在Unity中使用ML-Agents实现一个简单的小球AI
在Unity中使用ML-Agents实现一个简单的小球AI
- 1 环境搭建
- 2 官方案例3DBall
- 2.1 直接运行结果
- 2.2 尝试训练
- 3 创建一个简单案例
- 3.1 搭建场景
- 3.2 代码
- 3.3 相关设置
- 3.4 训练
- 3.5 运行训练出来的模型
1 环境搭建
网上的教程也有,这里就不详细说了。这次主要是参看了这个博客搭建好的环境(虽然以前已经搭建过了,但是太久了都不知道怎么搭的了,所以重新搭建一遍)。
大概流程就是:
- 下载Anaconda,然后安装。就和安装一般软件一样简单。
- 下载ML-agents,虽然目前最新都已经更新到0.10了,但是我这里下的是0.8.1的relaese,因为看的教程用的是这个。
- 用Anaconda创建一个环境。可以使用命令行也可以使用可视化界面Anaconda Navigator。这个也比较简单。
- 激活环境,使用pip命令安装相应的内容。先直接在环境下安装mlagents相关内容,再到ml-agents-envs和ml-agents位置下安装"-e ."(目前还不太懂这个意思)。
2 官方案例3DBall
2.1 直接运行结果
- 打开场景。
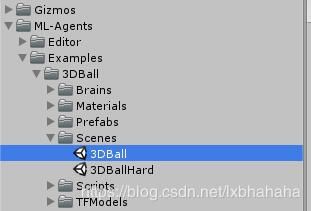
- 确保Ball3DAcademy中的这个control没有勾上,勾上了就是训练的模式,不勾就是运行的模式。
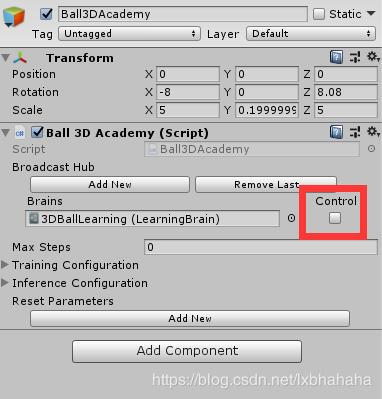
- 直接播放就可以看到结果了(因为模型已经训练好,各种东西都设置好了)。小球都稳稳的被拖着,即便手动的拖动小球也几乎不会掉。
2.2 尝试训练
- 先用cd命令把路径切换到mlagents的根目录(不是Unity工程的根目录,是更外面一层的目录)。

