Kaggle-纽约市出租车费预测
1 数据导入
在kaggle上下载完训练数据和测试数据之后,将数据导入。由于训练数据集过大,电脑配置有限,训练集只导入100000条记录。
trainData=pd.read_csv('train.csv',nrows=100000)
testData=pd.read_csv('test.csv')
2 数据审查
2.1. 数据的整体情况

2.2 类型审查
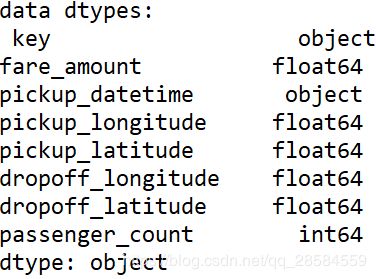
key列和pickup_datetime列显示为字符串类型,需要将其转换为时间类型。
2.3 数据的基本情况
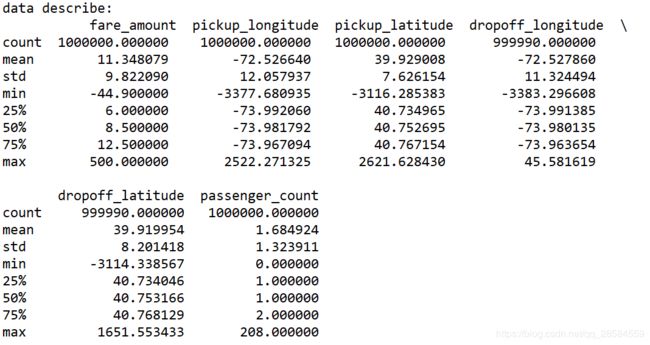
观察每一个变量的数据基本情况:从fare_amount来看,最小值为负数,不合常理;从经纬度来看,最小值为-3000多,最大值为2000多,不合常理;乘客人数最大为208人,最小为0人,不合常理。
2.4 缺失值审查
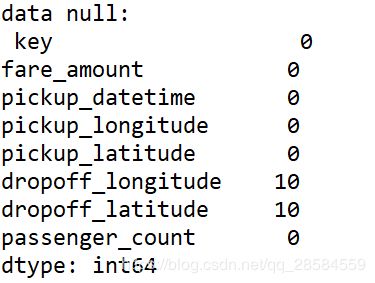
综上,需要首先对数据进行以下处理:
(1)异常值处理:去除明显异常的记录
(2)缺失值处理:去除存在缺失值的记录
(3)类型转换:将字符串类型的列转换成时间类型的列
3 数据预处理
数据预处理包括类型转化、异常值处理、缺失值处理等
###类型转换
trainData['key']=pd.to_datetime(trainData['key'])
trainData['pickup_datetime']=pd.to_datetime(trainData['pickup_datetime'])
print('data dtypes:\n',trainData.dtypes)
###缺失值处理
trainData=trainData.dropna(axis=0)
print('data null:\n',trainData.isnull().sum())
###异常值处理
#去除fare_amount异常值
trainData=trainData.drop(trainData[trainData['fare_amount']<=0].index)
#passenger_count异常值
trainData=trainData.drop(trainData[trainData['passenger_count']<=0].index)
trainData=trainData.drop(trainData[trainData['passenger_count']>6].index)
#去除经纬度异常值
#去除不在纽约市区经纬度范围内的上车下车点
def select_within_boundingbox(dataframe,BB):
return (dataframe['pickup_longitude']>=BB[0]) & (dataframe['pickup_longitude']<=BB[1]) & \
(dataframe['dropoff_longitude']>=BB[0]) & (dataframe['dropoff_longitude']<=BB[1]) & \
(dataframe['pickup_latitude']>=BB[2]) & (dataframe['pickup_latitude']<=BB[3]) & \
(dataframe['dropoff_latitude']>=BB[2]) & (dataframe['dropoff_latitude']<=BB[3])
