ADPCM文件解码详解
本文转自:http://hi.baidu.com/sunsee/item/68d61e451921e30ec016134a
一、搞了几天终于搞定这个ADPCM解码了,之前找了很多的资料,大致描述的都是千篇一律,但是基本上都没有说到细节上,让我也走了不少弯路,其实主要在细节,网上给的算法是正确的,但是直接运用根本就不行,噪音很大。这一点让我一直很头疼,最后还是看了英文资料,才得到解答,还是老外的原始资料好。
二、给个英文参考网址吧
http://www.moon-soft.com/program/FORMAT/windows/wavec.htm
https://ccrma.stanford.edu/courses/422/projects/WaveFormat/
这两个讲的很详细,请仔细阅读!通过阅读我发现细节在与adpcm格式的wav文件的block的特点,每一个block包含header和data两部分,
Typedef struct{
short sample0; //block中第一个采样值(未压缩)
BYTE index; //上一个block最后一个index,第一个block的index=0;
BYTE reserved; //尚未使用
}MonoBlockHeader
关键是我们要抓住每一个block的header里面的信息,即sample0,运算的时候注意运用!
三、还是给个代码吧,多的也不说了!
1、adpcm.c文件代码
#include"adpcm.h"
/* Intel ADPCM step variation table */
staticintindexTable[16]={
-1,-1,-1,-1,2,4,6,8,
-1,-1,-1,-1,2,4,6,8,
};
staticintstepsizeTable[89]={
7,8,9,10,11,12,13,14,16,17,
19,21,23,25,28,31,34,37,41,45,
50,55,60,66,73,80,88,97,107,118,
130,143,157,173,190,209,230,253,279,307,
337,371,408,449,494,544,598,658,724,796,
876,963,1060,1166,1282,1411,1552,1707,1878,2066,
2272,2499,2749,3024,3327,3660,4026,4428,4871,5358,
5894,6484,7132,7845,8630,9493,10442,11487,12635,13899,
15289,16818,18500,20350,22385,24623,27086,29794,32767
};
voidadpcm_decoder(char*inbuff,char*outbuff,intlen_of_in,structadpcm_state *state )
{
int i=0,j=0;
chartmp_data;
structadpcm_state *tmp_state =state;
longstep;/* Quantizer step size */
signedlongpredsample;/* Output of ADPCM predictor */
signedlongdiffq;/* Dequantized predicted difference */
intindex;/* Index into step size table */
intSamp;
unsignedcharSampH,SampL;
unsignedcharinCode;
/* Restore previous values of predicted sample and quantizer step
size index
*/
predsample =state->valprev;
index =state->index;
for(i=0;i<len_of_in*2;i++)
{
tmp_data=inbuff[i/2];
if(i%2)
inCode=(tmp_data&0xf0)>>4;
else
inCode=tmp_data &0x0f;
step =stepsizeTable[index];
/* Inverse quantize the ADPCM code into a predicted difference
using the quantizer step size
*/
diffq =step >>3;
if(inCode &4)
diffq +=step;
if(inCode &2)
diffq +=step >>1;
if(inCode &1)
diffq +=step >>2;
/* Fixed predictor computes new predicted sample by adding the
old predicted sample to predicted difference
*/
if(inCode &8)
predsample -=diffq;
else
predsample +=diffq;
/* Check for overflow of the new predicted sample
*/
if(predsample >32767)
predsample =32767;
elseif(predsample <-32768)
predsample =-32768;
/* Find new quantizer stepsize index by adding the old index
to a table lookup using the ADPCM code
*/
index +=indexTable[inCode];
/* Check for overflow of the new quantizer step size index
*/
if(index <0)
index =0;
if(index >88)
index =88;
/* Return the new ADPCM code */
Samp=predsample;
if(Samp>=0)
{
SampH=Samp/256;
SampL=Samp-256*SampH;
}
else
{
Samp=32768+Samp;
SampH=Samp/256;
SampL=Samp-256*SampH;
SampH+=0x80;
}
outbuff[j++]=SampL;
outbuff[j++]=SampH;
}
/* Save the predicted sample and quantizer step size index for
next iteration
*/
state->valprev =(short)predsample;
state->index =(char)index;
}
#ifndefADPCM_H
#defineADPCM_H
#ifdef__cplusplus
extern"C"{
#endif
struct adpcm_state {
short valprev; /* Previous output value */
char index; /* Index into stepsize table */
};
voidadpcm_decoder(char*inbuff,char*outbuff,intlen_of_in,structadpcm_state *state );
#ifdef__cplusplus
} /* extern "C" */
#endif
#endif/* ADPCM_H*/
3、main.c文件代码
#include"stdio.h"
#include "stdlib.h"
#include "adpcm.h"
#defineCFG_BlkSize 256
charch[CFG_BlkSize]; //用来存储wav文件的头信息
charsavedata[CFG_BlkSize*4];
unsignedcharRiffHeader[]={
'R','I','F','F',// Chunk ID (RIFF)
0x70,0x70,0x70,0x70,// Chunk payload size (calculate after rec!)
