Apache Kafka --- A high-throughput distributed messaging system.
Why we built this
Kafka is a messaging system that was originally developed at LinkedIn to serve as the foundation for LinkedIn's activity stream and operational data processing pipeline. It is now used at a variety of different companies for various data pipeline and messaging uses.
Activity stream data is a normal part of any website for reporting on usage of the site. Activity data is things like page views, information about what content was shown, searches, etc. This kind of thing is usually handled by logging the activity out to some kind of file and then periodically aggregating these files for analysis. Operational data is data about the performance of servers (CPU, IO usage, request times, service logs, etc) and a variety of different approaches to aggregating operational data are used.
In recent years, activity and operational data has become a critical part of the production features of websites, and a slightly more sophisticated set of infrastructure is needed.
Use cases for activity stream and operational data
- "News feed" features that broadcast the activity of your friends.
- Relevance and ranking uses count ratings, votes, or click-through to determine which of a given set of items is most relevant.
- Security: Sites need to block abusive crawlers, rate-limit apis, detect spamming attempts, and maintain other detection and prevention systems that key off site activity.
- Operational monitoring: Most sites needs some kind of real-time, heads-up monitoring that can track performance and trigger alerts if something goes wrong.
- Reporting and Batch processing: It is common to load data into a data warehouse or Hadoop system for offline analysis and reporting on business activity
Characteristics of activity stream data
This high-throughput stream of immutable activity data represents a real computational challenge as the volume may easily be 10x or 100x larger than the next largest data source on a site.
Traditional log file aggregation is a respectable and scalable approach to supporting offline use cases like reporting or batch processing; but is too high latency for real-time processing and tends to have rather high operational complexity. On the other hand, existing messaging and queuing systems are okay for real-time and near-real-time use-cases, but handle large unconsumed queues very poorly often treating persistence as an after thought. This creates problems for feeding the data to offline systems like Hadoop that may only consume some sources once per hour or per day. Kafka is intended to be a single queuing platform that can support both offline and online use cases.
Kafka supports fairly general messaging semantics. Nothing ties it to activity processing, though that was our motivating use case.
Deployment
The following diagram gives a simplified view of the deployment topology at LinkedIn.
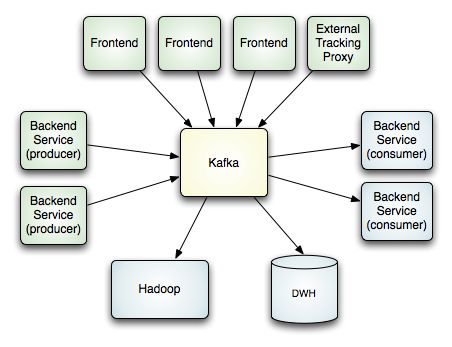
Note that a single kafka cluster handles all activity data from all different sources. This provides a single pipeline of data for both online and offline consumers. This tier acts as a buffer between live activity and asynchronous processing. We also use kafka to replicate all data to a different datacenter for offline consumption.
It is not intended that a single Kafka cluster span data centers, but Kafka is intended to support multi-datacenter data flow topologies. This is done by allowing mirroring or "syncing" between clusters. This feature is very simple, the mirror cluster simply acts as a consumer of the source cluster. This means it is possible for a single cluster to join data from many datacenters into a single location. Here is an example of a possible multi-datacenter topology aimed at supporting batch loads:
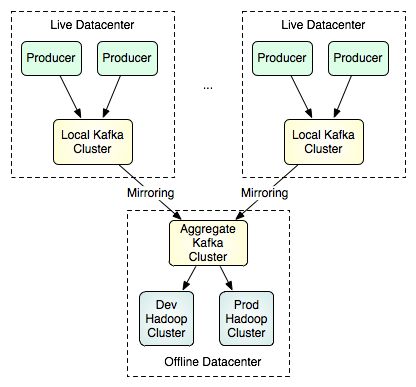
Note that there is no correspondence between nodes in the two clusters—they may be of different sizes, contain different number of nodes, and a single cluster can mirror any number of source clusters. More details on using the mirroring feature can be found here.
Major Design Elements
There is a small number of major design decisions that make Kafka different from most other messaging systems:
- Kafka is designed for persistent messages as the common case
- Throughput rather than features are the primary design constraint
- State about what has been consumed is maintained as part of the consumer not the server
- Kafka is explicitly distributed. It is assumed that producers, brokers, and consumers are all spread over multiple machines.
Each of these decisions will be discussed in more detail below.
Basics
First some basic terminology and concepts.
Messages are the fundamental unit of communication. Messages are published to a topic by a producer which means they are physically sent to a server acting as a broker (probably another machine). Some number ofconsumers subscribe to a topic, and each published message is delivered to all the consumers.
