【机器学习】李宏毅《1天搞懂深度学习》
写在前面的话:
网上找了很多资料,还是李宏毅老师的《1天搞懂深度学习》好评如潮,有的资料比较分散,就把一些很不错的链接集中在这里了。
PPT:
这是slideshare的链接:
http://www.slideshare.net/tw_dsconf/ss-62245351?qid=108adce3-2c3d-4758-a830-95d0a57e46bc&v=&b=&from_search=3
百度云链接:
链接: https://pan.baidu.com/s/1lgMGT-L_KwlBLkWr70TAxQ 提取码: gap5
视频:
YouTube链接:
https://www.youtube.com/playlist?list=PLJV_el3uVTsPMxPbjeX7PicgWbY7F8wW9
斯坦福计算机视觉课程:
https://study.163.com/course/courseLearn.htm?courseId=1004697005#/learn/video?lessonId=1049395813&courseId=1004697005
干货总结:
https://mp.weixin.qq.com/s?__biz=MzU0NTAyNTQ1OQ==&mid=2247486273&idx=2&sn=d0c8c831dff03b1670eb05eda6ccc541&chksm=fb72779dcc05fe8b75b0c223fb546e561f26f37b777c4f073dfb5f0b9e476b495d0ca171489f&mpshare=1&scene=1&srcid=1229SGI66dWQ3CtstzgDqrCc#rd (感谢实验室大帅哥的分享=-=)
https://blog.csdn.net/dulingwen/article/details/88924695