'W','A','V','E',// RIFF resource format type
'f','m','t',' ',// Chunk ID (fmt )
0x10,0x00,0x00,0x00,// Chunk payload size (0x14 = 20 bytes)
0x01,0x00, // Format Tag ()
0x01,0x00, // Channels (1)
0x40,0x1f,0x00,0x00,// Sample Rate, = 16.0kHz
0x80,0x3e,0x00,0x00,// Byte rate 32.0K
0x02,0x00, // BlockAlign == NumChannels * BitsPerSample/8
0x10,0x00 // BitsPerSample
};
unsignedcharRIFFHeader504[]={
'd','a','t','a',// Chunk ID (data)
0x70,0x70,0x70,0x70 // Chunk payload size (calculate after rec!)
};
/****************************************************************
函数名称: main
功能描述:
输入参数: none
输出参数: none
****************************************************************/
voidmain(void)
{
FILE *fpi,*fpo;
unsignedlongiLen,temp;
structadpcm_state ADPCMstate;
unsignedlongi =0;
unsignedlongj;
fpi=fopen("f:\\lk\\test.adpcm","rb"); //为读,打开一个wav文件
if((fpi=fopen("f:\\lk\\test.adpcm","rb"))==NULL) //若打开文件失败,退出
{
printf("can't open this file\n");
printf("\nread error!\n");
printf("\n%d\n",i);
exit(0);
}
fseek(fpi,0,SEEK_END);
iLen=ftell(fpi);
printf("\n======================================================\n");
printf("\n========================%d========================\n",iLen);
printf("\n======================================================\n");
if((iLen-44)%CFG_BlkSize)
iLen =(iLen-44)/CFG_BlkSize+1;
else
iLen =(iLen-44)/CFG_BlkSize;
fpo=fopen("f:\\lk\\new.pcm","rb+"); //为写,打开一个wav文件
if((fpo=fopen("f:\\lk\\new.pcm","rb+"))==NULL) //若打开文件失败,退出
{
printf("can't open this file\n");
printf("\nwrite error!\n");
exit(0);
}
fseek(fpo,0,SEEK_SET);
fwrite(RiffHeader,sizeof(RiffHeader),1,fpo); //写文件riff
fwrite(RIFFHeader504,sizeof(RIFFHeader504),1,fpo); //写 data块头
while(i<iLen)
{
fseek(fpi,48+i*CFG_BlkSize,SEEK_SET);
fread(ch,1,CFG_BlkSize,fpi);
printf("\n======================================================\n");
for(j=0;j<100;j++)
printf("| %d |",ch[j]);
printf("\n======================================================\n");
////////////////////////添加读取BlockHeader部分开始////////////////////////////////
if(i ==0)
{
ADPCMstate.index =0; //第一个block的index为 0 当前的BlockSize为 256 即采样点数为 (256-4)*2+1 = 505
}
else
{
ADPCMstate.index =ch[2];
}
ADPCMstate.valprev =(short)ch[0]+((short)(ch[1]))*256; //每一个block里面帧头有一个未压缩的数据 存储时 先低后高
savedata[0]=ch[0]; //存储第一个没有被压缩的数据
savedata[1]=ch[1]; //存储第一个没有被压缩的数据
////////////////////////添加读取BlockHeader部分结束////////////////////////////////
adpcm_decoder(&ch[4],&savedata[2],CFG_BlkSize-4,&ADPCMstate);//解码出来了 (256-4)*4 个字节
temp =(CFG_BlkSize-4)*4+2;
fseek(fpo,44+i*temp,SEEK_SET); //开始写声音数据
fwrite(savedata,temp,1,fpo);
i++;
}
temp *=i;
RiffHeader[4]=(unsignedchar)((40+temp)&0x000000ff);
RiffHeader[5]=(unsignedchar)(((40+temp)&0x0000ff00)>>8);
RiffHeader[6]=(unsignedchar)(((40+temp)&0x00ff0000)>>16);
RiffHeader[7]=(unsignedchar)(((40+temp)&0xff000000)>>24);
fseek(fpo,4,SEEK_SET);
fwrite(&RiffHeader[4],4,1,fpo);
RiffHeader[40]=(unsignedchar)(temp&0x000000ff);
RiffHeader[41]=(unsignedchar)((temp&0x0000ff00)>>8);
RiffHeader[42]=(unsignedchar)((temp&0x00ff0000)>>16);
RiffHeader[43]=(unsignedchar)((temp&0xff000000)>>24);
fseek(fpo,40,SEEK_SET);
fwrite(&RiffHeader[40],4,1,fpo);
fclose(fpi);
fclose(fpo);
printf("\n==========================OK!=========================\n");
}
1. 音频简介
经常见到这样的描述: 44100HZ 16bit stereo 或者 22050HZ 8bit mono 等等.