Kafka is explicitly distributed—producers, consumers, and brokers can all be run on a cluster of machines that co-operate as a logical group. This happens fairly naturally for brokers and producers, but consumers require some particular support. Each consumer process belongs to a consumer group and each message is delivered to exactly one process within every consumer group. Hence a consumer group allows many processes or machines to logically act as a single consumer. The concept of consumer group is very powerful and can be used to support the semantics of either a queue or topic as found in JMS. To support queuesemantics, we can put all consumers in a single consumer group, in which case each message will go to a single consumer. To support topic semantics, each consumer is put in its own consumer group, and then all consumers will receive each message. A more common case in our own usage is that we have multiple logical consumer groups, each consisting of a cluster of consuming machines that act as a logical whole. Kafka has the added benefit in the case of large data that no matter how many consumers a topic has, a message is stored only a single time.
Message Persistence and Caching
Don't fear the filesystem!
Kafka relies heavily on the filesystem for storing and caching messages. There is a general perception that "disks are slow" which makes people skeptical that a persistent structure can offer competitive performance. In fact disks are both much slower and much faster than people expect depending on how they are used; and a properly designed disk structure can often be as fast as the network.
The key fact about disk performance is that the throughput of hard drives has been diverging from the latency of a disk seek for the last decade. As a result the performance of linear writes on a 6 7200rpm SATA RAID-5 array is about 300MB/sec but the performance of random writes is only about 50k/sec—a difference of nearly 10000X. These linear reads and writes are the most predictable of all usage patterns, and hence the one detected and optimized best by the operating system using read-ahead and write-behind techniques that prefetch data in large block multiples and group smaller logical writes into large physical writes. A further discussion of this issue can be found in this ACM Queue article; they actually find that sequential disk access can in some cases be faster than random memory access!
To compensate for this performance divergence modern operating systems have become increasingly aggressive in their use of main memory for disk caching. Any modern OS will happily divert all free memory to disk caching with little performance penalty when the memory is reclaimed. All disk reads and writes will go through this unified cache. This feature cannot easily be turned off without using direct I/O, so even if a process maintains an in-process cache of the data, this data will likely be duplicated in OS pagecache, effectively storing everything twice.
Furthermore we are building on top of the JVM, and anyone who has spent any time with Java memory usage knows two things:
- The memory overhead of objects is very high, often doubling the size of the data stored (or worse).
- Java garbage collection becomes increasingly sketchy and expensive as the in-heap data increases.
As a result of these factors using the filesystem and relying on pagecache is superior to maintaining an in-memory cache or other structure—we at least double the available cache by having automatic access to all free memory, and likely double again by storing a compact byte structure rather than individual objects. Doing so will result in a cache of up to 28-30GB on a 32GB machine without GC penalties. Furthermore this cache will stay warm even if the service is restarted, whereas the in-process cache will need to be rebuilt in memory (which for a 10GB cache may take 10 minutes) or else it will need to start with a completely cold cache (which likely means terrible initial performance). It also greatly simplifies the code as all logic for maintaining coherency between the cache and filesystem is now in the OS, which tends to do so more efficiently and more correctly than one-off in-process attempts. If your disk usage favors linear reads then read-ahead is effectively pre-populating this cache with useful data on each disk read.
This suggests a design which is very simple: rather than maintain as much as possible in-memory and flush to the filesystem only when necessary, we invert that. All data is immediately written to a persistent log on the filesystem without any call to flush the data. In effect this just means that it is transferred into the kernel's pagecache where the OS can flush it later. Then we add a configuration driven flush policy to allow the user of the system to control how often data is flushed to the physical disk (every N messages or every M seconds) to put a bound on the amount of data "at risk" in the event of a hard crash.
This style of pagecache-centric design is described in an article on the design of Varnish here (along with a healthy helping of arrogance).
Constant Time Suffices
The persistent data structure used in messaging systems metadata is often a BTree. BTrees are the most versatile data structure available, and make it possible to support a wide variety of transactional and non-transactional semantics in the messaging system. They do come with a fairly high cost, though: Btree operations are O(log N). Normally O(log N) is considered essentially equivalent to constant time, but this is not true for disk operations. Disk seeks come at 10 ms a pop, and each disk can do only one seek at a time so parallelism is limited. Hence even a handful of disk seeks leads to very high overhead. Since storage systems mix very fast cached operations with actual physical disk operations, the observed performance of tree structures is often superlinear. Furthermore BTrees require a very sophisticated page or row locking implementation to avoid locking the entire tree on each operation. The implementation must pay a fairly high price for row-locking or else effectively serialize all reads. Because of the heavy reliance on disk seeks it is not possible to effectively take advantage of the improvements in drive density, and one is forced to use small (< 100GB) high RPM SAS drives to maintain a sane ratio of data to seek capacity.
Intuitively a persistent queue could be built on simple reads and appends to files as is commonly the case with logging solutions. Though this structure would not support the rich semantics of a BTree implementation, but it has the advantage that all operations are O(1) and reads do not block writes or each other. This has obvious performance advantages since the performance is completely decoupled from the data size--one server can now take full advantage of a number of cheap, low-rotational speed 1+TB SATA drives. Though they have poor seek performance, these drives often have comparable performance for large reads and writes at 1/3 the price and 3x the capacity.
