大数据学习系列(七)Hadoop伪分布式项目及环境搭建
一、环境准备
1.准备一台虚拟机
虚拟机安装请移步另一篇博客:https://blog.csdn.net/qq_40825301/article/details/105214440
2.配置ip : 我配置的ip为:192.168.40.33,保证能访问外网
3.配置hostname : eleven-2
4.配置hosts : 192.168.40.33 eleven-2
5.关闭防火墙,避免后期发生问题找不到原因
二、环境搭建,可参考 hadoop官网,都有讲解
官方:https://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation
2.1.安装并配置jdk
2.1.1.上传jdk
注意:hadoop3.0版本之前可用jdk1.7,hadoop3.0之后的版本需要用jdk1.8
我本地下载了jdk,通过rz命令或者xftp上传至linux.
没有rz命令的可以安装一下,yum install lrzsz
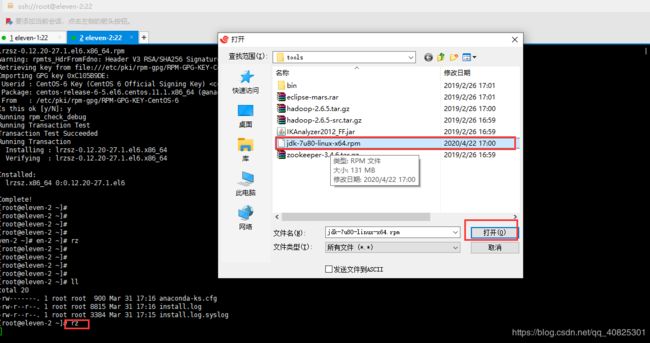
2.1.2 安装jdk,默认的安装路径为 /usr/java/jdk...
#####上传后,安装jdk####
执行命令 rpm -i jdk的安装文件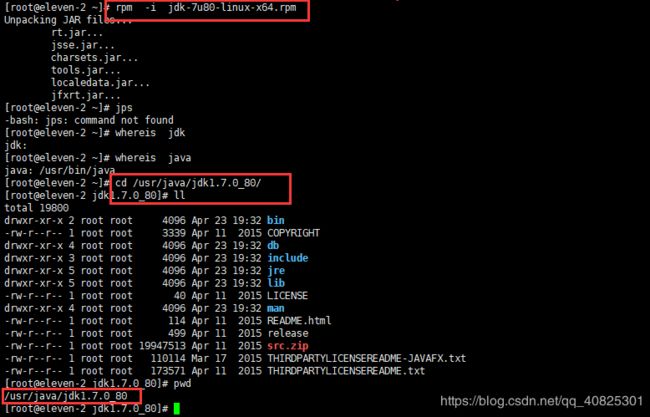
2.1.3 配置环境变量
1.复制jdk的安装路径
2.配置环境变量
1.打开/etc/profile文件,在末尾追加 命令: vi + /etc/profile
2.配置
export JAVA_HOME=/usr/java/jdk1.7.0_80
PATH=$PATH:$JAVA_HOME/bin
3.保存退出
4.重新刷新配置文件
. /etc/profile 或者 source /etc/profile
2.1.4 验证 ,输入jps查看进程,成功。
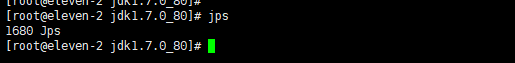
