java Bio的缺点(为什么会出现NIo) NIo单线程模型
前言:
不知道大家想过没有,java BIo服务端为什么要一个线程对应一个连接,为什么一定要开线程去处理,为什么会出现NIo,一个网络完整的请求经过了哪些步骤,NIo reactor单线程模型怎么实现,有什么缺点?本文会分为几个部分,为大家一一解答。如果能理解此篇文章,会对后面学习Nio的各种reactor模式非常有帮助。
目录:
一个网络完整的请求经过了哪些步骤
java BIO缺点
NIo reactor单线程模型怎么实现,有什么缺点
主文:
一个网络完整的请求经过了哪些步骤?
假设一个人发生消息给另外一个人需要经过如下这几步:
1.准备消息
2.编码,比如我有一个字符串的消息要发送出去,那么发送出去之前要把这个字符串消息转为字节(Byte),这是因为网络上传输的不能是原本的字符串;又比如,我要给发送出去的消息加一个消息标识,用来以后另一端收消息的程序可以用来解决粘包拆包问题
3.将消息发送到网络通道,write方法
4.网络传输
5.程序另一端读取数据,read方法
6.解码,和编码相对应,比如发送过来的消息,是字符串转为字节,那么解码要做的事就是把字节转为字符串;又或者数据还加了标识,就要根据这个标识去读取数据,解决粘包拆包问题
7.处理业务逻辑,比如是做群聊场景,那么当程序收到消息之后,要将这条转发给对应群聊中的每一个人
8.准备数据响应给消息发送者,回到第一步
步骤①②③属于消息发送着要做的事情
步骤⑤⑥⑦是消息接收者要做的事情
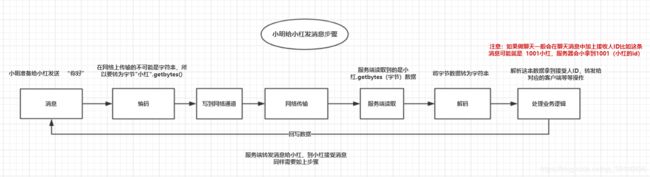
一个完整的网络通信请求,就是客户端发送消息,服务端读取消息,服务端响应消息给客户端,客户端读取消息。客户端和服务端都会经过上述七个步骤。
java BIO缺点
Bio当中两个会导致程序阻塞的方法:
socket.getInputStream().read(b);此方法会一直阻塞到有数据输入,此socket对应的客户端发送了数据,serverSocket.accept();此方法会一直阻塞到有客户端连接java BIo服务端为什么要一个线程对应一个连接,为什么一定要开线程去处理?
下面附上一段Bio不开线程去处理的代码,然后我们来分析一下会出现什么情况:
package com.luban.bio;
import com.luban.utils.HttpUtil;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.text.SimpleDateFormat;
import java.util.Date;
public class BioServer {
public static void main(String[] args) {
try {
ServerSocket serverSocket=new ServerSocket(1388);
while (true){
Socket socket = serverSocket.accept(); //阻塞
System.out.println(socket.getRemoteSocketAddress().toString()+"来连接了");
while (true){
InputStream inputStream = null;
OutputStream outputStream = null;
try {
inputStream = socket.getInputStream();
outputStream = socket.getOutputStream();
} catch (IOException e) {
e.printStackTrace();
}
try {
byte[] bytes = new byte[1024];
inputStream.read(bytes);//阻塞
System.out.println(new String(bytes));
outputStream.write(HttpUtil.getHttpResponseContext200(new SimpleDateFormat("yyyy-MM-dd hh:dd:ss").format(new Date())).getBytes("utf-8"));
outputStream.flush();
}catch (Exception e){
e.printStackTrace();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
因为serverSocket.accept()接受客户端连接方法,必须等到有客户端来接连的时候才会解阻塞;inputStream.read(bytes)必须等此客户端发来了数据才会解阻塞。serverSocket.accept()没有客户端来连接一直阻塞不动,inputStream.read(bytes)客户端没有发来数据一直阻塞,代码不会往下执行。按我如上代码,如果一个客户端来连接之后,这个客户端没有发来数据代码则一直卡在inputStream.read(bytes)不动,serverSocket.accept()方法得不到调用,那么此时有客户端来连接,是不会接受连接的,必须要等到第一个连接上来的客户端发来了数据才可以。同理,当第一个连接上来的客户端发来了数据,代码将执行到serverSocket.accept()阻塞,那么此时第一个连接上来的客户端发来了数据,inputStream.read(bytes)方法不会调用,那么就不会读取客户端发来的数据,客户端发来一条数据,服务器有可能半天不会响应。
所以java BIo服务端一定要开线程去处理。
附上BIo经典编码模式代码:
服务端mian程序入口:
package com.luban.luban.io;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
public class BioServer {
public static void main(String[] args) throws IOException {
int port=8080;
if(args!=null&&args.length>0){
try {
port=Integer.valueOf(args[0]);
}catch (Exception e){
}
}
ServerSocket serverSocket=null;
try {
serverSocket=new ServerSocket(port);
while (true){
Socket socket = serverSocket.accept();
new Thread(new TimeServerHandler(socket)).start();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if(serverSocket!=null){
serverSocket.close();
}
}
}
}
处理业务逻辑类:
package com.luban.luban.io;
import java.io.*;
import java.net.Socket;
import java.text.SimpleDateFormat;
import java.util.Date;
public class TimeServerHandler implements Runnable {
private Socket socket;