Having access to virtually unlimited disk space without penalty means that we can provide some features not usually found in a messaging system. For example, in kafka, instead of deleting a message immediately after consumption, we can retain messages for a relative long period (say a week).
Maximizing Efficiency
Our assumption is that the volume of messages is extremely high, indeed it is some multiple of the total number of page views for the site (since a page view is one of the activities we process). Furthermore we assume each message published is read at least once (and often multiple times), hence we optimize for consumption rather than production.
There are two common causes of inefficiency: two many network requests, and excessive byte copying.
To encourage efficiency, the APIs are built around a "message set" abstraction that naturally groups messages. This allows network requests to group messages together and amortize the overhead of the network roundtrip rather than sending a single message at a time.
The MessageSet implementation is itself a very thin API that wraps a byte array or file. Hence there is no separate serialization or deserialization step required for message processing, message fields are lazily deserialized as needed (or not deserialized if not needed).
The message log maintained by the broker is itself just a directory of message sets that have been written to disk. This abstraction allows a single byte format to be shared by both the broker and the consumer (and to some degree the producer, though producer messages are checksumed and validated before being added to the log).
Maintaining this common format allows optimization of the most important operation: network transfer of persistent log chunks. Modern unix operating systems offer a highly optimized code path for transferring data out of pagecache to a socket; in Linux this is done with the sendfile system call. Java provides access to this system call with the FileChannel.transferTo api.
To understand the impact of sendfile, it is important to understand the common data path for transfer of data from file to socket:
- The operating system reads data from the disk into pagecache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
This is clearly inefficient, there are four copies, two system calls. Using sendfile, this re-copying is avoided by allowing the OS to send the data from pagecache to the network directly. So in this optimized path, only the final copy to the NIC buffer is needed.
We expect a common use case to be multiple consumers on a topic. Using the zero-copy optimization above, data is copied into pagecache exactly once and reused on each consumption instead of being stored in memory and copied out to kernel space every time it is read. This allows messages to be consumed at a rate that approaches the limit of the network connection.
For more background on the sendfile and zero-copy support in Java, see this article on IBM developerworks.
End-to-end Batch Compression
In many cases the bottleneck is actually not CPU but network. This is particularly true for a data pipeline that needs to send messages across data centers. Of course the user can always send compressed messages without any support needed from Kafka, but this can lead to very poor compression ratios as much of the redundancy is due to repetition between messages (e.g. field names in JSON or user agents in web logs or common string values). Efficient compression requires compressing multiple messages together rather than compressing each message individually. Ideally this would be possible in an end-to-end fashion—that is, data would be compressed prior to sending by the producer and remain compressed on the server, only being decompressed by the eventual consumers.
Kafka supports this be allowing recursive message sets. A batch of messages can be clumped together compressed and sent to the server in this form. This batch of messages will be delivered all to the same consumer and will remain in compressed form until it arrives there.
Kafka supports GZIP and Snappy compression protocols. More details on compression can be found here.
Consumer state
Keeping track of what has been consumed is one of the key things a messaging system must provide. It is not intuitive, but recording this state is one of the key performance points for the system. State tracking requires updating a persistent entity and potentially causes random accesses. Hence it is likely to be bound by the seek time of the storage system not the write bandwidth (as described above).
Most messaging systems keep metadata about what messages have been consumed on the broker. That is, as a message is handed out to a consumer, the broker records that fact locally. This is a fairly intuitive choice, and indeed for a single machine server it is not clear where else it could go. Since the data structure used for storage in many messaging systems scale poorly, this is also a pragmatic choice--since the broker knows what is consumed it can immediately delete it, keeping the data size small.
What is perhaps not obvious, is that getting the broker and consumer to come into agreement about what has been consumed is not a trivial problem. If the broker records a message as consumed immediately every time it is handed out over the network, then if the consumer fails to process the message (say because it crashes or the request times out or whatever) then that message will be lost. To solve this problem, many messaging systems add an acknowledgement feature which means that messages are only marked as sentnot consumed when they are sent; the broker waits for a specific acknowledgement from the consumer to record the message as consumed. This strategy fixes the problem of losing messages, but creates new problems. First of all, if the consumer processes the message but fails before it can send an acknowledgement then the message will be consumed twice. The second problem is around performance, now the broker must keep multiple states about every single message (first to lock it so it is not given out a second time, and then to mark it as permanently consumed so that it can be removed). Tricky problems must be dealt with, like what to do with messages that are sent but never acknowledged.
Message delivery semantics
So clearly there are multiple possible message delivery guarantees that could be provided:
- At most once—this handles the first case described. Messages are immediately marked as consumed, so they can't be given out twice, but many failure scenarios may lead to losing messages.
