CentOS6.5下安装在eclipse配置Hadoop插件
前提:虚拟机中以安装好Hadoop集群。
一、安装eclipse
解压Eclipse即可,进入eclipse解压之后的目录
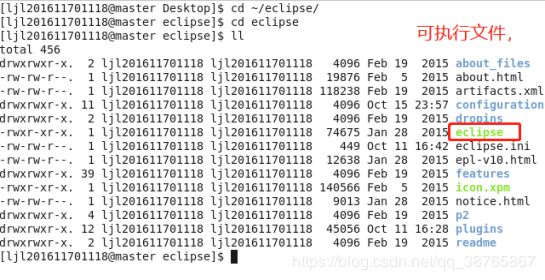
执行命令
./eclipse
二、将插件hadoop-eclipse-plugin-2.5.2.jar移到eclipse目录下的plugins下,记得这个插件要和你所安装的hadoop版本一致,才可以正确安装。

使用图形化界面的复制粘贴,亦或是命令行下使用cp命令。

以下操作,请先开启hadoop集群
三、eclipse配置Hadoop插件
启动eclipse
1,点击preferences,进入,
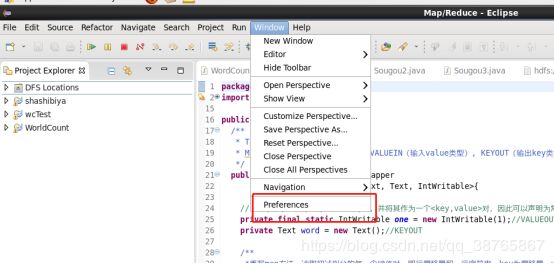
2、看到左边有一个map/reduce,点击,点击browser,添加自己的Hadoop路径,然后点击左下角的OK

3、再次点击preferences,点击show view,然后选择MapReduce Tool下的黄色小象,然后OK
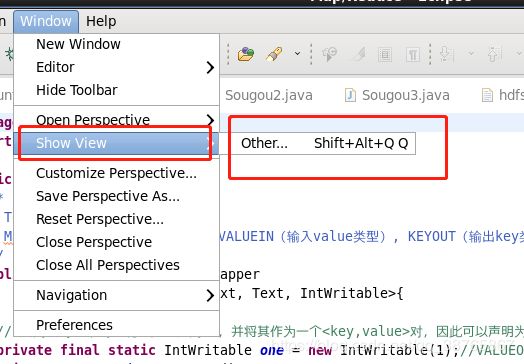

4、会发现在控制台那里,多出了一个小象的框

5、点击Map/Reduce下方的白色区域,new一个hadoop location。
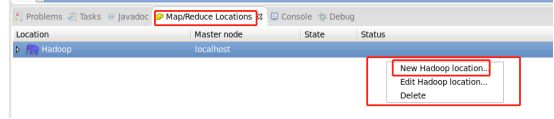
6、配置相应的端口
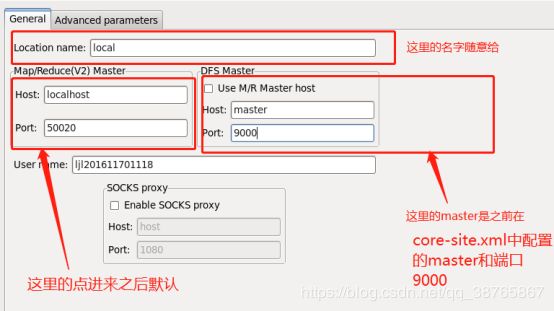
7、确认之后控制台界面那边会多出一个配置

点击上面的hadoop出现提示,不用理睬
8、点击左上角的File,然后新建,然后点击其他

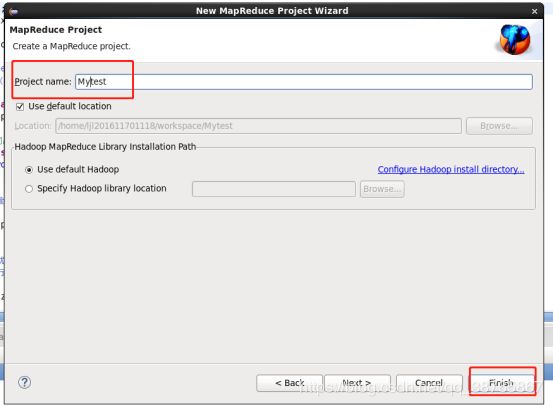
9、创建一个Map/Reduce project

点击next,然后输入自己的工程名称,点击finish,会自动帮你生成一个带hadoop相应的jar包的文件,左上角还会出现一个DFS文件。

DFS location是要可以打开的,才算是正确执行完成,不然是错误的哦。在这里就是你的hdfs文件存储的路径,可以在这里直接创建、删除、上传、下载文件,每次执行完记得右键刷新,因为不会自动刷新

10、把hadoop下的三个文件复制到在项目下,可以在eclipse中执行hadoop
Core-site.xml
Hdfs-site.xml
Log4j.properties
这三个文件在你安装的hadoop下的etc下的hadoop文件夹里面

这个是我的个人目录:/home/ljl201611701118/hadoop-2.5.2/etc/hadoop
移动到工程目录src的同级目录

到这一步,已经完成了eclipse中配置hadoop插件了,可以愉快的在eclipse上进行hadoop的代码编写啦。
四、测试
- 写一个对文件中的数字进行排序的代码
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Sort {
//map将输入中的value化成IntWritable类型,作为输出的key
public static class Map extends Mapper{
private static IntWritable data=new IntWritable();
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
String line=value.toString();
data.set(Integer.parseInt(line));
context.write(data, NullWritable.get());
}
}
//reduce将输入中的key复制到输出数据的key上,
//然后根据输入的value-list中元素的个数决定key的输出次数
//用全局linenum来代表key的位次
public static class Reduce extends Reducer{
//实现reduce函数
public void reduce(IntWritable key,Iterable values,Context context) throws IOException,InterruptedException{
for(NullWritable val:values){
context.write(key, NullWritable.get());
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");//创建一个job,设置名称
job.setJarByClass(Sort.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
//he Reduce shu chu dui ying
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
//设置输入文本路径
FileInputFormat.addInputPath(job, new Path("/myMapreduce"));
//设置mp结果输出路径
FileOutputFormat.setOutputPath(job, new Path("/myMapreduce/wordcount")); System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 2、编写sort.txt文件

3、上传到指定目录DFS中

DFS localtion下创建这个目录,并上传文件
创建目录

上传文件,先把sort文件移动到linux中,然后点击upload file to DFS...

上传成功

4、运行
右键点击文件,Run As --》 java Application

5、运行成功

6、查看结果
在DFS location下查看(文件太大好像无法查看,可以通过命令行查看)
自动生成程序中写的输出目录,part-r-00000就是输出结果


通过命令行查看
hadoop fs -cat /myMapreduce/wordcount/part-r-00000 grep | head -n 300


配置和运行都成功啦,开始继续学习啦。
如果对你有帮助,点个赞啦,(๑′ᴗ‵๑)I Lᵒᵛᵉᵧₒᵤ❤