一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter
本文主要解决的问题是在,基于优先级的拥塞控制PFC是一种粗粒度的机制,它主要是通过检测优先级队列的长度是否超过阈值,然后再发送PFC拥塞信号帧来进行流量控制。这种做法会带来不公平性以及行头阻塞等问题。作者表明,单的数据包延迟(以主机的往返时间来衡量)是一种有效的拥塞信号。因此作者通过对延迟梯度或排队随时间变化的微分做出反应,以在提供高带宽的同时保持较低的数据包延迟。
Abstract
数据中心传输旨在提供低延迟的消息传递和高吞吐量。我们表明,简单的数据包延迟(以主机的往返时间来衡量)是一种有效的拥塞信号,无需交换机反馈。首先,我们证明了NIC硬件的进步使得RTT的测量精度达到了微秒级,并且这些RTT足以估算交换机的排队时间。然后,我们描述TIMELY如何使用RTT梯度来调整传输速率,以在提供高带宽的同时保持较低的数据包延迟。我们在具有OS-by-pass功能的NIC上运行的主机软件中实施我们的设计。我们展示了在Clos网络拓扑上使用多达数百台机器进行的实验,它提供了出色的性能:在具有PFC的光纤网络上为OS-by-pass消息启用TIMELY可将99%的尾部延迟降低9倍,同时保持接近线速的吞吐量。我们的系统还优于在优化内核中运行的DCTCP,将尾部延迟减少了13倍。据我们所知,TIMELY是第一个用于数据中心的基于延迟的拥塞控制协议,尽管它的RTT信号(由于NIC卸载)比以前的基于延迟的方案少了一个数量级,但是TIMELY仍能实现其结果。
1. Introduction
数据中心网络运行紧密耦合的计算任务,这些任务必须响应用户,例如,成千上万台后端计算机可能会交换信息来满足用户请求,并且所有传输必须足够快地完成,以使完整的响应得到满足 100毫秒[24]。 为了满足这些要求,即使这些方面的性能不一致,数据中心传输也必须同时提供高带宽(?Gbps)和低延迟(?msec)的利用率。 始终具有较低的延迟很重要,因为即使是一小部分的后期操作也会引起连锁反应,从而降低应用程序性能[21]。 结果,数据中心传输必须严格限制延迟和数据包丢失。
由于传统的基于损耗的传输无法满足这些严格的要求,因此新的数据中心传输[10、18、30、35、37、47]利用网络支持来发信号通知拥塞的发生(例如,DCTCP [35] 及其后续产品使用ECN),引入流抽象以最大程度地减少完成延迟,将调度放到中央控制器等。 然而,在本文的工作中,我们会退后一步来寻找更简单,可立即部署的设计。
我们搜索的关键是拥塞信号。 理想信号将具有多个属性。 快速通知发送者有关拥塞程度的信息将是及时的。 这足以在具有多个流量类别的复杂环境中工作。 并且,这将易于部署。
令人惊讶的是,我们发现经过适当调整的众所周知的信号可以满足我们的所有目标:RTT测量形式的延迟。 RTT是每次确认后都会细化的拥塞度量。 它为低优先级传输提供了通货膨胀的衡量标准,从而有效地支持了多种流量类别,而这些优先级传输却落后于高优先级的传输。 此外,它不需要网络交换机的支持。
至少从TCP Vegas开始,就已经在广域Internet中探索了延迟[16],并且一些现代TCP变体使用延迟估计[44,46]。 但是这种延迟的使用并非没有问题。 基于延迟的方案往往与更具攻击性的基于损失的方案竞争较弱,并且由于主机和网络问题(例如,延迟的ACK和不同的路径),延迟估计可能非常不准确。 由于这些原因,在混合方案中通常将延迟与其他指标(例如损耗)一起使用。
此外,由于数据中心RTT难以以微秒的粒度进行测量,因此延迟尚未在数据中心用作拥塞信号。 主机延迟(例如对确认的中断处理)很容易使这种精度水平不堪重负。 DCTCP避开了基于延迟的方案,该方案说:“对排队延迟中如此小的增加进行准确的测量是一项艰巨的任务。” [35]
我们的见解是,NIC的最新发展确实允许以足够的精度来测量数据中心RTT,而使用延迟作为拥塞信号的广域陷阱并不适用。 最近的NIC为数据包事件的高质量时间戳提供了硬件支持[1、3、5、8、9],以及由硬件生成的ACK,这些ACK消除了不可预测的主机响应延迟。 同时,可以控制数据中心主机软件以避免与其他传输竞争,并且多条路径具有相似的,较小的传播延迟。
在本文中,我们证明了基于延迟的拥塞控制在数据中心中提供了出色的性能。 我们的主要贡献包括:
- 我们通过实验证明了使用NIC硬件测得的多位RTT信号如何与网络排队密切相关。
- 我们介绍了通过延迟测量(及时)通知的运输:基于RTT的拥塞控制方案。 TIMELY使用速率控制,旨在与多数据包段的NIC卸载协同工作,以实现高性能。 与早期的方案[16,46]不同,我们不会将队列构建为固定的RTT阈值。 相反,我们使用RTT变化率或梯度来预测拥塞的发生,从而在提供高吞吐量的同时将延迟保持在较低水平。