- At least once—this is the second case where we guarantee each message will be delivered at least once, but in failure cases may be delivered twice.
- Exactly once—this is what people actually want, each message is delivered once and only once.
This problem is heavily studied, and is a variation of the "transaction commit" problem. Algorithms that provide exactly once semantics exist, two- or three-phase commits and Paxos variants being examples, but they come with some drawbacks. They typically require multiple round trips and may have poor guarantees of liveness (they can halt indefinitely). The FLP result provides some of the fundamental limitations on these algorithms.
Kafka does two unusual things with respect to metadata. First the stream is partitioned on the brokers into a set of distinct partitions. The semantic meaning of these partitions is left up to the producer and the producer specifies which partition a message belongs to. Within a partition messages are stored in the order in which they arrive at the broker, and will be given out to consumers in that same order. This means that rather than store metadata for each message (marking it as consumed, say), we just need to store the "high water mark" for each combination of consumer, topic, and partition. Hence the total metadata required to summarize the state of the consumer is actually quite small. In Kafka we refer to this high-water mark as "the offset" for reasons that will become clear in the implementation section.
Consumer state
In Kafka, the consumers are responsible for maintaining state information (offset) on what has been consumed. Typically, the Kafka consumer library writes their state data to zookeeper. However, it may be beneficial for consumers to write state data into the same datastore where they are writing the results of their processing. For example, the consumer may simply be entering some aggregate value into a centralized transactional OLTP database. In this case the consumer can store the state of what is consumed in the same transaction as the database modification. This solves a distributed consensus problem, by removing the distributed part! A similar trick works for some non-transactional systems as well. A search system can store its consumer state with its index segments. Though it may provide no durability guarantees, this means that the index is always in sync with the consumer state: if an unflushed index segment is lost in a crash, the indexes can always resume consumption from the latest checkpointed offset. Likewise our Hadoop load job which does parallel loads from Kafka, does a similar trick. Individual mappers write the offset of the last consumed message to HDFS at the end of the map task. If a job fails and gets restarted, each mapper simply restarts from the offsets stored in HDFS.
There is a side benefit of this decision. A consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but turns out to be an essential feature for many consumers. For example, if the consumer code has a bug and is discovered after some messages are consumed, the consumer can re-consume those messages once the bug is fixed.
Push vs. pull
A related question is whether consumers should pull data from brokers or brokers should push data to the subscriber. In this respect Kafka follows a more traditional design, shared by most messaging systems, where data is pushed to the broker from the producer and pulled from the broker by the consumer. Some recent systems, such as scribe and flume, focusing on log aggregation, follow a very different push based path where each node acts as a broker and data is pushed downstream. There are pros and cons to both approaches. However a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal, is generally for the consumer to be able to consume at the maximum possible rate; unfortunately in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems. Previous attempts at building systems in this fashion led us to go with a more traditional pull model.
Distribution
Kafka is built to be run across a cluster of machines as the common case. There is no central "master" node. Brokers are peers to each other and can be added and removed at anytime without any manual configuration changes. Similarly, producers and consumers can be started dynamically at any time. Each broker registers some metadata (e.g., available topics) in Zookeeper. Producers and consumers can use Zookeeper to discover topics and to co-ordinate the production and consumption. The details of producers and consumers will be described below.
Producer
Automatic producer load balancing
Kafka supports client-side load balancing for message producers or use of a dedicated load balancer to balance TCP connections. A dedicated layer-4 load balancer works by balancing TCP connections over Kafka brokers. In this configuration all messages from a given producer go to a single broker. The advantage of using a level-4 load balancer is that each producer only needs a single TCP connection, and no connection to zookeeper is needed. The disadvantage is that the balancing is done at the TCP connection level, and hence it may not be well balanced (if some producers produce many more messages then others, evenly dividing up the connections per broker may not result in evenly dividing up the messages per broker).
Client-side zookeeper-based load balancing solves some of these problems. It allows the producer to dynamically discover new brokers, and balance load on a per-request basis. Likewise it allows the producer to partition data according to some key instead of randomly, which enables stickiness on the consumer (e.g. partitioning data consumption by user id). This feature is called "semantic partitioning", and is described in more detail below.
The working of the zookeeper-based load balancing is described below. Zookeeper watchers are registered on the following events—
- a new broker comes up
- a broker goes down
- a new topic is registered
- a broker gets registered for an existing topic
Internally, the producer maintains an elastic pool of connections to the brokers, one per broker. This pool is kept updated to establish/maintain connections to all the live brokers, through the zookeeper watcher callbacks. When a producer request for a particular topic comes in, a broker partition is picked by the partitioner (see section on semantic partitioning). The available producer connection is used from the pool to send the data to the selected broker partition.
