DEEP LEARNING FOR ANOMALY DETECTION : A SURVEY 笔记
DEEP LEARNING FOR ANOMALY DETECTION : A SURVEY 笔记
- 学习笔记,如有谬误,还请不吝赐教!
- 瞎BB以及不错的链接
- 还不散,那就看文章吧,反正我也是google翻译的~
- 1. Introduction
- 2,3. 何为异常和新颖
- 4. 动机和挑战
- 5,6,7 略(嗯,博主就是这么敷衍...)
- 8. DAD的不同方面
- 8.1 数据性质
- 8.2 基于标记信息
- 8.2.1 Supervised deep anomaly detection
- 8.2.2 Semi-supervised deep anomaly detection
- 8.2.3 Unsupervised deep anomaly detection
- 8.3 基于训练目标
- 8.3.1 Deep hybrid models (DHM) (深度混合模型)
- 8.3.2 One class neural networks (OC-NN))(一分类神经网络)
- 8.4 Type of Anomaly 异常类别
- 8.4.1 Point Anomalies
- 8.4.2 Contextual Anomaly Detection
- 8.4.3 Collective or Group Anomaly Detection
- 8.5 Output of DAD Techniques
- 9 Applications of Deep Anomaly Detection
- 9.1 Intrusion Detection 入侵
- 9.2 Fraud Detection 欺诈
- 9.3 Malware Detection 恶意软件
- 9.4 Medical Anomaly Detection 医学
- 9.5 Deep learning for Anomaly detection in Social Networks
- 9.6 Log Anomaly Detection
- 9.7 Internet of things (IoT) Big Data Anomaly Detection
- 9.8 Industrial Anomalies Detection
- 9.9 Anomaly Detection in Time Series
- 9.10 Video Surveillance 监控
- 10 Deep Anomaly Detection (DAD) Models
- 10.1 Supervised deep anomaly detection
- 10.2 Semi-supervised deep anomaly detection
- 10.3 Hybrid deep anomaly detection
- 10.4 One-class neural networks (OC-NN) for anomaly detection
- 10.5 Unsupervised Deep Anomaly Detection
- 后记
学习笔记,如有谬误,还请不吝赐教!
瞎BB以及不错的链接
失踪人口回归?趁着领导们都不在来博客摸个鱼?!!!
入职之后头头儿让我搞异常检测,搞一个模型,训练集只有正常图片,要检测出异常的图片… 而且,最麻烦的是,这个是要做到像素级检测的,不止要找出异常图像,还要指出异常的位置在哪里。而这就和大多数做图像异常检测方法不一样了。
但毕竟温故而知新,拖师妹的福,给了两个github的链接,整理了一些异常检测的论文,包括综述(找论文也上GitHub?!学习了!!)。先放上码住!(排名不分先后)
第一链接.
https://github.com/kc-ml2/journal-lub/blob/ceaa45c5822f55d8060afdab907280d3e47b9288/past/2019-06-12-anomaly-detection.md
第二链接.