下面是一些PPT页的说明总结,转自:
https://blog.csdn.net/u010164190/article/details/72633245
整个PPT的思维导图如下:
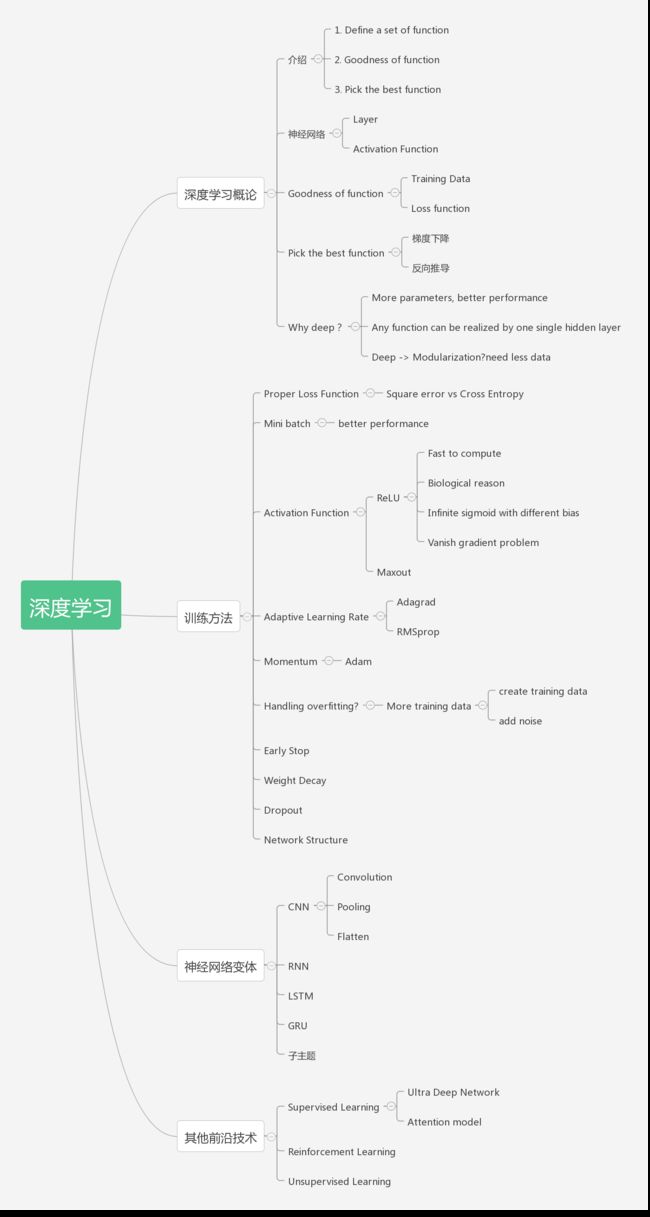
深度学习概论
介绍深度学习
作者非常浅显的指出机器(深度)学习过程非常简单,分为定义方法、判断方法的优劣、挑选出最佳的方法。

对于深度学习,首先第一步定义方法 - 神经网络。深度学习顾名思义是指多层的神经网络。
神经网络的思想来源于对于人脑的生理上的研究,人脑由数亿个神经元组成,神经元通过轴突互相连接通信。神经网络和人脑类似,存在多个层级(layer),每个层级都有多个节点(神经元),层级和层级之间相互连接(轴突),最终输出结果。
对于神经网络的计算能力可以理解为通过一层层Layer的计算归纳,逐步的将抽象的原始数据变的具体。以图片识别为例,输入是一个个像素点,经过每层神经网络,逐步变化成为线、面、对象的概念,然后机器有能力能够识别出来。

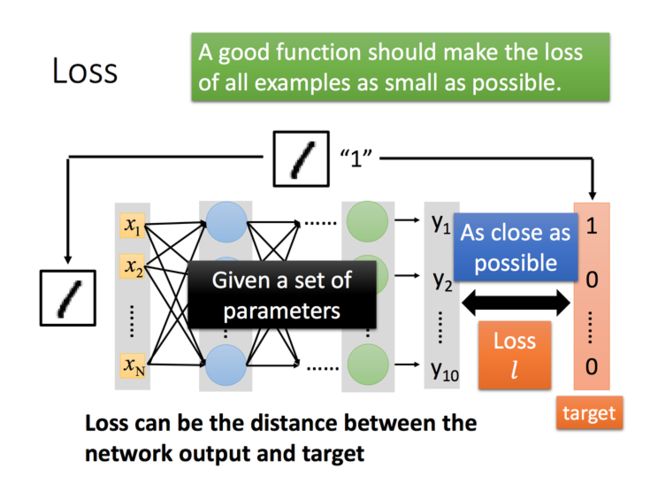
第二步,评估方法的优劣。
Loss function是用于评估方法优劣,通常我们用学习出来的参数对测试数据进行计算,得出对应的预测(y)然后和真实的测试数据的目标值(t)进行比对,y和t之间的差距往往就是Loss。那么评估一个算法的好坏,就是要尽可能的降低Loss。
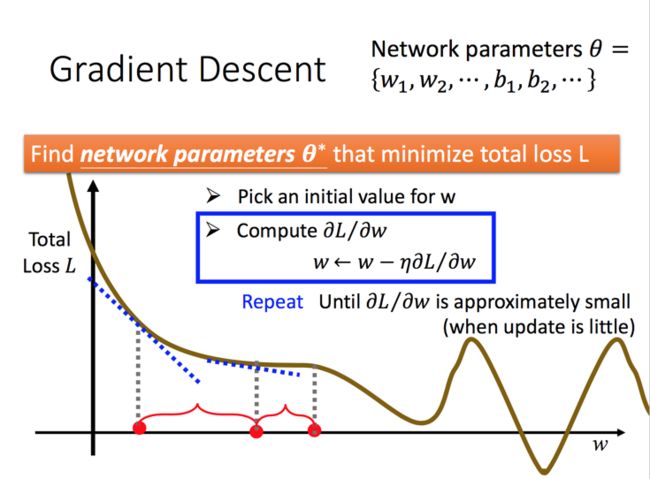
第三步,如何获得最佳的学习方法
获得最佳的学习是采用梯度下降算法,作者也提到梯度下降算法存在局部最优解的问题。人们往往认为机器无所不能,实际上更像是在一个地图上面拓荒,对周边一无所知。神经网络计算梯度的算法是反向传播算法,简称BP。
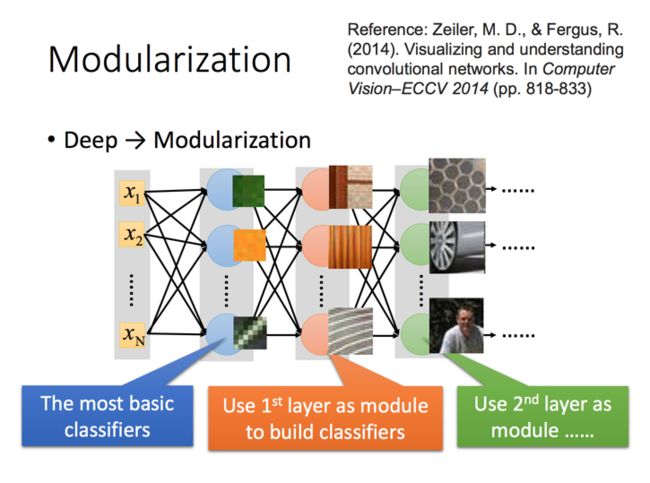
Why Deep?