BB = (-74.5, -72.8, 40.5, 41.8)
trainData=trainData[select_within_boundingbox(trainData,BB)]
print(trainData.describe())
4 数据探索
为了找到纽约市出租车费的相关影响因素,需要对已有数据间的关系进行探索。
4.1 时间与车费的关系
观察车费与年份、月份、日期、时间以及星期的关系。如果车费在不同情况下显示出差异性,则该特征可作为车费的一个影响因素。
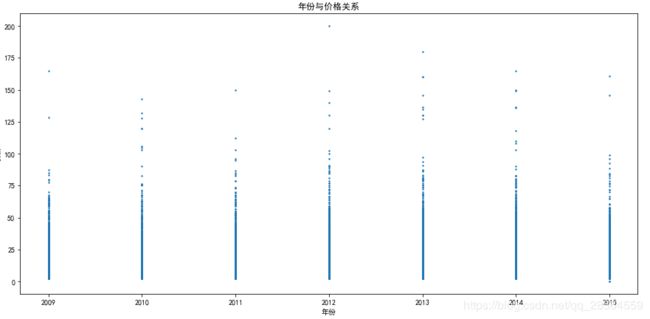
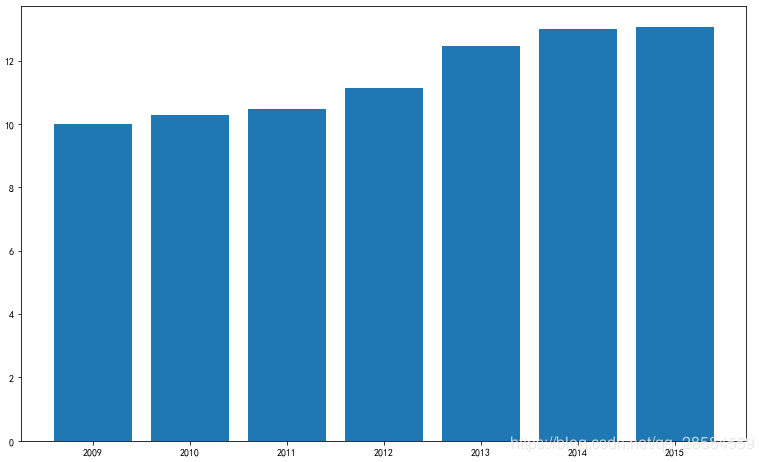
4.1.1 年份与出租车费的关系
plt.figure(figsize=(15,7))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(trainData['year'],trainData['fare_amount'],s=2)
plt.title('年份与价格关系')
plt.xlabel('年份')
plt.ylabel('价格')
plt.show()
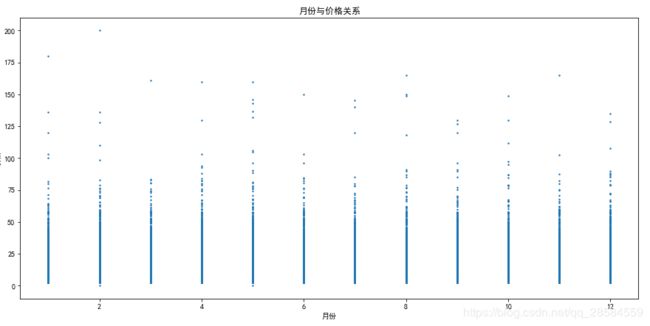
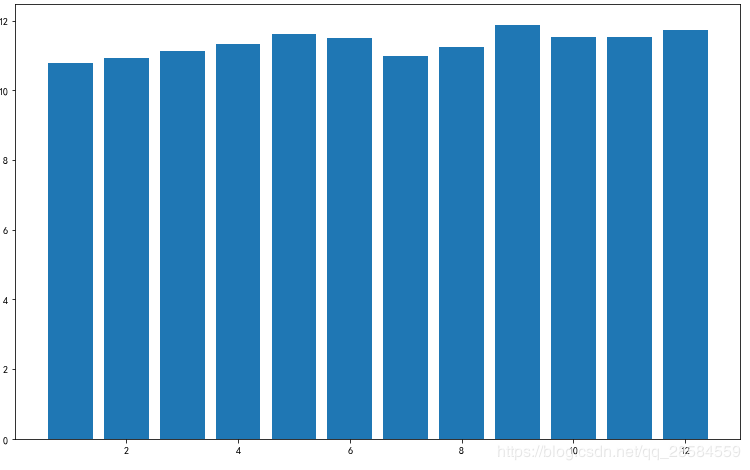
4.1.2 月份与出租车费的关系
plt.figure(figsize=(15,7))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(trainData['month'],trainData['fare_amount'],s=2)
plt.title('月份与价格关系')
plt.xlabel('月份')
plt.ylabel('价格')
plt.show()
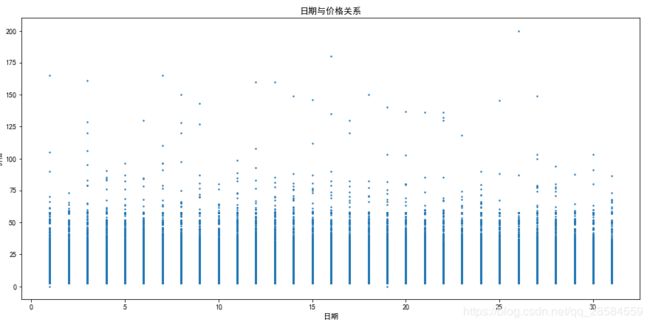
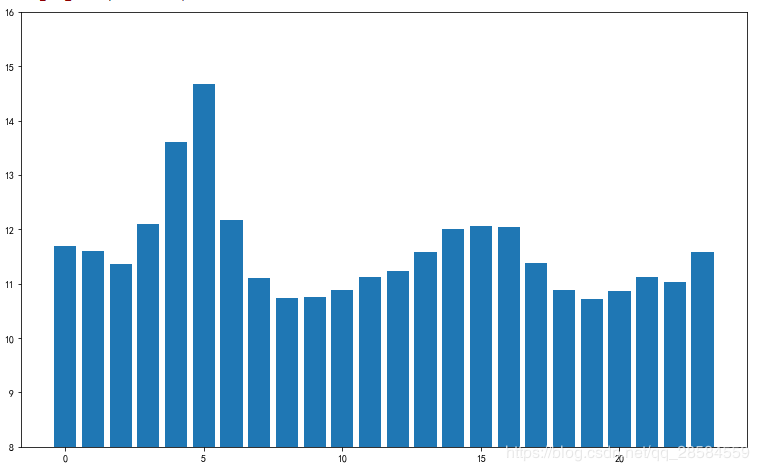
4.1.3 日期与出租车费的关系
plt.figure(figsize=(15,7))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(trainData['day'],trainData['fare_amount'],s=2)
plt.title('日期与价格关系')
plt.xlabel('日期')
plt.ylabel('价格')
plt.ylim(10,12)
plt.show()
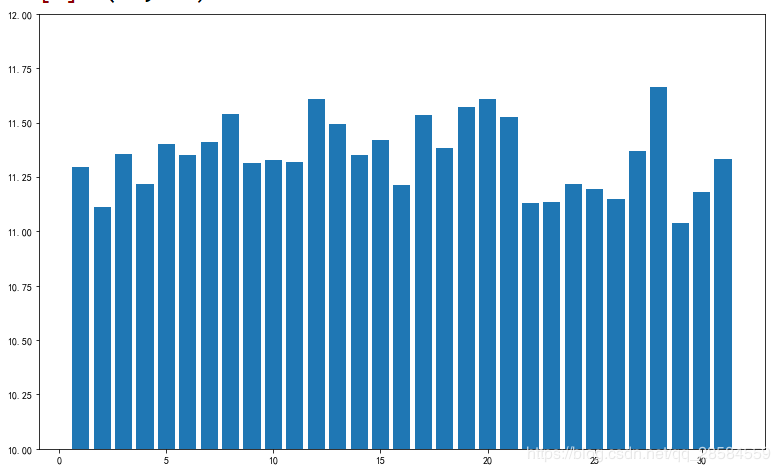
4.1.4 时间与出租车费的关系
plt.figure(figsize=(15,7))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(trainData['hour'],trainData['fare_amount'],s=2)
plt.title('小时与价格关系')
plt.xlabel('小时')
plt.ylabel('价格')
plt.ylim(8,16)
plt.show()
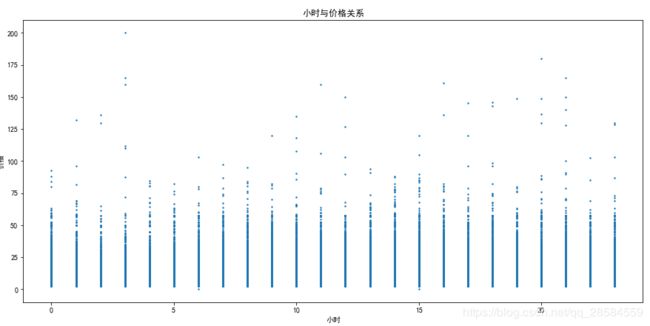
4.1.5 星期与出租车费的关系
plt.figure(figsize=(15,7))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(trainData['weekday'],trainData['fare_amount'],s=2)
