LZW字典压缩算法的实现
1数据压缩分类

2.字典压缩的基本原理
以色列人Lempel与Ziv发现在正文流中词汇和短语很可能会重复出现。当出现一个重复时,重复的序列可以用一个短的编码来代替。压缩程序重复扫描这样的重复,同时生成编码来代替重复序列。随着时间的过去,编码可以用来捕获新的序列。算法必须设计成压缩程序能够在编码和原始数据序列推导出当前的映射。
2.1.LZ77算法
LZ77字典算法的想法是企图查找正在压缩的字符序列是否在以前输入的数据中出现过,然后用已经出现过的字符串代替重复的部分,它的输出仅仅是指向早期出现过的字符串的“指针”。例如:
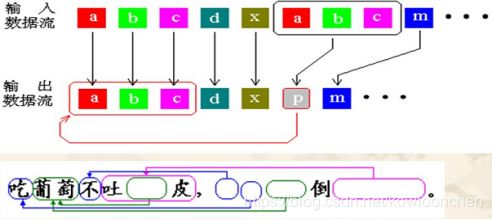
LZ77算法在某种意义上又可以称为“滑动窗口压缩”,该算法将一个虚拟的、可以跟压缩进程滑动的窗口作为词典,要压缩的字符串如果在该窗口中出现,则输出其出现的位置和长度。使用固定大小窗口进行匹配,而不是在所有已经编码的信息中匹配,是因为匹配算法的时间消耗往往很多,必须限制词典的大小才能保证算法的效率,随着压缩进程移动窗口词典窗口,使其中总包含最近编码过的信息,对大多数信息而言,要编码的字符串往往在最近的上下文中更容易找到匹配串。
LZ77算法的基本流程:
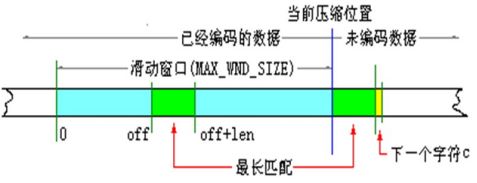
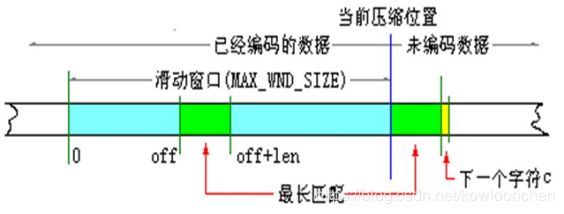
1. 从当前压缩位置开始,考察未编码的数据,并试图在滑动窗口中找出最长的匹配字符串,如果找到,则进行步骤2,否则进行步骤3;
2. 输出三元符号组(off,len,c),其中off为窗口中匹配字符串相对窗口边界的偏移,len为可匹配的仓长度,c为下一个字符,即不匹配的第一个字符,然后将窗口向后滑动len+1个字符,继续步骤1;
3. 输出三元符号组(0,0,c),其中c为下一个字符。然后将窗口向后滑动一个字符,继续步骤1.
LZ77算法示例:
| A |
A |
B |
C |
B |
B |
A |
B |
C |
如上一段字符串,我们可以通过下面的步骤来进行压缩:
| 步骤 |
位置 |
输入 |
匹配串 |
输出 |
| 1 |
1 |
A |
-- |
0,0,A |
| 2 |
2 |
AB |
A |
1,1,B |
| 3 |
4 |
C |
-- |
0,0,C |
| 4 |
5 |
BB |
B |
3,1,B |
| 5 |
7 |
ABC |
AB |
2,2,C |
LZ77算法通过输出真实的字符解决了在窗口中出现没有匹配串的问题,但是这个解决方案包含有冗余信息。冗余学习表现在连个方面:一是空指针;二是编码器可能输出额外的字符,这种字符是指可能包含在下一个匹配串中的字符。
2.2.LZSS算法
LZSS算法的思想是如果匹配串的长度比指针本身的长度还要长就输出指针,否则就输出真实字符。另外要输出额外的标志位区分是指针还是字符。
LZSS算法基本流程:
1.从当前压缩位置开始,考察未编码的字符,并试图在滑动窗口中找出最长的匹配字符串,如果匹配字符串长度大于等于最小匹配串长度,则决心步骤2,否则进行步骤3;
2.输出指针二元组(off,len)。其中off为窗口匹配字符串相对窗口边界的偏移,len为匹配串的长度,然后将窗口向后滑动len各字符,继续步骤1;
3.输出当前字符c,然后将窗口向后滑动1个字符,继续步骤1.
