Oracle之 dmp导入/导出、数据库操作等过程中的字符集问题
开篇:因为要定位一个 关于dmp文件导入的乱码问题, 于是乎我开始了漫长了 Oracle字符集搜索之路,网上关于讲解oracle字符集的文章多得数不胜数,但转载的这篇文章确是我最最喜欢的,图文并茂,恰当的例子通俗易懂,对于我这种小菜最最适合不过。
本文转自:http://blog.163.com/jiankun_liu/blog/static/1863927762013698175289/
原文标题:Oracle_字符集问题(数据库与客户端字符集关联关系)
//时间:2013-07-07
//作者:shm
//描述:本文主要记录了Oracle数据库的字符集问题,也涉及作为服务器操作系统的CentOS或者Windows的字符集与Oracle字符集之间的关联关系。
Oracle的字符集,这个问题的提出是因为两个原因:一是工作中遇到一个DMP文件需要恢复到数据库中去,而这个DMP文件的字符集是US7ASCII,第二个原因是一直在学习CentOS,在这个系统上安装Oracle已经能成功,但是被中文英文系统字符集等问题搞得有点头大。所以又回头翻了翻盖国强的书、看了看尚观的视频,终于有点心得,所以就写下了这篇算是笔记的文章。
Oracle数据库的字符集问题不算是大问题,但也是一个头疼的问题。这是因为有这么三个原因:一是Oracle数据库在安装时指定好字符集之后一般不能更改,二是字符集问题涉及服务器与客户端之间的存取问题,三是Oracle数据库迁移时也会跟字符集非常相关。
首先,要说清楚Oracle字符集的相关问题,则要先理清数据库运行过程中的架构以及在这个架构中的字符集设置及这些设置之间的关联关系。
先画一张图看一下:
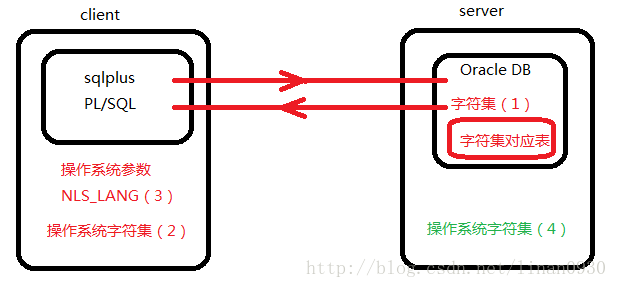
在这个图中,为了说明问题,我们将服务器与客户端分开,客户端用应用程序比如sqlplus或者PL/SQL与服务端相连。
服务端有两个字符集:服务端操作系统字符集(4)、服务端数据库字符集(1);
客户端有一个字符集:客户端操作系统字符集(2);
客户端有一个参数:操作系统参数NLS_LANG(3)。
这三个字符集与一个参数中,有一个字符集对整个架构的运行没有影响,它就是服务端操作系统字符集(4),所以这个字符集将不再出现在我们的讨论过程中。
为什么这个服务端操作系统字符集没有用呢?这是因为Oracle在存取字符时与客户端进行字符集确认与转码的过程是由Oracle数据库自身完成的,不需要经过Oracle数据库所在的服务器的帮助。具体的是怎么回事用以下例子说明一下。
比如在Oracle数据库中有一个表,用如下语句创建:
create table test(name varchar2(10));
为了说明问题假定有这样的一个环境:服务器端Oracle数据库的字符集是UTF8,客户端操作系统字符集是ZHS16GBK,客户端NLS_LANG参数设置为ZHS16GBK。
那么从客户端应用程序(比如sqlplus)发出这样一条命令:
insert into test (name) values('中国');
首先,这里有一个字符串“中国”,客户端操作系统用ZHS16GBK对它进行编码,比如编成“167219”,并把它交给sqlplus程序,然后把它发送给Oracle数据库。
接着,Oracle数据库收到一串编码“167219”,不是直接往数据库里一扔就完事的,它要问客户端操作系统:“请问你给我的这串代码是用什么格式编码的啊?”客户端操作系统怎么回答?它会这么回答:“编码格式请参照参数NLS_LANG”。Oracle数据库一看,NLS_LANG='ZHS16GBK',这个编码格式与Oracle数据库自身的编码格式“UTF8”不一样,然后就是Oracle数据库发挥自己专长的地方了,为什么呢?因为Oracle数据库有它自己的编码表,而且不是一张而是好多张编码表,它可以根据编码表对编码进行翻译和转码。这就好比Oracle数据库是一个翻译,它会好几国语言,牛人一个。像上面的这个情况,Oracle会把“167219”这串代码拿过来,根据参数NLS_LANG查ZHS16GBK编码表,找到对应这串代码的字符“中国”,然后再到UTF8编码表中查“中国”对应的编码,比如查到的结果是“3224678”。
最后,将转码之后的编码“3224678”存放到Oracle数据库中去。
为了进一步说明问题,我们再执行一条语句:
select name from test;
首先,Oracle数据库会从数据库中取出一串代码“3224678”。
接着,Oracle数据库不是直接把这串代码交给sqlplus程序,它会多问一句:“代码串我是取出来了,它是UTF8编码格式的,请问sqlplus,你希望要什么编码格式的?”,sqlplus仍然会很爽快地告诉Oracle数据库:“编码格式请继续参照参数NLS_LANG”。Oracle数据库一看,ZHS16GBK跟UTF8又不一样,所以先查UTF8编码表,找到编码“3224678”对应的字符“中国”,再查ZHS16GBK编码表,找到“中国”对应的编码“167219”,然后就是把最后得到的这串编码“167219”交给sqlplus程序。
