Spring Boot整合 Jpa教程
Spring Boot整合 Jpa
Spring Boot中的数据持久化方案前面给大伙介绍了两种
Spring Boot整合JdbcTemplate
Spring Boot配置JdbcTemplate之多数据源
SpringBoot整合MyBatis教程
Spring Boot整合MyBatis多数据源
一个是JdbcTemplate,还有一个MyBatis,JdbcTemplate配置简单,使用也简单,但是功能也非常有限,MyBatis则比较灵活,功能也很强大,据我所知,公司采用MyBatis做数据持久化的相当多,但是MyBatis并不是唯一的解决方案,除了MyBatis之外,还有另外一个东西,那就是Jpa。
Jpa介绍
首先需要向大伙介绍一下Jpa,Jpa(Java Persistence API)Java持久化API,它是一套ORM规范,而不是具体的实现,Jpa的江湖地位类似于JDBC,只提供规范,所有的数据库厂商提供实现(即具体的数据库驱动),Java领域,小伙伴们熟知的ORM框架可能主要是Hibernate,实际上,除了Hibernate之外,还有很多其他的ORM框架,例如:
- Batoo JPA
- DataNucleus (formerly JPOX)
- EclipseLink (formerly Oracle TopLink)
- IBM, for WebSphere Application Server
- JBoss with Hibernate
- Kundera
- ObjectDB
- OpenJPA
- OrientDB from Orient Technologies
- Versant Corporation JPA (not relational, object database)
Hibernate只是ORM框架的一种,上面列出来的ORM框架都是支持JPA2.0规范的ORM框架。既然它是一个规范,不是具体的实现,那么必然就不能直接使用(类似于JDBC不能直接使用,必须要加了驱动才能用),我们使用的是具体的实现,在这里我们采用的实现实际上还是Hibernate。
Spring Boot中使用的Jpa实际上是Spring Data Jpa,Spring Data是Spring家族的一个子项目,用于简化SQL和NoSQL的访问,在Spring Data中,只要你的方法名称符合规范,它就知道你想干嘛,不需要自己再去写SQL。
工程创建
创建Spring Boot工程,添加Web、Jpa以及MySQL驱动依赖,如下:
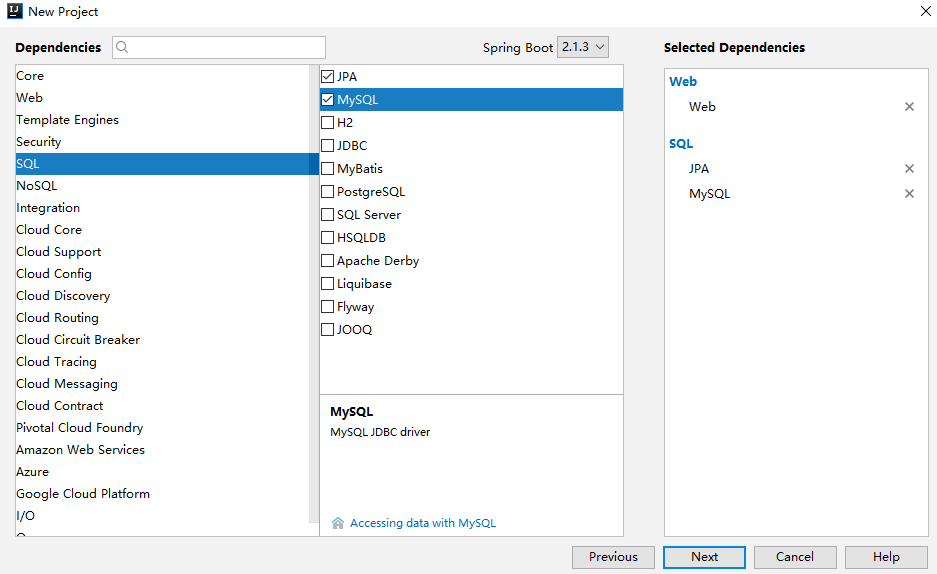
工程创建好之后,添加Druid依赖,完整的依赖如下:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.18version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
如此,工程就算创建成功了。
基本配置
工程创建完成后,只需要在application.properties中进行数据库基本信息配置以及Jpa基本配置,如下:
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.username=xiaoliu
spring.datasource.password=960614abcd
spring.datasource.url=jdbc:mysql:///ssm?serverTimezone=UTC
spring.jpa.show-sql=true
spring.jpa.database=mysql
spring.jpa.database-platform=mysql
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
注意这里和JdbcTemplate以及MyBatis比起来,多了Jpa配置,Jpa配置含义我都注释在代码中了,这里不再赘述,需要强调的是,最后一行配置,默认情况下,自动创建表的时候会使用MyISAM做表的引擎,如果配置了数据库方言为MySQL57Dialect,则使用InnoDB做表的引擎。
好了,配置完成后,我们的Jpa差不多就可以开始用了。
基本用法
ORM(Object Relational Mapping)框架表示对象关系映射,使用ORM框架我们不必再去创建表,框架会自动根据当前项目中的实体类创建相应的数据表。因此,我这里首先创建一个Book对象,如下:
@Entity(name = "t_book")
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private String author;
@Override
public String toString() {
return "Book{" +
"id=" + id +
", name='" + name + '\'' +
", author='" + author + '\'' +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
}
首先@Entity注解表示这是一个实体类,那么在项目启动时会自动针对该类生成一张表,默认的表名为类名,@Entity注解的name属性表示自定义生成的表名。@Id注解表示这个字段是一个id,@GeneratedValue注解表示主键的自增长策略,对于类中的其他属性,默认都会根据属性名在表中生成相应的字段,字段名和属性名相同,如果开发者想要对字段进行定制,可以使用@Column注解,去配置字段的名称,长度,是否为空等等。
做完这一切之后,启动Spring Boot项目,就会发现数据库中多了一个名为t_book的表了。
针对该表的操作,则需要我们提供一个Repository,如下:
public interface BookDao extends JpaRepository<Book,Integer> {
Book findBookById(Integer id);
List<Book> findBookByIdGreaterThan(Integer id);
List<Book> findBookByIdLessThanOrNameContaining(Integer id,String name);
@Query(value = "select * from t_book where id=(select max(id) from t_book)",nativeQuery = true)