44100HZ 16bit stereo: 每秒钟有 44100 次采样, 采样数据用 16 位(2字节)记录, 双声道(立体声);
22050HZ 8bit mono: 每秒钟有 22050 次采样, 采样数据用 8 位(1字节)记录, 单声道;
当然也可以有 16bit 的单声道或 8bit 的立体声, 等等。
采样率是指:声音信号在“模→数”转换过程中单位时间内采样的次数。采样值是指每一次采样周期内声音模拟信号的积分值。
对于单声道声音文件,采样数据为八位的短整数(short int 00H-FFH);
而对于双声道立体声声音文件,每次采样数据为一个16位的整数(int),高八位(左声道)和低八位(右声道)分别代表两个声道。
人对频率的识别范围是 20HZ - 20000HZ, 如果每秒钟能对声音做 20000 个采样, 回放时就足可以满足人耳的需求. 所以 22050 的采样频率是常用的, 44100已是CD音质, 超过48000的采样对人耳已经没有意义。这和电影的每秒 24 帧图片的道理差不多。
每个采样数据记录的是振幅, 采样精度取决于储存空间的大小:
1 字节(也就是8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(也就是16bit) 可以细到 65536 个数, 这已是 CD 标准了;
4 字节(也就是32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
如果是双声道(stereo), 采样就是双份的, 文件也差不多要大一倍.
这样我们就可以根据一个 wav 文件的大小、采样频率和采样大小估算出一个 wav 文件的播放长度。
譬如 "Windows XP 启动.wav" 的文件长度是 424,644 字节, 它是 "22050HZ / 16bit / 立体声" 格式(这可以从其 "属性->摘要" 里看到),
那么它的每秒的传输速率(位速, 也叫比特率、取样率)是 22050*16*2 = 705600(bit/s), 换算成字节单位就是 705600/8 = 88200(字节/秒),
播放时间:424644(总字节数) / 88200(每秒字节数) ≈ 4.8145578(秒)。
但是这还不够精确, 包装标准的 PCM 格式的 WAVE 文件(*.wav)中至少带有 42 个字节的头信息, 在计算播放时间时应该将其去掉,
所以就有:(424644-42) / (22050*16*2/8) ≈ 4.8140816(秒). 这样就比较精确了.
关于声音文件还有一个概念: "位速", 也有叫做比特率、取样率, 譬如上面文件的位速是 705.6kbps 或 705600bps, 其中的 b 是 bit, ps 是每秒的意思;
压缩的音频文件常常用位速来表示, 譬如达到 CD 音质的 MP3 是: 128kbps / 44100HZ.
