分布式计算框架MapReduce
本文概述:
1、什么是MapReduce?
2、MapReduce特点
3、MapReduce不适合的场景
4、MapReduce架构
5、MapReduce容错
6、MapReduce编程模型
7、Hadoop如何实现MapReduce?
8、hadoop集群xml配置
9、Java API 编程,使用MapReduce开发WordCount
什么是MapReduce?
MapReduce是一种编程模型,其理论来自Google公司发表的三篇论文(
MapReduce,BigTable,GFS
)之一,主要应用于海量数据的并行计算。
MapReduce可以分成
Map
和
Reduce
两部分理解。
1.Map:映射过程,把一组数据按照某种Map函数映射成新的数据。
2.Reduce:归约过程,把若干组映射结果进行汇总并输出。
我们可以利用MapReduce的思想,针对每个省的人口做并行映射,统计出若干个局部结果,再把这些局部结果进行整理和汇总:

1.Map
:
以各个省为单位,多个线程并行读取不同省的人口数据,每一条记录生成一个Key-Value键值对。图中仅仅是简化了的数据。
2.Shuffle
Shuffle这个概念在前文并未提及,它的中文意思是“洗牌”。Shuffle的过程是对数据映射的排序、分组、拷贝。
3.Reduce
执行之前分组的结果,并进行汇总和输出。
需要注意的是,这里描述的Shuffle只是抽象的概念,在实际执行过程中Shuffle被分成了两部分,一部分在Map任务中完成,一部分在Reduce任务中完成
MapReduce特点:
适用于海量数据的离线处理
易于编程
良好的扩展性
高容错性
分布式计算
MapReduce不适合的场景:
实时计算
流失计算
DAG计算
MapReduce架构:
MapReduce1.x跟MapReduce2.x的对比

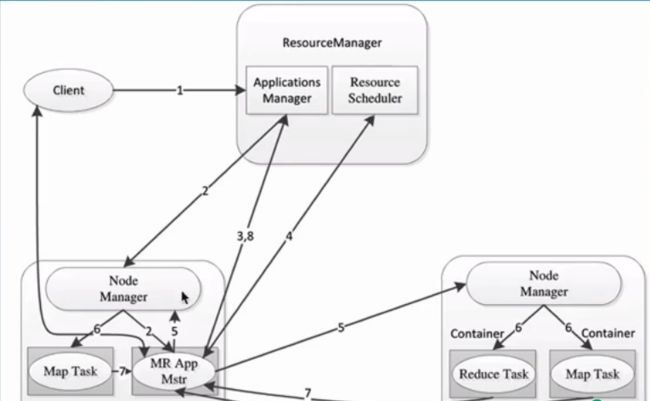
MapReduce容错
1)MRAppMaster:运行失败,由YARN的RM负责重新启动,默认启动次数2次
2)Map/Reduce Task
Task会周期性向MRAppMaster发送心跳,汇报运行状况
Task挂了,MRAppMaster会为task重新申请资源,然后重新执行(NM,换一个NM),次数限制,默认4次
MapReduce编程模型

Hadoop如何实现MapReduce?
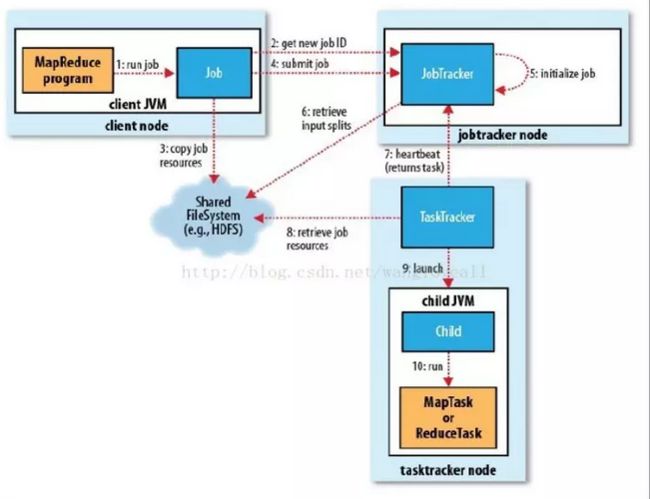
这里需要对几种实体进行解释:
HDFS
:
Hadoop的分布式文件系统,为MapReduce提供数据源和Job信息存储
Client Node
:
执行MapReduce程序的进程,用来提交MapReduce Job
JobTracker Node
:
把完整的Job拆分成若干Task,负责调度协调所有Task,相当于Master的角色
TaskTracker Node
:
负责执行由JobTracker指派的Task,相当于Worker的角色。这其中的Task分为MapTask和ReduceTask
hadoop集群mapred-site.xml配置:
mapred-site.xml
Java API 编程,使用MapReduce开发WordCount
1)在pom.xml中添加mapreduce的依赖
<
build
>
<
plugins
>
<
plugin
>
<
groupId
>
org.apache.maven.plugins
groupId
>
<
artifactId
>
maven-compiler-plugin
artifactId
>
<
version
>
3.5.1
version
>
<
configuration
>
<
source
>
1.7
source
>
<
target
>
1.7
target
>
configuration
>
plugin
>
plugins
>
build
>
2)开发代码
cfg.set(
"mapred.jar"
,
"
hdfs2-1.0-SNAPSHOT.jar"
);//这里是你maven打包的路径
Job job= Job.
getInstance
(cfg,
"word count"
);
job.setMapperClass(WordMap.
class
);
job.setJarByClass(TextCount.
class
);
job.setReducerClass(WordReduce.
class
);
job.setOutputKeyClass(Text.
class
);
job.setOutputValueClass(IntWritable.
class
);
FileInputFormat.
addInputPath
(job,
new
Path(
"file1"
));//源文件
//
判断是否有这个文件
FileSystem files = FileSystem.
get
(cfg);
if
(files.exists(
new
Path(
"file2"
))) {
files.delete(
new
Path(
"file2"
),
true
);
}
FileOutputFormat.
setOutputPath
(job,
new
Path(
"file2"
));//下载文件
System.
exit
(job.waitForCompletion(
true
) ?
0
:
1
);
}
public static class
WordMap
extends
Mapper{
private final
Text
wordKey
=
new
Text();
private final
IntWritable
one
=
new
IntWritable();
@Override
protected void
map(Object key, Text value, Context context)
throws
IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(
"[
\\
s+
\\
,
\\
;
\\
.
\\
[
\\
{
\\
(
\\
]
\\
}
\\
)
\\
<
\\
>
\\
=]{1,}"
);
//
拆分一行中的所有单词
if
(words!=
null
&&words.
length
>
0
){
for
(String word :
words) {
wordKey
.set(word);
one
.set(
1
);
context.write(
wordKey
,
one
);
}
}
}
}
public static class
WordReduce
extends
Reducer{
@Override
protected void
reduce(Text key, Iterable values, Context context)
throws
IOException, InterruptedException {
int
sum =
0
;
for
(IntWritable n :
values) {
sum+=n.get();
}
context.write(key,
new
IntWritable(sum));
}
3) 修改mapreduce-site.xml
<
property
>
<
name
>
mapreduce.app-submission.cross-platform
name
>
<
value
>
true
value
>
property
>
4)
使用maven进行打包
使用shell的方式进行删除操作,可以是可以的,但是个人不建议这么使用