大数据集群搭建
linux配置
ip配置
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
IPADDR=192.168.199.10
NETMASK=255.255.255.0
GATEWAY=192.168.199.2
DNS1=114.114.114.114
重启网络服务
/etc/init.d/network restart
或者 service network restart .
设置开机不启动图形界面
vim /etc/inittab
找到id:5:initdefault: 这一行,将5 改为3,即将它改为id:3:initdefault:。
可以通过命令切换
init 3 shell 界面
init 5 图形界面 或者 startx
关闭防火墙
开防火墙:service iptables start 或者 /etc/init.d/iptables stop
关闭防火墙:service iptables stop
查看防火墙状态:service iptables status
设置开机不启动
查看状态:chkconfig --list iptables
永久关闭:chkconfig --list iptables
[root@localhost ~]# service iptables status
iptables: Firewall is not running.
[root@localhost ~]# chkconfig --list iptables
iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
[root@localhost ~]# chkconfig iptables off
[root@localhost ~]# chkconfig --list iptables
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
更改主机名
vim /etc/sysconfig/network
HOSTNAME=master
本地网络配置
vim /etc/hosts
192.168.199.10 master
192.168.199.11 slave1
192.168.199.12 slave2
安装rz
yum install lrzsz
配置JDK
tar zxf jdk-8u191-linux-x64.tar.gz
配置环境变量
vim ~/.bashrc
#jdk
export JAVA_HOME=/usr/local/src/jdk1.8.0_191/bin
export PATH=$PATH:$JAVA_HOME
[root@localhost bin]# source ~/.bashrc
[root@localhost bin]# java -version
java version "1.8.0_191
克隆master为slave1和slave2
修改IP
vi /etc/sysconfig/network-scripts/ifcfg-eth0
slave1: IPADDR=192.168.199.11
slave2: IPADDR=192.168.199.12
解决克隆后无法上网的问题
将系统下/etc/udev/rules.d 路径下的 70-persistent-net.rules 文件清空或删除
rm -rf /etc/udev/rules.d /70-persistent-net.rules
重启
Reboot 或者 init 6
修改主机名
vim /etc/sysconfig/network
slave1: HOSTNAME=slave1
hostname slave1
slave2 HOSTNAME=slave2
hostname slave2
设置互信关系
cd ~/.ssh/
ssh-keygen 按四个回车
[root@master .ssh]# ls
id_rsa id_rsa.pub
cat id_rsa.pub > authorized_keys //拷贝,直接覆盖 如果是>>是追加
在另外两台机器也执行ssh-keygen
在分别把slave1和slave2的公钥加到master的authorized_keys里面
拷贝master的authorized_keys到slave上
scp -rp authorized_keys slave1:~/.ssh/
scp -rp authorized_keys slave2:~/.ssh/
用ssh slave1认证
tar -zxf hadoop-2.6.5.tar.gz
设置环境变量
#hadoop
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@master hadoop]# pwd
/usr/local/src/hadoop-2.6.5/etc/Hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
vim yarn-evn.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
[root@master hadoop]# vim slaves
slave1
slave2
vim core-site.xml
fs.defaultFS
hdfs://192.168.199.10:9000
hadoop.tmp.dir
file:/usr/local/src/hadoop-2.6.5/tmp/
vim hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.namenode.name.dir
file:/usr/local/src/hadoop-2.6.5/dfs/name
dfs.datanode.data.dir
file:/usr/local/src/hadoop-2.6.5/dfs/data
dfs.replication
2
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vim mapred-site.xml
mapreduce.framework.name
yarn
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8035
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
yarn.nodemanager.vmem-check-enabled
false
创建临时目录和文件目录
mkdir /usr/local/src/hadoop-2.6.5/tmp
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/name
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/data
拷贝文件安装包和环境变量到从节点上
scp -rp ~/.bashrc slave1:~/.bashrc
scp -rp ~/.bashrc slave2:~/.bashrc
scp -rp /usr/local/src/hadoop-2.6.5 slave1:/usr/local/src/
scp -rp /usr/local/src/hadoop-2.6.5 slave2:/usr/local/src/
更新环境变量
source ~/.bashrc
格式化hadoop
hadoop namenode –format
启动集群
start-all.sh
[root@master hadoop-2.6.5]# jps
3136 ResourceManager
2834 NameNode
2998 SecondaryNameNode
3319 Jps
[root@slave1 ~]# jps
2848 Jps
2608 DataNode
2701 NodeManager
监控页面
http://192.168.199.10:8088/
数据管理界面
http://192.168.199.10:50070/
安装zookeeper
tar zxf zookeeper-3.4.11.tar.gz
创建日志文件夹和数据文件夹
[root@master zookeeper-3.4.11]# mkdir data
[root@master zookeeper-3.4.11]# mkdir log
修改配置
[root@master zookeeper-3.4.11]# cd conf/
[root@master conf]# cp zoo_sample.cfg zoo.cfg
[root@master conf]# vim zoo.cfg
dataDir=/usr/local/src/zookeeper-3.4.11/data
dataLogDir=/usr/local/src/zookeeper-3.4.11/log
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
防止zookeeper.out在zookeeper同级目录
[root@master bin]# vim zkEnv.sh
54 if [ "x${ZOO_LOG_DIR}" = "x" ]
5 then
56 ZOO_LOG_DIR="/usr/local/src/zookeeper-3.4.11/log"
57 fi
58
59 if [ "x${ZOO_LOG4J_PROP}" = "x" ]
60 then
61 ZOO_LOG4J_PROP="INFO,ROLLINGFILE"

