八大排序算法详解(1)---插入类排序和选择类排序
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。
各种排序的稳定性,时间复杂度、空间复杂度、稳定性总结如下图:
一、插入排序:
思想:每步将一个待排序的记录,按其顺序码大小插入到前面已经排序的子序列的合适位置,直到全部插入排序完为止。
关键问题:在前面已经排好序的序列中找到合适的插入位置。
方法:
- 直接插入排序
- 二分插入排序
- 希尔排序
1、直接插入排序
插入排序示意图
插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
/**
* 直接插入排序
* @param v
*/
public void insertSort(View v) {
for (int i = 1; i < a.length; i++) {
// 待插入元素
int temp = a[i];
int j;
for (j = i - 1; j >= 0 && a[j] > temp; j--) {
// 将大于temp的往后移动一位
a[j + 1] = a[j];
}
a[j + 1] = temp;
}
}如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面。所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以插入排序是稳定的。
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
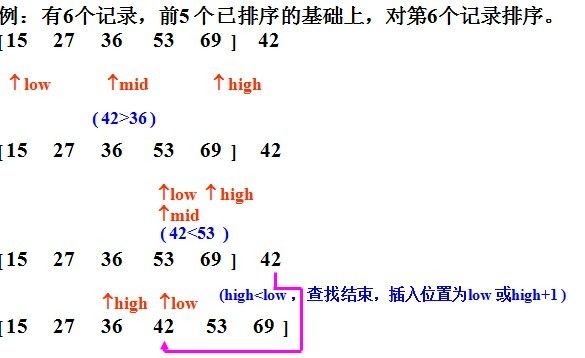
2、二分插入排序
二分法插入排序的思想和直接插入一样,只是找合适的插入位置的方式不同,这里是按二分法找到合适的位置,可以减少比较的次数。
public static void halfSort(int a[])
{
int start;
int end;
int temp=0;
int mid,j;
for(int i=1;i= start;j-- )
{
a[j+1] = a[j];
}
//将当前插入数字挪入它该待的坑位
a[start] = temp;
}
}
- 时间复杂度:O(nlog2n)
- 空间复杂度:O(1)
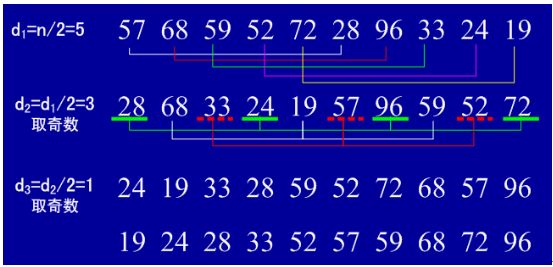
3、希尔排序
基本思想是:
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序。然后缩小间隔increment,重复上述子序列划分和排序工作。直到最后取increment=1,将所有元素放在同一个子序列中排序为止。
由于开始时,increment的取值较大,每个子序列中的元素较少,排序速度较快,到排序后期increment取值逐渐变小,子序列中元素个数逐渐增多,但由于前面工作的基础,大多数元素已经基本有序,所以排序速度仍然很快。
/**
* 希尔排序
* @param v
*/
public void shellSort(int a[]) {
int dk = a.length/2;
while(dk >= 1){
ShellInsertSort(a, dk);
dk = dk/2;
}
}
private void ShellInsertSort(int[] a, int dk) {
//类似插入排序,只是插入排序增量是1,这里增量是dk,把1换成dk就可以了
for (int i = dk; i < a.length; i++) {
// 待插入元素
int temp = a[i];
int j;
for (j = i - dk; j >= 0 && a[j] > temp; j = j-dk) {
// 将大于temp的往后移动dk位
a[j + dk] = a[j];
}
a[j + dk] = temp;
}
}希尔排序时效分析很难,关键码的比较次数与记录移动次数依赖于增量因子序列d的选取,特定情况下可以准确估算出关键码的比较次数和记录的移动次数。目前还没有人给出选取最好的增量因子序列的方法。增量因子序列可以有各种取法,有取奇数的,也有取质数的,但需要注意:增量因子中除1 外没有公因子,且最后一个增量因子必须为1。希尔排序方法是一个不稳定的排序方法。
- 时间复杂度:O(nlog2n)
- 空间复杂度:O(1)
二、选择排序
思想:每趟从待排序的记录序列中选择关键字最小的记录放置到已排序表的最前位置,直到全部排完。
关键问题:在剩余的待排序记录序列中找到最小关键码记录。
方法:
- 简单选择排序
- 二元选择排序
- 堆排序
1、简单选择排序
基本思想
在要排序的一组数中,选出最小的一个数与第一个位置的数交换;然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。