2.2配置ssh免密登陆
hadoop分布式集群会有多节点,多角色。namenode datanode secondary namenode,节点间会进行访问,因为每次ssh连接的时候都需要输入密码,ssh localhost也同样需要密码。为省去输入密码的操作,所以需要配置ssh免密访问。
因为此环境为伪分布式项目,所有节点都在一台服务器上,所以只需配置ssh localhost 免密即可
执行 ssh localhost,可以看到需要密码才能访问

2.2.1.生成密钥
命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
ssh-keygen:密钥生成器
-t :用哪种方法,此处用dsa方法
-p :密码,因为是免密登陆,密码为空
-f :生成文件的路径 ,显示如下便成功了

2.2.2:将公钥放入到验证文件中
命令
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys2.2.3:测试
ssh localhost,或者ssh eleven-2(注意此处是自己配置的hostname),发现就不再需要输入密码了

2.3 安装Hadoop
2.3.1:上传hadoop至服务器,我用的版本是:hadoop-2.6.5.tar.gz
2.3.2:解压至 /opt/sxt ,可以自定义
tar -zxvf hadoop-2.6.5.tar.gz -C /opt/sxt
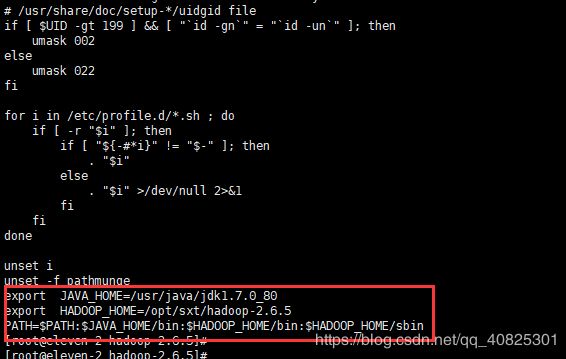
2.3.3:配置环境变量,hadoop相关命令放置在/bin目录,系统级别的脚本放置在/sbin,
在/etc/profile追加
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.4:配置Hadoop
hadoop的配置文件都在安装路径下/etc/hadoop目录下,hadoop启动会自动来读取相关配置文件
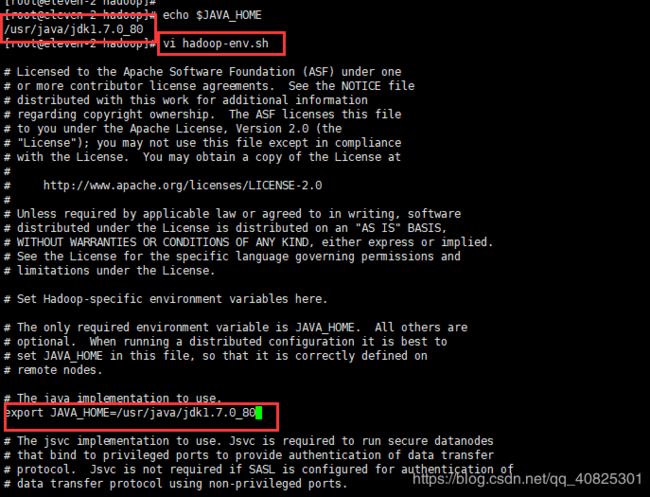