最后,sqlplus直接把得到的这串编码扔给客户端操作系统,而操作系统只有ZHS16GBK编码表,它不会问得到的这串编码是什么格式的,只会直接到ZHS16GBK编码表中去查“167219”对应的字符是什么,并把它交给应用程序显示出来。这个显示的结果是“中国”。
以上就是一个完整的从客户端编码并经过Oracle数据库转码存入数据库,然后从数据库取出并转码交给客户端显示的实验。
从以上过程我们可以得出以下一些结论:
1.对Oracle数据库存取起作用的是这些:客户端操作系统字符集、客户端操作系统参数NLS_LANG、服务端数据库字符集。
2.对Oracle数据库不起作用的是服务端操作系统字符集。
3.客户端操作系统只有一张编码表,与客户端字符集对应。
4.Oracle数据库的字符集只有一个,并且固定,一般不改变。
5.存放在Oracle数据库中的字符串的编码格式只有一个,它就是数据库的字符集所对应的编码格式。
6.Oracle数据库有很多张编码表,可以在数据存入时将其它编码格式的编码转换为数据库字符集指定的格式,取出时从数据库字符集指定的格式转换为其它编码格式。
7.整个架构中的转码只发生在Oracle数据库边界上,其它地方没有。
8.Oracle是根据客户端操作系统的参数NLS_LANG与自己的字符集进行对照来确定是否需要进行转码的。
最最重要的结论出来了:
9.Oracle数据库如何选择字符集?只有一个原则,那就是这个字符集要包含数据库运行过程中所能存入的数据字符,通常作为中国人我们选择ZHS16GBK,如果想再保险一点,选择AL32UTF8。
10.服务器操作系统选择什么字符集?这个字符集与数据库字符集一点关系都没有,只跟谁有关?操作系统管理员!所以它的选择原则是,系统管理员想选择什么就选择什么。
11.客户端操作系统选择什么字符集?我是中国人,我用中文操作系统,所以我选择ZHS16GBK。建议中国人都选择ZHS16GBK。
12.客户端操作系统参数NLS_LANG参数如何设置?这个只有一个设置方法,那就是与操作系统字符集相同。要不然会出问题的……
最最最最重要的一句话:
最好的,最不容易出字符集错误的就是:将数据库字符集、客户端字符集、客户端操作系统NLS_LANG参数三个地方作同样的设置。
另外再记录一下EXP和IMP过程与字符集相关的事情。
EXP时,起作用的有Oracle数据库的字符集和客户端操作系统参数NLS_LANG两项,这时服务器与客户端操作系统字符集都不起作用。如果客户端操作系统参数NLS_LANG与Oracle数据库的字符集相同,那就直接导出,不需要转码,并且导出文件的字符集与上述两项一样;如果客户端操作系统参数NLS_LANG与Oracle数据库的字符集不同,那么导出时Oracle数据库会将数据文件从Oracle数据库的字符集编码格式转码成客户端操作系统参数NLS_LANG指定的编码格式。总而言之一句话:导出文件的字符集格式与导出客户端操作系统参数NLS_LANG一定相同。
IMP时,起作用的仍然是两项,一项是DMP文件第二第三字节指定的字符集,另外一项是Oracle数据库的字符集。两个相同就不需要转码,两个不同就转成Oracle数据库字符集指定的编码格式。
最后记录我遇到的几个问题。
1.我前段时间测试过在CentOS上安装Oracle11gR2,那时我设置过CentOS的字符集中“zh_CN.UTF-8”,并且安装中文字体,当时也确实能得到我想要的结果,那就是:我安装的Oracle数据库的字符集是中文字符集ZHS16GBK。为什么呢,因为Oracle数据库的字符集是默认地根据操作系统的字符集来的,并且我也就选择它的默认字符集。所以没有出错。
但是,但是,现在我知道了,这个作为服务器的CentOS的字符集对Oracle数据库没有影响,所以现在让我再来一回去选择它是什么字符集,我会选择en_US.UTF-8,甚至en_US.US7ASCII。为什么呢,因为在shell界面显示中文确认是一个难题,所以管理CentOS,还是用英文吧,比较方便又对数据库没影响。随它去吧。
2.英文操作系统安装中文字符集oracle数据库时,一定要注意在选择数据库字符集的时候慢一点,细心地选择一个ZHS16GBK或者AL32UTF8。
3.DMP文件是US7ASCII字符集,要把它导入字符集是ZHS16GBK的数据库中去,如何操作?第一步:安装一个US7ASCII字符集的数据库(比如说9i);第二步,将DMP文件导入该数据库;第三步,设置导出客户端操作系统参数NLS_LANG=ZHS16GBK,然后导出;第四步,将后导出的DMP文件导入字符集是ZHS16GBK的数据库中去。理论上成功。需要做实验测试。
4.曾经说到,一般情况下数据库的字符集在数据库安装好之后就不可以更改。那么如果万一领导说一定要改,怎么办?比如说原来的字符集是ZHS16GBK,非要让转成UTF8,有没有办法?答案是有的,但是,但是不一定会全部成功,这里有一个严格超集的概念,这个概念在这篇文章里不讲。答案是这么做,设置导出客户端操作系统参数为UTF8,然后导出,这里,数据编码格式会从ZHS16GBK转码成UTF8,然后再删除ZHS16GBK的数据库,新建一个UTF8的数据库,再导入就可以了。