[root@master conf]# pwd
/usr/local/src/zookeeper-3.4.11/conf
[root@master conf]# vim log4j.properties
1 # Define some default values that can be overridden by system properties
2 zookeeper.root.logger=INFO, ROLLINGFILE
3 zookeeper.console.threshold=INFO

配置环境变量
vim ~/.bashrc
#zookeeper
export ZOOKEEPER_HOME=/usr/local/src/zookeeper-3.4.11
export PATH=$PATH:$ZOOKEEPER_HOME/bin
复制到各个从节点
scp -r ~/.bashrc slave1:~/.bashrc
scp -r ~/.bashrc slave1:~/.bashrc
scp -rp /usr/local/src/zookeeper-3.4.11 slave1:/usr/local/src/
scp -rp /usr/local/src/zookeeper-3.4.11 slave2:/usr/local/src/
各个节点分别添加ID
Master
echo "1" > /usr/local/src/zookeeper-3.4.11/data/myid
slave1
echo "2" > /usr/local/src/zookeeper-3.4.11/data/myid
slave2
echo "3" > /usr/local/src/zookeeper-3.4.11/data/myid
zkServer.sh start 启动集群
zkServer.sh status 查看转态
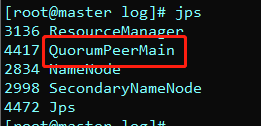
也可以使用脚本启动和关闭
start-zks.sh
#!/bin/bash
HOSTNAME="master slave1 slave2"
ZOOKEEPER_HOME="/usr/local/src/zookeeper-3.4.11"
APP_NAME="zookeeper-3.4.11"
for i in $HOSTNAME
do
echo "Starting ${APP_NAME} on ${i} "
ssh ${i} "source ~/.bashrc; bash ${ZOOKEEPER_HOME}/bin/zkServer.sh start > /dev/null 2>&1 &"
if [[ $? -ne 0 ]]; then
echo "Starting ${APP_NAME} on ${i} is ok"
fi
done
echo All $APP_NAME are started
exit 0
stop-zks.sh
#!/bin/bash
HOSTNAME="master slave1 slave2"
ZOOKEEPER_HOME="/usr/local/src/zookeeper-3.4.11"
APP_NAME="zookeeper-3.4.11"
for i in $HOSTNAME
do
echo "Stoping ${APP_NAME} on ${i} "
ssh ${i} "source ~/.bashrc; bash ${ZOOKEEPER_HOME}/bin/zkServer.sh stop > /dev/null 2>&1 &"
if [[ $? -ne 0 ]]; then
echo "Starting ${APP_NAME} on ${i} is ok"
fi
done
echo All $APP_NAME are stoped
exit 0
安装hive
卸载mysql
[root@master src]# rpm -qa | grep -i mysql
[root@master src]# rpm -e --nodeps mysql-community-libs-5.6.43-2.el7.x86_64
安装MySQL
wget http://repo.mysql.com/mysql57-community-release-el7-8.noarch.rpm
yum -y install mysql-server
service mysqld start 启动mysql
[root@master log]# chkconfig --list | grep mysqld 查看是否开机启动
mysqld 0:off 1:off 2:off 3:off 4:off 5:off 6:off
[root@master log]# chkconfig mysqld on 设置开机启动
出现问题
[root@master mysql]# service mysqld start
MySQL Daemon failed to start.
Starting mysqld: [FAILED]
查看监控日志
[root@master mysql]# tail -f /var/log/mysqld.log
190301 8:01:36 [ERROR] Fatal error: Can't open and lock privilege tables: Table 'mysql.host' doesn't exist