https://github.com/zhuyiche/awesome-anomaly-detection
很好,以上就是本篇博客最有价值的部分,散了散了~~
还不散,那就看文章吧,反正我也是google翻译的~
正文为提取的文章中比较有用的内容(没错 就是断章取义的意思!),括号内的内容为个人理解(就是瞎bb)
1. Introduction
随着数据量的增加,深度异常检测( deep anomaly detection (DAD))相较传统的异常检测方法具有明显的优势。
2,3. 何为异常和新颖
(其实文章也没有给出一个严格的定义,个人理解就是除了正常都是异常。怎么定义正常呢?用数据。)
这里就放个图吧
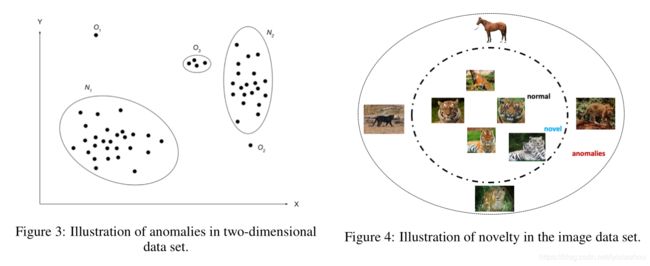
还挺形象的哈
4. 动机和挑战
diss传统方法:
1.传统方法难以获取数据中的复杂结构(比如医学图像)
2.传统方法难以处理大数据量
夸一下深度学习:
3.深度异常检测(DAD)技术可从数据中学习分层区分特征。这种自动特征学习功能消除了领域专家开发手动特征的需要,因此提倡解决端对端问题,即在文本和语音识别等领域中采用原始输入数据。
说一下异常检测的共同难题:
4.正常和异常(错误)行为之间的界限通常无法在几个数据域中精确定义,并且还在不断发展。对于常规算法和基于深度学习的算法而言,缺乏明确定义的代表性法线边界都带来了挑战。(模糊数学的用武之地?!!)
5,6,7 略(嗯,博主就是这么敷衍…)
8. DAD的不同方面
8.1 数据性质
1.顺序输入,例如,语音,文本,音乐,时间序列,蛋白质序列
2.非顺序数据,例如,图像
相应的深度学习模型见下表
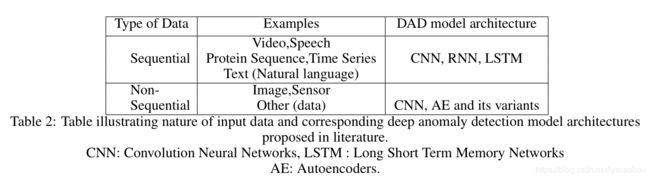
或者
1.低维
2.高维
DAD技术已被用来学习高维原始输入数据中的复杂层次特征关系(LeCun等[2015])。 DAD技术中使用的层数受输入数据维数的驱动,显示出更深的网络可在高维数据上产生更好的性能。 随后,在第10节中,深入探讨了考虑用于离群值检测的各种模型。(啊 第10节 我都不一定读的到那里…)
8.2 基于标记信息
(1) Supervised deep anomaly detection.
(2) Semi-supervised deep anomaly detection.
(3) Unsupervised deep anomaly detection.
8.2.1 Supervised deep anomaly detection
监督的异常检测就是分类问题,可以检测稀有品牌,检测禁药名称和欺诈性医疗保健交易,但由于1.异常标签不好获取,2.存在严重的类不平衡问题导致分类器效果不咋地,所以本文不讨论这个方法(弃子!!!)
8.2.2 Semi-supervised deep anomaly detection
半监督技术在异常检测中使用更为广泛,常用自编码方式(用正常图像训练自编码,异常图像就会有较大的重构误差,从而达到异常检测的目的,半监督的半应该是要通过异常图像来选择重构误差的阈值,所以训练虽然只有正常图像,但还是需要异常图像参与其中的。)
8.2.3 Unsupervised deep anomaly detection
这个没太看懂,先贴上中英双文,谨防误人子弟… 再说我看懂的…
######################################## 原文 #######################################
Unsupervised deep anomaly detection techniques detect outliers solely based on intrinsic properties of the data instances. Unsupervised DAD techniques are used in automatic labeling of unlabelled data samples since labeled data is very hard to obtain (Patterson and Gibson [2017]). Variants of Unsupervised DAD models (Tuor et al. [2017]) are shown to outperform traditional methods such as principal component analysis (PCA) (Wold et al. [1987]), support vector machine (SVM) Cortes and Vapnik [1995] and Isolation Forest (Liu et al. [2008]) techniques in applications domains such as health and cyber-security. Autoencoders are the core of all Unsupervised DAD models. These models assume a high prevalence of normal instances than abnormal data instances failing which would result in high false positive rate. Additionally unsupervised learning algorithms such as restricted Boltzmann machine (RBM) (Sutskever et al. [2009]), deep Boltzmann machine (DBM), deep belief network (DBN) (Salakhutdinov and Larochelle [2010]), generalized denoising autoencoders (Vincent et al. [2008]) , recurrent neural network (RNN) (Rodriguez et al. [1999]) Long short term memory networks (Lample et al. [2016]) which are used to detect outliers are discussed in detail in Section 11.7.
