服务器并发模型/方案
引言
引言TODO
各种模式代码TODO
注意,这篇文章的用词,listening fd和connection fd
对于每个模式会分析优缺点
最简单的模式:iterative模式
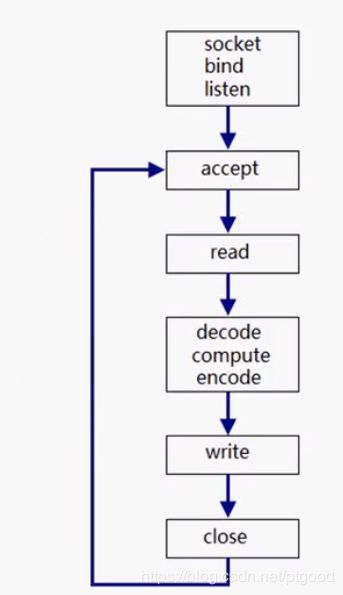
可称为iterative模式,循环模式;如下图,可以看出是一个socket编程的几个经典步骤,socket,bind,listen->accept->read->处理数据->send->close;同时也可以看出,这个只能适合短连接,因为每次只能处理一个connection fd,必须close了再重新accept新的connection fd,并处理数据完后send回处理结果
没有利用到多核,且只能应用于短连接
改进的模式:one connection per process/thread
针对于上一个只能用短连接的情况,对于每个connection fd可以各开个线程来处理那个connection fd的read->处理->send步骤,这样一是利用到了多核,二是解决了长连接的问题
问题来了,每次连接来了要创建个新process/thread,连接断开又要销毁,很容易想到用池的方法解决,引出第三种方法
再改进的模式:pre fork/thread
在socket,listen,bind,阶段我们就提前创建好process/thread,每个子进程/线程来作本文第一章图里的循环,即没连接到来时,每个子进程/线程是堵塞在accept状态的,
有带来一个问题:惊群问题,一个连接到来可能会多个accept返回,但是这个问题是可解决的,惊群问题详细见UNP的second edition,chapter 27
reactor模式
再提下reactor模式,大多数IO框架库的实现(如muduo,libevent)
reactor模式可以通过多路复用来实现一个reactor能单线程轮询多个客户端请求,从多个客户端角度来看,像是在并发执行,实际一个reactor是只在一个线程中,下图是reactor模式的图,是整个reactor的结构图

,看着比较抽象,这里用epoll来举例,epoll_ctl(listening fd可读事件)->epoll_wait()->分析事件种类->处理事件
而这分析和处理事件是判断事件种类并调用相应函数,如以下两种事件
1.listening fd可读,即连接请求到来事件,处理函数:accept并添加此connection fd到epoll关注中,即epoll_ctl(此connection fd可读)
2.connection fd可读事件,read->处理数据-->send
这只是个雏形,可以用单线程来监听多个事件(即多路复用的定义),如果只单独使用一个reactor很容易看出它的缺点是一个客户端连接处理数据不能太耗时,否则会妨碍新连接到来的处理或者是其他connection的整个处理过程,毕竟这里也只是单线程来处理,而改造也很容易,把耗时的地方提取出去,注意这里提一下,reactor所在线程被称为IO线程
reactor+thread_pool
这里我们直接跳过创建多线程/多进程再销毁的方案,直接用池的方案,当connection fd有数据来的时候,耗时操作让线程池来完成,即read到数据后的业务逻辑,
注意这图里表示的是reactor也负责read和send操作,而游双的书里提到的reactor模式的read和write由thread_pool里的线程来进行(send不知道由哪个,线程池吧),
注意这里的reactor和thread_pool的设计,这里暂时略过,有空再放代码TODO,
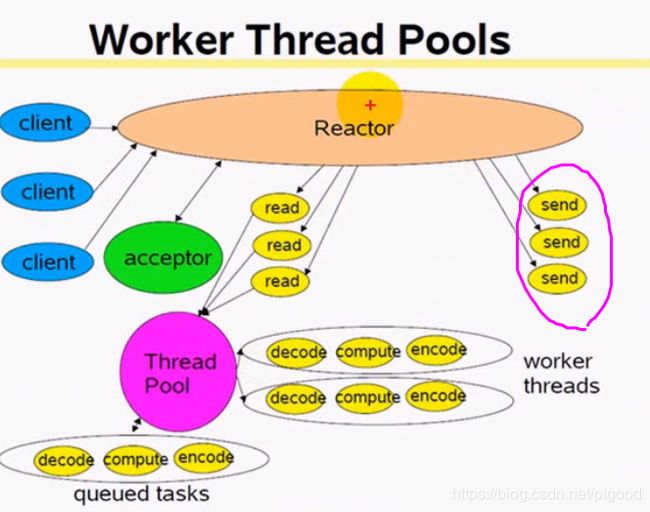
这里在提一下,之所以把read->处理这个流程放进thread_pool里,是怕这一系列操作是CPU密集的,或者说会大量消耗CPU时间从而无法让IO线程运行到epoll_wait监听事件,若丢进其他线程不影响IO线程来监听请求,所以这个模型能适应密集计算
这里还是有个问题,就是reactor线程的瓶颈,因为IO线程中epoll_wait返回后会进行一系列动作,做完后再继续epoll_wait,如果这时候有大量连接请求过来,就无法快速解决掉这一大波请求,因为只有一个reactor(即一个线程)在工作来进行accept->设置connection fd操作,,并且这个线程还要同时监听connection fd的事件并把事件扔给线程池处理,下面再引进一个方案
multiple reactor+thread_pool
multiple reactor或者说主从reactor,下图是模型示意图,省略了thread pool,
ps.注意这里的multiple reactor可以用one loop per threads,也可以用reactor in process,但如果要用线程池只能用one loop per thread

主reactor用于监听listening fd的可读事件,即新连接的到来,而subreactor只负责监听connection fd的可读事件,即客户端连接有消息发来,注意这里一个reactor占一个线程,并且前面说过了,reactor所在线程被称为IO线程,因为是监听IO可读写的线程;
这样就缓解了短时间大量连接到来的压力,把客户端来消息的压力分给subreactor
同时要提一下reactor分发connection fd给subreactor的方法是轮叫,及round-robin算法,即像播放歌曲一样列表循环,以保证每个subreactor的负载均衡,
优点:这也是目前最好的方案,能适应大量突发IO和密集计算
代码TODO
Q:reactor数目选择?略
proactor
proactor是利用异步IO的,这里提一下同步IO和异步IO的区别
代码的区别,放代码TODO
boost.asio是基于Proactor模式的,但是只是模拟proactor模式,通过epoll_wait来模拟异步IO
理论上说,proactor效率高于reactor,但是大部分IO框架都使用reactor模式,原因如下
linux的异步IO支持不完善,
1.glic aio有bug
2. kernal native aio不完善
参考资料
[大并发服务器开发](C++实战网)
[cnblog](https://www.cnblogs.com/winner-0715/p/8733787.html)
[游双的书](https://book.douban.com/subject/24722611/)
----
TODO:
- 完善proactor
- 把reactor的代码和框架图联系起来