Asynchronous send
Asynchronous non-blocking operations are fundamental to scaling messaging systems. In Kafka, the producer provides an option to use asynchronous dispatch of produce requests (producer.type=async). This allows buffering of produce requests in a in-memory queue and batch sends that are triggered by a time interval or a pre-configured batch size. Since data is typically published from set of heterogenous machines producing data at variable rates, this asynchronous buffering helps generate uniform traffic to the brokers, leading to better network utilization and higher throughput.
Semantic partitioning
Consider an application that would like to maintain an aggregation of the number of profile visitors for each member. It would like to send all profile visit events for a member to a particular partition and, hence, have all updates for a member to appear in the same stream for the same consumer thread. The producer has the capability to be able to semantically map messages to the available kafka nodes and partitions. This allows partitioning the stream of messages with some semantic partition function based on some key in the message to spread them over broker machines. The partitioning function can be customized by providing an implementation of the kafka.producer.Partitioner interface, default being the random partitioner. For the example above, the key would be member_id and the partitioning function would be hash(member_id)%num_partitions.
Support for Hadoop and other batch data load
Scalable persistence allows for the possibility of supporting batch data loads that periodically snapshot data into an offline system for batch processing. We make use of this for loading data into our data warehouse and Hadoop clusters.
Batch processing happens in stages beginning with the data load stage and proceeding in an acyclic graph of processing and output stages (e.g. as supported here). An essential feature of support for this model is the ability to re-run the data load from a point in time (in case anything goes wrong).
In the case of Hadoop we parallelize the data load by splitting the load over individual map tasks, one for each node/topic/partition combination, allowing full parallelism in the loading. Hadoop provides the task management, and tasks which fail can restart without danger of duplicate data.
Implementation Details
The following gives a brief description of some relevant lower-level implementation details for some parts of the system described in the above section.
API Design
Producer APIs
The Producer API that wraps the 2 low-level producers - kafka.producer.SyncProducer andkafka.producer.async.AsyncProducer.
class Producer {
/* Sends the data, partitioned by key to the topic using either the */
/* synchronous or the asynchronous producer */
public void send(kafka.javaapi.producer.ProducerData producerData);
/* Sends a list of data, partitioned by key to the topic using either */
/* the synchronous or the asynchronous producer */
public void send(java.util.List< kafka.javaapi.producer.ProducerData> producerData);
/* Closes the producer and cleans up */
public void close();
}
The goal is to expose all the producer functionality through a single API to the client. The new producer -
- can handle queueing/buffering of multiple producer requests and asynchronous dispatch of the batched data -
kafka.producer.Producerprovides the ability to batch multiple produce requests (producer.type=async), before serializing and dispatching them to the appropriate kafka broker partition. The size of the batch can be controlled by a few config parameters. As events enter a queue, they are buffered in a queue, until eitherqueue.timeorbatch.sizeis reached. A background thread (kafka.producer.async.ProducerSendThread) dequeues the batch of data and lets thekafka.producer.EventHandlerserialize and send the data to the appropriate kafka broker partition. A custom event handler can be plugged in through theevent.handlerconfig parameter. At various stages of this producer queue pipeline, it is helpful to be able to inject callbacks, either for plugging in custom logging/tracing code or custom monitoring logic. This is possible by implementing thekafka.producer.async.CallbackHandlerinterface and settingcallback.handlerconfig parameter to that class. - handles the serialization of data through a user-specified
Encoder-interface Encoder
{ public Message toMessage(T data); } The default is the no-op
kafka.serializer.DefaultEncoder - provides zookeeper based automatic broker discovery -
The zookeeper based broker discovery and load balancing can be used by specifying the zookeeper connection url through the
zk.connectconfig parameter. For some applications, however, the dependence on zookeeper is inappropriate. In that case, the producer can take in a static list of brokers through thebroker.listconfig parameter. Each produce requests gets routed to a random broker partition in this case. If that broker is down, the produce request fails. - provides software load balancing through an optionally user-specified
Partitioner-The routing decision is influenced by the
kafka.producer.Partitioner.interface Partitioner
The partition API uses the key and the number of available broker partitions to return a partition id. This id is used as an index into a sorted list of broker_ids and partitions to pick a broker partition for the producer request. The default partitioning strategy is{ int partition(T key, int numPartitions); } hash(key)%numPartitions. If the key is null, then a random broker partition is picked. A custom partitioning strategy can also be plugged in using thepartitioner.classconfig parameter.
Consumer APIs
We have 2 levels of consumer APIs. The low-level "simple" API maintains a connection to a single broker and has a close correspondence to the network requests sent to the server. This API is completely stateless, with the offset being passed in on every request, allowing the user to maintain this metadata however they choose.
The high-level API hides the details of brokers from the consumer and allows consuming off the cluster of machines without concern for the underlying topology. It also maintains the state of what has been consumed. The high-level API also provides the ability to subscribe to topics that match a filter expression (i.e., either a whitelist or a blacklist regular expression).
