Saliency Integration :An Arbitrator Model阅读总结
Saliency integration: An Arbitrator Model 2019.TMM总结
一、阅读总结
1. 本文提出了什么
- 文章提出了一种saliency integration的Arbitrator Model。
- 首先,将多个saliency model和external knowledge融合到reference map中。
- 其次,在对不带ground truth的saliency model的expertise(即质量、重要性、贡献)评估中,提出了两种不同的on-line model expertise评估方法,即基于统计的expertise评估方法AMS和基于潜变量的expertise评估方法AML。
- 最后,推导了一个Bayesian integration framework来reconcile具有不同expertise值的saliency model和reference map,经过数轮cellular automation,得到最终的saliency map。
2. 传统的方法有什么劣势
相关工作
| 作者 | 方法名称 | 具体内容 | 优点 | 局限性 | 作者的解决方法 | 文献索引 | 我的想法 |
|---|---|---|---|---|---|---|---|
| off-line saliency model | 通过使用预先准备的数据集优化特定的能量函数来权衡candidate model。 | 对特定的数据集,off-line saliency model的残差较小 | 一旦学习阶段完成,saliency integration model就固定下来,并且还需要为训练样本提供真实标签。此外,saliency integration model的参数设置仅对candidate model的特定组合有效,可拓展性是有限的。 | 本文使用的方法就是一种on-line saliency integration model。 | on-line model能直接通过待评价图像的特征来确定saliency maps的expertise,不需要任意预先收集的样本,因此,产生的expertise是图像特定的。与off-line saliency model相比,on-line saliency model不需要预先确定model,更加灵活高效。 | ||
| 每一个candidate saliency model的expertise都是相同的 | 以往的研究大多假设每个candidate saliency model的expertise(即权重或贡献)是相等的。 | 大大减轻了计算负担 | 没有考虑到每个candidate saliency model在预测图像时的预测能力是不一样,高级model的优势很容易被劣等 model的错误评价所淹没,那saliency integration model性能可能会降低。 | 提出基于统计的expertise评估方法AMS和基于潜变量的expertise评估方法AML,来对saliency model的expertise进行评估。 | 41,19 | 因为每个saliency model对不同的图像的评价结果肯定不一样,对superior model赋予高的权重,对inferior model赋予赋予低的权重,这样的 integration的效果是最好的。但是,评价一个model的好坏是一个比较困难的,本文的核心问题就是对每个model进行arbitrate,得出每个 model相适应的权重。这个arbitrate的方法是需要特别关注的地方。 | |
| Mai等人 | 使用没有ground truth的 图像对saliency model的 性能进行评估 |
使用k种不同的saliency目标检测方法来生成k个saliency map。利用ROC曲线下的AUC作为saliency map的客观质量度量。通过每个图像的AUC得分对其k个saliency map进行排序来获得每个图像的ground truth排序。 | 对candidate saliency model排序后即可知道每个saliency model的质量优劣,从而可以选择那个最佳的saliency model进行saliency目标检测。 | 因为该方法是without ground truth的,所以它所得到排序结果并不能详细地描述每个saliency model在图像上的性能。 | 文提出的方法也是基于without ground truth的,那要关注它的方法是否就能够准确estimate saliency model在图像上的性能。 | 42 | 本文提出的方法也是基于without ground truth的,那要关注它的方法是否就能够准确estimate saliency model在图像上的性能。 |
| Le Meur | 使用M-estimaor权重函数对candidate model进行estimate | 训练一个M-estimaor的权重函数,来评估 candidate saliency model的expertise,根据它们到candidate saliency model的距离线性总和来检测outlier model,并减少outlier model的expertise。 | M-estimaor表明对前两个最佳model的saliency map进行平均,或者只考虑一个专用的训练数据集时,确实可以增强预测的准确率。 | 考虑全部candidate model时,M-estimaor的表现类似于平均权重的方法,这表明计算出的权重远不能准确地指定candidate model的expertise。 | 本文考虑到只要质量接近真正的最佳地图,错误的saliency map仍然有用,所以采用对所有saliency model赋予不同权重的方式进行saliency model integration。 | 37 | Le Meur的文章说,在实践中,只要质量接近真正的最佳地图,错误的saliency map仍然有用。所以采用了百分比的方式比只对前两个最佳model的saliency map进行平均的结果可能更有效。 |
| Zhang,Quan等人 | 基于superpixel的saliency model integration expertise评估 | Quan等人:引入superpixel的概念,来评估每个model的expertise。为每个saliency model定义精度参数来表示其对特定图像场景的expertise,并为每个图像区域定义一个difficulty来表示它被正确检测的难度。利用GLAD model可以自动确定每个弱saliency model的精度和每个图像区域的难度,进而计算每个弱saliency标签对每个特定图像区域的professionality。最后,根据弱saliency ground truth及其所对应的professionality,推导出每个图像区域的强saliency标签。 Zhang等人:在每个单独的图像中执行图像内融合以获得超级像素级置信度和超级像素级融合图,并对所有训练图像执行图像间融合以获得图像级置信度和图像级融合图。然后,生成dynamic learning curriculum和pseudo ground-truth maps,为训练深度saliency目标检测器提供监督。最后,将得到的深度saliency目标检测器用于更新下一学习阶段的weak saliency map collection。 |
引出superpixel的概念,降低了后续处理任务的计算成本,并且剔除一些outlier像素点。 | 采取了superpixel的方法,可能会丢失图像的细节信息,saliency检测可能会受到影响。 | 引入了external knowledge map和严格的一致意见,Arbitrator Model只有在大多数candidate saliency model投票认为图像superpixel区域saliency,以及external knowledge确认其saliency时,才判断图像superpixel区域为saliency。这种共识很大程度上减少了图像superpixel区域被误判为saliency的可能性。 | 48,49 | superpixel会丢失图像的部分细节信息,认为superpixel的优势大于其劣势了。选取一个优秀的superpixel方法对于图像saliency检测来说应该是非常重要的。 |
3. 解决方案
3.1 概述
本文着重研究了on-line saliency integration方法,以同时应对一下两个挑战:
1.saliency integration方法应该允许在on-line的情况下,有效地确定每个candidate saliency model的expertise。
2. 即使大多数model都会对图像上的某个区域产生误判,也应该有一种纠错机制来纠正candidate model。
基于上述两个原则,本文提出了一个on-line saliency integration framework,本文称之为Arbitrator Model。推导了一个包含以下两个部分的Bayesian framework来reconcile这些原则:
- 融合多个saliency model和external knowledge的一致意见,来得到reference map。此共识原则可有效地纠正candidate model的误导。
- 对不带ground truth的saliency model的expertise评价方法提出了两种不同的on-line model expertise评估方法:一种是基于统计的方法,另一种是基于隐变量的方法。这两种方法在没有给定测试图像的ground truth下计算candidate model的expertise,并得到了candidate model 合理的expertise。
3.2 重要名词解释
1.Arbitrator model
本文提出一个Bayesian framework,命名为Arbitrator Model(AM).AM model让测试图像和由P saliency model获得的相应的saliency heat map作为输入。主要由两部分组成。
- reference generator:充分利用input heat map和external knowledge的一致意见。
- online estimator:将P saliency model作为candidate model,评估它的expertise。
2.Bayesian Integration Framework