- 我们使用Clos网络拓扑上的数百台计算机,通过OS-bypass消息实现来及时评估。 在具有PFC(优先级流量控制)的结构上为RDMA传输打开TIMELY可以将99%的尾部延迟降低9倍。 该尾部等待时间比在优化内核中运行的DCTCP的等待时间低13倍。
2. THEVALUE OFRTT AS A CONGESTION SIGNAL IN DATACENTERS
现有的数据中心传输使用来自网络交换机的信号来检测拥塞的发生,并以低水平的延迟和丢失来运行[15,35,37]。 我们认为,无需任何交换机支持,从RTT测量得出的网络排队延迟是一种出色的拥塞信号。
RTT directly reflects latency. RTT之所以有价值,是因为它们直接衡量我们关心的数量:网络排队导致的端到端延迟。从队列占用率得出的信号(例如ECN)无法直接告知该指标。数据包上的ECN标记仅表示与数据包相对应的队列度量值超过阈值。数据中心中QoS的大量使用意味着不可能将此阈值转换为单个相应的延迟。具有不同优先级的多个队列共享同一输出链路,但是ECN标记仅提供有关占用率超过阈值的队列的信息。低优先级的流量可能会经历较大的排队延迟,而不必建立大型队列。在这种情况下,排队延迟反映了网络中的拥塞状态,而低优先级流量的队列占用率却没有反映该问题。此外,ECN标记描述了单个开关的行为。在利用率很高的网络中,拥塞发生在多个交换机上,ECN信号在它们之间无法区分。 RTT会累积有关端到端路径的信息。它包括NIC,NIC也可能会变得很拥挤,但大多数方案都将其忽略。最后,RTT甚至可以用于通常用于支持FCoE的无损网络结构[2]。在这些结构中,由于用于确保零数据包丢失的优先级流控制机制,单纯的队列占用比例可能无法反映拥塞。
RTT can be measured accurately in practice. 一个关键的实践障碍是,是否可以在数据中心中准确测量RTT,而在这些数据中心中,RTT容易比广域延迟小1000倍。 过去,很多因素都无法进行精确的测量:内核调度导致的可变性; NIC性能技术,包括卸载(GSO / TSO,GRO / LRO); 以及诸如TCP延迟确认之类的协议处理。 在数据中心中,这些因素中的每一个都足够大,足以压倒传播和排队延迟,这个问题就很严重。
幸运的是,最近的NIC为解决这些问题提供了硬件支持[1、3、5、8、9],并且可以准确记录数据包发送和接收的时间,而不受软件引起的延迟的影响。 必须谨慎使用这些方法,以免对NIC造成过多负担。 我们将在本文后面部分描述NIC支持的用法。 这些NIC还为某些协议提供了基于硬件的确认。
这些功能的组合使我们能够进行精确的RTT测量,以准确跟踪端到端网络队列。 以下实验显示了这种行为:我们通过10 Gbps链路将两台主机连接到同一网络,并在静态网络上发送16 KB乒乓消息,而不会发生任何交叉通信。 由于不存在冲突,因此我们期望RTT测量值低且稳定。 图1比较了使用NIC硬件时间戳测量的RTT的CDF和通过OS TCP堆栈测量的RTT。 使用NIC时间戳的RTT的CDF几乎是一条直线,表明差异很小。 相比之下,内核TCP测得的RTT更大且变化更大。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第1张图片](http://img.e-com-net.com/image/info8/8b0cf778f9f64f37af9d5e04f6be804e.jpg)
RTT is a rapid, multi-bit signal. Network。网络排队延迟可以通过从RTT中减去已知的传播和串行化延迟来计算。令人惊讶地,我们发现,与诸如ECN标记之类的显式网络交换机信号相比,该方法提供了有关网络交换机状态的更丰富,更快速的信息。作为一个二进制量,ECN标记传达单个信息,而RTT测量传达多个信息,并捕获跨多个交换机汇总的端到端排队延迟的全部范围,而不是在任何情况下都超过简单固定阈值的排队N个开关之一。由于每个数据包可能都带有一个ECN标记,因此标记的序列可以缩小此间隙并传达有关拥塞级别的多位信息,就像在DCTCP中一样(实际上是使用ECN的方式)在数据中心)。但是,由于宿主源是突发性的,因此诸如64 KB分段卸载之类的现代实践会破坏及时制作的标记的独立性。线速大爆发往往会使大多数数据包高于或低于标记阈值。