作者首先指出越多的参数往往带来越好的预测能力,所以神经网络往往参数越多越好。那么如果是同样的参数情况下,为什么层级较多的表现会更好呢?

作者认为深度网络可以带来模块化的好处,随着网络的层级,神经网络会将像素元素逐渐归纳出一些基本的特征,进而变成纹理,进而变成对象。
训练方法
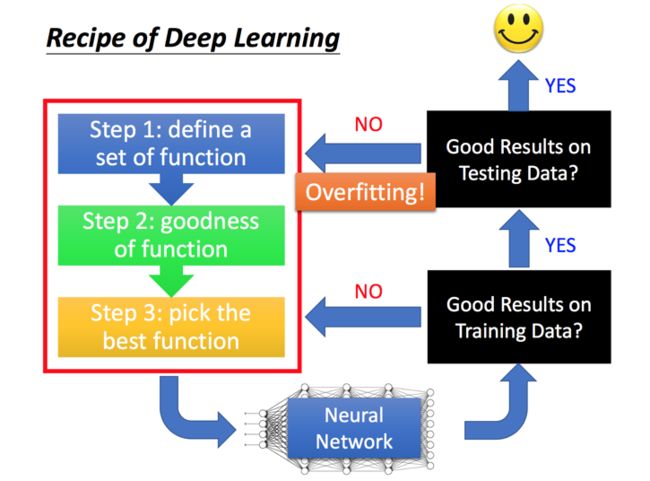
作者总结下来训练过程中会发现了两种情况:
1. 没有办法得到很好的训练结果 ---》 重新选择训练方式
2. 没有办法得到很好的测试结果 ---》 往往由于过度拟合导致,需要重新定义方法
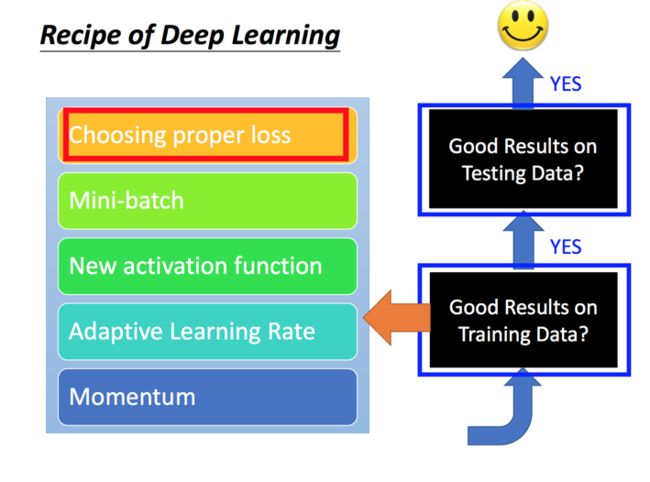
优化训练方法的手段:
1. 选择合适的Loss function:使用Cross Entropy效果要优于Mean Square Error
2. Mini-batch: 每次训练使用少量数据而不是全量数据效率更高
3. Activation Function:使用ReLU替代Sigmoid可以解决梯度消失的问题,可以训练更深的神经网络
4. Adaptive Learning Rate:可以随着迭代不断自我调整,提高学习效率
5. Momentum: 可以一定程度上避免陷入局部最低点的问题
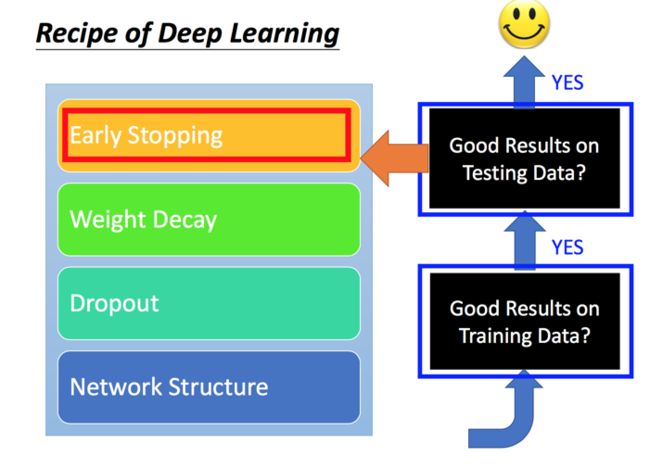
避免过度拟合(overfitting)的方法:
1. Early Stopping:使用cross validation的方式,不断对validation data进行检验,一旦发现预测精度下降则停止。
2. Weight Decay:参数正则化的一种方式?
3. Dropout:通过随机去掉一些节点的连接达到改变网络形式,所以会产生出多种网络形态,然后汇集得到一个最佳结果
4. Network Structure: 例如CNN等其他形态的网络
神经网络变体
Convolutional Neural Network (CNN)
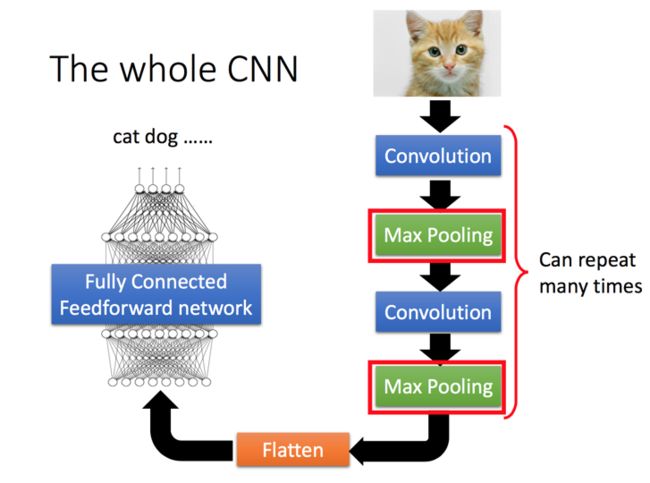
通常情况下,一个CNN包含多次的卷积、池化,然后Flatten,最终再通过一个深度神经网络进行学习预测。CNN在图像、语音识别取得非常好的成绩,核心的想法在于一些物体的特征往往可以提取出来,并且可能出现在图片的任何位置,而且通过卷积、池化可以大大减少输入数据,加快训练效率。
Recurrent Neural Network (RNN)
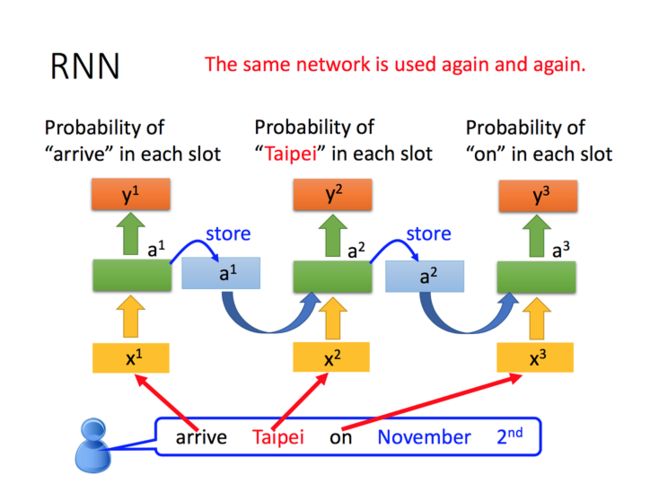
RNN的想法是可以将hidden layer的数据存储下来,然后作为输入给下一个网络学习。这种网络的想法可以解决自然语言中前后词语是存在关联性的,所以RNN可以把这些关联性放到网络中进行学习。
其他前沿技术
Ultra Deep Network:2015年出现了152层的Residual Net实现了图片3.57%错误率

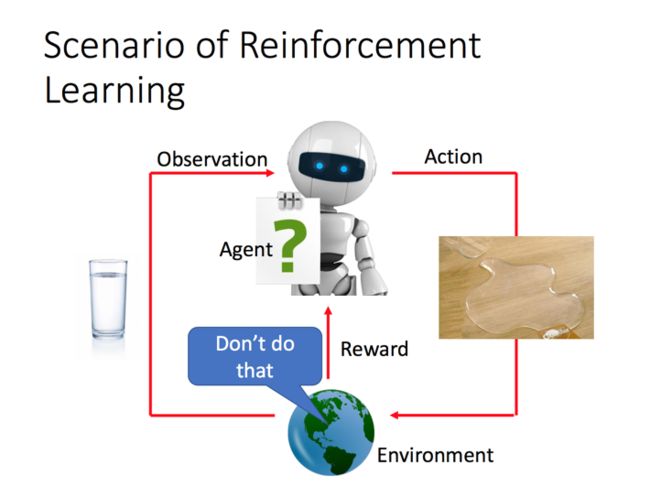
Reinforcement Learning: 通过奖励机制强化学习,并且做出相应的动作
Unsupervised Learning:
1. Deep Style

2. 生成图片

3. 无需人工介入理解文字的含义