2.4.1:配置hadoop中的JAVA_HOME路径(二次环境变量配置)
因为hadoop启动的时候会去依赖jdk的相关信息,这里需要给他指定路径去读取jdk或者jvm。
修改hadoop-env.sh,(分布式文件存储系统用的配置脚本)
修改mapre.env,sh 计算框架用的配置脚本
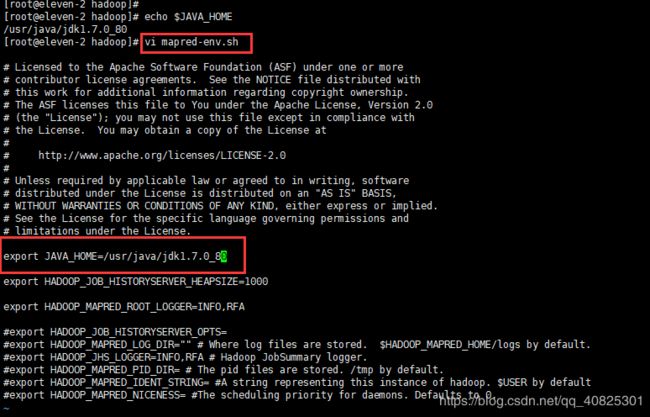 、、
、、
修改yarn-env.sh 资源管理用
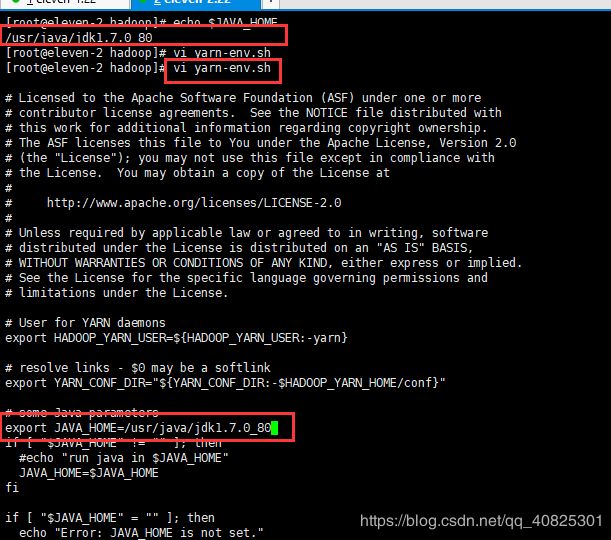
2.4.2:配置hadoop配置文件
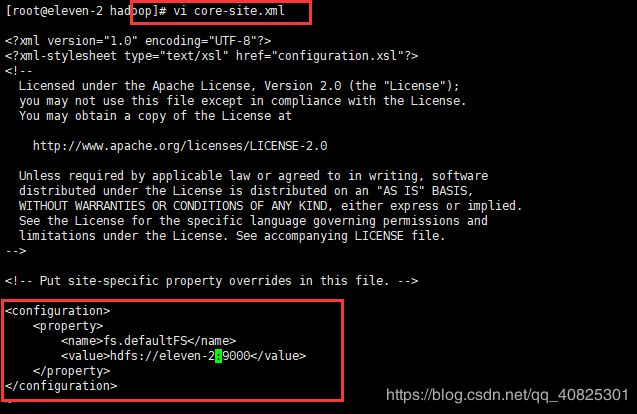
core-site.xml(核心配置文件)此文件为主角色节点信息(namenode)
fs.defaultFS
hdfs://eleven-2:9000
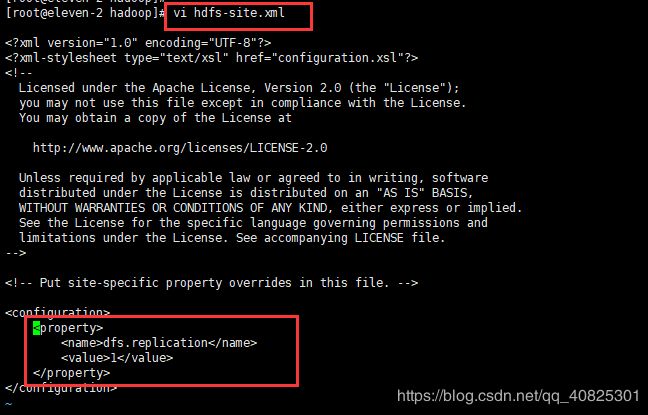
hdfs-site.xml ,配置副本数量,因为伪分布式,只有一台服务器,所以副本数量为1
dfs.replication
1
配置datanode,在slaves文件中配置从节点datanode信息.
此环境为伪分布式,所以从节点datanode都在eleven-2这一台服务器上,将slave文件的默认值localhost替换成eleven-2

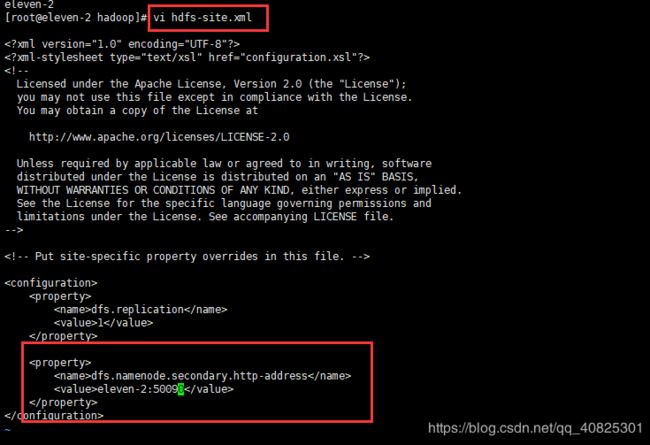
配置secondary namenode,在hdfs-site.xml文件中(参考官方文档)
在configuration块中添加如下配置
dfs.namenode.secondary.http-address
eleven-2:50090 ##ip:port,port为官方给的
在core-site.xml中默认有一个name为hadoop.tmp.dir的节点,它的value为一个目录,默认是一个临时目录
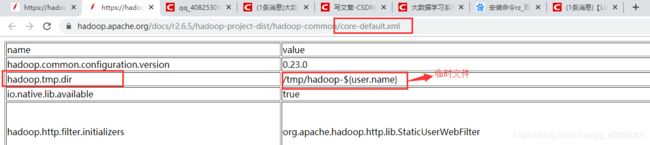