假设它是准确的,那么一次高RTT测量会立即发出拥塞程度的信号。 这种RTT测量甚至适用于沿单个网络路径发送的流的数据包突发:突发中最后一个数据包的RTT会跟踪整个数据包的最大RTT,因为对较早的数据包的延迟会推后的数据包。 为了显示RTT如何很好地跟踪网络排队延迟,我们建立了一个内播实验,在10个客户端计算机上同时传输100个数据流,同时将其传输到单个服务器。 为了合并NIC卸载,我们发送64 KB消息,并且在客户端每条消息仅收集一次RTT测量。 瓶颈链接是到服务器的10 Gbps链接。 我们每微秒采样一次交换队列。
图2显示了在终端系统上测得的RTT的CDF与直接在交换机上测得的队列占用率的比较,并显示了为10 Gbps链路计算的时间单位。 这两个CDF匹配得非常好。
相反,ECN信号与RTT并没有很好地关联,因此与排队量没有很好的关联。 我们建立了一个类似的播报实验,除了现在的TCP发送者执行向单个接收者的长传输。 瓶颈是到接收器的10 Gbps链路,具有80 KB的交换机ECN标记阈值。 我们使用SND_UNA [41]的进阶来标记RTT回合的结束,从而检测发送方在每个往返时间内用ECN标记接收的数据包的比例。 我们还对每一轮的最小RTT样本进行了测量,因为先前的工作已经发现它是一个可靠的描述符,不受延迟ACK和发送/接收卸载方案的影响。 图3中的散布图和箱形图1 [4]都只显示了ECN标记分数与RTT之间的弱相关性。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第2张图片](http://img.e-com-net.com/image/info8/a8caac83bcdc459292503a6ead993df7.jpg)
Limitations of RTTs. 尽管我们发现RTT信号很有价值,但有效的设计必须谨慎使用。 RTT测量会沿网络路径在两个方向上排队。 这可能会使ACK所经历的反向路径拥塞与数据包所经历的正向路径拥塞相混淆。 一种简单的解决方法是发送具有更高优先级的ACK,这样它们就不会引起明显的排队延迟。 在通常主要向一个方向发送数据的流的常见情况下,此方法适用。 我们不需要更复杂的方法。
我们进行了一项实验,以验证ACK优先级排序的有效性:我们启动了两个Incast(主要和次要),以使主要Incast的ACK与次要Incast的数据段共享相同的拥塞队列,如图4所示。 图5显示了以下三种情况下来自主播的RTT的CDF:1)ACK路径中没有拥塞(无次播)。 2)ACK路径中存在拥塞; 3)在存在反向拥塞的情况下,将来自主播的ACK优先分配给优先级较高的QoS队列。 我们发现反向拥塞在主要铸件的RTT测量中产生噪声,并延长了尾部潜伏期。 主铸件的吞吐量也受到影响(因此,较低百分位数中的较小RTT)。 通过ACK优先级排序,在主播中测得的RTT与在没有反向路径拥塞的情况下测得的RTT是相似的。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第3张图片](http://img.e-com-net.com/image/info8/38d0b8a12dcf47429b3e8a3ad78b07af.jpg)
在未来的研究工作中,通过在一个数据包中嵌入一个时间戳(例如,TCP时间戳)来计算两个数据包之间的单向延迟的变化将是很简单的。 排队延迟的变化就是到达时间的变化减去每个数据包的发送时间。 此方法仅需要以相同速率运行的时钟,这比同步时钟的要求要严格得多。
RTT的另一个经典缺点是变化的网络路径具有完全不同的延迟。 由于所有路径都具有较小的传播延迟,因此在数据中心中的问题较少。
3. TIMELY FRAMEWORK
TIMELY为速率控制提供了一个框架,该框架与用于可靠性的传输协议无关。 图6显示了它的三个组成部分:1)RTT测量以监视网络的拥塞情况; 2)将RTT信号转换为目标发送速率的计算引擎; 3)控制引擎,在各段之间插入延迟以达到目标速率。 我们在具有NIC硬件支持的主机软件中实现TIMELY,并为每个flow运行一个独立的实例。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第4张图片](http://img.e-com-net.com/image/info8/5d62724c479e4b388a20522167c726ad.jpg)
3.1 RTT Measurement Engine