2. PCM数据格式
PCM(Pulse Code Modulation)也被称为 脉码编码调制。PCM中的声音数据没有被压缩,如果是单声道的文件,采样数据按时间的先后顺序依次存入。(它的基本组织单位是BYTE(8bit)或WORD(16bit))
一般情况下,一帧PCM是由2048次采样组成的( 参 http://discussion.forum.nokia.com/forum/showthread.php?129458-请问PCM格式的音频流,每次读入或输出的块的大小是必须固定为4096B么&s=e79e9dd1707157281e3725a163844c49)。
如果是双声道的文件,采样数据按时间先后顺序交叉地存入。如图所示:

PCM的每个样本值包含在一个整数i中,i的长度为容纳指定样本长度所需的最小字节数。
首先存储低有效字节,表示样本幅度的位放在i的高有效位上,剩下的位置为0,这样8位和16位的PCM波形样本的数据格式如下所示。
样本大小 数据格式 最小值 最大值
8位PCM unsigned int 0 225
16位PCM int -32767 32767
一、概述:
本文叙述了如何通过IMA-ADPCM压缩和解压缩算法来完成从IMA-ADPCM文件转换为PCM文件的过程。主要包括的内容有:PCM和IMA-ADPCM WAVE文件内部结构的介绍,IMA-ADPCM压缩与解压缩算法,以及如何生成特有的音频压缩格式文件等三方面的内容。
二、WAVE文件的认识
WAVE文件是计算机领域最常用的数字化声音文件格式之一,它是微软专门为Windows系统定义的波形文件格式(Waveform Audio),由于其扩展名为"*.wav"。
wave文件有很多不同的压缩格式,而且现在一些程序生成的wave文件都或多或少地含有一些错误。这些错误的产生不是因为单个数据压缩和解压缩算法的问题,而是因为在压缩和解压缩后没有正确地组织好文件的内部结构。所以,正确而详细地了解各种WAVE文件的内部结构是成功完成压缩和解压缩的基础,也是生成特有音频压缩格式文件的前提。
最基本的WAVE文件是PCM(脉冲编码调制)格式的,这种文件直接存储采样的声音数据没有经过任何的压缩,是声卡直接支持的数据格式,要让声卡正确播放其它被压缩的声音数据,就应该先把压缩的数据解压缩成PCM格式,然后再让声卡来播放。
1.Wave文件的内部结构
WAVE文件是以RIFF(Resource Interchange File Format,"资源交互文件格式")格式来组织内部结构的。RIFF文件结构可以看作是树状结构,其基本构成是称为"块"(Chunk)的单元,最顶端是一个“RIFF”块,下面的每个块有“类型块标识(可选)”、“标志符”、“数据大小”及“数据”等项所组成,块的结构如表1所示:

上面说到的“类型块标识”只在部分chunk中用到,如“WAVE”chunk中,这时表示下面嵌套有别的chunk,当使用了“类型块标识”时,该chunk就没有别的项(如块标志符,数据大小等),它只作为文件读取时的一个标识。先找到这个“类型块标识”,再以它为起来读取它下面嵌套的其它chunk。
每个文件最前端写入的是RIFF块,每个文件只有一个RIFF块。从表2中可以看出它的结构:
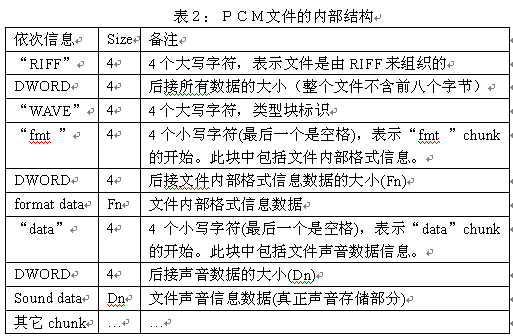
非PCM格式的文件会至少多加入一个“fact”块,它用来记录数据解压缩后的大小。(注意是数据而不是文件)这个“fact”块一般加在“data”块的前面。
2.WAVEFORMAT结构的认识
PCM和非PCM的主要区别是声音数据的组织不同,这些区别可以通过两者的WAVEFORMAT结构来区分。下面以PCM和IMA-ADPCM来进行对比:
WAVE的基本结构WAVEFORMATEX结构定义如下:
typedef struct
{
WORD wFormatag; //编码格式,包括WAVE_FORMAT_PCM,//WAVEFORMAT_ADPCM等
WORD nChannls; //声道数,单声道为1,双声道为2;
DWORD nSamplesPerSec;//采样频率;
DWORD nAvgBytesperSec;//每秒的数据量;
WORD nBlockAlign;//块对齐;
WORD wBitsPerSample;//WAVE文件的采样大小;
WORD sbSize; //PCM中忽略此值
}WAVEFORMATEX;
PCM的结构就是基本结构;
IMAADPCMWAVEFORMAT结构定义如下:
Typedef struct
{
WAVEFORMATEX wfmt;
WORD nSamplesPerBlock;
}IMAADPCMWAVEFORMAT;
IMA-ADPCM的wfmt->cbsize不能忽略,一般取值为2,表示此类型的WAVEFORMAT比一般的WAVEFORMAT多出2个字节。这两个字符也就是nSamplesPerBlock。
3.“fact”chunk的内部组织
在非PCM格式的文件中,一般会在WAVEFORMAT结构后面加入一个“fact”chunk,结构如下:
typedef struct{
char[4]; //“fact”字符串
DWORD chunksize;
DWORD datafactsize; //数据转换为PCM格式后的大小。
}factchunk;
datafactsize是这个chunk中最重要的数据,如果这是某种压缩格式的声音文件,那么从这里就可以知道他解压缩后的大小。对于解压时的计算会有很大的好处!
