【故障排查】tomcat session堆积导致内存占满频繁Full GC
一、故障发生
从一周前开始陆续接到线上用户反馈说接口访问偶发延时过大,频率大概是10%,延时8s左右。通过查看日志发现,有时上游服务发出请求后七八秒钟后本服务才收到请求,有时是本服务发出请求后七八秒钟后下游服务才收到请求,加之本服务已经在线上4个月没修改过代码没重启了,猜测可能是网络原因。找运维看了好几天也没发现大问题。
二、问题排查
1. 发现线索
偶然翻看线上gc日志,发现隔几分钟就会出现concurrent mode failure错误,处理这个错误花费的时间恰好跟线上接口延时时间相符。日志如下:
2020-03-29T07:18:23.553+0800: 11637468.523: [GC2020-03-29T07:18:23.553+0800: 11637468.523: [ParNew: 628867K->628867K(629120K), 0.0000410 secs]2020-03-29T07:18:23.553+0800: 11637468.
523: [CMS2020-03-29T07:18:24.060+0800: 11637469.029: [CMS-concurrent-sweep: 0.760/0.763 secs] [Times: user=0.00 sys=0.82, real=0.76 secs]
(concurrent mode failure): 1398143K->1398143K(1398144K), 8.9975520 secs] 2027011K->1869203K(2027264K), [CMS Perm : 43504K->43504K(72824K)], 8.9978420 secs] [Times: user=0.00 sys=8.98, real=9.00 secs]出现这个错误是因为在CMS回收老年代垃圾的时候,又有新的对象要进入老年代,但这时老年代空间不足放不下,触发这个报错。这时JVM会改用serial收集器回收垃圾,速度很慢且会stop the world。于是怀疑代码里可能有哪里有大对象产生。查看JVM参数如下:
-Xmx:2048M -XX:MaxPermSize=512M -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps \
-Xloggc:gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=20M按照默认1:2计算,老年代空间应该有1.3G左右。查看项目代码,最大的对象统计了下也只有30K,应该不算是大对象。再结合项目的QPS计算一下,感觉应该也不会导致上面那个错误。
2. 弯路
通过gc日志发现,老年代总量1398144K,gc开始的时候已经占了1398143K!!难道是触发gc的世纪不对?于是想要通过加入如下配置来改变gc时机。意思是在老年代空间还剩30%的时候就触发Full gc,而且每次gc都使用这个规则。
-XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly那为什么4个月来,最近一周才开始出现问题呢?难道是jvm默认的回收触发策略时间一长会出现什么bug?再仔细翻看gc日志又发现了一个重大的问题!!几乎看不到Young gc,全部都是full gc,而且是几秒钟一次,只不过不是每次都会出现concurrent mode failure错误。再多点日志看下:
2020-03-29T07:18:32.568+0800: 11637477.537: [GC [1 CMS-initial-mark: 1398143K(1398144K)] 1874205K(2027264K), 0.5915670 secs] [Times: user=0.00 sys=0.59, real=0.59 secs]
2020-03-29T07:18:33.160+0800: 11637478.129: [CMS-concurrent-mark-start]
2020-03-29T07:18:35.353+0800: 11637480.323: [CMS-concurrent-mark: 2.193/2.193 secs] [Times: user=0.00 sys=6.63, real=2.19 secs]
2020-03-29T07:18:35.353+0800: 11637480.323: [CMS-concurrent-preclean-start]
2020-03-29T07:18:37.899+0800: 11637482.869: [CMS-concurrent-preclean: 2.546/2.546 secs] [Times: user=0.00 sys=2.55, real=2.55 secs]
2020-03-29T07:18:37.900+0800: 11637482.869: [CMS-concurrent-abortable-preclean-start]
2020-03-29T07:18:37.900+0800: 11637482.869: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2020-03-29T07:18:37.901+0800: 11637482.870: [GC[YG occupancy: 487494 K (629120 K)]2020-03-29T07:18:37.901+0800: 11637482.870: [Rescan (parallel) , 0.7314790 secs]2020-03-29T07:18:38.632+0800: 11637483.602: [weak refs processing, 0.0000430 secs]2020-03-29T07:18:38.632+0800: 11637483.602: [scrub string table, 0.0008920 secs] [1 CMS-remark: 1398143K(1398144K)] 1885638K(2027264K), 0.7325420 secs] [Times: user=0.00 sys=6.70, real=0.73 secs]