##################################### Google 翻译 ####################################
深度异常检测技术仅基于数据实例的固有属性来检测异常值。无监督DAD技术用于未标记数据样本的自动标记,因为标记数据很难获得(Patterson和Gibson [2017])。无监督DAD模型的变体(Tuor等人[2017])表现优于传统方法,例如主成分分析(PCA)(Wold等人[1987]),支持向量机(SVM)Cortes和Vapnik [1995]和隔离森林(Liu等人[2008])技术应用于健康和网络安全等应用领域。自动编码器是所有无监督DAD模型的核心。这些模型假定正常实例的普及率高于异常数据实例的失败率,这将导致较高的误报率。此外,还有无监督学习算法,例如受限玻尔兹曼机(RBM)(Sutskever et al。[2009]),深度玻尔兹曼机(DBM),深度置信网络(DBN)(Salakhutdinov和Larochelle [2010]),广义降噪自动编码器(Vincent等)等人(2008)),循环神经网络(RNN)(Rodriguez等人[1999])用于检测异常值的长期短期记忆网络(Lample等人[2016])在11.7节中进行了详细讨论。
#####################################################################################
1.无监督学习DAD算法主要还是基于自编码(实在是没有监督信息了,只能自己监督自己了!所以找一个更合适异常检测的监督标准会很有优势?!)
2. 无监督学习模型误报比较高。(至于原因没看懂…)
8.3 基于训练目标
- Deep hybrid models (DHM).
- One class neural networks (OC-NN).
8.3.1 Deep hybrid models (DHM) (深度混合模型)
这里的混合指的是深度学习+传统检测。深度提特征,传统做检测。
基本流程就是先用自编码提取特征,再将提取到的特征交给传统异常检测方法(如one-class SVM (OC-SVM)),流程如下图。
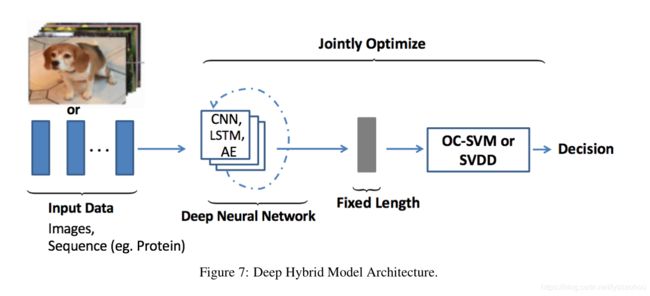
优化: Ergen等人提出了一种混合模型的变体,考虑了特征提取器与OC-SVM(或SVDD)目标的联合训练,以最大化检测性能。
缺点:这些混合方法的显着缺点是缺乏为异常检测定制的可训练目标,因此这些模型无法提取丰富的差异特征来检测异常值。
改进:为了克服这一限制,引入了异常检测的定制目标,例如深度一类分类(Ruff等人[2018a])和一类神经网络(Chalapathy等人[2018a])
8.3.2 One class neural networks (OC-NN))(一分类神经网络)
######################################## 原文 #######################################
One class neural network (OC-NN) Chalapathy et al. [2018a] methods are inspired by kernel-based one-class classification which combines the ability of deep networks to extract a progressively rich representation of data with the one-class objective of creating a tight envelope around normal data. The OC-NN approach breaks new ground for the following crucial reason: data representation in the hidden layer is driven by the OC-NN objective and is thus customized for anomaly detection. This is a departure from other approaches which use a hybrid approach of learning deep features using an autoencoder and then feeding the features into a separate anomaly detection method like one-class SVM (OC-SVM). The details of training and evaluation of one class neural networks is discussed in Section 10.4. Another variant of one class neural network architecture Deep Support Vector Data Description (Deep SVDD) (Ruff et al. [2018a]) trains deep neural network to extract common factors of variation by closely mapping the normal data instances to the center of sphere, is shown to produce performance improvements on MNIST (LeCun et al. [2010]) and CIFAR-10 (Krizhevsky and Hinton [2009]) datasets.
