隐马尔科夫模型(HMM)笔记(公式+代码)
文章目录
- 1. 基本概念
- 1.1 HMM模型定义
- 1.2 盒子和球模型
- 1.3 观测序列生成过程
- 1.4 HMM模型3个基本问题
- 2. 概率计算问题
- 2.1 直接计算法
- 2.2 前向算法
- 2.2.1 前向公式证明
- 2.2.2 盒子和球例子
- 2.2.3 前向算法Python代码
- 2.3 后向算法
- 2.3.1 后向公式证明
- 2.3.2 后向算法Python代码
- 2.4 一些概率与期望值
- 3. 学习算法
- 3.1 监督学习方法
- 3.2 无监督 B a u m Baum Baum- W e l c h Welch Welch 算法
- 4. 预测算法
- 4.1 近似算法
- 4.2 维特比 V i t e r b i Viterbi Viterbi 算法
- 4.3 维特比算法Python代码
- 5. PosTagging词性标注 实践
隐马尔科夫模型(hidden Markov model,HMM)是可用于 标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。隐马尔可夫模型在语音识别、自然语言处理、生物信息、模式识别等领域有着广泛的应用。
本文内容部分引用于 李航《统计学习方法》
1. 基本概念
1.1 HMM模型定义
- 隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。
- 隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence);
- 每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。
- 序列的每一个位置又可以看作是一个时刻。
一个不一定恰当的例子:你只知道一个人今天是散步了,逛街了,还是在家打扫卫生,推测今天的天气;这个人在下雨天可能在家打扫卫生,也有可能雨中散步,晴天可能去逛街,也有可能散步,或者打扫卫生
隐藏状态 Y(不可见):下雨,晴天
观察状态 X(可见): 散步,逛街,打扫房间
假设我们观测到的状态是 X X X序列, X = ( x 1 , x 2 , x 3 , . . . x n ) X=(x_1,x_2,x_3,...x_n) X=(x1,x2,x3,...xn), 隐藏状态是 Y Y Y序列, Y = ( y 1 , y 2 , y 3 , . . . y n ) Y=(y_1,y_2,y_3,...y_n) Y=(y1,y2,y3,...yn)
我们在知道观测序列 X X X的情况下,求有多大概率是该隐藏状态序列 Y Y Y
- 贝叶斯公式 P ( B ∣ A ) = P ( A B ) P ( A ) = P ( A ∣ B ) P ( B ) P ( A ) P(B|A)=\frac {P(AB)}{P(A)}=\frac{P(A|B)P(B)}{P(A)} P(B∣A)=P(A)P(AB)=P(A)P(A∣B)P(B)
现在我们要求的就是 P ( Y ∣ X ) P(Y|X) P(Y∣X)
P ( Y ∣ X ) = P ( y 1 , y 2 , y 3 , ⋯ , y n ∣ x 1 , x 2 , x 3 , ⋯ , x n ) = P ( x 1 , x 2 , x 3 , ⋯ , x n ∣ y 1 , y 2 , y 3 , ⋯ , y n ) P ( y 1 , y 2 , y 3 , ⋯ , y n ) P ( x 1 , x 2 , x 3 , ⋯ , x n ) ( 0 ) P ( y 1 , y 2 , y 3 , ⋯ , y n ) = P ( y 1 ) P ( y 2 , y 3 , y 4 , ⋯ , y n ∣ y 1 ) = P ( y 1 ) P ( y 2 ∣ y 1 ) P ( y 3 , y 4 , ⋯ , y n ∣ y 1 , y 2 ) = P ( y 1 ) P ( y 2 ∣ y 1 ) P ( y 3 ∣ y 1 , y 2 ) P ( y 4 , ⋯ , y n ∣ y 1 , y 2 , y 3 ) ⋮ = P ( y 1 ) P ( y 2 ∣ y 1 ) P ( y 3 ∣ y 1 , y 2 ) ⋯ P ( y n − 1 ∣ y 1 , y 2 , ⋯ , y n − 2 ) P ( y n ∣ y 1 , y 2 , ⋯ , y n − 1 ) = P ( y 1 ) ∏ i = 2 n P ( y i ∣ y 1 , y 2 , y 3 , ⋯ , y i − 1 ) = P ( y 1 ) ∏ i = 2 n P ( y i ∣ y i − 1 ) ( 1 ) \begin{aligned} P(Y|X) & = P(y_1,y_2,y_3,\cdots,y_n|x_1,x_2,x_3,\cdots,x_n)\\ & =\frac{P(x_1,x_2,x_3,\cdots,x_n|y_1,y_2,y_3,\cdots,y_n)P(y_1,y_2,y_3,\cdots,y_n)}{P(x_1,x_2,x_3,\cdots,x_n)}\quad\quad(0)\\ P(y_1,y_2,y_3,\cdots,y_n) & =P(y_1){\color{red}P(y_2,y_3,y_4,\cdots,y_n|y_1)}\\ & =P(y_1)P(y_2|y_1){\color{red}P(y_3,y_4,\cdots,y_n|y_1,y_2)}\\ & =P(y_1)P(y_2|y_1)P(y_3|y_1,y_2){\color{red}P(y_4,\cdots,y_n|y_1,y_2,y_3)}\\ \vdots\\ & =P(y_1)P(y_2|y_1)P(y_3|y_1,y_2)\cdots P(y_{n-1}|y_1,y_2,\cdots,y_{n-2})P(y_n|y_1,y_2,\cdots,y_{n-1})\\ & =P(y_1)\prod_{i=2}^{n}P(y_i|y_1,y_2,y_3,\cdots,y_{i-1})\\ & =\color{blue}{P(y_1)\prod_{i=2}^{n}P(y_i|y_{i-1})}\quad\quad\quad(1)\\ \end{aligned} P(Y∣X)P(y1,y2,y3,⋯,yn)⋮=P(y1,y2,y3,⋯,yn∣x1,x2,x3,⋯,xn)=P(x1,x2,x3,⋯,xn)P(x1,x2,x3,⋯,xn∣y1,y2,y3,⋯,yn)P(y1,y2,y3,⋯,yn)(0)=P(y1)P(y2,y3,y4,⋯,yn∣y1)=P(y1)P(y2∣y1)P(y3,y4,⋯,yn∣y1,y2)=P(y1)P(y2∣y1)P(y3∣y1,y2)P(y4,⋯,yn∣y1,y2,y3)=P(y1)P(y2∣y1)P(y3∣y1,y2)⋯P(yn−1∣y1,y2,⋯,yn−2)P(yn∣y1,y2,⋯,yn−1)=P(y1)i=2∏nP(yi∣y1,y2,y3,⋯,yi−1)=P(y1)i=2∏nP(yi∣yi−1)(1)
隐马尔可夫模型 两个假设
- 上式最后一步是隐马尔可夫的 齐次性 假设:当前状态 y i y_i yi 仅依赖于前一个状态 y i − 1 y_{i-1} yi−1
- 下面式子最后一步是隐马尔可夫的 观测独立性 假设:观测值 x i x_i xi 只跟他的隐含状态 y i y_i yi 相关
P ( x 1 , x 2 , x 3 , ⋯ , x n ∣ y 1 , y 2 , y 3 , ⋯ , y n ) = ∏ i = 1 n P ( x i ∣ x 1 , x 2 , x 3 , ⋯ , x i − 1 , y 1 , y 2 , y 3 , ⋯ , y n ) = ∏ i = 1 n P ( x i ∣ y i ) ( 2 ) \begin{aligned} &P(x_1,x_2,x_3,\cdots,x_n|y_1,y_2,y_3,\cdots,y_n)\\ =&\prod_{i=1}^{n}P(x_i|x_1,x_2,x_3,\cdots,x_{i-1},y_1,y_2,y_3,\cdots,y_n)\\ =&\color{blue}\prod_{i=1}^{n}P(x_i|y_i)\quad\quad\quad(2)\\ \end{aligned} ==P(x1,x2,x3,⋯,xn∣y1,y2,y3,⋯,yn)i=1∏nP(xi∣x1,x2,x3,⋯,xi−1,y1,y2,y3,⋯,yn)i=1∏nP(xi∣yi)(2)