public TimeServerHandler(Socket socket) {
this.socket=socket;
}
@Override
public void run() {
BufferedReader bufferedReader=null;
PrintWriter bufferedWriter=null;
try {
//典型的装饰者模式 带缓冲的字符流》字符流》字节流
bufferedReader= new BufferedReader(new InputStreamReader(socket.getInputStream()));
bufferedWriter=new PrintWriter(socket.getOutputStream(),true);
String line =null;
String time=null;
while (true){
line=bufferedReader.readLine();
if(line==null)
break;
time="SJ".equalsIgnoreCase(line)? new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()) : "你发的啥?";
bufferedWriter.println(time);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if(bufferedReader!=null){
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bufferedWriter!=null){
bufferedWriter.close();
}
if(socket!=null){
try {
socket.close();
this.socket=null;
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
知道了Bio必须是一个客户端对应一个线程之后我们就能分析出BIo的缺点了,假设有10万个客户端,那么服务器就要开10万个线程。那么服务器的线程是非常宝贵的,而且10万个线程一般会使服务器炸掉。对于一些链接上来但是并没有向服务器发来数据的客户端,我们服务器给它开一个是资源的浪费。正是因为Bio这个阻塞式的编码方式,必须要开线程去解决,然而线程资源又是非常宝贵的,所以才出现了NIo。
NIo reactor单线程模型怎么实现,有什么缺点?
Nio的出现必然就是解决我们Bio的一些缺点的,那么Bio的缺点是什么?编码方式必须是一个客户端对应一个线程。造成线程开启太多导服务器崩掉,也是对线程资源的浪费。所以在Nio中,他把两处阻塞的地方给去除掉了(accept和read方法)。并且提供selector对象,那么selector有什么作用呢?在Bio中,什么时候有客户端来连接,已经连接上来的客户端什么时候发来了数据,我们是不知道的。在Nio中,提供selector对象,我们可以把我们服务端的socket或者服务端接收到的客户端的socket注册在selector中,并指定感兴趣的事件,比如对于服务端的socket而言,它感兴趣的事件必然是监听是否有客户端来连接事件,也就是accept事件。对于客户端的socket而言,它感兴趣的事件必然是监听客户端是否发来了数据,也就是read事件。那么通过selector的通知我们可以清楚的知道那个socket有事件发生,比如有客户端来连接了,比如客户端发来数据了。基于selector的作用,那么我们的编码风格就全变了。Bio是直接调用accept或者read方法,一直在哪里傻等;而Nio是有事件发生了我在去调用对应的方法,根据事件的类型我们判断是改调用accept方法还是read方法。当没有事件发生的时候,我们可以做其他的事情,这样就极高的提高了性能。这里在多说几句,前面也说过因为Nio把两处阻塞的方法去掉了,如果像Bio一样直接调用accept方法或者read方法将发生死循环,因为这两个方法不会阻塞了。然后我们通过这种通知机制,有多少个事件,我调用对应的方法几次,就不会发生调用无效的问题。
备注:selector的底层实现,根据不同的操作系统来实现,Windows底层依赖select函数,linux依赖于epoll函数。当然不同版本可能实现有点差距。这个具体底层实现,要深入研究openjdk源码及操作系统函数,本篇不过多讲解,日后有时间专门写一篇selector底层实现的博客吧
下面附上reactor单线程模式服务端代码实现:
程序主入口代码:
package com.luban.oneReactor;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
try {
TCPReactor reactor = new TCPReactor(1333);
reactor.run();
} catch (IOException e) {
e.printStackTrace();
}
}
}事件轮询,事件分发类:
package com.luban.oneReactor;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.util.Iterator;
import java.util.Set;
public class TCPReactor implements Runnable {
private final ServerSocketChannel ssc;
private final Selector selector;
public TCPReactor(int port) throws IOException {
selector = Selector.open(); //创建选择器对象
ssc = ServerSocketChannel.open(); //打开服务端socket
InetSocketAddress addr = new InetSocketAddress(port);
ssc.socket().bind(addr); // 在ServerSocketChannel绑定端口
ssc.configureBlocking(false); // 设置ServerSocketChannel为非阻塞
SelectionKey sk = ssc.register(selector, SelectionKey.OP_ACCEPT); // ServerSocketChannel向selector注册一个OP_ACCEPT事件,然后返回該通道的key
sk.attach(new Acceptor(selector, ssc)); // 给定key一个附加的Acceptor对象 如果事件没有被改变 可以认为这个附加对象和OP_ACCEPT是绑定的
}
@Override
public void run() {
while (!Thread.interrupted()) { // 在线程中断前持续执行
System.out.println("Waiting for new event on port: " + ssc.socket().getLocalPort() + "...");
try {
//查看是否有事件发生 有事件发生则把这个事件加入到selectedKeys
selector.select();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("aaaaaaa");
//能执行到这里 说明发生了事件
// 取得所有已就绪事件的key集合