##################################### Google 翻译 ####################################
一分类神经网络(OC-NN)方法的灵感来自基于内核的一分类,该分类结合了深度网络提取渐进丰富的数据表示的能力和创建围绕正常数据的紧密包络的一类目标。 OC-NN方法由于以下关键原因而开辟了新天地:隐藏层中的数据表示由OC-NN目标驱动,因此可以针对异常检测进行定制。这与其他方法不同,后者使用一种混合方法,即使用自动编码器学习深层特征,然后将特征馈入单独的异常检测方法中,例如一分类SVM(OC-SVM)。关于训练和评估一分类神经网络的详细信息,请参见第10.4节。一分类神经网络体系结构的另一种变体深度支持向量数据描述(Deep SVDD)(Ruff等人[2018a])训练了深度神经网络,通过将正常数据实例紧密映射到球体中心来提取变化的公共因子。在MNIST(LeCun等人[2010])和CIFAR-10(Krizhevsky and Hinton [2009])数据集上的性能提高。
#####################################################################################
(你瞧,这就是找到了一个新的监督信息–一分类!利用分类这个信息来进行监督学习,其中Deep SVDD就是说反正你正常图像是单独一个类嘛,那么你在特征空间中就应该是比较紧密的团簇。)
8.4 Type of Anomaly 异常类别
1.point anomalies 点异常
2.contextual anomalies 上下文异常
3.collective anomalies 这是啥异常?!
这里也没有理解的很透彻,所以还是大段原文,不过配合例子多少能理解一点…(不过这次就不放Google翻译了!因为还不如看原文呢…)
8.4.1 Point Anomalies
Point anomalies often represent an irregularity or deviation that happens randomly and may have no particular interpretation. For instance, in Figure 10 a credit card transaction with high expenditure recorded at Monaco restaurant seems a point anomaly since it significantly deviates from the rest of the transactions. Several real world applications, considering point anomaly detection, are reviewed in Section 9.

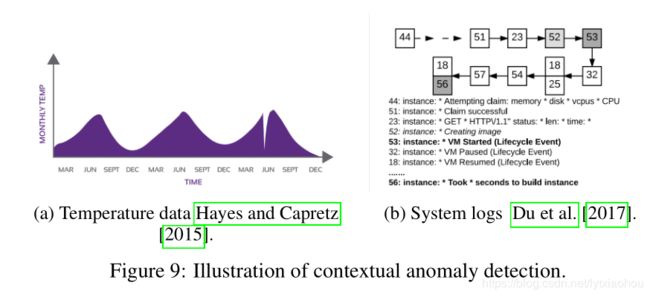
8.4.2 Contextual Anomaly Detection
A contextual anomaly is also known as the conditional anomaly is a data instance that could be considered as anomalous in some specific context (Song et al. [2007]). Contextual anomaly is identified by considering both contextual and behavioural features. The contextual features, normally used are time and space. While the behavioral features may be a pattern of spending money, the occurrence of system log events or any feature used to describe the normal behavior. Figure 9a illustrates the example of a contextual anomaly considering temperature data indicated by a drastic drop just before June; this value is not indicative of a normal value found during this time. Figure 9b illustrates using deep Long Short-Term Memory (LSTM) (Hochreiter and Schmidhuber [1997]) based model to identify anomalous system log events (Du et al. [2017]) in a given context (e.g event 53 is detected as being out of context).