2020-03-29T07:18:38.633+0800: 11637483.603: [CMS-concurrent-sweep-start]
2020-03-29T07:18:39.381+0800: 11637484.351: [CMS-concurrent-sweep: 0.748/0.748 secs] [Times: user=0.00 sys=0.75, real=0.75 secs]
2020-03-29T07:18:39.382+0800: 11637484.351: [CMS-concurrent-reset-start]
2020-03-29T07:18:39.386+0800: 11637484.355: [CMS-concurrent-reset: 0.004/0.004 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]每次gc老年代里面都是满的,怎么可能几秒钟就占满呢,肯定是没被回收!就是说项目中有无用对象在占用堆空间,这些对象随着时间的推移在逐渐累积。
3. 线上临时处理
按照上面的分析,重启服务是能暂时解决问题的,而且需要尽快重启,不然很可能服务会挂掉。于是先把n-1台机器上的服务重启了下,查看gc日志,没问题了,只有YC日志了。剩下的一台调低流量比例,下载jmap jump文件,命令:jmap -dump:live,format=b,file=h.hprof PID 。保存现场后,将此机器服务也重启了。线上没问题了。下面可以安心的找bug了。
4. 解析dump堆快照文件
dump的文件太大怕把线上机器搞坏了,于是同步到测试环境机器上,准备用MAT工具分析下。首先安装MAT工具:
1. 下载安装包,地址:http://www.eclipse.org/mat/downloads.php
在linux服务器执行命令 uname –m查看linux版本,点击上面的地址,找到相应版本,下载。如linux版本是x86_64,选择如下
我的测试机jdk环境是1.7的,所以选了MAT 1.7.0版本。
2. 先用unzip 解压。后可通过MemoryAnalyzer.ini 配置文件修改最大的内存,默认1G。我的dump文件3G,所以把这个MAT内存调成4G了。
3. cd到解压后的mat文件夹下。执行命令./ParseHeapDump.sh m.hprof org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
m.hprof就是jvm的dump文件,在mat目录下会生成3份.zip结尾的报告和一些m.相关的文件,将生成的m.hprof相关的文件都下载到本地。
5. 分析
生成的3个zip文件是综合信息,解压打开看下。
1. 先看下m_System_Overview文件夹下的index.html,列出了堆里面的对象占用内存汇总信息。

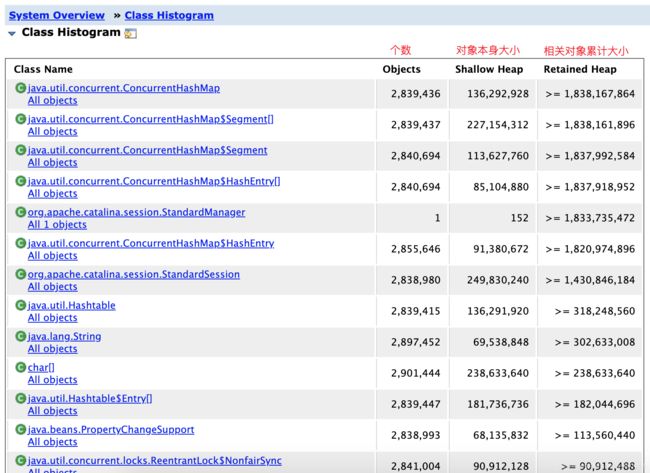
按照一般思路,会去里面找下排名第一的自定义类对象,可是自定义类对象排名相当靠后,排除。
2. 再看下m_Leak_Suspects文件夹下的index.html,发现一行醒目的提示。
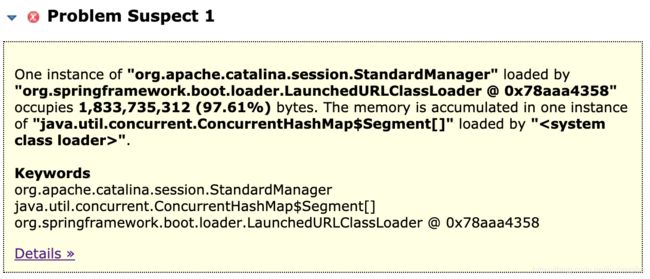
翻译一下:由“ org.springframework.boot.loader.LaunchedURLClassLoader @ 0x78aaa4358”加载的“ org.apache.catalina.session.StandardManager”的一个实例占用1,833,735,312(97.61%)字节。 内存在由“ <系统类加载器>”加载的“ java.util.concurrent.ConcurrentHashMap $ Segment []”的一个实例中累积。
意思是,有一个StandardManager对象,里面的ConcurrentHashMap数据太多,占用里97%的堆空间!!
迅速查看下这个类是干嘛用的,是tomcat用于保存session的。
3. 项目代码里有这么一个controller定义:
@RequestMapping(value = "/xxx", method = RequestMethod.GET)
public SystemConfig getSystemConfig(HttpServletResponse servletResponse,
HttpSession session) {
// 业务代码
// session.getId()
}如果这么写了Springboot会在处理的时候默认注入一个session进去,若请求头cookie中有session则校验通过后用传入的session,否则新生成一个sessionid,并以JSESSIONID为key放到response里返回给用户。
而由于项目本身历史原因,request里永远不会有session传入,所以每次请求这个接口都会新建一个session!再通过打印 request.getSession().getMaxInactiveInterval() 发现是-60,也就是不会过期!不断的生成session且不会清理,难怪内存会被撑爆。
三、 问题解决
确认这个逻辑无用后删掉这个字段,顺便把堆空间调大成4G。通过response头信息验证不会有session产生。发布上线。