SVM(一) latex手打公式 良心推导 原理分析 个人理解
文章目录
- SVM
- 简介
- 问题导入
- 最优超平面
- 间隔的度量
- 函数间隔
- 几何间隔
- 点到超平面距离的证明
- 如何解决线性不可分数据样本
- 为什么SVM是无穷维
- 求解最小几何间隔
- 拉格朗日乘子法
- 损失函数
- 求解推导
- 支持向量
- SVM(二)
SVM
简介
我相信这个算法很多人都知道,并且很多人都认为自己掌握的非常熟练了,这篇博客我准备了很久,其实这并不是我刚刚学习了SVM,而是学了很多用了很多时候从头再进行思考和总结,把自己会的东西给别人讲明白真的是一件不容易的事情。
我将利用很多我自己画的图片帮助大家理解,同时latex手打公式帮助大家进行部分重要公式的推导和分析。总而言之,我认为我写的这篇是我看过的SVM中讲的很详细的一篇blog,haha~。
问题导入
相信来看SVM的同学已经知道感知机了,那么我们看看感知机要解决的问题:
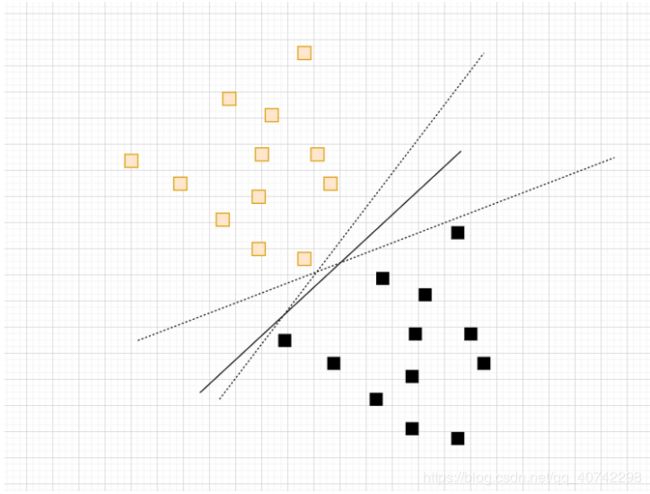
上图所示,现在有三个超平面,其实都可以做到我们想要的分类效果,但是肯定有一条线是最好的,但是感知机和逻辑斯蒂都不能解决最优超平面的问题,这时候SVM就可以解决。
另外我们在考虑一下,还是上面这个图,其实是很简单的,一条线就可以做到,但是如果是线性不可分呢,如下图

我画的有点随心啊,这就很明显不是一个很简单的问题了,SVM同样可以解决。
总结一下,SVM有什么贡献,或者说解决了什么问题:
- 给出最优的超平面
- 解决线性不可分情况
不过我们得详细讨论一下最优超平面的定义,还有怎么解决线性不可分情况。
最优超平面
还看第一幅图,其实我们可以凭感觉大部分人会说那一条实线相对另外两条是最优的,不过这还不够准确,最优超平面就是间隔最大化。也就是说最优超平面和最近的样本点的距离应该大于其他所有样本点的距离。
这就很好理解了,我们往往希望类间距离最大是比较好的划分评价标准之一。
这里还需要强调一下,SVM并不是找到真正的最优超平面,只是在最优超平面的附近,一种相对而言的最优超平面。
间隔的度量
这里有一个很有意思的概念需要分辨,就是我们使用的是什么间隔,或者说我们如何度量间隔。
先买个关子,间隔的度量公式(后面会详细推导):
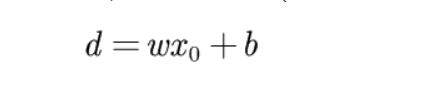
函数间隔
这就是数学家的一个定义,大家没必要去深究,记住就好,有点像一种规定。
d = wx + b ,但是如果w = 2w, b = 2b,相当于d就扩大了两倍。
这可就不对了,距离怎么可能是随着w和b变化的呢,这肯定就有问题,所以这不是我们使用的间隔的定义。
但是他也有名字——函数间隔。
几何间隔
那么怎么避免这种变化呢,也就是统一度量。
简单,我们都除以一个||w||,有点像都统一到最小单位去度量的感觉。
所以我们使用的间隔是:
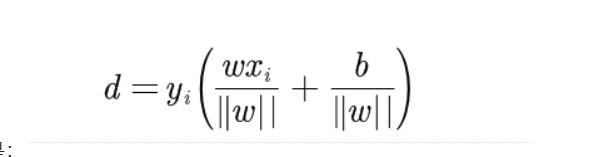
点到超平面距离的证明
为什么是上面这个公式呢?