Set selectedKeys = selector.selectedKeys();
Iterator it = selectedKeys.iterator();
//遍历已经发生的事件
while (it.hasNext()) {
SelectionKey selectionKey = it.next(); //read的事件对象
// 根据事件的key进行调度
dispatch(selectionKey);
it.remove();
}
}
}
private void dispatch(SelectionKey key) {
//取出附加对象 根据附加对象判断是什么事件 调用不同附加对象的run方法 这里请注意这个附加对象是会变化的
//如果是接受客户端连接事件的话 这里取出的附加对象就是Acceptor,调用的肯定也是Acceptor的run方法
//如果是已经连接上来的客户端发来数据 则是读事件 那么这里取出的附加对象就是TCPHandler,调用的肯定也是TCPHandler的run方法
//TCPHandler那里来的请往下看
//new Acceptor(selector, ssc).run()
Runnable r = (Runnable) (key.attachment()); //取出附加对象
if (r != null)
r.run();
}
} 处理客户端连接类:
package com.luban.oneReactor;
import java.io.IOException;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
public class Acceptor implements Runnable {
private final ServerSocketChannel ssc;
private final Selector selector;
public Acceptor(Selector selector, ServerSocketChannel ssc) {
//服务端的server
this.ssc=ssc;
//理解集合对象 专门存socket
this.selector=selector;
}
@Override
public void run() {
try {
SocketChannel sc= ssc.accept(); // 接受client连接请求
System.out.println(sc.socket().getRemoteSocketAddress().toString() + " is connected.");
if(sc!=null) {
sc.configureBlocking(false); // 设置非阻塞
SelectionKey sk = sc.register(selector, SelectionKey.OP_READ); // SocketChannel向selector注册一个OP_READ事件,然后返回该通道的key
selector.wakeup(); // 使一个阻塞住的selector操作立即返回
sk.attach(new TCPHandler(sk, sc)); // 给定key一个附加的TCPHandler对象
}
} catch (IOException e) {
e.printStackTrace();
}
}
}读取数据,处理业务逻辑类:
package com.luban.oneReactor;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.SocketChannel;
public class TCPHandler implements Runnable {
private final SelectionKey sk;
private final SocketChannel sc;
public TCPHandler(SelectionKey sk, SocketChannel sc) {
this.sk = sk;
this.sc = sc;
}
@Override
public void run() {
byte[] arr = new byte[1024];
ByteBuffer buf = ByteBuffer.wrap(arr);
int numBytes = 0; //读取字符串
try {
numBytes = sc.read(buf);
} catch (IOException e) {
e.printStackTrace();
}
if(numBytes == -1)
{
System.out.println("[Warning!] A client has been closed.");
closeChannel();
return;
}
String str = new String(arr); // 将读取到的byte內容转为字符串
if ((str != null) && !str.equals(" ")) {
process(str); // 处理业务逻辑
System.out.println(sc.socket().getRemoteSocketAddress().toString()
+ " > " + str);
String returnStr="服务端返回";
ByteBuffer returnBuf = ByteBuffer.wrap(returnStr.getBytes()); // wrap自动把buf的position设为0,所以不需要再flip()
try {
while (returnBuf.hasRemaining()) {
sc.write(returnBuf); // 回传给client回应字符串,发送buf的position位置 到limit位置为止之开的內容
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private void closeChannel() {
try {
sk.cancel();
sc.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
void process(String str) {
// 模拟处理业务逻辑
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} 如上这种编码就是reactor单线程编码方式,它至始至终就只有一个主(main)线程在运行(调用run方法不是开启线程)
对比起Bio来说,它确实解决了需要多线程的问题,但是它也有个很大的问题,因为一个线程处理这么多客户端的请求太慢了。就拿聊天案列来说吧
那对于我们服务端而言要做的事情有:读取---解码---处理业务逻辑---编码---发送(编码---发送是服务器响应客户端)
意思就是说,当一个客户端发来了数据,唯一的线程要去执行这5个步骤。那么如果是10万客户端同时发来了数据怎么办?
唯一的线程只能一个个的处理 ,先处理第一个客户端的,在处理第二个客户端。。。。那么第10万个那个客户端需要等到什么时候;而且请大家想想,在处理客户端发来的数据的时候,如果有新的客户端来连接怎么办? 唯一的线程必须等到处理完所有客户端发来的数据才会去接受新客户端连接,那么就是处理完10万个客户端发来的数据之后。
总结来说:Nio单线程模式一个线程处理又太慢了,性能不好,Bio线程多太多,容易导致服务器崩掉
即将更新,Nio reactor主从多线程模式;如果本文对你有帮助,请为原创点赞;