- 由 ( 1 ) ( 2 ) (1)(2) (1)(2), 且 ( 0 ) (0) (0)式忽略分母
P ( Y ∣ X ) = P ( y 1 , y 2 , y 3 , ⋯ , y n ∣ x 1 , x 2 , x 3 , ⋯ , x n ) = P ( x 1 , x 2 , x 3 , ⋯ , x n ∣ y 1 , y 2 , y 3 , ⋯ , y n ) P ( y 1 , y 2 , y 3 , ⋯ , y n ) P ( x 1 , x 2 , x 3 , ⋯ , x n ) ∝ P ( y 1 ) ∏ i = 2 n P ( y i ∣ y i − 1 ) ∏ i = 1 n P ( x i ∣ y i ) \begin{aligned} P(Y|X) =&P(y_1,y_2,y_3,\cdots,y_n|x_1,x_2,x_3,\cdots,x_n)\\ =&\frac{P(x_1,x_2,x_3,\cdots,x_n|y_1,y_2,y_3,\cdots,y_n)P(y_1,y_2,y_3,\cdots,y_n)}{P(x_1,x_2,x_3,\cdots,x_n)}\\ \propto & \color{blue}{P(y_1)\prod_{i=2}^{n}P(y_i|y_{i-1})}\prod_{i=1}^{n}P(x_i|y_i) \end{aligned} P(Y∣X)==∝P(y1,y2,y3,⋯,yn∣x1,x2,x3,⋯,xn)P(x1,x2,x3,⋯,xn)P(x1,x2,x3,⋯,xn∣y1,y2,y3,⋯,yn)P(y1,y2,y3,⋯,yn)P(y1)i=2∏nP(yi∣yi−1)i=1∏nP(xi∣yi)
隐马尔可夫模型由 三要素 决定
- 初始状态概率向量 π \pi π,(初始处于各个隐藏状态 y i y_i yi 的概率)
- 状态转移概率矩阵 A A A,(即式(1)中的 P ( y i ∣ y i − 1 ) P(y_i|y_{i-1}) P(yi∣yi−1) 的各种项构成的矩阵)
- 观测概率矩阵 B B B, (即式(2)中的 P ( x i ∣ y i ) P(x_i|y_i) P(xi∣yi) 的各种项构成的矩阵)
π \pi π 和 A A A 决定状态序列, B B B 决定观测序列。隐马尔可夫模型 λ \lambda λ 可以用三元符号表示, λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)
- 状态转移概率矩阵 A A A 与 初始状态概率向量 π \pi π 确定了隐藏的马尔可夫链,生成不可观测的状态序列。
- 观测概率矩阵 B B B 确定了如何从隐藏状态 y i y_i yi 生成观测 x i x_i xi,与状态序列综合确定了如何产生观测序列。
1.2 盒子和球模型
假设有4个盒子,每个盒子里都装有红、白两种颜色的球,盒子里的红、白球数由表列出。
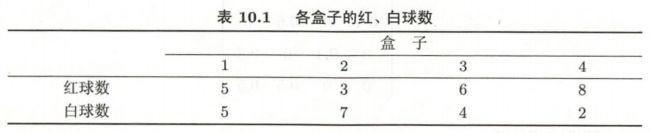
按下面的方法抽球,产生一个球的颜色的观测序列 X X X:
- 等概率随机选1个盒子,从这个盒子里随机抽出1个球,记录颜色,放回;
- 从当前盒子随机转移到下一个盒子,规则是:如果当前盒子是盒子1,那么下一盒子一定是盒子2;如果当前是盒子2或3,那么分别以概率0.4和0.6转移到左边或右边的盒子;如果当前是盒子4,那么各以0.5的概率停留在盒子4或转移到盒子3;
- 确定转移的盒子后,再从这个盒子里随机抽出1个球,记录颜色,放回;
- 重复5次,得到一个球的颜色的观测序列

- 各个隐含状态的初始概率 P ( y i ) P(y_i) P(yi) : π = ( 0.25 , 0.25 , 0.25 , 0.25 ) T \pi = (0.25,0.25,0.25,0.25)^T π=(0.25,0.25,0.25,0.25)T
- 各个隐含状态间的转移概率 P ( y i ∣ y i − 1 ) P(y_i|y_{i-1}) P(yi∣yi−1) : A = [ 0 1 0 0 0.4 0 0.6 0 0 0.4 0 0.6 0 0 0.5 0.5 ] A = \begin{bmatrix} 0 & 1 & 0 & 0 \\ 0.4 & 0 & 0.6 & 0 \\ 0 & 0.4 & 0 & 0.6 \\ 0 & 0 & 0.5 & 0.5 \\ \end{bmatrix} A=⎣⎢⎢⎡00.400100.4000.600.5000.60.5⎦⎥⎥⎤
- 观测(发射)概率 P ( x i ∣ y i ) P(x_i|y_i) P(xi∣yi): B = [ 0.5 0.5 0.3 0.7 0.6 0.4 0.8 0.2 ] B = \begin{bmatrix} 0.5 & 0.5 \\ 0.3 & 0.7 \\ 0.6 & 0.4 \\ 0.8 & 0.2 \\ \end{bmatrix} B=⎣⎢⎢⎡0.50.30.60.80.50.70.40.2⎦⎥⎥⎤
1.3 观测序列生成过程
- 输入:隐马模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π),观测序列长度 T T T (该例子为 5)
- 输出:观测序列 X = ( x 1 , x 2 , x 3 , x 4 , x 5 ) X = (x_1,x_2,x_3,x_4,x_5) X=(x1,x2,x3,x4,x5) , (红、白球)
- 跟据 π \pi π 随机产生一个 y i y_i yi 状态(盒子), 序列长度 t = 0
- 在 y i y_i yi 中,按照其观测概率 B B B 对应的行,产生一个观测序列 X X X 的元素 x i x_i xi(红球 or 白球),计数 t++
- 根据 y i y_i yi 的状态转移概率 A A A 对应的行,产生下一个状态 y i + 1 y_{i+1} yi+1 ,
while(t < T), 重复2,3步骤
1.4 HMM模型3个基本问题
- 概率计算问题:给定模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π) 和 观测序列 X = ( x 1 , x 2 . . . . . , x n ) X = (x_1,x_2.....,x_n) X=(x1,x2.....,xn), 计算在模型 λ \lambda λ 下,观测序列 X X X 出现的概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
- 学习问题:已知观测序列 X = ( x 1 , x 2 . . . . . , x n ) X = (x_1,x_2.....,x_n) X=(x1,x2.....,xn),估计模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π) 的参数,使得在该模型下,观测序列概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ) 最大。极大似然估计的方法估计参数
- 预测问题:也称解码(decoding)问题。已知模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π) 和 观测序列 X = ( x 1 , x 2 . . . . . , x n ) X = (x_1,x_2.....,x_n) X=(x1,x2.....,xn),求对给定观测序列条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X) 最大的状态序列 Y = ( y 1 , y 2 . . . . . . , y n ) Y = (y_1,y_2......,y_n) Y=(y1,y2......,yn)。即给定观测序列 X X X,求最有可能的对应隐含状态序列 Y Y Y