其中有几个需要注意的地方:
- w是超平面的法向量
- yi是判别结果,只有-1和1,y是用来弄符号的
然后我们来推一下:
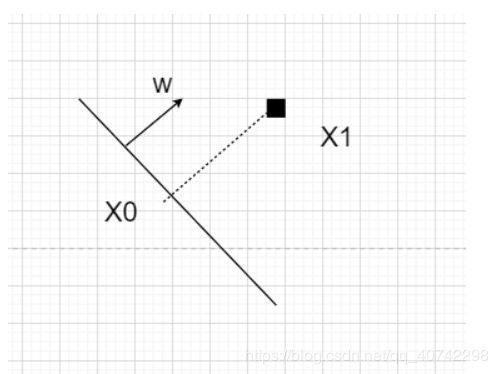
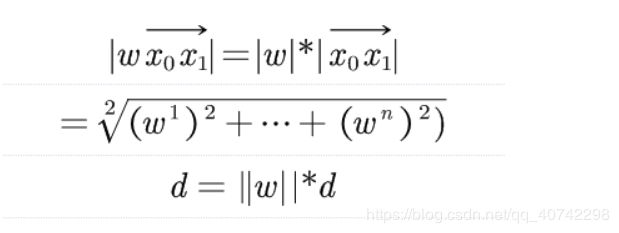

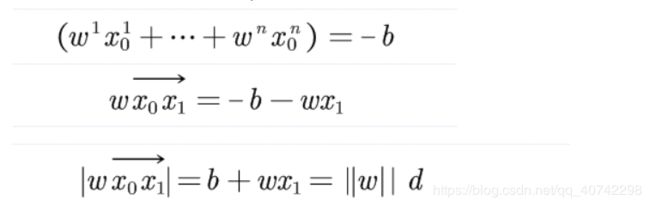
然后我们就得到了d。
如何解决线性不可分数据样本
这里还是用到第二幅图,也就是那个一个圆圈的超平面,我想大家都知道的说法是利用一个映射函数,来将不可分的样本映射到一个新的高维空间然后就变成了线性可分问题。
说实话我觉得这个说法实在是有点晦涩,或者说如果你认为这样就掌握了解决线性不可分样本的方法的话简直是大错特错了,真的是纸上谈兵。
下面我说说我的理解,当然可能有偏差,欢迎指正:
我们先明确一下,也就是前提条件:
1不同类的样本是存在差异的,不存在差异的样本那还分个什么劲啊,算是重要的废话吧
2相同的样本存在共性,好吧,这也是一句重要的废话
然后,我们举个例子:
小学生站队,笔直的站了一列,我们需要找到高于170的男生参加篮球队选拔:

好了现在来看一维的情况:
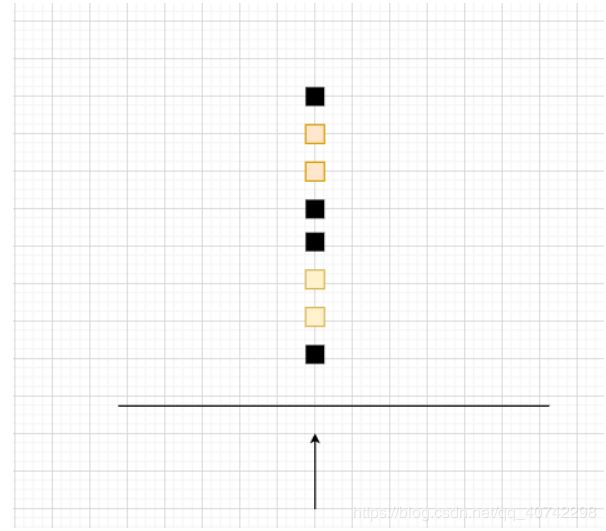
从这样一个角度去看,好吧 ,我就看到一个人,完全没法分辨。
那我们增加一个维度:
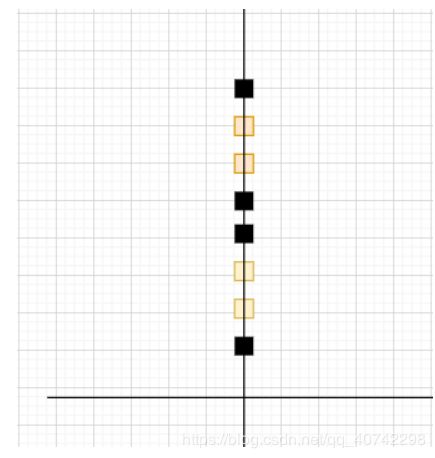
哎呀,可以分辨出来男女了至少,比如说黑色的方块是男生,好的,我们已经走出了第一步。
但是我们需要的是170以上的,那咋办呢,我们在增加一维,就是垂直于纸面的一个z轴,这我就不画了。
然后我们不就成功的找到了170以上的男生了吗。
什么意思呢,维度的增加会给我们更多的衡量,也就是描述的更多信息,信息越多,就越容易进行分辨。
因为不同类的样本一定存在差异,同类样本一定存在共性,所以我们可以得到这样一个推理:通过维度的上升,所有的线性不可分问题都可以这样去解决。
对了,那SVM是上升到多少维呢?100,1000?