- 然后输入这条命令
mlagents-learn config/trainer_config.yaml --run-id=3dball --train
其中,config/trainer_config.yaml是配置文件。id=后面,即“3dball”,为训练的id,可以改成自己喜欢的。最后会在model文件夹中生成一个用id命名的文件,训练完的模型就会在里面。
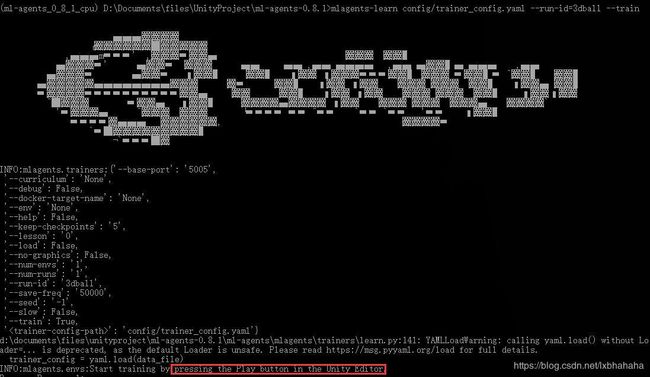
回车之后不出意外的话会出现以下画面,最后一行字就是请在Unity编辑器中按下播放。==确保这个时候academy中的control是勾上的,==因为现在要训练而不是运行结果。
- 按下播放之后,Unity就开始快速的训练(如果没有修改过的话,现在应该是100倍的速度在训练)
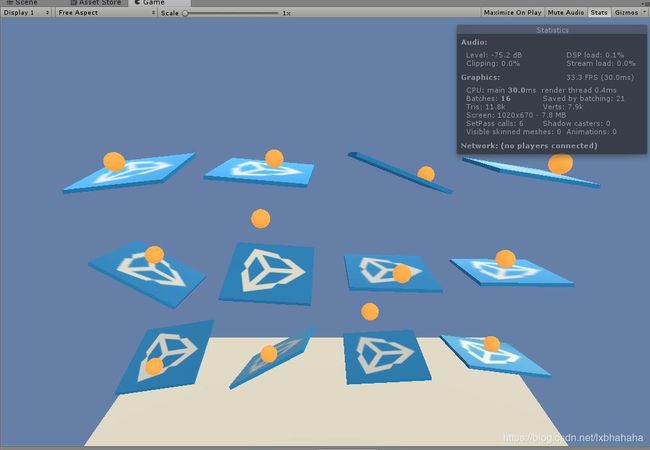
此时可以看出小球还是很容易掉落的(这不是gif,懒得弄哈哈)。
同时CMD这边先是输出了一些配置信息,然后就开始每1000步输出一次结果。MeanReward就是平均奖励(就是通过奖励的方法来训练的)。可以看出随着训练次数的增长,获得的平均奖励越来越高,说明训练的效果还是不错的。

- 训练完成之后运用训练好的模型。
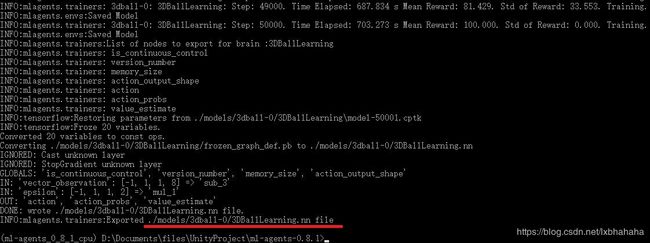
训练次数完成之后就会出现这样的界面,可以看到训练出来的模型已经已经导出到根目录底下的models/3dball-0/中。
然后把这个.nn文件放到unity中,替换掉我们刚才的Brain中的model。

然后取消勾选academy的control,再运行就可以看到训练好的成果了。
3 创建一个简单案例
既然能够成功的训练官方案例了,那么就来做一个简单的案例吧。主要是参照这个博客(不过也改了些东西),做一个小球自动去寻找靠近目标的AI。这貌似是类似HelloWord的第一个案例,找到好多个按这个思路的教程,也很简单。
3.1 搭建场景
- 地板,创建一个Plane,Reset一下位置。象征性的给个材质。
- 小球,创建一个Sphere,放到地板上。象征性的给个材质,加一个Rigidbody。
- 目标,创建一个Cube,放到地板上。象征性的给个材质,Tag设为goal。
- Academy,创建一个空物体。