2. 概率计算问题
给定模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π) 和 观测序列 X = ( x 1 , x 2 . . . . . , x n ) X = (x_1,x_2.....,x_n) X=(x1,x2.....,xn), 计算在模型 λ \lambda λ 下,观测序列 X X X 出现的概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
2.1 直接计算法
- 列举所有的长度为 T T T 的状态序列 Y = ( y 1 , y 2 . . . . . . , y t ) Y = (y_1,y_2......,y_t) Y=(y1,y2......,yt)
- 求 各个 状态序列 Y Y Y 与 观测序列 X = ( x 1 , x 2 . . . . . , x t ) X = (x_1,x_2.....,x_t) X=(x1,x2.....,xt) 的联合概率 P ( X Y ∣ λ ) P(XY|\lambda) P(XY∣λ)
- 然后对上面所有的状态序列求和 Σ \Sigma Σ,得到 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
- 状态序列 Y = ( y 1 , y 2 . . . . . . , y t ) Y = (y_1,y_2......,y_t) Y=(y1,y2......,yt) 的概率是: P ( Y ∣ λ ) = π y 1 A y 1 , y 2 A y 2 , y 3 . . . . . . A y t − 1 , y t P(Y|\lambda)=\pi_{y_1}A_{y_1,y_2}A_{y_2,y_3}......A_{y_{t-1},y_t} P(Y∣λ)=πy1Ay1,y2Ay2,y3......Ayt−1,yt
- 对固定的状态序列 Y = ( y 1 , y 2 . . . . . . , y t ) Y = (y_1,y_2......,y_t) Y=(y1,y2......,yt) ,观测序列 X = ( x 1 , x 2 . . . . . , x t ) X = (x_1,x_2.....,x_t) X=(x1,x2.....,xt) 的概率是: P ( X ∣ Y , λ ) = B y 1 , x 1 B y 2 , x 2 . . . . . . B y t , x t P(X|Y,\lambda)=B_{y_1,x_1}B_{y_2,x_2}......B_{y_t,x_t} P(X∣Y,λ)=By1,x1By2,x2......Byt,xt
- X , Y X,Y X,Y 同时出现的联合概率为: P ( X Y ∣ λ ) = P ( X ∣ Y , λ ) P ( Y ∣ λ ) = π y 1 B y 1 , x 1 A y 1 , y 2 B y 2 , x 2 . . . . . . A y t − 1 , y t B y t , x t P(XY|\lambda)=P(X|Y,\lambda)P(Y|\lambda)=\pi_{y_1}B_{y_1,x_1}A_{y_1,y_2}B_{y_2,x_2}......A_{y_{t-1},y_t}B_{y_t,x_t} P(XY∣λ)=P(X∣Y,λ)P(Y∣λ)=πy1By1,x1Ay1,y2By2,x2......Ayt−1,ytByt,xt
- 对上式在所有可能的状态序列 Y i Y_i Yi 的情况下求和 Σ \Sigma Σ,即可得到 P ( X ∣ λ ) = ∑ Y 1 Y n P ( X ∣ Y , λ ) P ( Y ∣ λ ) P(X|\lambda)=\sum_{Y_1}^{Y_n} P(X|Y,\lambda)P(Y|\lambda) P(X∣λ)=∑Y1YnP(X∣Y,λ)P(Y∣λ)
但是上面计算量很大,复杂度 O ( T N T ) O(TN^T) O(TNT),不可行
2.2 前向算法
-
前向概率 概念:
给定HMM模型 λ \lambda λ,定义到时刻 t 部分观测序列 X p a r t = ( x 1 , x 2 . . . . . , x t ) X_{part} = (x_1,x_2.....,x_t) Xpart=(x1,x2.....,xt) 且 t 时刻的状态 y t y_t yt 为 q i q_i qi 的概率为前向概率,记为: a t ( i ) = P ( x 1 , x 2 , . . . , x t , y t = q i ∣ λ ) a_t(i)=P(x_1,x_2,...,x_t,y_t=q_i | \lambda) at(i)=P(x1,x2,...,xt,yt=qi∣λ) -
递推求解 前向概率 a t ( i ) a_t(i) at(i) 及 观测序列概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
输入:给定HMM模型 λ \lambda λ, 观测序列 X X X
输出:观测序列概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
- 初值: a 1 ( i ) = π i B i , x 1 i = 1 , 2 , . . . , N a_1(i) = \pi_iB_{i,x_1}\quad\quad i = 1,2,...,N a1(i)=πiBi,x1i=1,2,...,N , N N N 为盒子个数
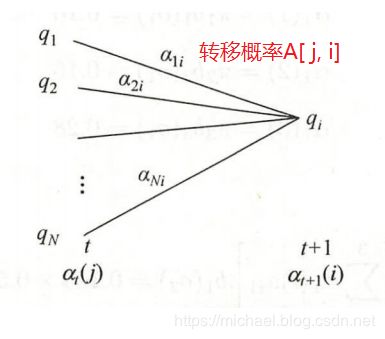
- 递推:对 t = 1 , 2 , . . . , T − 1 t=1,2,...,T-1 t=1,2,...,T−1, a t + 1 ( i ) = [ ∑ j = 1 N a t ( j ) A j , i ] B i , x t + 1 i = 1 , 2 , . . . , N a_{t+1}(i)= \begin{bmatrix} \sum_{j=1}^N a_t(j)A_{j,i} \end{bmatrix}B_{i,x_{t+1}}\quad i = 1,2,...,N at+1(i)=[∑j=1Nat(j)Aj,i]Bi,xt+1i=1,2,...,N
- 终止: P ( X ∣ λ ) = ∑ i = 1 N a T ( i ) P(X|\lambda) = \sum_{i=1}^N a_T(i) P(X∣λ)=∑i=1NaT(i)(看前向概率定义,全概率公式)
算法解释:
-
初始时刻 t = 1 t=1 t=1,观测到的是 x 1 x_1 x1, 可能的状态是盒子的编号 i = 1 , 2 , . . . , N i = 1,2,...,N i=1,2,...,N,概率为 π i \pi_i πi,在 i i i 盒子发射出 x 1 x_1 x1 颜色球的概率为 B i , x 1 B_{i,x_1} Bi,x1,所以 a 1 ( i ) = π i B i , x 1 a_1(i) = \pi_iB_{i,x_1} a1(i)=πiBi,x1
-
递推:上一时刻 t t t 的 N 种情况下 都可能转移到 t + 1 t+1 t+1 时的 q i q_i qi 状态,对应的前向概率乘以转移概率,并求和,得到 状态 q i q_i qi 的概率,再乘以发射概率 B i , x t + 1 B_{i,x_{t+1}} Bi,xt+1,就是 t + 1 t+1 t+1 时的前向概率
-
最后一个时刻 T T T 时的所有前向概率求和就是 P ( X ∣ λ ) = ∑ i = 1 N a T ( i ) P(X|\lambda) = \sum_{i=1}^N a_T(i) P(X∣λ)=∑i=1NaT(i)
-
前向算法是基于路径的, t + 1 t+1 t+1 时刻,直接用 t t t 时刻的结果,时间复杂度 O ( T N 2 ) O(TN^2) O(TN2)