解决
[root@master mysql]# mysql_install_db –usrer=mysql datadir=/var/lib/mysql
[root@master mysql]# mysql_install_db
[root@master mysql]# /etc/init.d/mysqld restart
Stopping mysqld: [ OK ]
Starting mysqld: [ OK ]
启动成功
[root@master mysql]# mysql -uroot -p
Enter password: 回车
修改密码
mysql> set password for 'root'@'localhost'=password('123456');
Query OK, 0 rows affected (0.00 sec)
下载:wget http://mirror.bit.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
解压:tar zxvf apache-hive-1.2.2-bin.tar.gz
[root@master conf]# mv apache-hive-1.2.2-bin hive-1.2.2
[root@master hive-1.2.2]# pwd
/usr/local/src/hive-1.2.2/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export HIVE_HOME=/usr/local/src/hive-1.2.2
export HIVE_CONF_DIR=/usr/local/src/hive-1.2.2/conf
[root@master conf]# vim hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&useSSL=false
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.exec.scratchdir
/usr/local/src/hive-1.2.2/tmp
hive.querylog.location
/usr/local/src/hive-1.2.2/log
改环境变量
#hive
export HIVE_HOME=/usr/local/src/hive-1.2.2
export PATH=$PATH:#HIVE_HOME/bin
[root@master conf]# vim hive-log4j.properties
找到hive.log.dir 改成:
hive.log.dir=/usr/local/src/hive-1.2.2/log
下面只写步骤,具体见hive的笔记
创建目录
[root@master hive-1.2.2]# mkdir log
[root@master hive-1.2.2]# mkdir tmp
连接mysql-connectxxx
wget https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.46.tar.gz
[root@master src]# tar zxf mysql-connector-java-5.1.44.tar.gz
cd mysql-connector-java-5.1.44/
cp mysql-connector-java-5.1.44-bin.jar /usr/local/src/hive-1.2.2/lib/
[root@master src]# cd hadoop-2.6.5/share/hadoop/yarn/lib/
[root@master lib]# mv jline-0.9.94.jar jline-0.9.94.jar.old
[root@master src]# cp hive-1.2.2/lib/jline-2.12.jar hadoop-2.6.5/share/hadoop/yarn/lib/
此处经常会报错
建议;
进入mysql:
mysql>use mysql;
mysql>select user,password from user;
mysql> delete from user where 1=1;
mysql> GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘123456’ WITH GRANT OPTION;
mysql> flush privileges;
mysql>quit;
hive
安装成功
安装spark
tar zxf spark-2.0.2-bin-hadoop2.6.tgz
[root@master src]# mv spark-2.0.2-bin-hadoop2.6 spark-2.0.2
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vim spark-env.sh
export SCALA_HOME=/usr/local/src/scala-2.11.8
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/src/spark-2.0.2
SPARK_DRIVER_MEMORY=1G
[root@master conf]# vim slaves
slave1
slave2
更改启动文件名,避免和hadoop冲突
[root@master sbin]# mv start-all.sh start-spark-all.sh
[root@master sbin]# mv stop-all.sh stop-spark-all.sh
拷贝
scp -r /usr/local/src/spark-2.0.2 slave1:/usr/local/src/
scp -r /usr/local/src/spark-2.0.2 slave2:/usr/local/src/
scp -r scala-2.11.8 slave1:/usr/local/src/
scp -r scala-2.11.8 slave2:/usr/local/src/
启动集群
[root@master src]# start-spark-all.sh
Master多个Master
Slave多个Worker
安装scala
tar –xzvf scala-2.11.8.tar.gz
配置环境变量
#scala
export SCALA_HOME=/usr/local/src/scala-2.11.8
export PATH= P A T H : PATH: PATH:SCALA_HOME/bin
安装anaconda3
sh Anaconda3-4.4.0-Linux-x86_64.sh
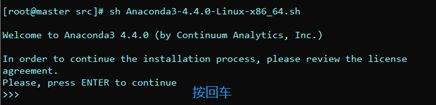