在此图中,输入是original image和P saliency maps。分析过程如下:
- 上通道中,external knowledge对original image进行处理,并使用最大似然估计的方法,得到intensity map。
- 下通道中,通过saliency model得到相应的saliency heat maps。
- 当超过半数的candidate saliency model投票认为superpixel saliency,且external knowledge也认为它saliency时,AM才认为它saliency。共识达成后,可得到reference map。
- 进入cellular automation阶段。通过reconcile the reference map和expertise,通过几轮迭代,计算得到final saliency map。
2.1 Reference generator
本文充分利用candidate model和external knowledge的能力,并采取严格的一致性原则,来解决candidate saliency model误判的问题。
获得reference map的三个步骤如下:
- 首先,基于external knowledge计算external saliency intensity map。
- 然后,基于candidate model和external knowledge map的一致意见,得到consensus map。
- 最后,以2.4中写的方式,传播consensus map而得到reference map。
2.2 The External Knowledge Map
我们通过引入external knowledge map,来纠正candidate model的错误。
研究了三种不同的模型来计算external knowledge map。分别是
- 广泛接受的boundary prior算法。
- 最先进的传统saliency model CCM。
- 最先进的深度学习方法DHSNet。
最后,采用了性能最好的深度学习方法作为external knowledge。
2.3 Consensus
共识如下:
- 超过半数的candidate saliency model投票superpixel saliency时。
- external knowledge也认为它saliency。
只有同时满足以上两个条件,AM才判定superpixel为saliency。这样consensus大大减少了unsaliency superpixel被误判为saliency的机会。
2.4 The Reference Map via Propagation
consensus map是高精度的saliency map,但是只保存图像的某些部分的saliency信息,因此我们需要将saliency信息扩展到整个图像。采用传播方法迭代地将consensus map上的这些值扩散到整个图像。传播方法首先将图像过分割成超像素,并构造无向图,该无向图由超像素的一组顶点和表示相邻顶点之间相似性的一组边组成。然后,选择传播种子以在几个迭代内空间扩散到整个图像。
2.5 Cellular automation