2.2.1 前向公式证明
首先有公式联合概率 P ( A B C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A B ) P(ABC) = P(A)P(B|A)P(C|AB) P(ABC)=P(A)P(B∣A)P(C∣AB),对任意多个项都成立
递推公式证明:
a t ( j ) A j , i = P ( x 1 , x 2 , . . . , x t , y t = q j ∣ λ ) P ( y t + 1 = q i ∣ y t = q j , λ ) = P ( x 1 , x 2 , . . . , x t ∣ y t = q j , λ ) P ( y t = q j ∣ λ ) P ( y t + 1 = q i ∣ y t = q j , λ ) = P ( x 1 , x 2 , . . . , x t ∣ y t = q j , y t + 1 = q i , λ ) P ( y t = q j , y t + 1 = q i ∣ λ ) = P ( x 1 , x 2 , . . . , x t , y t = q j , y t + 1 = q i ∣ λ ) { ∑ j = 1 N a t ( j ) A j , i } B i , x t + 1 = P ( x 1 , x 2 , . . . , x t , y t + 1 = q i ∣ λ ) P ( x t + 1 ∣ y t + 1 = q i , λ ) = P ( x 1 , x 2 , . . . , x t ∣ y t + 1 = q i , λ ) P ( y t + 1 = q i ∣ λ ) P ( x t + 1 ∣ y t + 1 = q i , λ ) = P ( x 1 , x 2 , . . . , x t ∣ y t + 1 = q i , x t + 1 , λ ) P ( x t + 1 , y t + 1 = q i ∣ λ ) = P ( x 1 , x 2 , . . . , x t , x t + 1 , y t + 1 = q i ∣ λ ) = a t + 1 ( i ) \begin{aligned} a_t(j)A_{j,i} &= P(x_1,x_2,...,x_t,y_t=q_j|\lambda)P(y_{t+1}=q_i|y_t=q_j,\lambda)\\ &={\color{red}P(x_1,x_2,...,x_t|y_t=q_j,\lambda)}P(y_t=q_j|\lambda)P(y_{t+1}=q_i|y_t=q_j,\lambda)\\ &= {\color{red}P(x_1,x_2,...,x_t|y_t=q_j,{\color{blue}y_{t+1}=q_i},\lambda)}P(y_t=q_j,y_{t+1}=q_i|\lambda)\\ &=P(x_1,x_2,...,x_t,y_t=q_j,y_{t+1}=q_i|\lambda)\\ \{\sum_{j=1}^N a_t(j)A_{j,i}\} B_{i,x_{t+1}} &= P(x_1,x_2,...,x_t,y_{t+1}=q_i|\lambda)P(x_{t+1}|y_{t+1}=q_i,\lambda)\\ &={\color{red}P(x_1,x_2,...,x_t|y_{t+1}=q_i,\lambda)}P(y_{t+1}=q_i|\lambda)P(x_{t+1}|y_{t+1}=q_i,\lambda)\\ &={\color{red}P(x_1,x_2,...,x_t|y_{t+1}=q_i,{\color{blue}x_{t+1}},\lambda)}P(x_{t+1},y_{t+1}=q_i|\lambda)\\ &=P(x_1,x_2,...,x_t,x_{t+1},y_{t+1}=q_i|\lambda)=a_{t+1}(i) \end{aligned} at(j)Aj,i{j=1∑Nat(j)Aj,i}Bi,xt+1=P(x1,x2,...,xt,yt=qj∣λ)P(yt+1=qi∣yt=qj,λ)=P(x1,x2,...,xt∣yt=qj,λ)P(yt=qj∣λ)P(yt+1=qi∣yt=qj,λ)=P(x1,x2,...,xt∣yt=qj,yt+1=qi,λ)P(yt=qj,yt+1=qi∣λ)=P(x1,x2,...,xt,yt=qj,yt+1=qi∣λ)=P(x1,x2,...,xt,yt+1=qi∣λ)P(xt+1∣yt+1=qi,λ)=P(x1,x2,...,xt∣yt+1=qi,λ)P(yt+1=qi∣λ)P(xt+1∣yt+1=qi,λ)=P(x1,x2,...,xt∣yt+1=qi,xt+1,λ)P(xt+1,yt+1=qi∣λ)=P(x1,x2,...,xt,xt+1,yt+1=qi∣λ)=at+1(i)
第一个蓝色处:前 t t t 个观测序列,显然跟 t + 1 t+1 t+1 时刻的状态 y t + 1 y_{t+1} yt+1无关,第二个蓝色处:观测独立性
终止公式证明(全概率公式):
∑ i = 1 N a T ( i ) = P ( x 1 , x 2 , . . . , x T , y T = q 1 ∣ λ ) + P ( x 1 , x 2 , . . . , x T , y T = q 2 ∣ λ ) + P ( x 1 , x 2 , . . . , x T , y T = q N ∣ λ ) = P ( x 1 , x 2 , . . . , x T ∣ λ ) = P ( X ∣ λ ) \begin{aligned} \sum_{i=1}^N a_T(i)&=P(x_1,x_2,...,x_T,y_T=q_1|\lambda)+P(x_1,x_2,...,x_T,y_T=q_2|\lambda)+P(x_1,x_2,...,x_T,y_T=q_N|\lambda)\\ &= P(x_1,x_2,...,x_T|\lambda)=P(X|\lambda) \end{aligned} i=1∑NaT(i)=P(x1,x2,...,xT,yT=q1∣λ)+P(x1,x2,...,xT,yT=q2∣λ)+P(x1,x2,...,xT,yT=qN∣λ)=P(x1,x2,...,xT∣λ)=P(X∣λ)
2.2.2 盒子和球例子
考虑盒子和球模型 λ = ( A , B , π ) \lambda = (A,B,\pi) λ=(A,B,π),状态集合(盒子的编号) Q = { 1 , 2 , 3 } Q=\{1,2,3\} Q={1,2,3},观测集合 V = { 红 , 白 } V=\{红,白\} V={红,白}
π = [ 0.2 0.4 0.4 ] , A = [ 0.5 0.2 0.3 0.3 0.5 0.2 0.2 0.3 0.5 ] , B = [ 0.5 0.5 0.4 0.6 0.7 0.3 ] \pi=\begin{bmatrix} 0.2 \\ 0.4 \\ 0.4 \\ \end{bmatrix}, A = \begin{bmatrix} 0.5 & 0.2 & 0.3 \\ 0.3 & 0.5 & 0.2 \\ 0.2 & 0.3 & 0.5 \\ \end{bmatrix}, B = \begin{bmatrix} 0.5 & 0.5 \\ 0.4 & 0.6 \\ 0.7 & 0.3 \\ \end{bmatrix} π=⎣⎡0.20.40.4⎦⎤,A=⎣⎡0.50.30.20.20.50.30.30.20.5⎦⎤,B=⎣⎡0.50.40.70.50.60.3⎦⎤
设总的时间长度 T = 3 T=3 T=3, 观测序列 X = ( 红 , 白 , 红 ) X=(红,白,红) X=(红,白,红),用前向算法计算 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
解 :
-
计算前向概率初值: a 1 ( i ) = π i B i , x 1 a_1(i) = \pi_iB_{i,x_1} a1(i)=πiBi,x1
