Java后端面试系列-数据库篇
Java后端面试系列-数据库篇
- 1 概述
- 1.1 关系型数据库主要考点
- 1.2 一个面试题引发的"血案"
- 2 索引模块
- 2.1 为什要使用索引
- 2.2 什么样的信息能够成为索引
- 2.3 索引的数据结构
- 2.3.1 二叉查找树上阵
- 2.3.2 B-Tree
- 2.3.3 B+ -Tree
- 2.3.4 结论
- 2.3.5 Hash索引
- 2.3.6 BitMap索引
- 2.4 密集索引和稀疏索引的区别
- 2.4.1 额外知识
- 2.5 衍生出来的问题,以mysql为例
- 2.5.1 如何定位并优化慢查询Sql
- 2.5.2 联合索引的最左匹配原则的成因
- 2.5.3 索引是建立得越多越好吗
- 3 锁模块
- 3.1 MyISAM与InnoDB关于锁方面的区别是什么
- 3.2 适用场景
- 3.2.1 MyISAM适合的场景
- 3.2.2 InnoDB适合的场景
- 3.3 锁的分类
- 3.4 数据库事务的四大特性
- 3.5 事务隔离级别以及各级别下的并发访问问题
- 3.6 InnoDB可重复读隔离级别下如何避免幻读
- 3.7 RC、RR级别下的InnoDB的非阻塞读如何实现
- 4 语法部分
- 4.1 GROUP
- 4.2 HAVING
- 5 数据库三范式
1 概述
1.1 关系型数据库主要考点
1.2 一个面试题引发的"血案"
- 问:如何设计一个关系型数据库?
- 答:

- 存储(文件系统):持久化
- 程序实例:包含以下8个模块。
存储模块:磁盘IO速率是瓶颈,得设计优化方法,比如:一次读取多条数据进入内存。
缓存机制:不宜过大,且有淘汰机制比如:LRU
SQL解析:将SQL语句进行解析
日志管理:记录操作记录,比如binlog
权限划分:记录多用户管理的权限划分模块,一般DBA关心
容灾机制:
索引管理:优化数据查询速率
锁管理:使之支持并发操作
2 索引模块
常见问题
- 为什要使用索引?
- 什么样的信息能够成为索引?
- 索引的数据结构?
- 密集索引和稀疏索引的区别?
2.1 为什要使用索引
答:快速查询数据。
若使用全表扫描,在数据量小的时候没有问题,一旦数据量大了,查询效率会降低;而索引类似于字典的偏旁部首,先找偏旁部首,可以更快速找到想要的数据。
2.2 什么样的信息能够成为索引
答:主键、唯一键以及普通键等
2.3 索引的数据结构
- 生成索引,建立二叉查找树进行二分查找
- 生成索引,建立B-Tree结构进行查找
- 生成索引,建立B±Tree结构进行查找
- 生成索引,建立Hash结构进行查找
2.3.1 二叉查找树上阵
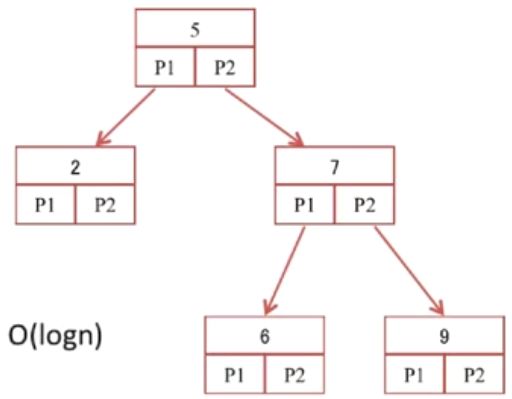
首先先说二叉查找树,这是会出现一个问题:当往一边增加会出现下面的情况:

结果是:二叉查找树退化成一个链表,时间复杂度为O(N)。
此时一个解决办法是通过旋转,维持树的平衡,比如:平衡二叉树、红黑树。但是又有一个问题:磁盘IO是关键,而磁盘IO访问次数与树的深度直接相关,比如访问数字“6”,就需要三次,还可以优化吗?
很明显,问题出在这些平衡树的子树最多两个,能不能多个呢,此时B-Tree站出来了。
2.3.2 B-Tree
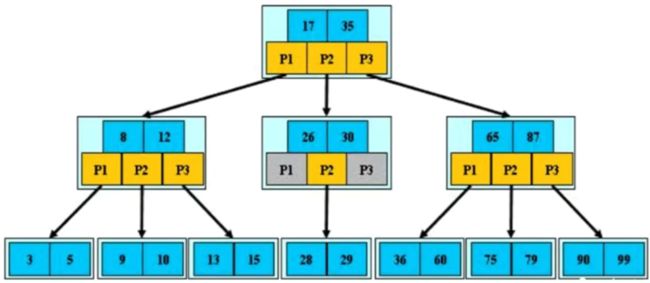
定义:
- 根节点至少包括两个孩子
- 树中每个节点最多包含有m个孩子(m>=2)
- 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
- 所有叶子节点都位于同一层
- 假设每个非终端节点中包含有 n n n个关键字信息,其中:
- K i ( i = 1... n ) K_i(i=1...n) Ki(i=1...n)为关键字,且关键字按顺序升序排序 k ( i − 1 ) < K i k(i-1)
k(i−1)<Ki - 关键字的个数 n n n必须满足: [ c e i l ( m / 2 ) − 1 ] < = n < = m − 1 [ceil(m/2)-1] <= n <= m-1 [ceil(m/2)−1]<=n<=m−1
- 非叶子结点的指针:P[1],P[2],…,P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其他P[i]指向关键字属于(K[i-1],K[i])的子树
- K i ( i = 1... n ) K_i(i=1...n) Ki(i=1...n)为关键字,且关键字按顺序升序排序 k ( i − 1 ) < K i k(i-1)
看起来,B-Tree已经不错了,但还有更好地选择。
2.3.3 B+ -Tree
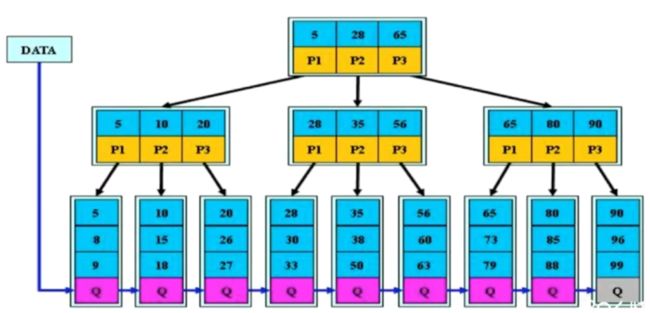
B+树是B树的变体,其定义基本与B树相同,除了:
- 非叶子结点的子树指针与关键字个数相同
- 非叶子结点的子树指针P[i],指向关键字值[K[i],K[i+1])的子树
- 非叶子结点仅用来索引,数据都保存的叶子节点中
- 所有叶子节点均有一个链指针指向下一个叶子节点
2.3.4 结论
B+Tree更适合用来做存储索引
- B+树的磁盘读写代价更低
- B+树的查询效率更加稳定
- B+树更有利于对数据库的扫描
2.3.5 Hash索引
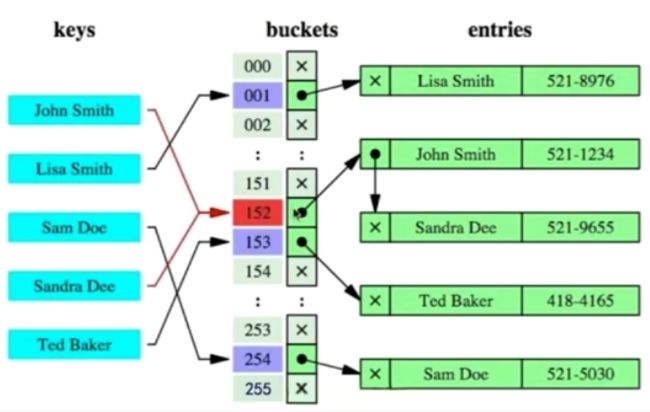
优点:查询效率高
缺点:
- 仅能满足“=”,“IN”,不能使用范围查询
- 无法用来避免数据的排序操作
- 不能利用部分索引建查询
- 不能避免表扫描
- 遇到大量Hash值相等的情况后性能并不一定比B-tree索引高
2.3.6 BitMap索引
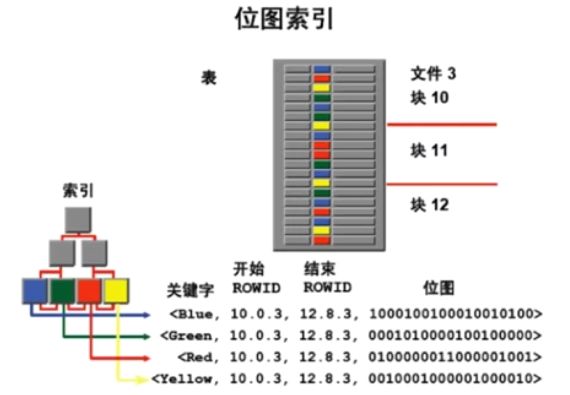
- 高效,适合统计
- 只适用于某个字段只有有限个取值的情况下
- 锁的粒度大
2.4 密集索引和稀疏索引的区别
- 密集索引文件中的每个搜索码值都对应一个索引值
- 稀疏索引文件置为索引码的某些值建立索引项


