Hadoop系列之原理与架构
一、Hadoop项目架构
Hadoop框架是用来解决数据离线批处理问题的框架,其中最核心的是HDFS和MapReduce,HDFS是架构在Hadoop之上的分布式文件系统,MapReduce是架构在Hadoop之上用来做计算的框架。
hadoop两个核心:HDFS和MapReduce
用途:解决分布式存储和分布式存储。
特点:高可靠性、高效性、可扩展性、成本低(普通PC机都能构建集群)
应用:Google、Facebook等,用于日志处理、批处理、离线处理
架构:离线分析:MR、Hive、Pig
实时查询:Hbase
BI分析:Mahout
分布式文件存储系统HDFS
底层数据源
Hadoop项目结构:
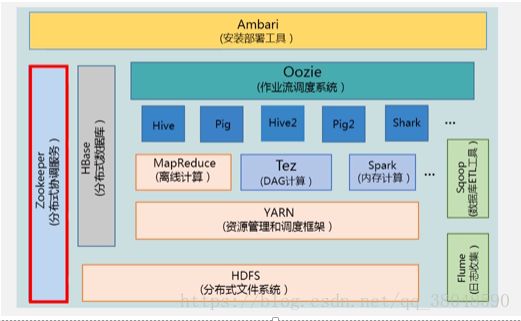
底层:
HDFS:分布式文件系统,负责数据的存储。
Yarn:存储之后要进行相关处理,因此需要一个资源管理和调度,(YARN),在Hadoop2.0,MapReduce作为离线处理。
计算分析工具:MapReduce、Spark、TeZ
TeZ(DAG计算)、Spark(内存计算)。
MapReduce是基于磁盘的,而Spark的计算过程是基于内存的,因此速度效率快很多。
MapReduce:做离线的批处理
Hive:数据仓库,用来做决策分析,历史记录都存在数据仓库当中,数据是多维的,可以用来做数据分析。属于Hadoop平台上的数据仓库,可以用SQL语句操作。Hive会把SqL语句转换成MapReduce作业。
Pig:流数据处理,提供了类似sql语句的查询,轻量级的编程语言。
Oozie:作业流调度系统
Zookeeper:集群管理、分布式锁
HBase:列族数据库,Hadoop上的非关系型数据库
Flume:日志相关收集,(美团)
Sqoop:完成数据导入导出(数据库ELT工具)。关系型数据库到HDFS、HBase、Hive互导
最上层:Ambari部署工具,Hadoop快速部署工具
二、Hadoop优化
局限和不足:抽象层次低,需人工编码、表达能力有限、难以看到程序整体逻辑、执行迭代操作效率低、开发者需要自己管理作恶之间的依赖、资源浪费、实时性差
优化与发展主要体现在两个方面:1、一方面:Hadoop自身两大核心组件
2、二方面,加入其它的组件如pig、spark、kafka等。


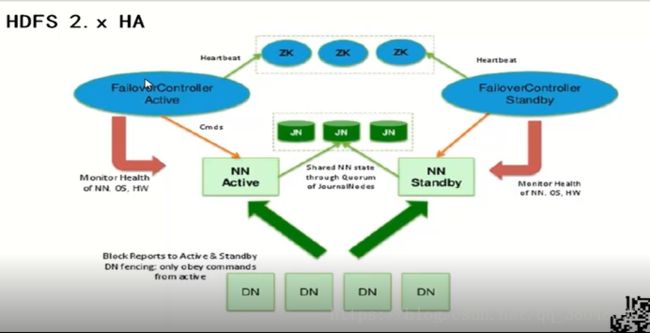
HDFS新特性:HDFS HA:解决HDFS1.0面临的单点故障问题,两个名称节点,一个活跃,一个待命,通过Zookeeper来管理,保持只有一个活跃节点的状态,它的作用是实时维护分布式文件系统的元数据信息。一旦节点出故障,即切换到待命状态的名称节点,并通过数据节点不断向活跃名称节点和待命名称节点来实时的汇报自己的信息
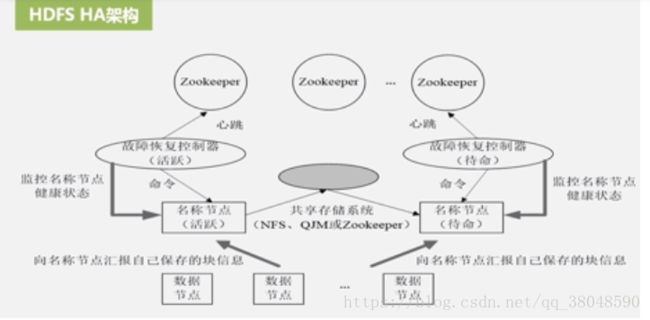
HDFS Federation:设计可解决单名称节点存在的问题
HDFS2.0 HA
主备NameNode 主NameNode 是active备用Namenode是standby状态。待命状态。
解决单点故障
主NameNode对外提供服务,备NameNode 同步主NameNode元数据,以待切换,所有DataNode同时向两个NameNode汇报数据块信息。
两种切换选择:手动切换(命令行)、自动切换(基于Zookeeper实现)
-基于Zookeeper自动切换方案
HDFS2.0 Federation
三、YARN
新引入的资源管理系统
核心思想:1、将MRv1中的JobTracker的资源管理和任务调度分开
2、兼容第三方计算框架。
Resource Manager、Node Manager
MapReduce作业是客户端需要执行的一个工作单元:包括输入数据、MapReduce程序和配置信息。主要是map任务和reduce任务,运行在集群的节点上并通过yarn进行调度。