a 1 ( 1 ) = π 1 B 1 , 1 = 0.2 ∗ 0.5 = 0.10 a_1(1) = \pi_1B_{1,1}=0.2*0.5=0.10 a1(1)=π1B1,1=0.2∗0.5=0.10,(1号盒子,时刻1摸出红色(第一列)的概率)
a 1 ( 2 ) = π 2 B 2 , 1 = 0.4 ∗ 0.4 = 0.16 a_1(2) = \pi_2B_{2,1}=0.4*0.4=0.16 a1(2)=π2B2,1=0.4∗0.4=0.16,(2号盒子,时刻1摸出红色的概率)
a 1 ( 3 ) = π 3 B 3 , 1 = 0.4 ∗ 0.7 = 0.28 a_1(3) = \pi_3B_{3,1}=0.4*0.7=0.28 a1(3)=π3B3,1=0.4∗0.7=0.28,(3号盒子,时刻1摸出红色的概率) -
递推计算:对 t = 1 , 2 , . . . , T − 1 t=1,2,...,T-1 t=1,2,...,T−1, a t + 1 ( i ) = [ ∑ j = 1 N a t ( j ) A j , i ] B i , x t + 1 i = 1 , 2 , . . . , N a_{t+1}(i)= \begin{bmatrix} \sum_{j=1}^N a_t(j)A_{j,i} \end{bmatrix}B_{i,x_{t+1}}\quad i = 1,2,...,N at+1(i)=[∑j=1Nat(j)Aj,i]Bi,xt+1i=1,2,...,N
a 2 ( 1 ) = { ∑ j = 1 3 a 1 ( j ) A j , 1 } B 1 , 2 = ( 0.10 ∗ 0.5 + 0.16 ∗ 0.3 + 0.28 ∗ 0.2 ) ∗ 0.5 = 0.077 a_2(1)=\{ \sum_{j=1}^3 a_1(j)A_{j,1} \} B_{1,2}=(0.10*0.5+0.16*0.3+0.28*0.2)*0.5=0.077 a2(1)={∑j=13a1(j)Aj,1}B1,2=(0.10∗0.5+0.16∗0.3+0.28∗0.2)∗0.5=0.077
(时刻2时,从1号盒子摸出白色的概率)
a 2 ( 2 ) = { ∑ j = 1 3 a 1 ( j ) A j , 2 } B 2 , 2 = ( 0.10 ∗ 0.2 + 0.16 ∗ 0.5 + 0.28 ∗ 0.3 ) ∗ 0.6 = 0.1104 a_2(2)=\{ \sum_{j=1}^3 a_1(j)A_{j,2} \} B_{2,2}=(0.10*0.2+0.16*0.5+0.28*0.3)*0.6=0.1104 a2(2)={∑j=13a1(j)Aj,2}B2,2=(0.10∗0.2+0.16∗0.5+0.28∗0.3)∗0.6=0.1104
(时刻2时,从2号盒子摸出白色的概率)
a 2 ( 3 ) = { ∑ j = 1 3 a 1 ( j ) A j , 3 } B 3 , 2 = ( 0.10 ∗ 0.3 + 0.16 ∗ 0.2 + 0.28 ∗ 0.5 ) ∗ 0.3 = 0.0606 a_2(3)=\{ \sum_{j=1}^3 a_1(j)A_{j,3} \} B_{3,2}=(0.10*0.3+0.16*0.2+0.28*0.5)*0.3=0.0606 a2(3)={∑j=13a1(j)Aj,3}B3,2=(0.10∗0.3+0.16∗0.2+0.28∗0.5)∗0.3=0.0606
(时刻2时,从3号盒子摸出白色的概率)
a 3 ( 1 ) = { ∑ j = 1 3 a 2 ( j ) A j , 1 } B 1 , 1 = ( 0.077 ∗ 0.5 + 0.1104 ∗ 0.3 + 0.0606 ∗ 0.2 ) ∗ 0.5 = 0.04187 a_3(1)=\{ \sum_{j=1}^3 a_2(j)A_{j,1} \} B_{1,1}=(0.077*0.5+0.1104*0.3+0.0606*0.2)*0.5=0.04187 a3(1)={∑j=13a2(j)Aj,1}B1,1=(0.077∗0.5+0.1104∗0.3+0.0606∗0.2)∗0.5=0.04187
(时刻3时,从1号盒子摸出红色的概率)
a 3 ( 2 ) = { ∑ j = 1 3 a 2 ( j ) A j , 2 } B 2 , 1 = ( 0.077 ∗ 0.2 + 0.1104 ∗ 0.5 + 0.0606 ∗ 0.3 ) ∗ 0.4 = 0.035512 a_3(2)=\{ \sum_{j=1}^3 a_2(j)A_{j,2} \} B_{2,1}=(0.077*0.2+0.1104*0.5+0.0606*0.3)*0.4=0.035512 a3(2)={∑j=13a2(j)Aj,2}B2,1=(0.077∗0.2+0.1104∗0.5+0.0606∗0.3)∗0.4=0.035512
(时刻3时,从2号盒子摸出红色的概率)
a 3 ( 3 ) = { ∑ j = 1 3 a 2 ( j ) A j , 3 } B 3 , 1 = ( 0.077 ∗ 0.3 + 0.1104 ∗ 0.2 + 0.0606 ∗ 0.5 ) ∗ 0.7 = 0.052836 a_3(3)=\{ \sum_{j=1}^3 a_2(j)A_{j,3} \} B_{3,1}=(0.077*0.3+0.1104*0.2+0.0606*0.5)*0.7=0.052836 a3(3)={∑j=13a2(j)Aj,3}B3,1=(0.077∗0.3+0.1104∗0.2+0.0606∗0.5)∗0.7=0.052836
(时刻3时,从3号盒子摸出红色的概率)
- 终止: P ( X ∣ λ ) = ∑ i = 1 N a T ( i ) = ∑ i = 1 3 a 3 ( i ) = 0.04187 + 0.035512 + 0.052836 = 0.130218 P(X|\lambda) = \sum_{i=1}^N a_T(i) = \sum_{i=1}^3 a_3(i)=0.04187+0.035512+0.052836=0.130218 P(X∣λ)=∑i=1NaT(i)=∑i=13a3(i)=0.04187+0.035512+0.052836=0.130218
2.2.3 前向算法Python代码
- 借鉴他人代码,手敲一遍并理解
# -*- coding:utf-8 -*-
# python3.7
# @Time: 2019/12/17 22:33
# @Author: Michael Ming
# @Website: https://michael.blog.csdn.net/
# @File: hiddenMarkov.py
import numpy as np
class HiddenMarkov:
def forward(self, Q, V, A, B, X, PI): # 前向算法
N = len(Q) # 隐藏状态数量
M = len(X) # 观测序列大小
alphas = np.zeros((N, M)) # 前向概率 alphas 矩阵
T = M # 时刻长度,即观测序列长度
for t in range(T): # 遍历每个时刻,计算前向概率 alphas
indexOfXi = V.index(X[t]) # 观测值Xi对应的V中的索引
for i in range(N): # 对每个状态进行遍历
if t == 0: # 计算初值
alphas[i][t] = PI[t][i] * B[i][indexOfXi] # a1(i)=πi B(i,x1)
print("alphas1(%d)=p%dB%d(x1)=%f" %(i,i,i,alphas[i][t]))
else:
alphas[i][t] = np.dot(
[alpha[t-1] for alpha in alphas], # 取的alphas的t-1列
[a[i] for a in A]) *B[i][indexOfXi] # 递推公式
print("alpha%d(%d)=[sigma alpha%d(i)ai%d]B%d(x%d)=%f"
%(t, i, t-1, i, i, t, alphas[i][t]))