2.4.1 额外知识
针对Mysql,MyISAM都是稀疏索引,而InnoDB有且仅有一个密集索引
InnoDB
- 若一个主键被定义,该主键则作为密集索引
- 若没有主键被定义,该表第一个唯一非空索引则作为密集索引
- 如不满足上述条件,则InnoDB内部会生成一个隐藏主键(密集索引)
- 非主键索引存储相关键位和其对应的主键值,包含两次查找
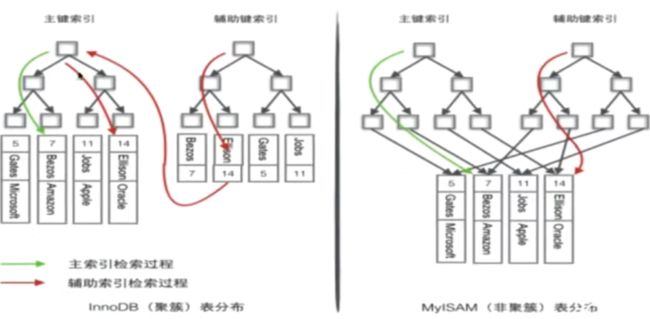
实际的样子

上面两个文件就是InnoDB的,下面三个是MyISAM的
.frm:代表表的结构.ibd:代表InnoDB表的数据和索引.MYD:代表MyISAM的数据.MYI:代表MyISAM的索引
2.5 衍生出来的问题,以mysql为例
- 如何定位并优化慢查询Sql
- 联合索引的最左匹配原则的成因
- 索引是建立得越多越好吗
2.5.1 如何定位并优化慢查询Sql
大致思路如下:
- 根据慢日志定位慢查询sql
- 使用 explain等工具分析sql
- 修改sql或者尽量让sql走索引
(1)根据慢日志定位慢查询sql
SHOW VARIABLES LIKE '%quer%';
查询一些系统变量:
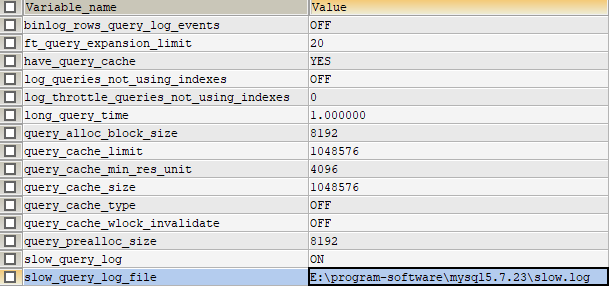
主要由三个变量值得注意:
long_query_time :查过这个时间,就算是个慢查询
slow_query_log :是否开启慢差日志
slow_query_log_file:慢差日志保存位置
修改命令如下:
SET GLOBAL long_query_time = 1;
SET GLOBAL slow_query_log = ON;
SET GLOBAL slow_query_log_file = 'E:\\program-software\\mysql5.7.23\\slow.log';
开始查询:
SELECT NAME FROM t_teacher ORDER BY NAME DESC;
可以打开slow.log

