝叶斯分类器:一种基于统计方法的分类器,要求先了解样本的分布特点(高斯、指数等),所以使用起来限制很多。在满足一些特定条件下,其优化目标与线性分类器有相同结构(同方差高斯分布等),其余条件下不是线性分类。
下面哪些是基于核的机器学习算法?()
Expectation Maximization
Radial Basis Function
Linear Discrimimate Analysis
Support Vector Machine
正确答案: B C D
- EM不是
- LDA在高维时候也能够使用核。参考
- SVM常见
以下说法中正确的是()
A. SVM对噪声(如来自其他分布的噪声样本)鲁棒
B. 在AdaBoost算法中,所有被分错的样本的权重更新比例相同
C. Boosting和Bagging都是组合多个分类器投票的方法,二者都是根据单个分类器的正确率决定其权重
D. 给定n个数据点,如果其中一半用于训练,一般用于测试,则训练误差和测试误差之间的差别会随着n的增加而减少
正确答案: B D
解析:
- SVM并不是对噪声鲁棒的,soft-margin就是针对数据集中存在一些特异点,引入松弛变量得出的。所以当来自其它分布的噪声较多时,将不再鲁棒;
- 被分错的样本权证增加的比例是相同的,题目中并没有说权重是相同的;
- Bagging中每个基分类器的权重都是相同的;
Adaboost与Bagging的区别:
(1)采样方式:Adaboost是错误分类的样本的权重较大实际是每个样本都会使用;Bagging采用有放回的随机采样;
(2)基分类器的权重系数:Adaboost中错误率较低的分类器权重较大;Bagging中采用投票法,所以每个基分类器的权重系数都是一样的。
(3)Bias-variance权衡:Adaboost更加关注bias,即总分类器的拟合能力更好;Bagging更加关注variance,即总分类器对数据扰动的承受能力更强。
- 显而易见是是正确的啊。
在()情况下,用分支定界法做特征选择计算量相对较少?
选用的可分性判据J具有可加性
选用的可分性判据J对特征数目单调不减
样本较多

正确答案: B D
解析:
分支定界法类似决策树的决策特征,要选择那些具有强可分辨性的少量特征。
5. 算法
(AB)C
AC(B)
A(BC)
所以效率都相同
解析: 卡方检验值 常采用特征选择方法。常见的六种特征选择方法: 前向算法 正确答案: D 95 解释池化:参考图片 参考1 A. SVM是这样一个分类器,他寻找具有最小边缘的超平面,因此它也经常被称为最小边缘分类器(minimal margin classifier) B. 在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差。 C. 在决策树中,随着树中结点数变得太大,即使模型的训练误差还在继续减低,但是检验误差开始增大,这是出现了模型拟合不足的问题。 D. 聚类分析可以看作是一种非监督的分类。 解析: 特征选取 正确答案: A B C 感知准则函数 正确答案: A C D Expectation Maximization 正确答案: B C D A. SVM对噪声(如来自其他分布的噪声样本)鲁棒 正确答案: B D 选用的可分性判据J具有可加性 正确答案: B D
ABC=(AB)C=A(BC).
(AB)C = m*n*p + m*p*q,
A(BC)=n*p*q + m*n*q.
m*n*p下列哪个不属于常用的文本分类的特征选择算法?
互信息
信息增益
主成分分析
DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性
互信息法用于衡量特征词与文档类别直接的信息量。
如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。
相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的
如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。解决隐马模型中预测问题的算法是?
后向算法
Baum-Welch算法
维特比算法
解析:
A、B:前向、后向算法解决的是一个评估问题,即给定一个模型,求某特定观测序列的概率,用于评估该序列最匹配的模型。
C:Baum-Welch算法解决的是一个模型训练问题,即参数估计,是一种无监督的训练方法,主要通过EM迭代实现;
D:维特比算法解决的是给定 一个模型和某个特定的输出序列,求最可能产生这个输出的状态序列。如通过海藻变化(输出序列)来观测天气(状态序列),是预测问题,通信中的解码问题。输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为:
96
97
98
99
100
在CNN网络中卷积池之后会跟上一个池化层,池化层的作用是提取局部均值与最大值,根据计算出来的值不一样就分为均值池化层与最大值池化层,一般常见的多为最大值池化层。池化的时候同样需要提供filter的大小、步长
M M M:输出层大小
N N N:输入层大小
p a d d i n g padding padding:原图像边缘上加入一层(多层)像素,也叫做补零。
k e r n a l kernal kernal:卷积核大小
s t r i d e stride stride:步长
卷积向下取整再加1,池化向上取整。
( 1 ) F l o o r [ ( 200 + 2 ∗ 1 − 5 ) / 2 ] + 1 = 98 + 1 = 99 ( 2 ) U p p e r [ ( 99 + 2 ∗ 0 − 3 ) / 1 ] + 1 = 96 + 1 = 97 ( 3 ) F l o o r [ ( 97 + 2 ∗ 1 − 3 ) / 1 ] + 1 = 97 (1) Floor[(200+2*1-5)/2]+1=98+1=99 \\ (2) Upper[(99 + 2*0 - 3)/1] + 1 = 96+1=97 \\ (3) Floor[(97 + 2*1-3)/1] +1 = 97 (1)Floor[(200+2∗1−5)/2]+1=98+1=99(2)Upper[(99+2∗0−3)/1]+1=96+1=97(3)Floor[(97+2∗1−3)/1]+1=97
因此选C(97)以下描述错误的是(SVM等知识点):
A. 应该是最大间隔分类
B. 相反
C. 过拟合
D. 对的影响聚类算法效果的主要原因有:( )?
模式相似性测度
分类准则
已知类别的样本质量
解析:
D之所以不正确,是因为聚类是对无类别的数据进行聚类,不使用已经标记好的数据。
A.
B. 参考 模式相似度测度指的是:欧氏距离等以下()属于线性分类器最佳准则?
贝叶斯分类
支持向量机
Fisher准则
解析:
【线性分类器有三大类】感知器准则函数、SVM、Fisher准则,而贝叶斯分类器不是线性分类器。
下面哪些是基于核的机器学习算法?()
Radial Basis Function
Linear Discrimimate Analysis
Support Vector Machine
以下说法中正确的是()
B. 在AdaBoost算法中,所有被分错的样本的权重更新比例相同
C. Boosting和Bagging都是组合多个分类器投票的方法,二者都是根据单个分类器的正确率决定其权重
D. 给定n个数据点,如果其中一半用于训练,一般用于测试,则训练误差和测试误差之间的差别会随着n的增加而减少
解析:
Adaboost与Bagging的区别:
(1)采样方式:Adaboost是错误分类的样本的权重较大实际是每个样本都会使用;Bagging采用有放回的随机采样;
(2)基分类器的权重系数:Adaboost中错误率较低的分类器权重较大;Bagging中采用投票法,所以每个基分类器的权重系数都是一样的。
(3)Bias-variance权衡:Adaboost更加关注bias,即总分类器的拟合能力更好;Bagging更加关注variance,即总分类器对数据扰动的承受能力更强。在()情况下,用分支定界法做特征选择计算量相对较少?
选用的可分性判据J对特征数目单调不减
样本较多
解析:
分支定界法类似决策树的决策特征,要选择那些具有强可分辨性的少量特征。5. 算法