4.“data”chunk的内部组织
从“data”chunk的第9个字节开始,存储的就是声音信息的数据了,(前八个字节存储的是标志符“data”和后接数据大小size(DWORD)。这些数据可能是压缩的,也可能是没有压缩的。
PCM中的声音数据没有被压缩,如果是单声道的文件,采样数据按时间的先后顺序依次存入。(它的基本组织单位是BYTE(8bit)或WORD(16bit))如果是双声道的文件,采样数据按时间先后顺序交叉地存入。如图所示:

IMA-ADPCM是压缩格式,它是从PCM的16位采样压缩成4位的。对于单声道的IMA-ADPCM来说,它是将PCM的数据按时间次序依次压缩并写入文件中的,每个byte中含两个采样,低四位对应第一个采样,高四位对应第二个采样。而对于双声道的IMA-ADPCM来说,它的存储相对就麻烦一些了,它是将PCM的左声道的前8个采样依次压缩并写入到一个DWORD中,然后写入“data”chunk里。紧接着是右声道的前8个采样。以此循环,当采样数不足8时(到数据尾端),应该把多出来的采样用0填充。其示意图如下:
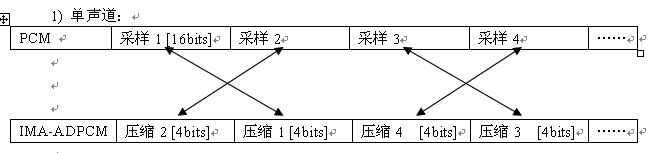
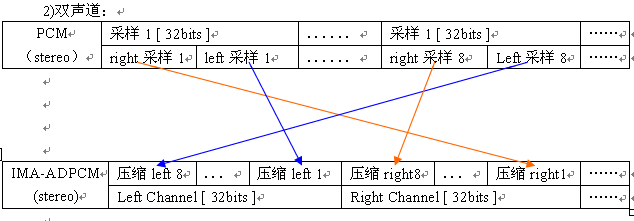
特别注意:
在IMA-ADPCM中,“data”chuck中的数据是以block形式来组织的,我把它叫做“段”,也就是说在进行压缩时,并不是依次把所有的数据进行压缩保存,而是分段进行的,这样有一个十分重要的好处:那就是在只需要文件中的某一段信息时,可以在解压缩时可以只解所需数据所在的段就行了,没有必要再从文件开始起一个一个地解压缩。这对于处理大文件将有相当的优势。同时,这样也可以保证声音效果。
Block一般是由block header (block头) 和data 两者组成的。其中block header是一个结构,它在单声道下的定义如下:
Typedef struct
{
short sample0; //block中第一个采样值(未压缩)
BYTE index; //上一个block最后一个index,第一个block的index=0;
BYTE reserved; //尚未使用
}MonoBlockHeader;
有了blockheader的信息后,就可以不需要知道这个block前面和后面的数据而轻松地解出本block中的压缩数据。对于双声道,它的blockheader应该包含两个MonoBlockHeader其定义如下:
typedaf struct
{
MonoBlockHeader leftbher;
MonoBlockHeader rightbher;
}StereoBlockHeader;
在解压缩时,左右声道是分开处理的,所以必须有两个MonoBlockHeader;
注1:上述的index是解压缩算法中必须用到的一个参数。详见后面。
注2: 关于block的大小,通常会有以下几种情况:
对于单声道,大小一般为512byte,显然这里面可以保存的sample个数为(512-sizeof(MonoBlockHeader))/4 + 1 = 1017个<其中"+1"是第一个存在头结构中的没有压缩的sample.
对于双声道,大小一般为1024byte,按上面的算法可以得出,其中的sample个数也是1017个.
4.读取WAVE文件的方法.
