ElasticSearch学习之(三)--搜索入门从lucene到Soler,ElasticSearch
一. 什么是搜索
搜索大白话来说就是通过部分信息查找我们需要的更多更详细的信息。例如:通过百度,Google等各种工具对视频, 新闻,商品等各种我们需要获取的信息的检索。按照搜索的使用场景大概可以分为以下几种:
垂直搜索:是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
互联网搜索:各类电商(某宝,某东,某多等),招聘网站,视频网站,新闻网站等都含有高级搜索功能。
IT系统内部搜索:OA,各类后台管理系统的通过一些员工姓名,工号等搜索员工详细信息。或者通过部分产品的名字,状态,颜色,型号等属性搜索相对应的产品。
面对以上的使用场景我们常见检索的实现方式也是日新月异,花样百出,但是归根到底也就大致分为以下几种:
1. 数据库检索
做开发的大部分都知道我们需要搜索的一些产品信息,或者其他信息他的来源往往是数据库(绝大多数)。视频网站的视频地址,新闻网站的新闻信息,招聘网站的招聘信息等等,这些个数据源极有可能都是存放在数据库的。操作过数叫的同学都了解通过创建一些数据库字段索引在查询部分信息的时候会提高效率,但是随着数据量的增大,随着业务需求搜索响应时间的提升。通过数据库直接检索的方式已经被淘汰啦。当然可能有人说用缓存redis,memercache等等。但是有一点数据量上千万或者上亿就不是这些缓存能够满足的。
2.全文检索
数据库假如有100万数据,如果我需要查询出姓名包括“张三”的,可能就需要查询100万条数据,逐个比对还不能拆解需要搜索的词汇。这就是全文检索。
3.倒排索引
倒排索引其实上一篇都说过了,倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。

二.认识Lucene
1.什么是Lucene
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
然而Lucene的全文检索就是对文档中所有词句进行分词处理,然后对这些分词处理过的单词建立倒排索引,这样就大大提高了检索的效率。
2.认识Lucene
Lucene目前最新的版本是7.x系列,但是在企业中还是用4.x比较多。老版本下载地址:http://archive.apache.org/dist/lucene/java/
正如上述Lucene也就是一个底层提供简单API的工具包 jar 包。2004年 Solr 一款基于Lucene开发的企业级的搜索引擎产品诞生。同一年 Shay Banon(也是Hadoop的创始人) 在2004年创造了Elasticsearch的前身,称为Compass,并于2010年2月发布了Elasticsearch的第一个版本。也是基于Lucene开发的企业级的搜索引擎产品。
3.Lucene的基本使用
Lucene提供API来实现对索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)。创建索引的流程:

文档Document:数据库中一条具体的记录
字段Field:数据库中的每个字段
目录对象Directory:物理存储位置
写出器的配置对象:需要分词器和lucene的版本
三.认识Solr
1. 什么是Solr
Apache Solr (读音: SOLer) 是一个开源的搜索服务器。名字来源于 Search On Lucene Replication。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。Apache Solr 中存储的资源是以 Document 为对象进行存储的。每个文档由一系列的 Field 构成,每个 Field 表示资源的一个属性。Solr 中的每个 Document 需要有能唯一标识其自身的属性,默认情况下这个属性的名字是 id,在 Schema 配置文件中使用:id进行描述。

2.Solr工作原理
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。

3.Solr发展历史
2004年 CNET 开发 Solar,为 CNET 提供站内搜索服务
2006年1月捐献给 Apache ,成为 Apache 的孵化项目 2007年 Solr 孵化成熟,发布了1.2版,并成为 Lucene 的子项目
2010年6月,solr 发布了的1.4.1版,这是1.4的 bugfix 版本,1.4.1的solr使用的lucene是2.9版本的
solr 从1.4.x版本以后,为了保持和lucene同步的版本,solr直接进入3.0版本。
四.认识ElasticSearch
1.什么是ElasticSearch
ElasticSearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用ElasticSearch的水平伸缩性,能使数据在生产环境变得更有价值。ElasticSearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elastic Search 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。”Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticdsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
2.ElasticSearch的发展历史
Shay Banon在2004年创造了Elasticsearch的前身,称为Compass。在考虑Compass的第三个版本时,他意识到有必要重写Compass的大部分内容,以“创建一个可扩展的搜索解决方案”。因此,他创建了“一个从头构建的分布式解决方案”,并使用了一个公共接口,即HTTP上的JSON,它也适用于Java以外的编程语言。Shay Banon在2010年2月发布了Elasticsearch的第一个版本。
Elasticsearch BV成立于2012年,主要围绕Elasticsearch及相关软件提供商业服务和产品。
2015年3月,Elasticsearch公司更名为Elastic。
3.ElasticSearch对比Lucene

4.Elasticsearch和Solr比较


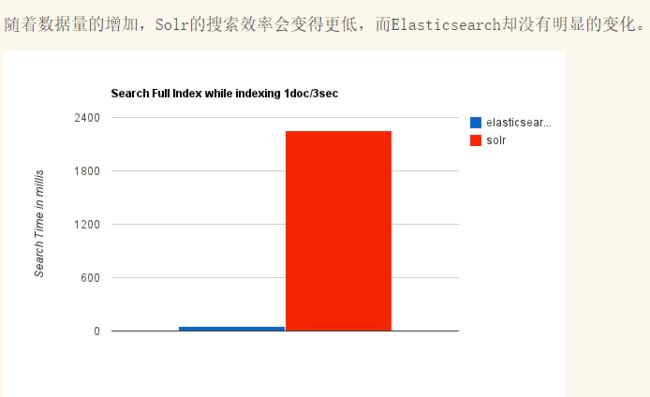
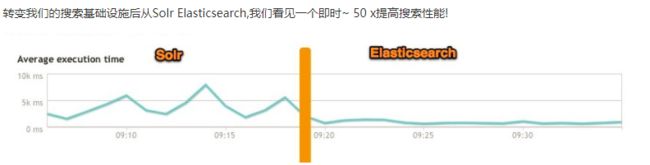
ElasticSearch vs Solr 总结
(1)es基本是开箱即用,非常简单。Solr安装略微复杂
(2)Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
(3)Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
(4)Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,但是随着版本的迭代更多更高级的API使用起来更加方便快捷。部分高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
(5)Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
(6)Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,但目前使用增长率很低,而 Elasticsearch相对开发维护者日渐壮大,社区活跃,更新快,使用频率越来越高。但学习使用成本较高。
如有披露或问题欢迎留言或者入群探讨