花了近10秒
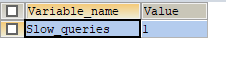
也可用通过命令查询本次连接慢差的次数:
SHOW STATUS LIKE '%slow_queries%';
(2)根据explain工具分析这条sql
EXPLAIN SELECT NAME FROM t_teacher ORDER BY NAME DESC;
重点是看type和Extra两个字段
- type

- extra

(3)修改sql或者尽量让sql走索引
改
EXPLAIN SELECT id FROM t_teacher ORDER BY id DESC;
加索引
ALTER TABLE t_teacher ADD INDEX idx_name(NAME);
2.5.2 联合索引的最左匹配原则的成因
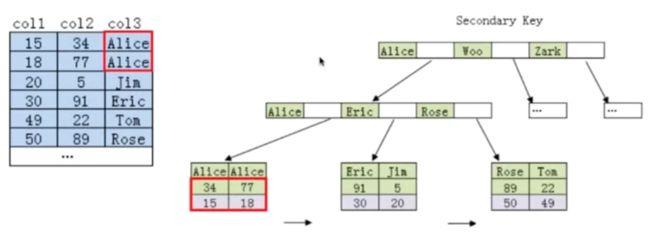
2.5.3 索引是建立得越多越好吗
不是。
- 数据量小的表不需要建立索引,建立会增加额外的开销。
- 数据变更需要维护索引,因此需要更多的维护成本
- 更多的索引意味着需要更多的空间开销。
3 锁模块
常见问题
- MyISAM与InnoDB关于锁方面的区别是什么
- 数据库事务的四大特性
- 事务隔离级别以及各级别下的并发访问问题
- InnoDB可重复读隔离级别下如何避免幻读
- RC、RR级别下的InnoDB的非阻塞读如何实现
3.1 MyISAM与InnoDB关于锁方面的区别是什么

InnoDB中在SQL没用到索引时,走的表级锁;用到索引,走的行级索。
3.2 适用场景
3.2.1 MyISAM适合的场景
- 频繁使用全表count语句
- 对数据库进行增删改的频率不高,查询非常频繁
- 没有十五
3.2.2 InnoDB适合的场景
- 数据库的增删改操作很多时
- 对数据库的可靠性要求高时,要求支持事务
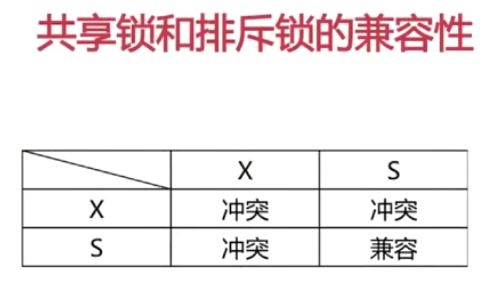
3.3 锁的分类
- 按锁的粒度划分,可分为表级锁、行级锁、页级锁
- 按锁级别划分,可分为共享锁、排它锁
- 按加锁方式划分,可分为自动锁、显式锁
- 按操作分,可分为DML锁,DDL锁
- 按使用方式划分,可分为乐观锁,悲观锁
3.4 数据库事务的四大特性
ACID
- 原子性
- 一致性
- 隔离性
- 持久性
3.5 事务隔离级别以及各级别下的并发访问问题
问题:
- 更新丢失——read uncommitted(读未提交)解决
- 脏读——read committed(读已提交)解决
- 不可重复读——repeatable read (可重复读)解决
- 幻读——serializable(序列化)解决
3.6 InnoDB可重复读隔离级别下如何避免幻读
- 表象:快照读(非阻塞读)——伪MVCC
- 内在:next-key锁(行锁+gap锁)
问:对主键索引或唯一索引会用Gap锁吗?
- 如果where条件全部命中,则不会用Gap锁,只会加记录锁。