在知道了WAVE文件的内部数据组织后,可以直接通过FILE或HFILE来实现文件的读取。但由于WAVE文件是以RIFF格式来组织的,所以用多媒体输入输出流来操作将更加方便,可以直接在文件中查找chunk并定位数据。
三、IMA-ADPCM 编码和解码算法
IMA-ADPCM 是Intel公司首先开发的是一种主要针对16bit采样波形数据的有损压缩算法, 压缩比为4:1.它与通常的DVI-ADPCM是同一算法。(对8bit数据压缩时是3.2:1,也有非标准的IMA-ADPCM压缩算法,可以达到5:1甚至更高的压缩比)4:1的压缩是目前使用最多的压缩方式。
ADPCM(Adaptive Differential Pulse Code Modulation 差分脉冲编码调制)主要是针对连续的波形数据的, 保存的是相临波形的变化情况, 以达到描述整个波形的目的。算法中必须用到两个一维数组,setptab[] 和index_adjust[],附在下面的代码之后。
--------------------------------------------------------------------------------
IMA-ADPCM 压缩过程
首先我们认为声音信号都是从零开始的,那么需要初始化两个变量
int index = 0,prev_sample = 0;
但在实际使用中,prev_sample的值是每个block中第一个采样的值。(这点在后面的block中会详细介绍)
假设已经写好了两个函数:
GetNextSamp() ——得到一个16bit 的采样数据;
SaveComCode() ——保存一个4bit 的压缩样品;
下面的循环将依次压缩声音数据流:
while (还有数据要处理) {
cur_sample = GetNextSamp(); // 得到PCM中的当前采样数据
diff = cur_sample-prev_sample; // 计算出和上一个的增量
if (diff<0)
{
diff=-diff;
fg=8;
}
else fg=0; // fg 保存的是符号位
code = 4*diff / steptab[index];
if (code>7) code=7; // 根据steptab[] 得到一个0~7 的值,它描述了采样振幅的变化量
index+=index_adjust[code]; // 根据声音强度调整下次取steptab 的序号,便于下次得到更精确的变化量的描述
if (index<0) index=0; // 调整index的值
else if (index>88) index=88;
prev_sample=cur_sample;
SaveComCode(code|fg); // 加上符号位保存起来
}
--------------------------------------------------------------------------------
IMA-ADPCM 解压缩过程
解压缩实际是压缩的一个逆过程,假设写好了以下两个函数:
GetNextCode() ——得到一个编码(4bit)
OutputSamp() ——将解码出来的声音信号保存起来(16bit).
int index=0,cur_sample=0;
while (还有数据要处理) {
code=GetNextCode(); // 得到下一个压缩样品Code 4bit
if ((code & 8) != 0) fg=1 else fg=0;
code&=7; // 将code 分离为数据和符号
diff = (steptab[index]*code) /4 + steptab[index] / 8; // 后面加的一项是为了减少误差
if (fg==1) diff=-diff;
cur_sample+=diff; // 计算出当前的波形数据
if (cur_sample>32767) OutputSamp(32767);
else if (cur_sample<-32768) OutputSamp(-32768);
else OutputSamp(cur_sample);
index+=index_adjust[code];
if (index<0) index=0;
if (index>88) index=88;
}
--------------------------------------------------------------------------------
附表
int index_adjust[8] = {-1,-1,-1,-1,2,4,6,8};
int steptab[89] = { 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 19, 21, 23, 25, 28, 31, 34, 37, 41, 45, 50, 55, 60, 66, 73, 80, 88, 97, 107, 118, 130, 143, 157, 173, 190, 209, 230, 253, 279, 307, 337, 371, 408, 449, 494, 544, 598, 658, 724, 796, 876, 963, 1060, 1166, 1282, 1411, 1552, 1707, 1878, 2066, 2272, 2499, 2749, 3024, 3327, 3660, 4026, 4428, 4871, 5358, 5894, 6484, 7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899, 15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794, 32767 };
四、设计自己特用的压缩声音文件格式。
有了上述几节的知识,要基于IMA-ADPCM Encode/Dcode算法来设计出特有的压缩声音文件格式就不难了!只要 先设计好特有的文件内部结构和特殊的数据组织结构,再以此为标准编写压缩和解压缩程序就行了。由于我们已经搞清楚了PCM里面的数据组织,所以我们还可以进行PCM文件的截取、连接、压缩等更多功能。