plt.title('星期与价格关系')
plt.xlabel('星期')
plt.ylabel('价格')
plt.show()
4.2 距离与出租车费的关系
经纬度之间的距离不能单纯的用两点之间的距离来表示,所以这里采用求解两个点之间的球面距离作为两地之间的距离。
def distance(lon1,lat1,lon2,lat2):
R=6371
C=np.sin(lat1)*np.sin(lat2)+np.cos(lat1)*np.cos(lat2)*np.cos(lon1-lon2)
try:
distance=R*np.arccos(C)*pi/180
except:
distance=0
return distance
# 计算距离
trainData['distance_miles'] = distance(trainData.pickup_longitude, trainData.pickup_latitude, \
trainData.dropoff_longitude, trainData.dropoff_latitude)
trainData['distance_miles'].fillna(0,inplace=True)
#距离的分布
trainData.distance_miles.hist(bins=50, figsize=(12,4))
plt.xlabel('distance miles')
plt.title('Histogram ride distances in miles')
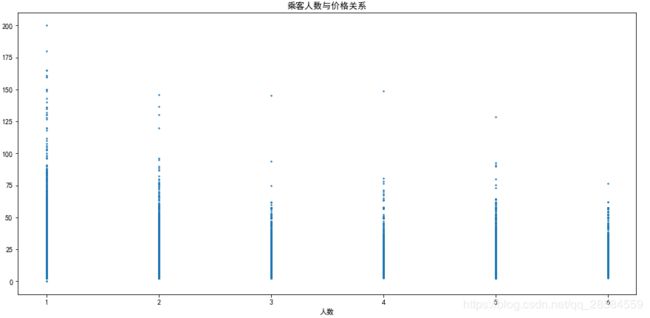
4.3 乘客人数与出租车费之间的关系
plt.figure(figsize=(15,7))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(trainData['passenger_count'],trainData['fare_amount'],s=2)
plt.title('乘客人数与价格关系')
plt.xlabel('人数')
plt.ylabel('价格')
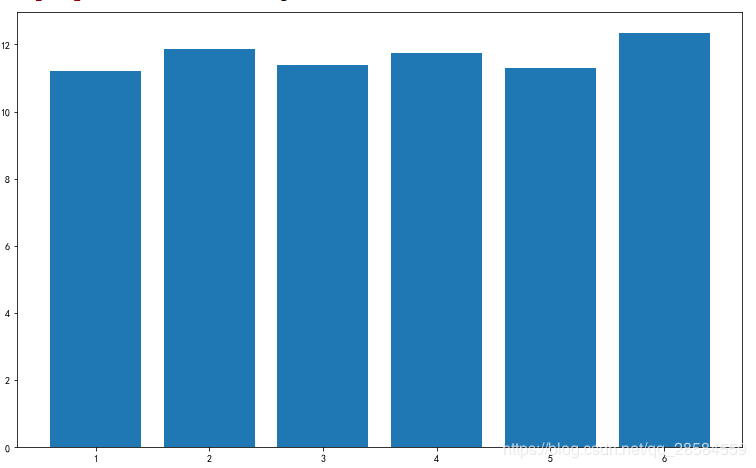
plt.ylim(8,14)
plt.show()
5 特征工程
在原先给定的数据基础上,得到新的数据特征,数据特征包括:时间特征、距离特征、乘客人数特征等。
5.1 时间特征
trainData['year']=trainData['pickup_datetime'].map(lambda x:x.year)
trainData['month']=trainData['pickup_datetime'].map(lambda x:x.month)
trainData['day']=trainData['pickup_datetime'].map(lambda x:x.day)
trainData['hour']=trainData['pickup_datetime'].map(lambda x:x.hour)
trainData['weekday']=trainData['pickup_datetime'].map(lambda x:x.dayofweek)
5.2 距离特征
trainData['distance_miles'] = distance(trainData.pickup_longitude, trainData.pickup_latitude, \