SVM上升到无穷维,其实很好理解,往下看。
为什么SVM是无穷维
对于非线性划分,我们会使用核函数:
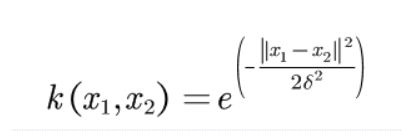
这里使用高斯核举例子。
我们可以使用泰勒展开式进行带入替换成下面的式子:
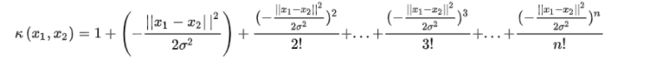
好了,这样似乎我们也找到了核函数的意义:
为什么我们需要核函数进行高维变换,其实就是用到了核函数的特点:
它可以将我们的分类空间扩展到无穷高维,但是其实是在扩展之前计算是在低维度计算的,所以虽然分类空间是高位的,但是我们并没有在高维进行计算。真的是厉害。不过我对核函数的理解可能还很浅薄,欢迎大家的观点。
求解最小几何间隔
通过我们上述讨论我们已经可以知道我们就是要求解最小几何间隔,我们得到下面的数学公式:
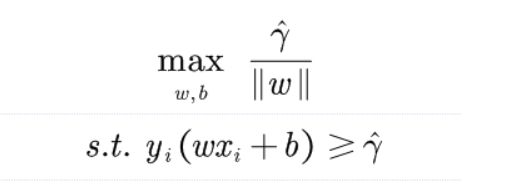
其实我们应该对这个式子感到敏感,因为这是非常明显的有约束的极值问题,我们使用拉格朗日乘数法可以解决。
不过在此之前我们进行一些数学变换,这里其实就是为了后面的求导后的计算更加简便,没有什么实际意义。都是等价变换。
最终我们得到:
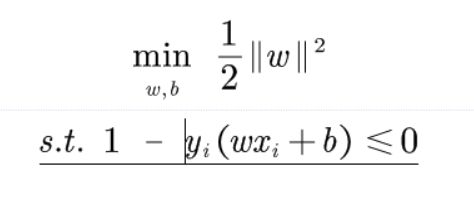
拉格朗日乘子法
大家看这个链接里面有详细的推导。
传送门
损失函数
然后我们得到损失函数,其实就是利用拉格朗日乘子法得到的一个转化后的无约束的极值求解问题。
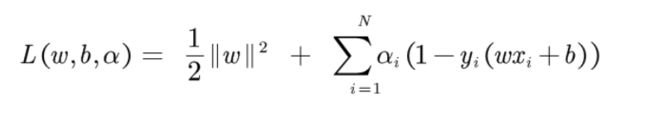
所以我们的目标就是求解:
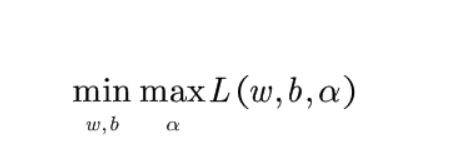
- 这里其实有一个点很多人不会注意,为什么是min max而不是max min,当然你会说不就是应该让损失函数最小吗,额其实我不是这个意思。换句话说为什么max下面是α而不是w,b。
- 这让我挺困惑的。
答:
- 首先,我们的得到的结果应该是符合约束的,也就是说后面一项的括号里(1-y(wx+b))一定是小于零的。那么根据拉格朗日乘子法,α应该是大于零的,所以最后L的结果是小于1/2 w^2的。好了说明在α为参数的情况下L只有最大值。