3.2 代码
然后就开始写代码了,一共只创建两个脚本。
- RollerAgent,继承自Agent,然后将脚本给我小球。
- RollerAcademy,继承自Academy,然后将脚本给Academy空物体。
Agent和Academy都是在MLAgents命名空间下的。
RollerAcademy里面什么都不用写,Agent的脚本如下:
using MLAgents;
using UnityEngine;
// 原博客的代码又很多注释,这里简洁一点就删掉了,以及一些小小的修改
public class RollerAgent : Agent
{
public Transform Target;
Rigidbody rBody;
public float speed = 10;
void Start()
{
rBody = GetComponent<Rigidbody>();
}
public override void AgentReset()
{
if (transform.localPosition.y < 0)
{
rBody.angularVelocity = Vector3.zero;
rBody.velocity = Vector3.zero;
transform.localPosition = new Vector3(0, 0.5f, 0);
}
Target.localPosition = new Vector3(Random.Range(-4.5f,4.5f),
0.5f,
Random.Range(-4.5f, 4.5f));
}
public override void CollectObservations()
{
AddVectorObs(Target.localPosition - transform.localPosition);
AddVectorObs(rBody.velocity.z);
AddVectorObs(rBody.velocity.x);
}
public override void AgentAction(float[] vectorAction, string textAction)
{
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
rBody.AddForce(controlSignal * speed);
if (transform.localPosition.y < 0)
{
Done();
}
}
private void OnCollisionEnter(Collision other) {
if(other.transform.tag == "goal"){
SetReward(1.0f);
Done();
}
}
}
其中的一些函数的意义
public override void AgentReset()
{
// 执行Done()之后会调用。就是一次重置,可以在这个函数中重新设置下一次训练的内容
}
public override void CollectObservations()
{
// 收集信息。在这里给tensorflow传递要用的参数,会影响到Brain设置中Vector Observation的设置。
}
public override void AgentAction(float[] vectorAction, string textAction)
{
// 根据处理得出的结果进行动作。
// vectorAction是得出向量,跟Brain设置中Vector Action的设置有影响。用这些结果再次进行控制小球的运动。
// textAction还不知道是干嘛的
}
3.3 相关设置
需要创建一个LearningBrain,名字取什么都可以。

然后这个LearningBrain的设置如下,Vector Observation中的Space Size是5(原博客中是8,因为我改了下代码,去掉了3个分量,所以是5),Vector Action中的Space Size是2。对应的就是代码中传入的数据和得出的数据的个数(不是变量的个数,而是具体分量的个数,比如一个Vector3再加两个float就是5了)。这时候下面提示说没有模型,但是可以训练。这是当然的,因为我们还没有训练怎么会有模型嘛,如果是执行训练的结果就必须要有模型了,而且Brain和模型(Model)向量不匹配的话也是会提示的。

然后把这个Brain分别放到RollerAcademy和RollerAgent中的对应位置(RollerAcademy中如果没有的话就先add New一下)。然后勾上后面的Control等待我们的训练。
接下来就是配置一下相关的训练信息(不设置也行,就会使用默认的,不同的案例设置一个对应合适的训练信息训练效果会更好。不过设置成什么样就需要机器学习的跟多知识了,我也只是略知一二)。在根目录的config文件夹中有一个trainer_config.yaml文件,打开它可以看到其他的案例的训练信息。我们在后面加上一段下面这个:
SingleRollerBallLearningBrain:
batch_size: 10
buffer_size: 100
max_steps: 2.0e4
第一行就是创建的LearningBrain的名称,创建的是啥就写啥,训练前MLAgents会自己到这个配置文件中寻找和大脑对应的训练信息。
batch_size,根据我浅薄的知识储备这应该是一次喂入网络中数据的数量。
buffer_size,这个就猜不出来了。
max_steps,这个最好理解,就是最多训练多少回。用的是科学计数法,2.0e4就是两万的意思。
要注意冒号之后是有空格的。
3.4 训练
接下来就可以开始训练了(就跟刚才训练官方案例一模一样)。
同样的先把在命令提示符中把路径设置到mlagents的根目录,然后输入一下的指令,回车。
mlagents-learn config/trainer_config.yaml --run-id=RollerBall --train
这句话的意思同理上面训练官方案例的时候。
然后提示运行Unity编辑器。运行之后等待训练结束。
这里有个小插曲,在跟着做的时候发现怎么训练都训练的一塌糊涂。也找不出问题在哪里,后来下载原博客的工程仔细比对才发现原来RollerAgent中的Decision Interval和别人的不一样。我这里自带默认就是1,别人是10,改过来之后就好了。(下面有个Obstacles是因为想加一个躲避障碍的功能,结果训练了半天也得不到好的结果)

3.5 运行训练出来的模型
把训练出来的模型放到Brain中,去掉Control。运行。
第一个小案例就做好了。