print(alphas)
P = sum(alpha[M-1] for alpha in alphas) # 最后一列概率的和
print("P=%f" % P)
Q = [1, 2, 3]
V = ['红', '白']
A = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]
B = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]
# X = ['红', '白', '红', '红', '白', '红', '白', '白']
X = ['红', '白', '红'] # 书上的例子
PI = [[0.2, 0.4, 0.4]]
hmm = HiddenMarkov()
hmm.forward(Q, V, A, B, X, PI)
关于numpy的一些操作:
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> b
array([[ 7, 8],
[ 9, 10],
[11, 12]])
>>> np.dot(a[0],[B[1] for B in b])
64
>>> np.dot([A[0] for A in a],[B[1] for B in b])
132
>>> np.multiply(a[0],[B[1] for B in b])
array([ 8, 20, 36])
>>> np.multiply([A[0] for A in a],[B[1] for B in b])
array([ 8, 40, 84])
运行结果:(跟上面计算一致)
alphas1(0)=p0B0(x1)=0.100000
alphas1(1)=p1B1(x1)=0.160000
alphas1(2)=p2B2(x1)=0.280000
alpha1(0)=[sigma alpha0(i)ai0]B0(x1)=0.077000
[[0.1 0.077 0. ]
[0.16 0. 0. ]
[0.28 0. 0. ]]
alpha1(1)=[sigma alpha0(i)ai1]B1(x1)=0.110400
[[0.1 0.077 0. ]
[0.16 0.1104 0. ]
[0.28 0. 0. ]]
alpha1(2)=[sigma alpha0(i)ai2]B2(x1)=0.060600
[[0.1 0.077 0. ]
[0.16 0.1104 0. ]
[0.28 0.0606 0. ]]
alpha2(0)=[sigma alpha1(i)ai0]B0(x2)=0.041870
[[0.1 0.077 0.04187]
[0.16 0.1104 0. ]
[0.28 0.0606 0. ]]
alpha2(1)=[sigma alpha1(i)ai1]B1(x2)=0.035512
[[0.1 0.077 0.04187 ]
[0.16 0.1104 0.035512]
[0.28 0.0606 0. ]]
alpha2(2)=[sigma alpha1(i)ai2]B2(x2)=0.052836
[[0.1 0.077 0.04187 ]
[0.16 0.1104 0.035512]
[0.28 0.0606 0.052836]]
P=0.130218
2.3 后向算法
-
后向概率 概念:
给定HMM模型 λ \lambda λ,定义到时刻 t t t 状态 y t y_t yt 为 q i q_i qi 的条件下,从 t + 1 t+1 t+1 到 T T T 的部分观测序列 X p a r t = ( x t + 1 , x t + 2 . . . . . , x T ) X_{part} = (x_{t+1},x_{t+2}.....,x_T) Xpart=(xt+1,xt+2.....,xT) 的概率为后向概率,记为: β t ( i ) = P ( x t + 1 , x t + 2 . . . . . , x T ∣ y t = q i , λ ) \beta_t(i)=P(x_{t+1},x_{t+2}.....,x_T|y_t=q_i , \lambda) βt(i)=P(xt+1,xt+2.....,xT∣yt=qi,λ) -
递推求解 后向概率 β t ( i ) \beta_t(i) βt(i) 及 观测序列概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
输入:给定HMM模型 λ \lambda λ, 观测序列 X X X
输出:观测序列概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ)
- 初值: β T ( i ) = 1 i = 1 , 2 , . . . , N \beta_T(i) = 1\quad\quad i = 1,2,...,N βT(i)=1i=1,2,...,N , N N N 为盒子个数
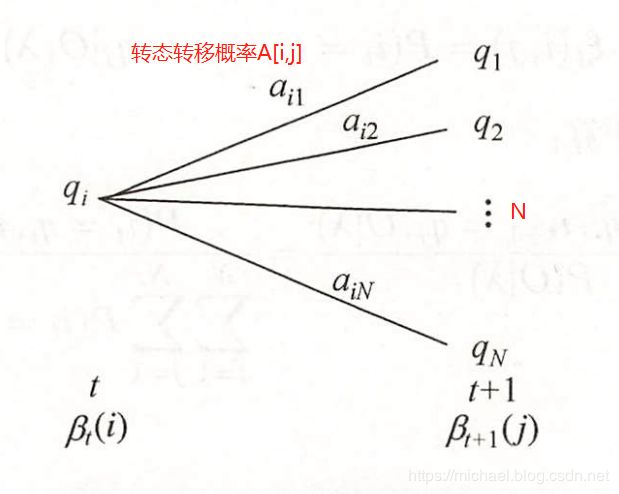
- 递推:对 t = T − 1 , T − 2 , . . . , 1 t=T-1,T-2,...,1 t=T−1,T−2,...,1, β t ( i ) = ∑ j = 1 N A i , j B j , x t + 1 β t + 1 ( j ) i = 1 , 2 , . . . , N \beta_{t}(i)=\sum_{j=1}^N A_{i,j}B_{j,x_{t+1}}\beta_{t+1}(j)\quad i = 1,2,...,N βt(i)=∑j=1NAi,jBj,xt+1βt+1(j)i=1,2,...,N
- 终止: P ( X ∣ λ ) = ∑ i = 1 N π i B i , x 1 β 1 ( i ) P(X|\lambda) = \sum_{i=1}^N \pi_iB_{i,x_1}\beta_1(i) P(X∣λ)=∑i=1NπiBi,x1β1(i)
算法解释:
2.3.1 后向公式证明
递推公式证明:
∑ j = 1 N A i , j B j , x t + 1 β t + 1 ( j ) = ∑ j = 1 N A i , j P ( x t + 1 ∣ y t + 1 = q j , λ ) P ( x t + 2 , . . . , x T ∣ y t + 1 = q j , λ ) = ∑ j = 1 N A i , j P ( x t + 1 ∣ x t + 2 , . . . , x T , y t + 1 = q j , λ ) P ( x t + 2 , . . . , x T ∣ y t + 1 = q j , λ ) = ∑ j = 1 N A i , j P ( x t + 1 , x t + 2 , . . . , x T ∣ y t + 1 = q j , λ ) = ∑ j = 1 N A i , j P ( x t + 1 , x t + 2 , . . . , x T ∣ y t + 1 = q j , y t = q i , λ ) = ∑ j = 1 N P ( y t + 1 = q j ∣ y t = q i , λ ) P ( x t + 1 , x t + 2 , . . . , x T ∣ y t + 1 = q j , y t = q i , λ ) = ∑ j = 1 N P ( x t + 1 , x t + 2 , . . . , x T , y t + 1 = q j ∣ y t = q i , λ ) = P ( x t + 1 , x t + 2 , . . . , x T ∣ y t = q i , λ ) = β t ( i ) \begin{aligned} \sum_{j=1}^N A_{i,j}B_{j,x_{t+1}}\beta_{t+1}(j) &= \sum_{j=1}^N A_{i,j}{\color{red}P(x_{t+1}|y_{t+1}=q_j,\lambda)}P(x_{t+2},...,x_T|y_{t+1}=q_j,\lambda)\\ &= \sum_{j=1}^N A_{i,j}{\color{red}P(x_{t+1}|{\color{blue}x_{t+2},...,x_T},y_{t+1}=q_j,\lambda)}P(x_{t+2},...,x_T|y_{t+1}=q_j,\lambda)\\ &= \sum_{j=1}^N A_{i,j}P(x_{t+1},x_{t+2},...,x_T|{\color{red}y_{t+1}=q_j},\lambda)\\ &= \sum_{j=1}^N A_{i,j}P(x_{t+1},x_{t+2},...,x_T|{\color{red}y_{t+1}=q_j},{\color{blue}y_t=q_i},\lambda)\\ &= \sum_{j=1}^N P(y_{t+1}=q_j|y_t=q_i,\lambda)P(x_{t+1},x_{t+2},...,x_T|{\color{red}y_{t+1}=q_j},{\color{blue}y_t=q_i},\lambda)\\ &= \sum_{j=1}^N P(x_{t+1},x_{t+2},...,x_T,{\color{red}y_{t+1}=q_j}|{\color{blue}y_t=q_i},\lambda)\\ &= P(x_{t+1},x_{t+2},...,x_T|{\color{blue}y_t=q_i},\lambda)=\beta_{t}(i)\\ \end{aligned}\\ j=1∑NAi,jBj,xt+1βt+1(j)=j=1∑NAi,jP(xt+1∣yt+1=qj,λ)P(xt+2,...,xT∣yt+1=qj,λ)=j=1∑NAi,jP(xt+1∣xt+2,...,xT,yt+1=qj,λ)P(xt+2,...,xT∣yt+1=qj,λ)=j=1∑NAi,jP(xt+1,xt+2,...,xT∣yt+1=qj,λ)=j=1∑NAi,jP(xt+1,xt+2,...,xT∣yt+1=qj,yt=qi,λ)=j=1∑NP(yt+1=qj∣yt=qi,λ)P(xt+1,xt+2,...,xT∣yt+1=qj,yt=qi,λ)=j=1∑NP(xt+1,xt+2,...,xT,yt+1=qj∣yt=qi,λ)=P(xt+1,xt+2,...,xT∣yt=qi,λ)=βt(i)
第一个蓝色处:观测独立性;第二个蓝色处:观测独立性( x t + 1 , . . . x T x_{t+1},...x_T xt+1,...xT都与 y t y_t yt无关)
终止公式证明:
π i B i , x 1 β 1 ( i ) = P ( y 1 = q i ∣ λ ) P ( x 1 ∣ y 1 = q i , λ ) P ( x 2 , x 3 , . . . , x T ∣ y 1 = q i , λ ) = P ( x 1 , y 1 = q i ∣ λ ) P ( x 2 , x 3 , . . . , x T ∣ x 1 , y 1 = q i , λ ) = P ( x 1 , x 2 , . . . , x T , y 1 = q i ∣ λ ) ∑ i = 1 N π i B i , x 1 β 1 ( i ) = ∑ i = 1 N P ( x 1 , x 2 , . . . , x T , y 1 = q i ∣ λ ) = P ( x 1 , x 2 , . . . , x T ∣ λ ) = P ( X ∣ λ ) \begin{aligned} \pi_iB_{i,x_1}\beta_1(i)&=P(y_1=q_i|\lambda)P(x_1|y_1=q_i,\lambda)\color{red}P(x_2,x_3,...,x_T|y_1=q_i,\lambda)\\ &=P(x_1,y_1=q_i|\lambda)\color{red}P(x_2,x_3,...,x_T|{\color{blue}{x_1}},y_1=q_i,\lambda)\\ &=P(x_1,x_2,...,x_T,y_1=q_i|\lambda)\\ \sum_{i=1}^N \pi_iB_{i,x_1}\beta_1(i) &= \sum_{i=1}^N P(x_1,x_2,...,x_T,y_1=q_i|\lambda)=P(x_1,x_2,...,x_T|\lambda)=P(X|\lambda)\\ \end{aligned} πiBi,x1β1(i)i=1∑NπiBi,x1β1(i)=P(y1=qi∣λ)P(x1∣y1=qi,λ)P(x2,x3,...,xT∣y1=qi,λ)=P(x1,y1=qi∣λ)P(x2,x3,...,xT∣x1,y1=qi,λ)=P(x1,x2,...,xT,y1=qi∣λ)=i=1∑NP(x1,x2,...,xT,y1=qi∣λ)=P(x1,x2,...,xT∣λ)=P(X∣λ)
利用 前向 和 后向 概率的定义,可以将观测序列概率 P ( X ∣ λ ) P(X|\lambda) P(X∣λ) 写成:
P ( X ∣ λ ) = ∑ i = 1 N ∑ j = 1 N α t ( i ) A i , j B j , x t + 1 β t + 1 ( j ) , t = 1 , 2 , . . . , T − 1 P(X|\lambda)=\sum_{i=1}^N\sum_{j=1}^N \alpha_t(i)A_{i,j}B_{j,x_{t+1}}\beta_{t+1}(j),\quad t= 1,2,...,T-1 P(X∣λ)=∑i=1N∑j=1Nαt(i)Ai,jBj,xt+1βt+1(j),t=1,2,...,T−1
证明如下:
∑ i = 1 N ∑ j = 1 N α t ( i ) A i , j B j , x t + 1 β t + 1 ( j ) = ∑ i = 1 N ∑ j = 1 N P ( x 1 , x 2 , . . . , x t , y t = q i ∣ λ ) P ( y t + 1 = q j ∣ y t = q i , λ ) ∗ P ( x t + 1 ∣ y t + 1 = q j , λ ) P ( x t + 2 , x t + 3 , . . . , x T ∣ y t + 1 = q j , λ ) = ∑ i = 1 N ∑ j = 1 N P ( x 1 , x 2 , . . . , x t ∣ y t = q i , λ ) P ( y t = q i ∣ λ ) P ( y t + 1 = q j ∣ y t = q i , λ ) ∗ P ( x t + 1 ∣ x t + 2 , x t + 3 , . . . , x T , y t + 1 = q j , λ ) P ( x t + 2 , x t + 3 , . . . , x T ∣ y t + 1 = q j , λ ) = ∑ i = 1 N ∑ j = 1 N P ( x 1 , x 2 , . . . , x t ∣ y t = q i , y t + 1 = q j , λ ) P ( y t = q i ∣ λ ) P ( y t + 1 = q j ∣ y t = q i , λ ) ∗ P ( x t + 1 ∣ x t + 2 , x t + 3 , . . . , x T , y t + 1 = q j , λ ) P ( x t + 2 , x t + 3 , . . . , x T ∣ y t + 1 = q j , λ ) = ∑ i = 1 N ∑ j = 1 N P ( x 1 , x 2 , . . . , x t ∣ y t = q i , y t + 1 = q j , λ ) P ( y t = q i ∣ λ ) P ( y t + 1 = q j ∣ y t = q i , λ ) ∗ P ( x t + 1 , x t + 2 , x t + 3 , . . . , x T ∣ y t + 1 = q j , λ ) = ∑ i = 1 N ∑ j = 1 N P ( x 1 , x 2 , . . . , x t , y t + 1 = q j ∣ y t = q i , λ ) P ( y t = q i ∣ λ ) ∗ P ( x t + 1 , x t + 2 , x t + 3 , . . . , x T ∣ x 1 , x 2 , . . . , x t , y t + 1 = q j , y t = q i , λ ) = ∑ i = 1 N ∑ j = 1 N P ( y t = q i ∣ λ ) P ( x 1 , x 2 , . . . , x t , y t + 1 = q j ∣ y t = q i , λ ) ∗ P ( x t + 1 , x t + 2 , x t + 3 , . . . , x T ∣ x 1 , x 2 , . . . , x t , y t + 1 = q j , y t = q i , λ ) = ∑ i = 1 N ∑ j = 1 N P ( y t = q i ∣ λ ) P ( x 1 , x 2 , . . . , x t , y t + 1 = q j , x t + 1 , x t + 2 , x t + 3 , . . . , x T ∣ y t = q i , λ ) = ∑ i = 1 N P ( y t = q i ∣ λ ) P ( x 1 , x 2 , . . . , x t , x t + 1 , x t + 2 , x t + 3 , . . . , x T ∣ y t = q i , λ ) = ∑ i = 1 N P ( x 1 , x 2 , . . . , x t , x t + 1 , x t + 2 , x t + 3 , . . . , x T , y t = q i ∣ λ ) = P ( x 1 , x 2 , . . . , x T ∣ λ ) = P ( X ∣ λ ) \begin{aligned} \sum_{i=1}^N\sum_{j=1}^N \alpha_t(i)A_{i,j}B_{j,x_{t+1}}\beta_{t+1}(j) &= \sum_{i=1}^N\sum_{j=1}^N P(x_1,x_2,...,x_t,y_t=q_i|\lambda)P(y_{t+1}=q_j|y_t=q_i,\lambda)\\&\quad\quad\quad\quad\quad*P(x_{t+1}|y_{t+1}=q_j,\lambda)P(x_{t+2},x_{t+3},...,x_T|y_{t+1}=q_j,\lambda)\\ &= \sum_{i=1}^N\sum_{j=1}^N P(x_1,x_2,...,x_t|y_t=q_i,\lambda)P(y_t=q_i|\lambda)P(y_{t+1}=q_j|y_t=q_i,\lambda)\\&\quad\quad\quad\quad\quad*P(x_{t+1}|{\color{red}x_{t+2},x_{t+3},...,x_{T}},y_{t+1}=q_j,\lambda)P(x_{t+2},x_{t+3},...,x_T|y_{t+1}=q_j,\lambda)\\ &= \sum_{i=1}^N\sum_{j=1}^N P(x_1,x_2,...,x_t|y_t=q_i,{\color{blue}y_{t+1}=q_j},\lambda)P(y_t=q_i|\lambda)P(y_{t+1}=q_j|y_t=q_i,\lambda)\\&\quad\quad\quad\quad\quad*P(x_{t+1}|{x_{t+2},x_{t+3},...,x_{T}},y_{t+1}=q_j,\lambda)P(x_{t+2},x_{t+3},...,x_T|y_{t+1}=q_j,\lambda)\\ &= \sum_{i=1}^N\sum_{j=1}^N P(x_1,x_2,...,x_t|y_t=q_i,{\color{blue}y_{t+1}=q_j},\lambda)P(y_t=q_i|\lambda)P(y_{t+1}=q_j|y_t=q_i,\lambda)\\&\quad\quad\quad\quad\quad*P(x_{t+1},{x_{t+2},x_{t+3},...,x_{T}}|y_{t+1}=q_j,\lambda)\\ &= \sum_{i=1}^N\sum_{j=1}^N P(x_1,x_2,...,x_t,{\color{blue}y_{t+1}=q_j}|y_t=q_i,\lambda)P(y_t=q_i|\lambda)\\&\quad\quad\quad\quad\quad*P(x_{t+1},{x_{t+2},x_{t+3},...,x_{T}}|{\color{red}x_1,x_2,...,x_t},y_{t+1}=q_j,{\color{blue}y_t=q_i},\lambda)\\ &= \sum_{i=1}^N\sum_{j=1}^N P(y_t=q_i|\lambda)P({\color{orangered}x_1,x_2,...,x_t,y_{t+1}=q_j}|y_t=q_i,\lambda)\\&\quad\quad\quad\quad\quad*P(x_{t+1},{x_{t+2},x_{t+3},...,x_{T}}|{\color{orangered}x_1,x_2,...,x_t,y_{t+1}=q_j},{\color{blue}y_t=q_i},\lambda)\\ &= \sum_{i=1}^N\sum_{j=1}^N P(y_t=q_i|\lambda)P({\color{orangered}x_1,x_2,...,x_t,y_{t+1}=q_j},x_{t+1},{x_{t+2},x_{t+3},...,x_{T}}|{\color{blue}y_t=q_i},\lambda)\\ &= \sum_{i=1}^N P(y_t=q_i|\lambda)P({\color{orangered}x_1,x_2,...,x_t},x_{t+1},{x_{t+2},x_{t+3},...,x_{T}}|{\color{blue}y_t=q_i},\lambda)\\ &= \sum_{i=1}^N P({\color{orangered}x_1,x_2,...,x_t},x_{t+1},{x_{t+2},x_{t+3},...,x_{T}},{\color{blue}y_t=q_i}|\lambda)\\ &= P(x_1,x_2,...,x_T|\lambda)=P(X|\lambda)\\ \end{aligned} i=1∑Nj=1∑Nαt(i)Ai,jBj,xt+1βt+1(j)=i=1∑Nj=1∑NP(x1,x2,...,xt,yt=qi∣λ)P(yt+1=qj∣yt=qi,λ)∗P(xt+1∣yt+1=qj,λ)P(xt+2,xt+3,...,xT∣yt+1=qj,λ)=i=1∑Nj=1∑NP(x1,x2,...,xt∣yt=qi,λ)P(yt=qi∣λ)P(yt+1=qj∣yt=qi,λ)∗P(xt+1∣xt+2,xt+3,...,xT,yt+1=qj,λ)P(xt+2,xt+3,...,xT∣yt+1=qj,λ)=i=1∑Nj=1∑NP(x1,x2,...,xt∣yt=qi,yt+1=qj,λ)P(yt=qi∣λ)P(yt+1=qj∣yt=qi,λ)∗P(xt+1∣xt+2,xt+3,...,xT,yt+1=qj,λ)P(xt+2,xt+3,...,xT∣yt+1=qj,λ)=i=1∑Nj=1∑NP(x1,x2,...,xt∣yt=qi,yt+1=qj,λ)P(yt=qi∣λ)P(yt+1=qj∣yt=qi,λ)∗P(xt+1,xt+2,xt+3,...,xT∣yt+1=qj,λ)=i=1∑Nj=1∑NP(x1,x2,...,xt,yt+1=qj∣yt=qi,λ)P(yt=qi∣λ)∗P(xt+1,xt+2,xt+3,...,xT∣x1,x2,...,xt,yt+1=qj,yt=qi,λ)=i=1∑Nj=1∑NP(yt=qi∣λ)P(x1,x2,...,xt,yt+1=qj∣yt=qi,λ)∗P(xt+1,xt+2,xt+3,...,xT∣x1,x2,...,xt,yt+1=qj,yt=qi,λ)=i=1∑Nj=1∑NP(yt=qi∣λ)P(x1,x2,...,xt