8.4.3 Collective or Group Anomaly Detection
Anomalous collections of individual data points are known as collective or group anomalies, wherein each of the individual points in isolation appears as normal data instances while observed in a group exhibit unusual characteristics. For example, consider an illustration of a fraudulent credit card transaction, in the log data shown in Figure 10, if a single transaction of ”MISC” would have occurred, it might probably not seem as anomalous. The following group of transactions of valued at $75 certainly seems to be a candidate for collective or group anomaly. Group anomaly detection (GAD) with an emphasis on irregular group distributions (e.g., irregular mixtures of image pixels are detected using a variant of autoencoder model (Chalapathy et al. [2018b], Bontemps et al. [2016], Araya et al. [2016], Zhuang et al. [2017]).
所以总结一下,点异常就是孤立点,离群点;上下文异常是这个点不孤立,不离群,但在一个序列中它出现在了不符合序列规律的位置;组异常就是单独看每个数据都正常,但讲这些点看做一个整体时,与其他整体会有明显差别。
8.5 Output of DAD Techniques
1.anomaly score
2.binary label
这个就不细说了,就是要么输出一个分数,表示异常的程度,怎么划分正常异常就是另一件事了。还有就是直接给一个二值的结果,正常或者异常。
9 Applications of Deep Anomaly Detection
这里只会细看一下我关系的方面,其他方面就放个标题表示他说到了。
9.1 Intrusion Detection 入侵
9.2 Fraud Detection 欺诈
9.3 Malware Detection 恶意软件
9.4 Medical Anomaly Detection 医学

9.5 Deep learning for Anomaly detection in Social Networks
9.6 Log Anomaly Detection
9.7 Internet of things (IoT) Big Data Anomaly Detection
9.8 Industrial Anomalies Detection
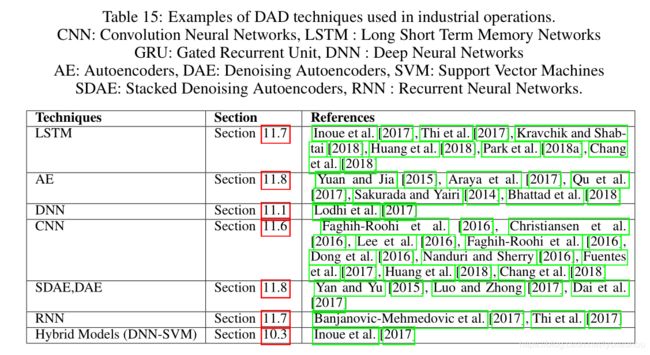
9.9 Anomaly Detection in Time Series
9.10 Video Surveillance 监控
10 Deep Anomaly Detection (DAD) Models
嗯 这里还是要仔细看一下的,不过也是原文为主吧。所以综述嘛,主要还是论文索引,后面还是要去看论文的…
10.1 Supervised deep anomaly detection
由于缺乏干净的数据标签,有监督的深度异常检测技术并不像半监督和无监督方法那样流行。(判了死刑…). 不过讲道理,监督的异常检测我觉得还是有价值的。因为人们说异常检测,只是大家可以明确的告诉你什么是正常,而异常的范围很大很宽泛,不能简单的用语言甚至是数据来描述。但实际应用的时候,需要判断的异常往往并没有那么宽泛,甚至需要检测出来的异常也就那么几种。那么是不是可考虑某种监督类型的异常检测方法,只检测一些异常,然后依靠网络的泛化性能来自动识别出一些相近的异常?不过这里一提到网络泛化性能就又很玄学了,也不是一个轻易就可以搞定的事情。)
10.2 Semi-supervised deep anomaly detection
半监督的假设:
1 .邻近性和连续性:在输入空间和学习的特征空间中彼此靠近的点更有可能共享同一标签。
2. 网络的隐层学习了鲁邦的特征并可以依靠这些特征将正常和异常区分开
计算复杂度(不关心…)
优缺点:
- 基于GAN的网络在只有少量异常数据的情况下有着不错的表现
- 语无监督相比,少量的标记可以显著提升性能