- 然后我们再看原始的有约束的极值问题方程组,我们要求得的就是1/2 W^2的最小值,所以以w和b为参数,放在min下面。
注:自己的一点思考,欢迎大家指正。
求解推导
现在我们要对上面这个式子进行求解了。
首先将它转换为对偶形式:
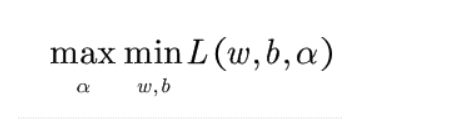
这其实没什么好说的了,对偶问题肯定是等价的。
然后我们来求解里面的minL():
将α看为常量。然后求导,求极值。
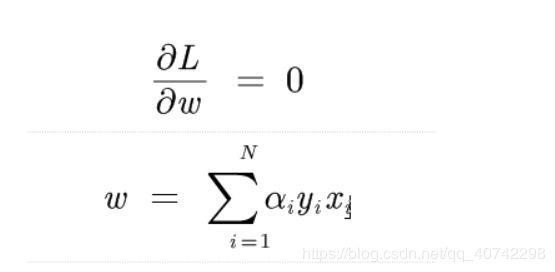
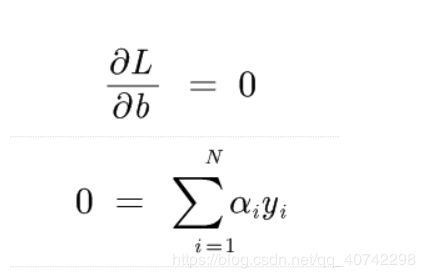
然后我们带入L中,得到:
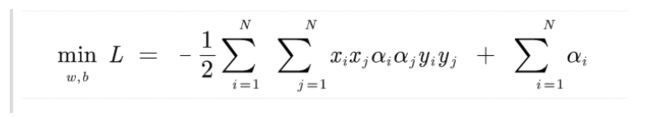
后面其实就比较简单了,然后还有一个问题值得讨论,就是什么是支持向量机。
支持向量
什么是支持向量呢?这关系到为什么这个算法叫这个名字。
我们发现在求解推导中我们已经得到了w的取值:
w* = 求和 α*yixi
这里根据KKT的互补条件,我们可以得到:
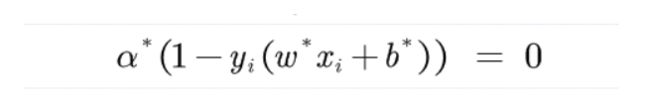
结合两个式子,确实有一些奇妙的地方:

首先w中的元素是不能全为零的,那么为了让w有意义,a就不能全为零。所以α中一定存在元素大于零的情况,根据KKT条件,当α大于零,后面括号内就一定是0.这表示样本点距离超平面的距离是1,1是我们把y上三角(表示到超平面距离)用1替换了,我们把这个立超平面最近的点叫做支持向量。
另外,我们计算w时只有那些支持向量才有意义,其他样本多几个少几个不会有什么影响的。
这里我们也发现了为什么SVM的速度较慢,因为他需要遍历所有样本来找到支持向量,然后计算w,b。
SVM(二)
SVM(二) latex手打公式 良心推导 原理分析 个人理解
怕写的太长了大家看不下去,关于SVM剩下的软间隔和核函数的部分见上面的超链接。
大家共勉~~