我们假设传统的传输方式是接收方明确地确认新数据,以便我们可以提取RTT。 我们根据图7定义RTT,图7显示了一条消息的时间轴:由多个数据包组成的段作为单个突发发送,然后由接收器作为一个单元进行确认。 在接收到数据段的ACK时会生成一个完成事件,该事件包括ACK接收时间。 从发送第一个数据包(发送)到接收到ACK(完成)的时间定义为完成时间。 与TCP不同,一组数据包有一个RTT,而不是每1-2个数据包有一个RTT。 有几个延迟组件:1)传输段中所有数据包的序列化延迟,通常最大为64 KB; 2)段及其ACK在数据中心之间传播的往返线路延迟; 3)在接收方产生ACK的周转时间; 和4)双向交换机的排队延迟。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第5张图片](http://img.e-com-net.com/image/info8/12be035b603f44e88bb5cb26a5ed3ab2.jpg)
我们将RTT定义为仅是传播和排队延迟组件。 第一部分是网段大小和网线速率的确定性函数。 我们从总经过时间中进行计算并减去,以便输入到TIMELY费率计算引擎的RTT不受网段大小的影响。 在我们使用基于NIC的ACK的设置中,第三个分量足够接近零,我们可以忽略它。 在其余组件中,第二个组件是传播延迟,包括交换机上基于数据包的存储和转发行为。 它是最小RTT,对于给定的流量是固定的。 只有最后一个部分(排队延迟)会导致RTT发生变化,这是我们检测拥塞的重点。 总而言之,在主机A上运行的TIMELY(如图7所示)将RTT计算为:
![]()
例如,在10 Gbps网络中,64 KB的串行化需要51 µs,传播范围可能是10-100 µs,而1500 B的排队需要1.2 µs。 我们依靠两种形式的NIC支持来精确测量分段RTT,如下所述。
ACK Timestamps。 我们要求NIC提供完成时间戳记tcompletion。 如第2节所示,操作系统时间戳受调度和中断等变化的影响,这些变化很容易掩盖拥塞信号。 tsend是在将网段发布到NIC之前由主机软件读取的NIC硬件时间。
Prompt ACK generation。 我们需要基于NIC的ACK生成,以便我们可以忽略接收器的周转时间。 一种替代方法是使用时间戳来测量由于主机处理延迟而导致的ACK周转延迟。 我们避免了此选项,因为它将需要扩展传输线格式以明确包括此差异。
幸运的是,某些现代的NIC [1、3、5、8、9]提供一个或两个功能,并且通过带有时间戳段识别的消息传递实现自然满足了我们的要求。 §5中描述了RDMA上下文中TIMELY的特定实现。 我们相信我们的设计更普遍地适用于TCP,需要谨慎处理NIC的批处理行为,将ACK与新数据的接收正确关联,并补偿ACK的周转时间。
3.2 Rate Computation Engine
该组件实现了我们的基于RTT的拥塞控制算法,如§4所述。 速率计算引擎的接口很简单。 每次完成事件后,RTT测量引擎都会以秒为单位向速率计算引擎提供RTT。 虽然这是唯一需要的输入,但是其他定时信息也可能有用,例如,NIC中的延迟。不需要数据包级别的操作;在正常操作中,由于NIC卸载,我们预计单个完成事件的大小最大为64 KB。 速率计算引擎在每个完成事件上运行拥塞控制算法,并为流输出更新的目标速率。
3.3 Rate Control Engine
当准备好发送一条消息时,速率控制引擎将其分成多个段进行传输,然后将每个段依次发送到调度程序。为了提高运行时效率,我们实现了一个可处理所有流的调度程序。调度程序使用段大小,流率(由速率计算引擎提供)和上次传输时间来计算当前段的发送时间,并带有适当的起搏延迟。然后将该段放在调度程序中的优先级队列中。过去具有发送时间的段以循环方式进行服务;具有未来发送时间的段被排队。在经过定步延迟之后,速率控制引擎将段传递到NIC,以作为数据包突发立即传输。首先将数据批处理为64 KB的段,然后调度程序计算定步延迟,以将其插入两个此类批处理的段之间。请注意,最大批处理大小是64 KB,而不是必需的,例如,在任何给定时间仅具有小消息要交换的流的段大小将小于64 KB。稍后,我们还将提供小于64 KB的段大小的结果。
TIMELY是基于速率的,而不是基于窗口的,因为考虑到NIC卸载的广泛使用,它可以更好地控制流量突发。 带宽延迟乘积在数据中心中只是少量的数据包突发,例如,在10 Gbps时为51 µs是一条64 KB消息。 在这种情况下,窗口不提供对数据包传输的细粒度控制。 通过指定目标速率,可以更直接地控制突发之间的间隔。 为了保障安全,我们将未完成数据的数量限制在静态的最坏情况下。
4. TIMELY CONGESTION CONTROL
我们的拥塞控制算法在速率计算引擎中运行。 在本节中,我们描述了我们的环境和关键性能指标,然后介绍了基于梯度的方法和算法。
4.1 Metrics and Setting