- CA的每一次迭代,都融合了reference map、the p-th saliency intensity map的expertise αp和其他binary maps的expertise βp(q≠p)。
- 在每一次迭代中,Sp和阈值γp都会被更新。
同时,CA过程中,reference map都会被更新,其更新步骤如下:
- t = 0时,由external knowledge集成的reference map被定义为S0Ref.
- 之后,每个candidate saliency map都在进行更新,如Eq.4。p-th model 的St+1p都是基于之前的p-th model的αp,Stp来进行更新的。
- 因此,在t > 0时,the reference map StRef通过对candidate saliency map求平均来更新,如Eq.5。external knowledge 则不再被集成。所以,the external knowledge的影响是适当且隐性的。
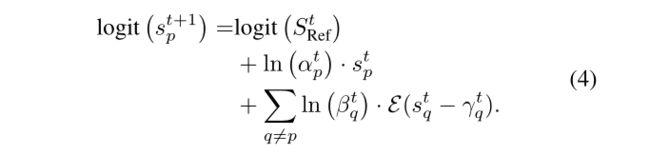

3.Model-expertise estimator
在此项工作中,cellular automata(CA)被用来更新current saliency intensity map。同时,reference map是通过平均candidate saliency map的方式来更新的,间接地更新了reference map。CA基于如下规则更新saliency intensity map:
- 首先,很自然地想到可以将candidate saliency map设计成为用于更精确估计的连续值的intensity map。
- 然而,由于不同的saliency model具有不同的语义含义和幅度,我们引入了threshold,除了p-th candidate model使用连续的map,而其他candidate model使用binary map。
- 在CA过程中,saliency intensity map和saliency binary map都被集成,由于binary map若被更新则会不可避免地丢失精度,所以只有saliency intensity map会被更新。
- 在没有监督信息的前提下,本文提出了两种online方法来获得expertise。一种是基于统计学的方法AMS,如Eq.3所示。另一种是基于潜变量expertise和difficulty的方法AML。计算如Eq.24。