trainData.dropoff_longitude, trainData.dropoff_latitude)
trainData['distance_miles'].fillna(0,inplace=True)
6 测试数据的处理
为了对测试数据进行预测,需要对测试数据进行与训练数据相同的特征提取。
print('testdata null:', testData.isnull().any())
#时间序列
testData['key']=pd.to_datetime(testData['key'])
testData['pickup_datetime']=pd.to_datetime(testData['pickup_datetime'])
print('data dtypes:\n',testData.dtypes)
testData['year']=testData['pickup_datetime'].map(lambda x:x.year)
testData['month']=testData['pickup_datetime'].map(lambda x:x.month)
testData['day']=testData['pickup_datetime'].map(lambda x:x.day)
testData['hour']=testData['pickup_datetime'].map(lambda x:x.hour)
testData['weekday']=testData['pickup_datetime'].map(lambda x:x.dayofweek)
#距离
testData['distance_miles'] = distance(testData.pickup_longitude, testData.pickup_latitude, \
testData.dropoff_longitude, testData.dropoff_latitude)
testData['distance_miles'].fillna(0,inplace=True)
7 模型构建
本文决定采用RandomForestRegression模型实现出租车价格的预测。
trainX=trainData.iloc[:,train.columns!='fare_amount']
trainY=trainData['fare_amount']
testX=testData
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
scores=[]
for i in range(50,201,50):
rf=RandomForestRegressor(n_estimators=i)
score=cross_val_score(rf,trianX,trainY,cv=5)
scores.append(np.mean(score))
best_n=50*(np.argmax(scores)+1)
rf=RandomForestRegressor(n_estimators=best_n)
rf.fit(trainX,trainY)
rf_predict=pd.DataFrame()
rf_predict['key']=testData['key']
rf_predict['fare_amount']=rf.predict(testX)
rf_predict.to_csv('submision_rf.csv',index=False)