数据中心网络环境的特点是,通过高带宽,低延迟路径上紧密耦合的计算形式,产生大量突发消息工作负载。在许多方面,它与传统的广域网相反。带宽充足,而最重要的是流程计算时间(例如,对于远程过程调用(RPC))。对于短RPC,最小完成时间由传播和序列化延迟确定。因此,我们尝试最小化任何排队延迟以保持RTT低。尾部延迟很重要,因为当即使一小部分数据包延迟时,应用性能也会大幅度下降[21]。一致的低延迟意味着低排队延迟和接近零的数据包丢失,因为恢复操作可能会大大增加消息延迟。较长的RPC将具有较大的完成时间,因为在共享网络上传输更多数据需要花费时间。为了使增加的时间保持较小,我们必须保持较高的总吞吐量以使所有流量受益,并保持近似的公平性,从而使任何流量都不会受到惩罚。
我们评估的主要指标是RTT(第99个百分位)和总吞吐量,因为它们确定我们完成短期和长期RPC的速度(假设有些公平)。 当吞吐量和数据包RTT之间存在冲突时,我们宁愿以牺牲少量带宽为代价将RTT保持在较低水平。 这是因为带宽一开始就足够,RTT的增加直接影响短传输的完成时间。 实际上,我们试图将吞吐量/等待时间曲线拖延到尾部等待时间变得不可接受的地步。 次要指标是公平性和损失。 我们将二者作为检查报告,而不是对其进行详细研究。 最后,相对于较高的平均值,我们更倾向于采用稳定的设计,但为了可预测的性能而采用振荡速率。
4.2 Delay Gradient Approach Delay-based
基于时延的拥塞控制算法,例如FAST TCP [46]和Compound TCP [44],是受TCP Vegas的基础工作启发的[16]。这些将RTT高于基线的增加解释为拥塞的指示:如果进一步增加延迟以尝试将瓶颈队列的缓冲区占用保持在某个预定义阈值附近,则会降低发送速率。然而,凯利等[33]认为,当队列时间短于控制环路延迟时,就不可能控制队列大小。在数据中心中就是这种情况,在10 Gbps链路上,一条64 KB消息的控制环路延迟至少为51 µs,并且由于竞争的流量可能会大大提高,而一个排队延迟的数据包则持续1 µs。在这种情况下,最多的算法是控制队列占用率的分布。即使可以控制队列的大小,但为数据中心网络选择一个阈值(其中多个队列可能成为瓶颈)也是众所周知的难题。
TIMELY的拥塞控制器通过对延迟梯度或排队随时间变化的微分做出反应,从而实现了低延迟,而不是试图保持排队。 这是可能的,因为我们可以准确地测量表明排队延迟发生变化的RTT的差异。 由于RTT增加而导致的正延迟梯度表示队列增加,而负梯度表示队列减少。 通过使用梯度,我们可以对队列增长做出反应,而无需等待队列的形成–一种有助于我们实现低延迟的策略。
延迟梯度是瓶颈队列中速率不匹配的代理。 我们受到RCP,XCP,PI和QCN [10、28、32、39]的启发,发现速率不匹配的显式反馈比仅基于队列大小的显式反馈具有更好的稳定性和收敛性。 此后甚至可能导致队列的控制精度降低。 关键区别在于,所有这些现有控制器均在网络中的点队列中运行,而TIMELY通过使用端到端延迟梯度可实现类似的优势。
4.3 The Main Algorithm
算法1显示了我们的拥塞控制算法的伪代码。 及时为每个连接保持单一速率R(t),并使用RTT样本在每个完成事件上更新它。 它采用梯度跟踪,使用平滑的延迟梯度作为误差信号来调整速率,以保持吞吐量接近可用带宽。 另外,我们使用阈值来检测和响应利用率不足或数据包延迟过高的极端情况。 图8显示了梯度区域以及两个阈值。 当RTT在标称工作范围内时,梯度跟踪算法会根据RTT样本计算延迟梯度,并使用它来调整发送速率。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第6张图片](http://img.e-com-net.com/image/info8/59656aa8ab444c1e972e8a1c924932ce.jpg)
Computing the delay gradient.我们依靠使用NIC时间戳(§3)进行准确的RTT测量。 为了计算延迟梯度,TIMELY计算两个连续RTT样本之间的差。 我们通过将差除以最小RTT来归一化,以获得无量纲的数量。 实际上,最小RTT的确切值并不重要,因为我们只需要确定队列是在增长还是在减少。 因此,我们使用一个固定值来表示跨数据中心网络的导线传播延迟,这是提前知道的。 最后,我们将结果通过EWMA过滤器。 该过滤器使我们能够检测队列中上升和下降的总体趋势,而忽略了不表示拥塞的较小队列波动
Computing the sending rate. 接下来,及时使用标准化梯度来更新连接的目标速率。 如果梯度为负或等于零,则网络可以跟上传入的总速率,因此存在更高速率的空间。 在这种情况下,TIMELY通过为连接执行加法增量来探测更多带宽:R = R +δ,其中δ是带宽加法增量常数。 当梯度为正时,总发送速率大于网络容量。 因此,TIMELY会执行乘以速率递减的β,由梯度因子缩放:
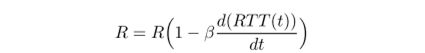
延迟梯度信号基于总的传入和传出速率,对于同一条拥塞路径上的所有连接都是通用的。 众所周知的AIMD属性可确保我们的算法在所有连接中均达到公平[19]。 以较高速率发送的连接的速率下降幅度更大,而所有连接的速率保持不变。
尽管延迟梯度在正常操作中有效,但利用率严重不足或等待时间较长的情况需要更积极的响应。 接下来,我们讨论如何及时发现和应对这些情况。
Need for RTT low threshold Tlow. 对于我们的算法,理想的环境是对数据包进行完美调整的环境。 但是,在实际设置中,TIMELY速率是根据可能高达64 KB的段粒度强制执行的。 这些较大的段会导致数据包突发,从而导致网络中的瞬态队列,从而在偶尔发生冲突时导致RTT尖峰。 如果不加注意,核心算法会检测到由于RTT突然尖峰而产生的正梯度,并不必要地推断出拥塞和退避。 我们通过使用低阈值Tlow过滤RTT尖峰来避免这种情况。 对于大于阈值的RTT样本,基于延迟梯度开始进行调整。 Tlow是网络中使用的段大小的(非线性)增加函数,因为较大的消息会导致更多的突发队列占用。 我们在评估中探讨了这种影响,并展示了主机上的细粒度起搏如何减少突发性,因此需要较低的阈值。
Need for RTT high threshold Thigh. 核心梯度算法可保持接近瓶颈链路吞吐量,同时建立的队列很少。 但是,从理论上讲,当队列保持较高的固定级别时,梯度可能会保持为零。 为了消除这种担忧,Thigh作为可容忍的端到端网络队列延迟(即尾部延迟)的上限。 如果延迟增加,它提供了一种与速率值无关的降低速率的方法,这是可能的保护,因为我们在具有已知特征的数据中心环境中运行。 如果测得的RTT大于Thigh,我们会反复降低速率:

请注意,我们使用即时而不是平滑的RTT。 尽管这看起来很不正常,但我们可以对单个过大的RTT进行响应,从而放慢速度,因为我们可以确信它会发出拥塞信号,而我们的首要任务是保持低数据包延迟并避免丢失。 我们尝试将平均RTT作为拥塞指标进行响应,发现由于反馈回路中的额外延迟,它会损害数据包延迟。 等到平均值上升,并且拥塞控制降低速率时,网络中的排队延迟已经增加。 我们的发现与[27]一致,后者通过控制理论分析表明,平均队列长度是RED AQM的失败。 我们在§6中展示了Thigh如何使我们沿着吞吐量-延迟折衷曲线向右移动。
Hyperactive increase (HAI) for faster convergence. 受TCP BIC,CUBIC [42]拥塞控制和QCN [10]中最大探测阶段的启发,我们提供了HAI选项以加快收敛速度,如下所示:如果经过一段缓慢的时间后TIMELY未达到新的公平份额 增长,即连续几个完成时间的负值,然后HAI切换到更快的加性增长,其中速率增加Nδ而不是δ。 当由于网络负载减少而导致新的公平份额急剧增加时,这很有用。
4.4 Gradient versus Queue Size
我们通过实验强调了梯度方法与基于队列大小的方案有何不同。 如果我们为Tlow和Thigh设置相同的值,则TIMELY收敛控制将减少为基于队列大小的方法(类似于TCP FAST算法; FAST则是Vegas的缩放改进版本)。 将Ttarget表示为该单个RTT阈值的值,即Ttarget = Tlow = Thigh。 然后,该速率通过队列上方Ttarget之上的队列大小来缩放,从而增加和增加乘数减少的速率。
图9比较了针对Incast流量模式的基于梯度和队列大小的方法的RTT和吞吐量。 (有关实验的详细信息,请参见§6。)我们将梯度的上限和下限分别设为50 µs和500 µs,而队列大小的方法将Ttarget设为50 µs和500 µs。 我们看到队列大小方法可以保持低延迟或高吞吐量,但是发现很难做到这两种。 通过建立一个高达500 µs的高Ttarget的固定队列,可以优化吞吐量,但以排队为代价的等待时间为代价。 另外,通过将站立队列保持在50 µs的低Ttarget上,可以优化延迟,但由于队列有时为空,因此吞吐量很充足。 通过对上升和下降队列进行操作,梯度方法可以预测拥塞的发生。 这使它可以提供高队列目标的高吞吐量,同时使尾部等待时间接近低目标。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第7张图片](http://img.e-com-net.com/image/info8/361683616fb24ab281a091bfbc04ff73.jpg)