Book getMaxIdBook();
@Query(value = "insert into t_book(name,author) values(?1,?2)",nativeQuery = true)
@Modifying
@Transactional
Integer addBook(String name,String author);
@Query(value = "insert into t_book(name,author) values(:name,:author)",nativeQuery = true)
@Modifying
@Transactional
Integer addBook2(@Param("name") String name, @Param("author")String author);
}
这里,自定义BookDao接口继承自JpaRepository,JpaRepository提供了一些基本的数据操作方法,例如保存,更新,删除,分页查询等,开发者也可以在接口中自己声明相关的方法,只需要方法名称符合规范即可,在Spring Data中,只要按照既定的规范命名方法,Spring Data Jpa就知道你想干嘛,这样就不用写SQL了,那么规范是什么呢?参考下图:
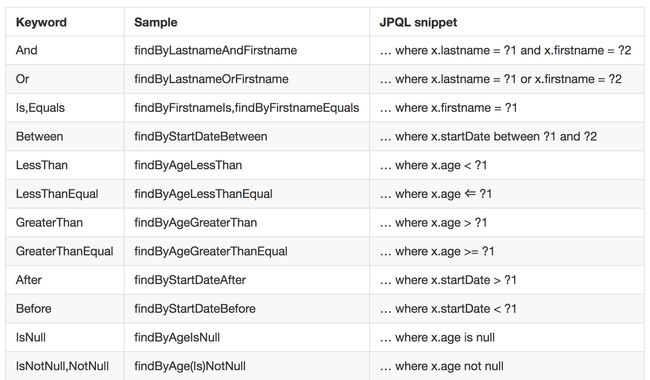
当然,这种方法命名主要是针对查询,但是一些特殊需求,可能并不能通过这种方式解决,例如想要查询id最大的用户,这时就需要开发者自定义查询SQL了,如上代码所示,自定义查询SQL,使用@Query注解,在注解中写自己的SQL,默认使用的查询语言不是SQL,而是JPQL,这是一种数据库平台无关的面向对象的查询语言,有点定位类似于Hibernate中的HQL,在@Query注解中设置nativeQuery属性为true则表示使用原生查询,即大伙所熟悉的SQL。上面代码中的只是一个很简单的例子,还有其他一些点,例如如果这个方法中的SQL涉及到数据操作,则需要使用@Modifying注解。
好了,定义完Dao之后,接下来就可以在测试类中进行测试了
@RunWith(SpringRunner.class)
@SpringBootTest
public class JpaApplicationTests {
@Autowired
BookDao bookDao;
@Test
public void contextLoads() {
Book book=new Book();
book.setName("三国演义");
book.setAuthor("罗贯中");
bookDao.save(book);
}
@Test
public void update(){
Book book=new Book();
book.setAuthor("luoguanzhong");
book.setName("sanguoyanyi");
book.setId(2);
bookDao.saveAndFlush(book);
}
@Test
public void delete(){
bookDao.deleteById(2);
}
@Test
public void find1(){
Optional<Book> byId = bookDao.findById(3);
System.out.println(byId.get());
List<Book> all=bookDao.findAll();
System.out.println(all);
}
// @Test
// public void find2(){
// List list = bookDao.findAll(new Sort(Sort.Direction.DESC, "id"));
// System.out.println(list);
// }
@Test
public void find3(){
Pageable pageable= PageRequest.of(0,2 );
Page<Book> page = bookDao.findAll(pageable);
System.out.println("总记录数:"+page.getTotalElements());
System.out.println("当前页记录数:"+page.getNumberOfElements());
System.out.println("每页记录数:"+page.getSize());
System.out.println("获取总页数:"+page.getTotalPages());
System.out.println("查询结果:"+page.getContent());
System.out.println("当前页(从0开始计):"+page.getNumber());
System.out.println("是否为首页:"+page.isFirst());
System.out.println("是否为尾页:"+page.isLast());
}
@Test
public void find4(){
Book book=bookDao.findBookById(3);
System.out.println(book);
}
@Test
public void find5(){
List<Book> list = bookDao.findBookByIdGreaterThan(4);
System.out.println(list);
List<Book> list1 = bookDao.findBookByIdLessThanOrNameContaining(5, "水");
System.out.println(list1);
}
@Test
public void find6(){
Book book=bookDao.getMaxIdBook();
System.out.println(book);
}
@Test
public void test7(){
Integer r1 = bookDao.addBook2("java", "小刘");
System.out.println(r1);
Integer r2 = bookDao.addBook("python", "老刘");
System.out.println(r2);
}
}
如此之后,即可查询到需要的数据。
好了,本文的重点是Spring Boot和Jpa的整合,这个话题就先说到这里。