Low-level API
class SimpleConsumer {
/* Send fetch request to a broker and get back a set of messages. */
public ByteBufferMessageSet fetch(FetchRequest request);
/* Send a list of fetch requests to a broker and get back a response set. */
public MultiFetchResponse multifetch(List fetches);
/**
* Get a list of valid offsets (up to maxSize) before the given time.
* The result is a list of offsets, in descending order.
* @param time: time in millisecs,
* if set to OffsetRequest$.MODULE$.LATIEST_TIME(), get from the latest offset available.
* if set to OffsetRequest$.MODULE$.EARLIEST_TIME(), get from the earliest offset available.
*/
public long[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets);
}
The low-level API is used to implement the high-level API as well as being used directly for some of our offline consumers (such as the hadoop consumer) which have particular requirements around maintaining state.
High-level API
/* create a connection to the cluster */
ConsumerConnector connector = Consumer.create(consumerConfig);
interface ConsumerConnector {
/**
* This method is used to get a list of KafkaStreams, which are iterators over
* MessageAndMetadata objects from which you can obtain messages and their
* associated metadata (currently only topic).
* Input: a map of
* Output: a map of
*/
public Map> createMessageStreams(Map topicCountMap);
/**
* You can also obtain a list of KafkaStreams, that iterate over messages
* from topics that match a TopicFilter. (A TopicFilter encapsulates a
* whitelist or a blacklist which is a standard Java regex.)
*/
public List createMessageStreamsByFilter(
TopicFilter topicFilter, int numStreams);
/* Commit the offsets of all messages consumed so far. */
public commitOffsets()
/* Shut down the connector */
public shutdown()
}
This API is centered around iterators, implemented by the KafkaStream class. Each KafkaStream represents the stream of messages from one or more partitions on one or more servers. Each stream is used for single threaded processing, so the client can provide the number of desired streams in the create call. Thus a stream may represent the merging of multiple server partitions (to correspond to the number of processing threads), but each partition only goes to one stream.
The createMessageStreams call registers the consumer for the topic, which results in rebalancing the consumer/broker assignment. The API encourages creating many topic streams in a single call in order to minimize this rebalancing. The createMessageStreamsByFilter call (additionally) registers watchers to discover new topics that match its filter. Note that each stream that createMessageStreamsByFilter returns may iterate over messages from multiple topics (i.e., if multiple topics are allowed by the filter).
Network Layer
The network layer is a fairly straight-forward NIO server, and will not be described in great detail. The sendfile implementation is done by giving the MessageSet interface a writeTo method. This allows the file-backed message set to use the more efficient transferTo implementation instead of an in-process buffered write. The threading model is a single acceptor thread and N processor threads which handle a fixed number of connections each. This design has been pretty thoroughly tested elsewhere and found to be simple to implement and fast. The protocol is kept quite simple to allow for future the implementation of clients in other languages.
Messages
Messages consist of a fixed-size header and variable length opaque byte array payload. The header contains a format version and a CRC32 checksum to detect corruption or truncation. Leaving the payload opaque is the right decision: there is a great deal of progress being made on serialization libraries right now, and any particular choice is unlikely to be right for all uses. Needless to say a particular application using Kafka would likely mandate a particular serialization type as part of its usage. The MessageSet interface is simply an iterator over messages with specialized methods for bulk reading and writing to an NIO Channel.
Message Format
/** * A message. The format of an N byte message is the following: * * If magic byte is 0 * * 1. 1 byte "magic" identifier to allow format changes * * 2. 4 byte CRC32 of the payload * * 3. N - 5 byte payload * * If magic byte is 1 * * 1. 1 byte "magic" identifier to allow format changes * * 2. 1 byte "attributes" identifier to allow annotations on the message independent of the version (e.g. compression enabled, type of codec used) * * 3. 4 byte CRC32 of the payload * * 4. N - 6 byte payload * */
Log
A log for a topic named "my_topic" with two partitions consists of two directories (namely my_topic_0 andmy_topic_1) populated with data files containing the messages for that topic. The format of the log files is a sequence of "log entries""; each log entry is a 4 byte integer N storing the message length which is followed by the N message bytes. Each message is uniquely identified by a 64-bit integer offset giving the byte position of the start of this message in the stream of all messages ever sent to that topic on that partition. The on-disk format of each message is given below. Each log file is named with the offset of the first message it contains. So the first file created will be 00000000000.kafka, and each additional file will have an integer name roughlyS bytes from the previous file where S is the max log file size given in the configuration.
The exact binary format for messages is versioned and maintained as a standard interface so message sets can be transfered between producer, broker, and client without recopying or conversion when desirable. This format is as follows:
On-disk format of a message message length : 4 bytes (value: 1+4+n) "magic" value : 1 byte crc : 4 bytes payload : n bytes
The use of the message offset as the message id is unusual. Our original idea was to use a GUID generated by the producer, and maintain a mapping from GUID to offset on each broker. But since a consumer must maintain an ID for each server, the global uniqueness of the GUID provides no value. Furthermore the complexity of maintaining the mapping from a random id to an offset requires a heavy weight index structure which must be synchronized with disk, essentially requiring a full persistent random-access data structure. Thus to simplify the lookup structure we decided to use a simple per-partition atomic counter which could be coupled with the partition id and node id to uniquely identify a message; this makes the lookup structure simpler, though multiple seeks per consumer request are still likely. However once we settled on a counter, the jump to directly using the offset seemed natural—both after all are monotonically increasing integers unique to a partition. Since the offset is hidden from the consumer API this decision is ultimately an implementation detail and we went with the more efficient approach.