此外,如图10所示,当队列大小方法将RTT向上和向下推向目标队列大小时,其连接速率会更多地振荡。 梯度法使公平份额周围的汇率保持平稳。 使用队列大小方法和梯度方法,在AQM的控制理论术语中显示了相似的结果[28]。
主要结论是,Tlow和Thigh阈值有效地将延迟带入了目标范围内,并且在许多AQM方案中起着类似于目标队列占用的作用。 使用延迟梯度可以提高稳定性,并有助于将等待时间保持在目标范围内。
5. IMPLEMENTATION
我们的实现基于具有OS旁路功能的10 Gbps NIC。 NIC支持具有基于硬件的ACK和时间戳的多数据包段。 我们在RDMA(远程直接内存访问)的上下文中实现了TIMELY,将其作为NIC功能和主机软件的组合。 我们使用RDMA原语来调用NIC服务,并将完整的内存到内存的传输卸载到NIC。 特别是,我们主要使用RDMA写入和读取来从本地主机内存中获取一条消息,并将其作为突发数据包发送到网络上。 在远程主机上,NIC确认收到完整消息,并将其直接放置在远程内存中以供远程应用程序使用。 传输完成后,将通知本地主机此确认。 我们在下面描述实现的一些值得注意的地方。
Transport Interface. TIMELY与传输协议的拥塞控制部分有关。 它与传输向应用程序公开的可靠性或更高级别的接口无关。 这使得与其余传输的接口变得简单:消息发送和接收。 在发件人处收到消息时,如果消息很大,则及时将其分成较小的段,并以目标速率发送这些段。 一条消息只是字节的有序序列。 该段被传递到NIC,然后作为突发数据包通过网络发送。 在远程主机上,NIC确认收到完整段。 在接收方,当接收到一个段时,它将被传递到传输的其余部分进行处理。 这个简单的模型支持从RPC到字节流(例如TCP)的传输
Using NIC Completions for RTT Measurement. 实际上,使用NIC时间戳具有挑战性。我们的NIC仅记录多数据包操作完成的绝对时间戳,因此我们的用户空间软件需要记录操作何时发布到NIC的时间戳。这需要一种将主机时钟映射到NIC时钟以及进行校准的方案。我们将工作发布到NIC时记录主机(CPU)时间戳,并建立一种校准机制以将NIC时间戳映射到主机时间戳。一个简单的线性映射就足够了。该机制之所以有效,是因为在记录主机发送时间戳和将消息实际发送到NIC之间被中断的可能性相当低。图11比较了从NIC HW时间戳,校准机制和纯软件时间戳获得的RTT。请注意,TIMELY不会旋转,因此中断和唤醒都包含在软件时间戳中。它清楚地表明,校准机制与仅使用NIC时间戳一样准确。此外,SW时间戳具有较大的方差,随主机负载的增加而增加。
![一周一论文(翻译)——[SIGMOD 2015] TIMELY RTT-based Congestion Control for the Datacenter_第8张图片](http://img.e-com-net.com/image/info8/5b5b5953cc5d4a92a245886a5dcfcf02.jpg)
我们认为发生的任何NIC排队都是RTT信号的一部分。 这很重要,因为NIC排队还表示拥塞,并且由与网络排队相同的基于速率的控制来处理-即使NIC为我们提供了实际的发送时间戳,我们还是希望能够观察NIC排队。
RDMA rate control. 对于RDMA写操作,发送器上的TIMELY直接控制段起搏速度。 对于RDMA读取,接收器发出读取请求,作为响应,远程主机执行数据段的DMA。 在这种情况下,TIMELY无法直接调整数据段的速度,而是通过调整读取请求的步调来达到相同的结果:在计算读取请求之间的调整间隔时,速率计算引擎会考虑从读取的数据段字节 远程主机。
Application limited behavior. 应用程序并不总是具有足够的数据来传输以使其流量达到目标速率。 发生这种情况时,我们不想无意间增加目标速率,因为网络似乎没有拥塞。 为避免此问题,仅当应用程序发送的目标速率超过目标速率的80%时,才让目标速率增加,并且还将最大目标速率限制为10 Gbps。 留出一定空间的目的是让应用程序确实有足够的数据要发送时,在没有不合理延迟的情况下提高其速率。
Rate update frequency. TIMELY的费率更新公式假设每个RTT间隔最多有一个完成事件。 10 Gbps链路上64 KB消息的传输延迟为51 µs; 最小RTT为20 µs,在任何给定的最小RTT间隔内最多可以有一个完成事件。 但是,对于较小的段大小,在最小RTT间隔内可能会有多个完成事件。 在这种情况下,我们希望基于最新信息来更新费率。 我们通过更新每个完成事件的速率来做到这一点,并注意按每个最小RTT间隔的完成数量来缩放更新,以免影响新信息。