/**
* 简单选择排序
* @param v
*/
public void selectSort(int a[]) {
int min;
for(int i = 0; i < a.length; i++){
min = i;
for(int j = i + 1; j < a.length; j++){//找到最小值下标
if(a[j] < a[min]){
min = j;
}
}
swap(a, i, min);
}
}
/**
* 元素交换
* @param
*/
public void swap(int[] data, int i, int j) {
if (i == j) {
return;
}
data[i] = data[i] + data[j];
data[j] = data[i] - data[j];
data[i] = data[i] - data[j];
}- 时间复杂度:O(n2)
- 空间复杂度:O(1)
2、二元选择排序
基本思想
简单选择排序,每趟循环只能确定一个元素排序后的定位。我们可以考虑改进为每趟循环确定两个元素(当前趟最大和最小记录)的位置,从而减少排序所需的循环次数。改进后对n个数据进行排序,最多只需进行[n/2]趟循环即可。
/**
* 二元选择排序
* @param v
*/
public void twoSelectSort(int a[]) {
int min, max;
for(int i = 0; i < a.length/2; i++){
min = i; max = i; //分别记录最大和最小关键字记录位置
for(int j = i + 1; j< a.length - i; j++){
if (a[j] > a[max]) {
max = j;
continue;
}
if (a[j] < a[min]) {
min = j;
}
}
swap(a, i, min); //最小值放到前面
if (i == max) {
max = min;
//如果当前i就是max,第一次排序后max要调整为min(a[i]新的位置是a[min])
}
swap(a, a.length-1-i, max); //最大值放到后面
}
}- 时间复杂度:O(n2)
- 空间复杂度:O(1)
3、堆排序
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。
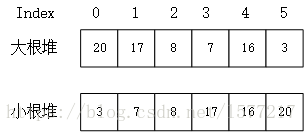
堆是具有以下性质的完全二叉树:
- 每个结点的值都大于或等于其左右孩子结点的值,称为大根堆;
- 或者每个结点的值都小于或等于其左右孩子结点的值,称为小根堆。如下图:

通过图可以比较直观的看出大根堆和小根堆的特点,需要注意的是:这种结构是对父节点-左/右孩子节点之间做的约束,而对左-右孩子节点之间并没有什么要求。
另外,因为堆的结构是完全二叉树,所以可以用数组来存储,并通过节点下标的规律快速进行索引。
下面是上图大根堆与小根堆对应的数组:
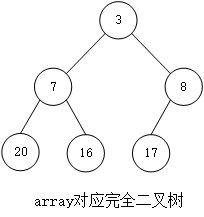
假设现在待排序数据存在array[count]中,其初始状态如下:
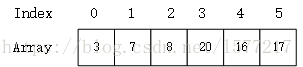
对应的完全二叉树为:
堆排序的过程如下:
(1)初始化堆;
因为堆是对父节点-左/右孩子节点之间的约束,所以从最后一个非叶子节点开始调整。

注意每次交换后,都要对下一层的子堆进行递归调整,因为交换后有可能破坏已调整子堆的结构。
(2)进行调整后,堆顶元素(array[0])为最大值,将最大值与堆尾部元素(array[count-1])交换,并将count值减去1,则此时得到新的无序数组array[count],此时的堆被破坏;

对应到数组元素为:
 (黄色标记为已排序部分)
(黄色标记为已排序部分)
(3)调整堆:与建堆过程类似,堆顶元素被一个比较小的值代替,所以从堆顶元素开始调整,在堆顶、堆顶的左孩子、堆顶的右孩子中找出最大的与堆顶进行交换,被交换的元素再次与他下一层的左右孩子进行比较(递归)调整。

(4)重复(2)。
下面把整个过程画完:

此时,大概的一个手工过程就懂了,注意的是:初始化堆是基础,时从下向上调整。交换后调整堆时因为有了建堆的基础,每次调整的都是二叉树的一支子树,是从上往下。
public class HeapSort {
public static void main(String[] args) {
int[] array = new int[]{12, 5, 9 , 36, 8, 21, 7};
System.out.println("初始状态:");
showArray(array);
initHeap(array); //这个应该也是堆排序的一部分,此处只是为了显示下结果
System.out.println("建堆之后:");
showArray(array);
heapSort(array);
System.out.println("排序之后:");
showArray(array);
}
public static void heapSort(int[] array){
initHeap(array); //建堆
int count = array.length;
while(count > 1) {
int tmp = array[count - 1];
array[count - 1] = array[0];
array[0] = tmp;
count--; //未排序部分又少一个
adjustHeap(array, count, 0);//调整过程自上而下,参数root=0
}
}
public static void initHeap(int[] array){
//建堆,从最后一个非叶子节点开始,而最后一个非叶子节点的下标为array.length/2-1
for(int root = array.length/2 - 1; root >= 0; root--){
adjustHeap(array, array.length, root);
}
}
public static void adjustHeap(int[] array, int count, int root){
int maxChildIndex;
while(root <= count/2-1) { //待调整子堆的根节点必须是非叶子节点
//需要在root、letfchild、rightchild中找到最大的值,
//因为最后一个非叶子节点有可能没有右孩子,所以要做出判断。
if(root == count/2 - 1 && count % 2 == 0){
//节点数量为偶数时,最后一个非叶子节点只有左孩子
maxChildIndex = 2 * root + 1;
}else{
int leftChildIndex = 2 * root + 1;
int rightChildIndex = 2 * root + 2;
maxChildIndex = array[leftChildIndex] > array[rightChildIndex] ?
leftChildIndex : rightChildIndex;
}
if(array[root] < array[maxChildIndex]){
int tmp = array[root];
array[root] = array[maxChildIndex];
array[maxChildIndex] = tmp;
//*****************这里很重要,继续调整因交换结构改变的子堆
root = maxChildIndex;
}else{
return;
}
}
}
public static void showArray(int[] array){
for(int i = 0; i < array.length; i++){
System.out.print(array[i] + ((i == array.length - 1) ? "\n" : " "));
}
}
}
输出结果:
初始状态:
12 5 9 36 8 21 7
建堆之后:
36 12 21 5 8 9 7
排序之后:
5 7 8 9 12 21 36- 时间复杂度:O(nlogn)
- 空间复杂度:O(1)