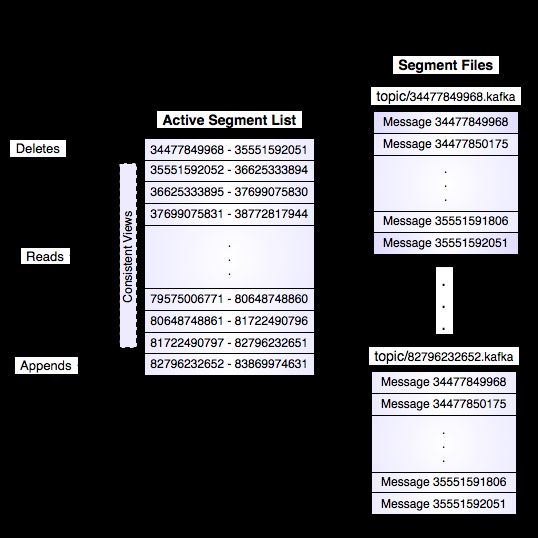
Writes
The log allows serial appends which always go to the last file. This file is rolled over to a fresh file when it reaches a configurable size (say 1GB). The log takes two configuration parameter M which gives the number of messages to write before forcing the OS to flush the file to disk, and S which gives a number of seconds after which a flush is forced. This gives a durability guarantee of losing at most M messages or S seconds of data in the event of a system crash.
Reads
Reads are done by giving the 64-bit logical offset of a message and an S-byte max chunk size. This will return an iterator over the messages contained in the S-byte buffer. S is intended to be larger than any single message, but in the event of an abnormally large message, the read can be retried multiple times, each time doubling the buffer size, until the message is read successfully. A maximum message and buffer size can be specified to make the server reject messages larger than some size, and to give a bound to the client on the maximum it need ever read to get a complete message. It is likely that the read buffer ends with a partial message, this is easily detected by the size delimiting.
The actual process of reading from an offset requires first locating the log segment file in which the data is stored, calculating the file-specific offset from the global offset value, and then reading from that file offset. The search is done as a simple binary search variation against an in-memory range maintained for each file.
The log provides the capability of getting the most recently written message to allow clients to start subscribing as of "right now". This is also useful in the case the consumer fails to consume its data within its SLA-specified number of days. In this case when the client attempts to consume a non-existant offset it is given an OutOfRangeException and can either reset itself or fail as appropriate to the use case.
The following is the format of the results sent to the consumer.
MessageSetSend (fetch result) total length : 4 bytes error code : 2 bytes message 1 : x bytes ... message n : x bytes
MultiMessageSetSend (multiFetch result) total length : 4 bytes error code : 2 bytes messageSetSend 1 ... messageSetSend n
Deletes
Data is deleted one log segment at a time. The log manager allows pluggable delete policies to choose which files are eligible for deletion. The current policy deletes any log with a modification time of more than N days ago, though a policy which retained the last N GB could also be useful. To avoid locking reads while still allowing deletes that modify the segment list we use a copy-on-write style segment list implementation that provides consistent views to allow a binary search to proceed on an immutable static snapshot view of the log segments while deletes are progressing.
Guarantees
The log provides a configuration parameter M which controls the maximum number of messages that are written before forcing a flush to disk. On startup a log recovery process is run that iterates over all messages in the newest log segment and verifies that each message entry is valid. A message entry is valid if the sum of its size and offset are less than the length of the file AND the CRC32 of the message payload matches the CRC stored with the message. In the event corruption is detected the log is truncated to the last valid offset.
Note that two kinds of corruption must be handled: truncation in which an unwritten block is lost due to a crash, and corruption in which a nonsense block is ADDED to the file. The reason for this is that in general the OS makes no guarantee of the write order between the file inode and the actual block data so in addition to losing written data the file can gain nonsense data if the inode is updated with a new size but a crash occurs before the block containing that data is not written. The CRC detects this corner case, and prevents it from corrupting the log (though the unwritten messages are, of course, lost).
Distribution
Zookeeper Directories
The following gives the zookeeper structures and algorithms used for co-ordination between consumers and brokers.
Notation
When an element in a path is denoted [xyz], that means that the value of xyz is not fixed and there is in fact a zookeeper znode for each possible value of xyz. For example /topics/[topic] would be a directory named /topics containing a sub-directory for each topic name. Numerical ranges are also given such as [0...5] to indicate the subdirectories 0, 1, 2, 3, 4. An arrow -> is used to indicate the contents of a znode. For example /hello -> world would indicate a znode /hello containing the value "world".