为了提高调度程序的效率,速率控制引擎会延迟执行速率更新。 当先前计算出的段发送时间过去时,调度程序将检查当前速率。 如果速率降低,我们将重新计算发送时间,并在适当的情况下重新排队该段。 否则,调度程序继续将网段发送到NIC。
Additional pacing opportunities. 缺省情况下,NIC以链接线路速率将段作为数据包突发发送。我们探索了另一种可能性:使用NIC速率限制器以小于线路速率的速率发送突发数据包。基本原理是使用NIC大小的工作单元来补充调速引擎,该引擎将流的数据包随时间传播。使用硬件速率限制器[43],将部分起搏责任转移到NIC是可行的。但是,由于硬件的限制,每隔几个RTT重新配置起搏率并不总是可行的。取而代之的是,我们使用一种混合方法:大型网段的软件步调和链接速率以下的固定速率的硬件步调,例如10 Gbps链路上的5 Gbps。在这些高速率下,NIC步调的目的是在突发中插入间隙,以便多个突发在交换机上混合而不会引起延迟尖峰。在这种情况下,速率控制引擎通过将其视为较低的传输线速率来补偿NIC起搏延迟。
6. Related Work
数据中心拥塞控制是一个深入研究的话题[15,18,35,37,38,47]。 及时关注相同的问题。
RED [23]和CoDel [40]提早丢弃数据包,促使发送方降低传输速率,以避免与拖尾相关的庞大的排队队列。 但是,丢失仍然会增加遇到丢包的流的等待时间。 为了避免数据包丢失,许多方案都依靠ECN形式的交换机支持,其中将数据包标记为指示拥塞[22]。 ECN标记通常跨多个数据包组合[15、35、37]以提供细粒度的拥塞信息,但是我们在§2中的实验表明ECN具有固有的局限性。 还有其他一些依赖交换机支持来缓解拥塞的提议,例如QCN [29](细粒度的队列占用信息)和pFabric [38](细粒度的优先级划分)。
TIMELY属于另一类算法,该算法使用延迟测量来检测拥塞,而无需交换机支持。 我们从TCP Vegas,FAST和Compound [16、44、46]中汲取灵感。 这些建议是基于窗口的,并保持接近最小RTT的队列。 相比之下,TIMELY是一种基于速率的算法,采用梯度方法,并且不依赖于测量最小RTT。 我们显示,即使RTT信号很少,它也可以很好地支持NIC。
最近的方案DX [17]独立地确定了使用延迟作为高吞吐量和低延迟数据中心通信的拥塞信号的好处。 DX使用用于NIC的DPDK驱动程序实现了精确的延迟测量,并且拥塞控制算法位于Linux TCP堆栈中。 DX算法与传统的基于窗口的提议相似,其加性增加和乘性减少与平均排队延迟成正比。
CAIA延迟梯度[25](CDG)提出了一种用于广域网TCP拥塞控制的延迟梯度算法。 其主要目标是找出与基于丢失的拥塞控制并存的情况。 因此,其算法的性质与TIMELY中的算法不同。
链路层流控制用于Infiniband和数据中心桥接(DCB)网络中的低延迟消息传递。但是,文献[20,36]记录了优先流控制(PFC)的问题,包括行头阻塞和暂停传播或拥塞扩散。最近的一些建议旨在使用ECN标记来解决PFC的这些问题,以保持较低的队列占用率。 TCP-Bolt [14]在内核TCP堆栈中使用了经过修改的DCTCP算法。 DCQCN [48]将ECN标记与NIC中实现的QCN启发的基于速率的拥塞控制算法结合使用。评估表明,它可以解决PFC的HoL阻塞和不公平问题,从而使RoCE可以大规模部署。 TIMELY使用RTT信号,在支持NIC时间戳的主机软件中实现,并且适用于OS旁路和基于OS的传输。在拥塞控制和CPU利用率方面对TIMELY和DCQCN进行比较是一个有趣的未来工作。
通过使用分布式方法[18,47]甚至是集中式方法[30]调度传输,也可以避免拥塞。 但是,这种方案尚待大规模验证,并且比基于简单延迟的方法更为复杂。
最后,诸如Conga [13]和FlowBender [11]之类的负载敏感路由可以通过在网络上分散流量来缓解拥塞热点,从而提高吞吐量。 但是,仍然需要基于主机的拥塞控制,以将提供的负载与网络容量相匹配。
7. CONCLUSION
传统观点认为,延迟是数据中心中不可信任的拥塞信号。 我们在TIMELY方面的经验表明,情况恰恰相反-如果适当地调整了延迟,则RTT与网络中的队列建立密切相关。 我们构建了TIMELY,它利用现代NIC支持的时间戳和快速的ACK周转功能,基于精确的RTT测量来执行拥塞控制。 我们发现,即使在不经常使用RTT信号和NIC卸载的情况下,TIMELY仍可以检测并响应数十微秒的排队,以实现低数据包延迟和高吞吐量。 随着数据中心速度的提高一个数量级,未来的工作应该集中在有效的RTT持续用于拥塞控制上,同时重新考虑基于延迟的算法的本质。