LZSS算法示例:
| A |
A |
B |
C |
B |
B |
A |
B |
C |
如上一段字符串,我们可以通过下面的步骤来进行压缩:
| 步骤 |
位置 |
输入 |
匹配串 |
输出 |
| 1 |
1 |
A |
-- |
A |
| 2 |
2 |
AB |
-- |
A |
| 3 |
3 |
BC |
-- |
B |
| 4 |
4 |
CB |
-- |
C |
| 5 |
5 |
BCA |
BC |
3,2 |
| 6 |
7 |
ABC |
ABC |
1,3 |
在相同的计算机环境下,LZSS算法比LZ77算法可获得更高的压缩比,而编码同样简单,这也就是往上面这种算法成为开发新算法的基础。许多后来的开发文档压缩程序都是使用LZSS的思想。例如:PKZip、GZip、ARJ、LHArc和ZOO等。其差别仅仅是指针的长度和窗口的大小有所不同。
2.3.LZ78算法
LZ78算法的想法是企图从输入的数据中创建一个“短语词典(Dirctionary of the Phrases)”,这种短语可以是任意字符的组合。编码数据过程中当遇到已经在词典中出现的短语时,编码器就输出这个词典中短语的索引号,而不是短语本身。
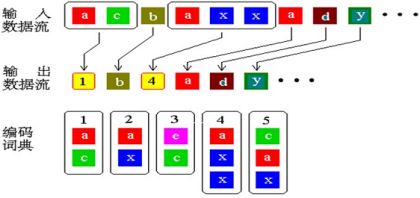
LZ78的编码思想是不断的从字符流中提取新的字符串,通俗的理解为新的“词条”,然后用码字(Code Word)表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替换字符流,生成码字流,从而达到压缩数据的目的。
LZ78编码器输出的是码字-字符(w,c)对,每次输出一对到码子流中,与码字W相对的字符串用字符C进行扩展生成新的字符串,然后添加到词典中。
LZ78算法基本流程:
1.将词典和当前前缀P都初始化为空;
2.当前字符C:=字符流中的下一个字符;
3.判断P+C是否在词典中
(1)如果“是”,则用C扩展P,即让P:=P+C,返回到步骤2;
(2)如果“否”,则输出与当前前缀P相对应的码字W和当前字符C,即(W,C),将P+C添加到词典中,令P=空值,并返回步骤2。
LZSS算法示例:
| 位置 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|||||||
| 字符 |
A |
B |
B |
C |
B |
C |
A |
B |
A |
|||||||
如上一段字符串,我们可以通过下面的步骤来进行压缩:
| 步骤 |
位置 |
输入 |
词典 |
输出 |
| 1 |
1 |
A |
A |
0,A |
| 2 |
2 |
B |
B |
0,B |
| 3 |
3 |
BC |
BC |
2,C |
| 4 |
5 |
CBA |
BCA |
3,A |
| 5 |
8 |
BCA |
BA |
2,A |
2.4.LZW算法
J.Ziv和A.Lempel在1978年首次发表了介绍第二类词典编码算法的文章。在他们的研究基础上,Terry A.Wlch在1984年发表了改进这种编码算法的文章。因此把这种编码方法称为LZW压缩算法。
在编码原理上,LZW与LZ78相比有如下差别:
- LZW输出代表词典中的字符串码字。这就意味着开始时词典不能是空的,它必须包含可能在流中出现的所有单个字符。即在编码匹配时,至少可以在词典中找到长度为1的匹配串。LZW编码是围绕称为词典的转换表来完成的;
- LZW编码器就是通过管理这个词典完成输入与输出之间的转换。LZW编码器的输出是字符流,字符流可以是8为的ASCII字符组成的字符串,而输出是用n位表示的码字流,码字代表单个字符或者多个字符组成的字符串。
比如Ababcabab这个字符串,是由9个字符组成的,但是会发现一点就是ab这个字符组合比较的多。如果我们用一个数字,也就是7来表示ab的话,则字符串就变为了77c77,这样一来字符串的字符个数就变为了5个,如果大家仔细些会发现,如果我们用一个数字8来表示abab,则原来的字符串就变为了8c8只有3个字符了,是不是很神奇哈。
LZW压缩实现步骤:
①打开一个待压缩文件与存放压缩后的文件
②读入一个字节作为后缀,判断这个词字典中是否存在,存在则直接输出,不存在则加入字典中。
③如果超过了最大的长度则,将当前码表写出到文件中,清空,再次读入
④最后,将没有写完的信息,和码表都输出,压缩就完成了
两个重要概念:
前缀prefix:一个词组的前面一个字符 ,比如 ab,前缀为a,8f前缀为8;
后最suffix:反之,为后一个字符,比如 ab,后缀为b,8f后缀为f;
有了前缀后缀,我们就能清楚的表示出来一个词了。同样,我们还来做一个字符串 ababbacb 8个字符
| 第几步 |
前缀 |
后缀 |
词 |
存在对应码 |
输出 |
码 |
| 1 |
|
a |
(,a) |
|
|
|
| 2 |
a |
b |
(a,b) |
no |
a |
256 |
| 3 |
b |
a |
(b,a) |
no |
b |
257 |
| 4 |
a |
b |
(a,b) |
yes |
|
|
| 5 |
256 |
b |
(256,b) |
no |
256 |
258 |
| 6 |
b |
a |
(b,a) |
yes |
|
|
| 7 |
257 |
c |
(257,c) |
no |
257 |
259 |
| 8 |
c |
b |
(c,b) |
no |
c |
260 |
把输出来的和最后一个后缀连在一起则是:a,b,256,257,c,b 这6个字符,那么就达到了压缩的目的。对应生成的码表则是:
| 256 |
257 |
258 |
259 |
260 |
| (a,b) |
(b,a) |
(256,b) |
(257,c) |
(c,b) |
解压缩就很简单了,将输出字符串按照码表对应转化回来就实现了。即a,b,256(ab),257(ba),c,b
即 ababbacb压缩成功。
当然我们不能一直无穷之境的增加码表的长度,再说内存也容不下这么长的码表。所以我们用0~65534保存字节所对应的编码,0~255是系统字节的长度,256~65534是自定义的。如果超过了65534的话,我们这必须再次编码。即将原来所对应的编码输出,将256~65534这一段清空,再次编码就可以了。
为了记录是在哪里清空的,所有又在文件中写一个字符,表示 “清除”,下面的示例程序中用的是65535表示。下面是LZW压缩详细的代码示例:
①打开一个待压缩文件与存放压缩后的文件
| //…code… //打开被压缩文件 java.io.FileInputStream fis = new java.io.FileInputStream(path); //压缩文件输出流 java.io.FileOutputStream fos = new java.io.FileOutputStream(path+".NetJavaZip"); java.io.DataOutputStream dos = new java.io.DataOutputStream(fos); //…code… |
②读入一个字节作为后缀,判断这个词字典中是否存在,存在则直接输出,不存在则加入字典中。
| //…code… prefix=fis.read();//读入一个字节 while(fis.available()>0){ suffix=fis.read();//读入一个后缀 index=lz.getIndex(prefix, suffix);//得到对应的下标 if(index!=-1){//存在元素在表里面 prefix=index;//前序变为标号 }else{//在表里不存在 // System.out.println("输出了~"+prefix); dos.writeChar(prefix);//输出前缀 lz.add(prefix,suffix);//加入到表中 prefix=suffix;//前缀变为后缀 } } //…code… |
③如果超过了最大的长度则,将当前码表写出到文件中,清空,再次读入
| //…code… if(lz.length==lzw.Max_Length){//超过最大长度则,重置 dos.writeChar(65535);//写出一个65535作为重置的标示 与码表的打印 for(int i=256;i dos.writeChar(lz.node[i].prefix);//前缀写出 dos.writeChar(lz.node[i].suffix);//后缀写出 }
lz = new lzw();//清空原来信息 } //…code… |
④最后,将没有写完的信息,和码表都输出,压缩就完成了
| //…code… dos.writeChar(prefix);//输出最后一个没有配对的 //输出最后的的码表 dos.writeChar(65535);//写出一个-1作为重置的标示 与码表的打印 //写出码表 dos.writeInt(lz.length-256);//码表长度 for(int i=256;i dos.writeChar(lz.node[i].prefix);//前缀写出 dos.writeChar(lz.node[i].suffix);//后缀写出 } //…code… |
解压缩过程:
- 读入码表之前的压缩信息
| //…code… char data; int current=0; char []codeData = new char[65536]; lzw lz = new lzw();//自定义码表 data=dis.readChar(); while(data!=65535){//把码表钱的东西读取出来 codeData[current]=data; current++;//当前位置增加 data=dis.readChar(); } //…code… |
- 读入对应长度的码表
| //…code… int length = dis.readInt();//得到码表的长度 for(int i=0;i int prefix = dis.readChar(); int suffix = dis.readChar(); lz.add(prefix, suffix); } //…code… |
③翻译编码,写出源文件
| //…code… //解压缩、写出该部分的源文件 for(int i=0;i //System.out.println("传进来的数据是~"+codeData[i]); lz.writeIt(dos, codeData[i]); } //…code… public void writeIt(java.io.DataOutputStream dos,int index){ if(index>255){//是生成的码则需要转化为byte输出 writeIt(dos,node[index].prefix); writeIt(dos,node[index].suffix); }else{ try { dos.write((char)index); } catch (IOException e) { e.printStackTrace(); } } } //…code… |
字典压缩到这里就完成了,聪明的你还在等什么呢?赶快动手吧!