yarn 问题总结 (目前遇到的问题)
以下为使用yarn过程中遇到的问题,会持续更新,也当做是个个人笔记吧,好记性不如烂笔头。
一、部分nodemanager节点状态变为unhealthy
现象:
首先会在ambari界面看到有两台机器上的nodemanager被标志位unhealthy (图中已经被修复,所以没有显示出有unhealthy的。),也可以去yarn的界面有个左边有个nodes选项,也可以查看nodemanager的服务状态,命令yarn node -list -all 当然也可以查看。然后我以为可能是服务有问题,就跑去那两台机器去重启nodemanager,但是发现重启没有用,还是两台上的nodemanager 状态为unhealthy。
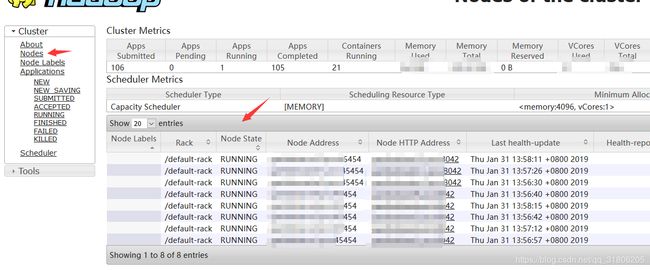

如果某台机器上的nodemanager变为了unhealthy,那么那台内存和cpu都将不可用,这将极大影响我们使用yarn集群来跑我们的离线任务,所以我们要恢复它。
yarn-site.xml
yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage 这个配置项默认是90,意思是如果路配置项下的yarn.nodemanager.local-dirs路径或者yarn.nodemanager.log-dirs.配置项下的路径的磁盘使用率达到了90%以上,则将此台机器上的nodemanager标志为unhealthy,这里面的值可以设置为0到100之间,如果超过100的话,就不生效了。
yarn.nodemanager.disk-health-checker.min-healthy-disks 默认值是0.25 只要不足25%的磁盘使用率超过90%,那么这些机器就会被标志为unhealthy,同样作用于yarn.nodemanager.local-dirs下的路径或者yarn.nodemanager.log-dirs.配置项下的路径。
解决方案:
1.删除以上目录下的无用数据,让磁盘使用率降低到90%以下。
2.将 yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage 设置为100.yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage 设置为0.
提示:
所以,这也给我们了一种提示和优化方法吧,就是:
yarn.nodemanager.local-dirs下的路径或者yarn.nodemanager.log-dirs.配置项下的路径要和hdfs数据路径分开!!!!!,做到日志和数据分离。这样就不会导致hdfs数据写满了,yarn也不可用了(unhealthy),也就是磁盘和内存+cpu分离。
二、集群有资源,但是任务一直停留在accept状态,一直进入不了RUNNING状态 或者集群有资源,但是提交任务不能运行。
首先要明确一下什么是accept状态和running状态,只要你向hadoop yarn提交任务,yarn queue中的待等待任务数没超过上限,就可以进入accept状态,这时client就会向yarn申请一个container,来运行application master,只要得到了container 来运行application master,就会进入running状态,这时你的任务就会开始运行。
通过上述描述,也就是说一个任务从accept状态转化为running状态的一个充要条件是你的application master获得一个container 并且运行起来。
也就是说,任务一直停留在accept状态,一直进入不了RUNNING状态 或者集群有资源,但是提交任务不能运行,这个问题的根源是application master 没获得到container ,但是有个疑问,我集群明明有资源,但是为什么application master获得不来资源呢。
明确一下,大家应该都是默认用的是Capacity Scheduler(容量调度器)
在hadoop配置目录下:capacity-scheduler.xml
或者ambari yarn 配置界面:
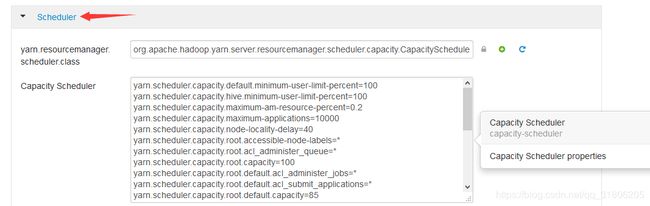
yarn.scheduler.capacity.maximum-am-resource-percent=0.2
这个值调为0.5 或者根据适当情况调大。
这个属性的意思是你的application master 申请的container资源最大不能超过集群总资源的百分之多少,默认是百分之20.
举个例子哈,你的集群资源总共有100G内存,100*0.2也就是20G,也就是说你的application master申请的container资源总共最大为20G,假设一个container最小memory为4G,也就是说,你的application master最多有5个可以并行,如果当第六个任务提交时,即使集群有资源,但是你的application master获取不到container,你的任务状态也无法从accept转化为running,你的任务照样不可以运行,官网说这个其实也是控制任务并行度的,其实也对,因为你控制了application master的个数,不就是控制了任务并行度嘛?
三、任务长时间卡在map 0%,reduce 0%
如果任务走到这一步,肯定是RUNNING状态了,application master得到了container资源。
你们应该可以看到你们RUNNING界面,

应该会只显示这个任务占用了1个container,内存应该是你配置的container最低配,然后核也是,这时你们应该会有个疑问,就是我任务既然有container了!为什么任务进度不会前进呢?是因为你这1个container仅仅运行了application master,并没有运行实际工作的exector,所以当然任务不会前进了,也就是说,你这个实际运行的 任务,仅仅领导了一个运行着application master的container ,并没有执行exector,你领到的仅仅是个“”低保“”而已,所以进度不会前进。
所以,这会导致一个问题,一个大任务和一个小任务同时运行,大任务占了很多资源,小任务就领导了一份“低保“(仅仅一个container里运行着application master),这就会导致小任务的运行时间可能会跟大任务运行时间差不多的一种假象。可能会造成这种困扰。这里要注意哈。
所以!Capacity Scheduler里面的队列(资源隔离,分组)多么重要!
四、Task attempt failed to report status for xxx seconds. Killing!
在mapred-site.xml当中,有个这么个配置文件:
mapreduce.task.timeout 我们配置的是1200000
意思是:如果mapreduce任务既不读取输入,也不写入输出,也不更新其状态字符串,当时间超过1200000毫秒的时候,就会出现这个错误,出现这个错误可能是出现死循环,我们是长时间scan hbase数据超时。
如果出现这个错可以增大上述配置时间,或者检查你的代码。
五、提交任务到yarn ,出现Unsupported major.minor version 52.0
这个错误意思是你项目用JDK1.8运行过,现在又在本地环境变量为低版本的jdk1.7或者jdk1.6下运行,就会报错:“本地jdk版本太低,不支持这个jdk1.8编译过的项目运行”
首先检查下你编译代码的环境和你实际运行的环境是不是jdk8,如果检查无误的话,进入下一步。
yarn其实也是会获取java环境变量的,检查yarn-env.sh的脚本当中的JAVA_HOME是否是jdk1.8版本,这点也是需要非常注意的。
以后持续更新,目前就先想到这么多。。