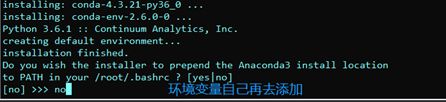
安装完成后添加环境变量
切换py27,输入这条命令
[root@master bin]# conda create -n py27 python=2.7 -y -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
查看版本信息和切换python
conda info -e # 查看Python版本信息
source activate root # 切换Python 3.6
source activate py27 #切换py2.7
在~/.bashrc中 加入默认启动Python 2.7的配置,并激活配置文件:

更新环境变量
[root@master bin]# source ~/.bashrc
(py27) [root@master bin]#
安装TensorFlow
(py27) [root@master bin]# conda install -y -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ tensorflow=1.2

在Python 2.7环境下,numpy已经完成安装,不用单独在安装。
pip install numpy

安装kafka
1.下载Kafka安装包
2.上传安装包
3.解压
4.修改配置文件 config/server.properties、
找到以下的配置
host.name=master
log.dirs=/data/kafka
zookeeper.connect=master:2181,slave1:2181,slave2:2181
拷贝到其他节点
#Master
vim config/server.propertie
broker.id=0
#Slave1
vim config/server.propertie
broker.id=1
#Slave2
vim config/server.propertie
broker.id=2
启动:利用脚本启动
#!/bin/bash
HOSTNAME="master slave1 slave2"
KAFKA_HOME="/usr/local/src/kafka_2.11-0.10.2.1"
APP_NAME="kafka_2.11-0.10.2.1"
for i in $HOSTNAME
do
echo "Starting ${APP_NAME} on ${i} "
ssh ${i} "source ~/.bashrc; nohup sh ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties > /dev/null 2>&1 &"
if [[ $? -ne 0 ]]; then
echo "Starting ${APP_NAME} on ${i} is ok"
fi
done
echo All $APP_NAME are started
exit 0
关闭kafka
#!/bin/bash
HOSTNAME="master slave1 slave2"
KAFKA_HOME="/usr/local/src/kafka_2.11-0.10.2.1"
APP_NAME="kafka_2.11-0.10.2.1"
for i in $HOSTNAME
do
echo "Stopping ${APP_NAME} on ${i} "
ssh ${i} "source ~/.bashrc;bash ${KAFKA_HOME}/bin/kafka-server-stop.sh"
if [[ $? -ne 0 ]]; then
echo "Stopping ${APP_NAME} on ${i} is down"
fi
done
echo All $APP_NAME are stopped
exit 0
后续更新