- The fundamental disadvantages of semi-supervised techniques presented by (Lu [2009]) are applicable even in a deep learning context. Furthermore, the hierarchical features extracted within hidden layers may not be representative of fewer anomalous instances hence are prone to the over-fitting problem…
10.3 Hybrid deep anomaly detection
混合模型假设:
1.在深度神经网络的隐藏层中提取了稳健的特征,有助于分离可以隐藏异常存在的不相关特征。
2.在复杂的高维空间上构建可靠的异常检测模型需要特征提取器和异常检测器。
优点:
1.特征提取器大大降低了“维数灾难”,尤其是在高维域中。
2.由于线性或非线性核模型在减小的输入维数上运行,混合模型将具有更高的可扩展性和计算效率。
缺点:
1.混合方法是次优的,因为它不能影响特征提取器隐藏层内的表示学习,因为采用了通用损失函数而不是用于异常检测的定制目标。
2.The deeper hybrid models tend to perform better if the individual layers are (Saxe et al. [2011]) which introduces computational expenditure.(如果在网络层中加入额外的算力,深度混合模型会表现的更好)
10.4 One-class neural networks (OC-NN) for anomaly detection
OC-NN approach is novel for the following crucial reason: data representation in the hidden layer are learned by optimizing the objective function customized for anomaly detection as illustrated in The experimental results in (Chalapathy et al. [2018a], Ruff et al. [2018a]) demonstrate that OC-NN can achieve comparable or better performance than existing state-of-the-art methods for complex datasets, while having reasonable training and testing time compared to the existing methods.
OC-NN方法之所以新颖,原因有以下几个关键原因:隐藏层中的数据表示是通过优化针对异常检测定制的目标函数来学习的,如(Chalapathy et al.[2018a],Ruff et al.[2018a])表明,与现有方法相比,OC-NN可以实现比现有或最新的复杂数据集更好的性能,并且与现有方法相比具有合理的训练和测试时间。
模型假设:
1.OC-NN模型提取深层神经网络的隐藏层中数据分布内变化的共同因素。
2.执行组合表示学习,并为测试数据实例生成离群值。
3.异常样本不包含变化的共同因素,因此隐藏层无法捕获异常值的表示。
优点:
1.OC-NN模型联合训练一个深度神经网络,同时优化输出空间中的数据封闭超球面或超平面。
2.OC-NN提出了一种交替最小化算法,用于学习OC-NN模型的参数。 我们观察到OC-NN目标的子问题等同于解决定义明确的分位数选择问题。
缺点:
1.对于高维输入数据,训练时间和模型更新时间可能会更长。
2.由于输入空间的变化,模型更新也将花费更长的时间。
10.5 Unsupervised Deep Anomaly Detection
模型假设:
1.可以将原始或潜在特征空间中的“正常”区域与原始或潜在特征空间中的“异常”区域区分开。
2.与其余数据集相比,大多数数据实例是正常的。
3.无监督的异常检测算法会根据数据集的固有属性(例如距离或密度)产生数据实例的异常值。 深层神经网络的隐藏层旨在捕获数据集内的这些内在属性(Goldstein和Uchida [2016])。
优点:
1.了解固有的数据特征,以将法线与异常数据点分开。 此技术可识别数据中的共性并有助于异常检测。(但如何保证学习到的特征是正常数据独有的而不是异常数据也有的呢?)
2.寻找异常的经济有效的技术,因为它不需要用于训练算法的注释数据。
缺点:
1.在复杂的高维空间中,学习数据内的共性通常是具有挑战性的。
2.在使用自动编码器时,选择正确的压缩度,即降维通常是一个超参数,需要调整以获得最佳结果。
3.无监督技术对噪声和数据损坏非常敏感,通常不如监督或半监督技术准确
后记
后面还有一些具体模型的简单介绍,感觉不是很有用就不看了。后续就是要找具体的文章看一看了。但毕竟做研究和做工程还是有很大区别的,文章的方法只提供思路和借鉴。希望工作后的第一个项目可以有一个不错的结果吧!