Broker Node Registry
/brokers/ids/[0...N] --> host:port (ephemeral node)
This is a list of all present broker nodes, each of which provides a unique logical broker id which identifies it to consumers (which must be given as part of its configuration). On startup, a broker node registers itself by creating a znode with the logical broker id under /brokers/ids. The purpose of the logical broker id is to allow a broker to be moved to a different physical machine without affecting consumers. An attempt to register a broker id that is already in use (say because two servers are configured with the same broker id) is an error.
Since the broker registers itself in zookeeper using ephemeral znodes, this registration is dynamic and will disappear if the broker is shutdown or dies (thus notifying consumers it is no longer available).
Broker Topic Registry
/brokers/topics/[topic]/[0...N] --> nPartions (ephemeral node)
Each broker registers itself under the topics it maintains and stores the number of partitions for that topic.
Consumers and Consumer Groups
Consumers of topics also register themselves in Zookeeper, in order to balance the consumption of data and track their offsets in each partition for each broker they consume from.
Multiple consumers can form a group and jointly consume a single topic. Each consumer in the same group is given a shared group_id. For example if one consumer is your foobar process, which is run across three machines, then you might assign this group of consumers the id "foobar". This group id is provided in the configuration of the consumer, and is your way to tell the consumer which group it belongs to.
The consumers in a group divide up the partitions as fairly as possible, each partition is consumed by exactly one consumer in a consumer group.
Consumer Id Registry
In addition to the group_id which is shared by all consumers in a group, each consumer is given a transient, unique consumer_id (of the form hostname:uuid) for identification purposes. Consumer ids are registered in the following directory.
/consumers/[group_id]/ids/[consumer_id] --> {"topic1": #streams, ..., "topicN": #streams} (ephemeral node)
Each of the consumers in the group registers under its group and creates a znode with its consumer_id. The value of the znode contains a map of
Consumer Offset Tracking
Consumers track the maximum offset they have consumed in each partition. This value is stored in a zookeeper directory
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id] --> offset_counter_value ((persistent node)
Partition Owner registry
Each broker partition is consumed by a single consumer within a given consumer group. The consumer must establish its ownership of a given partition before any consumption can begin. To establish its ownership, a consumer writes its own id in an ephemeral node under the particular broker partition it is claiming.
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id] --> consumer_node_id (ephemeral node)
Broker node registration
The broker nodes are basically independent, so they only publish information about what they have. When a broker joins, it registers itself under the broker node registry directory and writes information about its host name and port. The broker also register the list of existing topics and their logical partitions in the broker topic registry. New topics are registered dynamically when they are created on the broker.
Consumer registration algorithm
When a consumer starts, it does the following:
- Register itself in the consumer id registry under its group.
- Register a watch on changes (new consumers joining or any existing consumers leaving) under the consumer id registry. (Each change triggers rebalancing among all consumers within the group to which the changed consumer belongs.)
- Register a watch on changes (new brokers joining or any existing brokers leaving) under the broker id registry. (Each change triggers rebalancing among all consumers in all consumer groups.)
- If the consumer creates a message stream using a topic filter, it also registers a watch on changes (new topics being added) under the broker topic registry. (Each change will trigger re-evaluation of the available topics to determine which topics are allowed by the topic filter. A new allowed topic will trigger rebalancing among all consumers within the consumer group.)
- Force itself to rebalance within in its consumer group.
Consumer rebalancing algorithm
The consumer rebalancing algorithms allows all the consumers in a group to come into consensus on which consumer is consuming which partitions. Consumer rebalancing is triggered on each addition or removal of both broker nodes and other consumers within the same group. For a given topic and a given consumer group, broker partitions are divided evenly among consumers within the group. A partition is always consumed by a single consumer. This design simplifies the implementation. Had we allowed a partition to be concurrently consumed by multiple consumers, there would be contention on the partition and some kind of locking would be required. If there are more consumers than partitions, some consumers won't get any data at all. During rebalancing, we try to assign partitions to consumers in such a way that reduces the number of broker nodes each consumer has to connect to.
Each consumer does the following during rebalancing:
1. For each topic T that Ci subscribes to
2. let PT be all partitions producing topic T
3. let CG be all consumers in the same group as Ci that consume topic T
4. sort PT (so partitions on the same broker are clustered together)
5. sort CG
6. let i be the index position of Ci in CG and let N = size(PT)/size(CG)
7. assign partitions from i*N to (i+1)*N - 1 to consumer Ci
8. remove current entries owned by Ci from the partition owner registry
9. add newly assigned partitions to the partition owner registry
(we may need to re-try this until the original partition owner releases its ownership)
When rebalancing is triggered at one consumer, rebalancing should be triggered in other consumers within the same group about the same time.
Ref: http://kafka.apache.org/design.html