- 如果where条件部分命令或全部不命中,则会用Gap锁,记录锁。
Gap锁会用在费唯一索引或者不走索引的当前读中
- 非唯一索引
- 不走索引
3.7 RC、RR级别下的InnoDB的非阻塞读如何实现
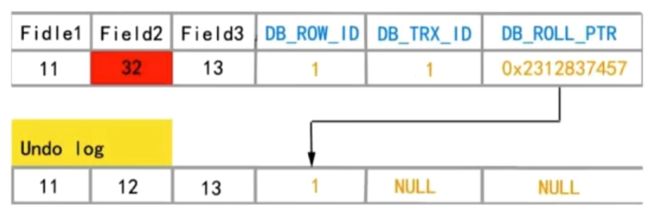
- 数据行里的DB_TRX_ID(最后一次修改的事务ID)、DB_ROLL_PTR(回滚指针,指向undo log中修改前的行)、DB_ROW_ID(插入数据时自增)字段
- undo日志(存储的老版本数据,分别insert undo log和update undo log)
insert undo log指定的insert操作的undo log,只在事务回滚时需要,并且在提交事务之后就会丢弃;
update undo log:存储update、detele操作,不仅在事务回滚时需要,快照读时也需要,只有当快照中不涉及该日志中的操作,才会被删除。
- read view(还会根据你的事务ID得出你可见的数据,因为越新打开的事务,事务ID越大)
注:只有非序列化隔离级别下的select语句为快照读;其他是当前读,比如:select .. lock in share mode,select ... for update,update delete insert
4 语法部分
关键语法:
- GROUP BY
- HAVING
- 统计相关:CUNT、SUM、MAX、MIN、AVG
4.1 GROUP
- 满足“select 子句中的列名必须为分组列或列函数”
- 列函数对于group by子句定义的每个组各返回一个结果
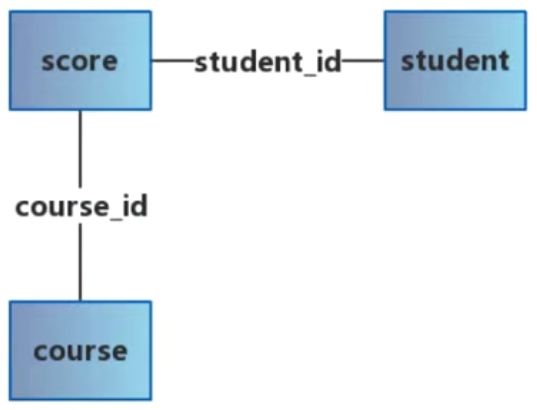
# 查询所有同学的学号、选课数、总成绩
SELECT student_id,COUNT(course_id),SUM(score)
FROM score
GROUP BY student_id
# 查询所有同学的学号、姓名、选课数、总成绩
SELECT score.student_id,student.`name`,COUNT(course_id),SUM(score)
FROM score, student
WHERE score.`student_id` = student.`student_id`
GROUP BY score.student_id
4.2 HAVING
- 通常与GROUP BY子句一起使用
- WHERE过滤行,HAVING过滤组
- 出现在同意sql的顺序:WHERE>GROUP BY>HAVING
# 查询平均成绩大于60分的同学的学号和平均成绩
SELECT student_id, AVG(score)
FROM score
GROUP BY student_id
HAVING AVG(score) > 60
# 查询没有学全所有课的同学的学号、姓名
SELECT s.student_id, s.name
FROM student s, score sco
WHERE s.student_id = sco.student_id
GROUP BY sco.student_id
HAVING COUNT(sco.course_id) != (SELECT COUNT(*) FROM course);
5 数据库三范式
-
1NF:字段不可分;
-
2NF:有主键,非主键字段依赖主键;
-
3NF:非主键字段不能相互依赖,不存在传递依赖