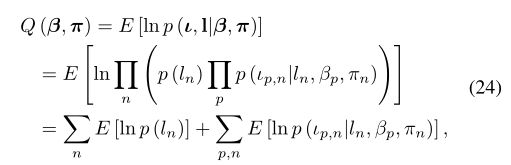
Statistics-based Expertise
Latent-variable-based Expertise
4. 主要贡献
| 贡献名称(按贡献大小从上到下) | 为了解决了一个什么问题,如何解决的? | 输入 | 输出 | 图片索引 | 我的看法 |
|---|---|---|---|---|---|
| Arbitrator Model (AM) | 主要由两部分组成: 1.reference generator: 充分利用input heat maps和external knowledge的consensus。2.online estimator:有效地确定每个candidate saliency model的expertise,即使在大多数model都对图像上的某个区域产生误判时,AM也应该有一种纠正机制来纠正它们。 |
由saliency model获得的saliency heat maps和and测试图片 | 最终的saliency map | Fig1 | |
| Bayesian Integration Framework | 充分利用external knowledge和所有candidate saliency model的特征,采用多数投票的方式来生成reference map。Bayesian integration framework将不同expertise的reference map和saliency map与cellular automation(CA)进行reconcile,以计算最终的saliency map。 | 由saliency model获得的saliency heat maps和and测试图片 | final saliency map | Fig1 | |
| Reference generator | 获得reference map的三个步骤:1. 首先,基于external knowledge计算external saliency intensity map。2. 然后,基于candidate model和external knowledge map的一致意见,得到a consensus map。3. 最后,传播consensus map而得到reference map。 | 测试图像和由P saliency model获得的相应的saliency heat map | reference map | ||
| The External Knowledge Map | 引入三种不同的SOTA方法来计算external knowledge map:1.引入knowledge map from assumptions:假设一个superpixel区域与边界superpixel区域的差异越大,superpixel区域就越saliency。具体方法为:将图像上第n个superpixel的平均CIELab特征描述为{cn},并选择四个边界上的superpixel作为boundary seed。利用K-均值算法将boundary seed分为K个簇。计算其与每个簇的外观相似性。如果超级混合体仍然与其最相似的簇有很大的不同,那么它更可能是显著的。可得到external knowledge map Sext。 2.引入Knowledge Map from Traditional Methods:基于轮廓闭合的模型(CCM)获得external knowledge map。CCM在supervised saliency model中是SOTA的,它将闭合完整性和闭合可靠性结合起来进行显著目标检测,具有纠正inferior saliency information的能力。 3.引入Knowledge Map from Deep Methods:采用一种基于卷积神经网络的端到端的深层网络来检测显著目标。 |
original image | external knowledge map | 引入三种SOTA的方法,来获得external knowledge map,其中,DHSNet模型比基于预先计算边界先验模型和CCM模型的效果都要好。本文中的external knowledge是基于DHSNet的。 | |
| cellular automaton | 如Fig.4所示。αp表示the expertise of the p-th saliency intensity map。βq表示the p-th binary map。在cellular automation的每一次迭代中,CA融合reference map、the p-th saliency intensity map Sp with its expertise αp and the rest binary maps with varying expertise βp(q≠p) by the expertise estimator into the final saliency map。Sp和阈值γp也是随着每一次迭代所更新。ε(Sp-γp)阈值化the q-th saliency intensity map tp get the binary map。 | reference map、the p-th saliency intensity map的expertise αp和其他binary maps的expertise βp(q≠p) | 每个saliency map的expertise | Fig.4 | 在CA过程中,AM模型通过对p-th candidate model使用连续的map而其他模型则使用binary map。 |
| Model-expertise estimator | 在没有监督信息的前提下,提出了两种online方法来获得expertise。一种是基于统计学的方法AMS,如Eq.3所示。另一种是基于潜变量expertise和difficulty的方法AML。计算如Eq.24。 | reference map、the p-th saliency intensity map的expertise αp和其他binary maps的expertise βp(q≠p) | 每个saliency map的expertise | Fig.4 |
作者认为,本文的主要贡献有三:
- 本文充分利用candidate saliency model和external knowledge的一致意见,提出了一个Bayesian saliency integration framework。
- 探索了on-line测量多个saliency model expertise的方法,并分别介绍了基于统计的expertise评估方法AMS和基于潜变量的expertise评估方法AML。
- 在最新的saliency integration方法中,本文中被评估的candidate model和其组合的数量是最大的。
5. 数据集
本文使用的数据集是ECSSD、ASD、Imgsal、DUT-OMRON数据集。
- ASD数据集是最广泛使用的数据集之一,具有来自MSRA-5000显著性对象数据库的1000幅图像,在场景中具有明显的显著性对象。
- mgSal数据集具有挑战性,包括六个复杂级别的235幅图像。
- ECSSD数据集包含1000幅具有复杂显著性的图像,而且图像中的对象在语义上是有意义的。
- DUT-OMRON数据集包含大量5168幅难度更大、更具挑战性的图像。
6. 实验结果
6.1 saliency object detection评价指标:
F-measure:F-measure作为Precision和Recall的加权调和平均值,具有非负权重,它的计算公式如下:


MAE表示saliency map和ground map之间的整体像素差异。
6.2 实验分析
大量组合的比较

1. Superior models combination
选取表现最优的前1个,前2个,前3个…前n个model作为candidate model。Table2的前7行表明,在每个组合中,AMS和AML都优top candidate saliency model和MCA model。因此,当superior saliency model被组合时,所提出的AM model表现良好。
2. Inferior models combination
选取表现最差的前1个,前2个,前3个…前n个model作为candidate model。AM model也大大改善了top candidate saliency model的F-measure。而其他on-line integration model如AVE, BN, MCA和M-est都降低了F-measure。
3. Random combination
从candidate saliency model中随机选取2个,3个,4个…n个模型作为candidate saliency model。
无论选择模型的数量多少,AM模型都能稳定地提高性能。
4. Deep models combination
从Table2的最后一大行中可以看出,当深度学习模型作为candidate model时,所有包含基于深度网络的reference map的AMmodel的集成结果都优于top candidate saliency mode。
Rationality of the Reference Map and the Expertise
通过评估遵循四种策略的各种组合的AM model,得出不管candidate model性能优劣,AM都能显显著地提高它的性能。这里,我们来讨论reference map和expertise的合理性。
1.reference map的必要性

- 从Table5中可以看出,与被作为一个candidate saliency map相比,external knowledge被整合到reference map有更好的性能。
- 此外,从Table2中可以看出,当使用相同的expertise estimation方法时,reference map的质量越好,集成的性能就越高。
- 在CA更新的过程中,reference map是通过平均candidate saliency map的方式来更新的。
所以我们做了一个小实验来评估reference map在CA的每一次迭代时需要被更新的必要性。在几种不同的candidate saliency model组合的实验中表明,若每一次迭代时更新reference map,F-measure值都要高于没有更新reference map的情况。
4. 为了定量研究reference map和expertise的贡献,我们还在ECSSD数据集上用包括DRFI、GP、LR、MB+、TLLT和UFO在内的candidate model组合来测试AM model的每个单元。第一列的基础框架式基于相等的expertise和没有external reference 的框架,后面几列在这个框架中添加了不同的组件。"L"代表基于潜变量的expertise估计,"S"代表基于统计的expertise估计。

从Table4中可以看出,基于reference map和expertise性能要明显高于基础框架。
5. 在CA过程中,AM模型通过对p-th candidate model使用连续的map而其他模型使用binary map。这种更新形式保持了当前 candidate saliency map的saliency intensity,并消除了其他saliency model具有不同语义含义和幅度的影响。

这是他们的测试结果例子,GT是真值,最后两列是本文AMS,AML方法的实验结果。

7. 总结
- 本文提出了一种Arbitrator Model作为一种有效的saliency integration model,以减轻off-line model训练的负担,使训练速度更快。一方面,AM model引入了reference map,通过充分学习saliency maps和expertise的特征,克服了劣等model的误导。另一方面,它不需要了解ground truth,以on-line的方式合理地学习saliency model的expertise。
- 本文还讨论了saliency model的两种on-line expertise评估方法,即基于统计的expertise评估方法和基于潜在变量的expertise评估方法。实验结果中很容易地观察到,如果没有reference map,基于统计的expertise比基于隐变量的expertise更准确。(6中的图中,AMS是基于统计的,AML是基于隐变量的)结合reference map,两种expertise评估方法的性能相似,然而,基于潜变量的方法的计算成本高于基于统计的方法。并且,当candidate model数量增加时,基于统计的expertise比基于潜变量的expertise更有效。
- AM model提出了一种新的 integration framework,该 framework 融合了reference map和the candidate saliency models of varying expertise。本文integrate多个saliency model的external knowledge的共识,来逼近真实的reference map,为了进一步提高reference map的质量,可以采用更复杂的方式引入expertise,即使用多个external knowledge而不是一个external knowledge来提高reference map的精确度。此外,多个saliency model可以以其他形式而不是多数投票来对reference map做出贡献,例如采用平均场近似方法。在此项工作中,如果reference map的质量较差,我们建议采用隐变量的方法,如果reference map的质量好,建议使用统计的方法。但是,如果reference map的质量不确定且不考虑计算成本,也可以将基于隐变量的方法和基于统计的方法结合起来,以稳定expertise评估的准确度。
- 目前,在AM model的cellular automaton更新的阶段,细胞的状态只受所有saliency maps相同位置的superpixel的影响。在未来,将探讨图像相邻superpixel的影响。此外,AM framework的reference map和expertise评估可应用于协同saliency检测和其他任务,如异常检测等。