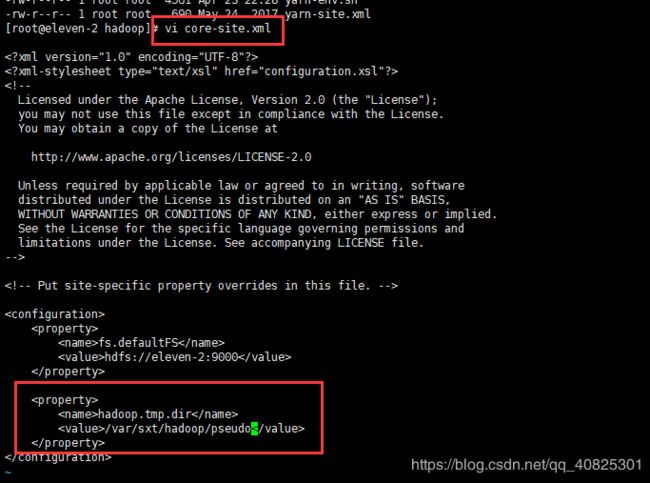
从下图可看出这个路径用于存放namenode和datanode的元数据和数据信息的,存在丢失的风险。所以需要重新定义一下。


重写core-site.xml文件中name为hadoop.tmp.dir的节点。
hadoop.tmp.dir
/var/sxt/hadoop/pseudo ##将数据保存至此路径下,可自定义
三、格式化及启动hadoop
3.1 格式化
在格式化的过程中主要生成fsimage镜像快照文件,生成clusterID(集群id),
命令: hdfs namenode -format下图效果即成功
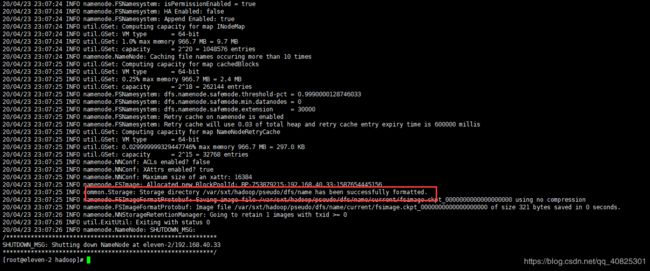
格式化成功会在配置的/var/sxt/hadoop/pseudo 路径下生成dfs/name文件夹,/name文件夹用于存放角色namenode的元数据和数据信息,
之后启动hadoop会在/dfs目录下生成/data ,namesecondary文件夹,存放datanode 和secondary namenode的元数据和数据。
进入到/var/sxt/hadoop/pseudo/dfs/name/current 目录下查看生成的快照文件及其他文件
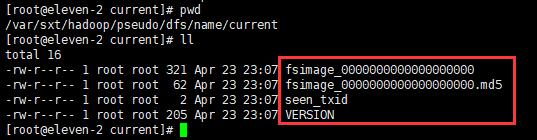
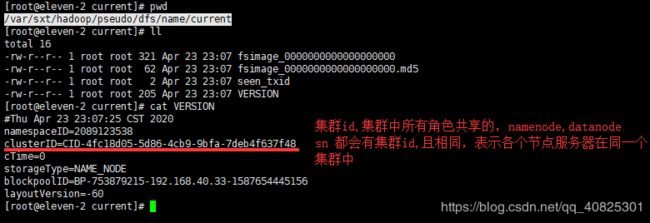
这个clusterID(集群id)每次格式化,启动都会发生变化,所以以后发现集群启动不起来报错,看是不是集群ID不一致的问题造成的。
3.2 启动hadoop
会依次启动三个角色,namenode 、datanode 、secondary namenode。启动成功后每个角色都是一个java进程。
命令:start-dfs.sh
启动完成后会在配置的/var/sxt/hadoop/pseudo 目录下生成角色datanode 和secondary namenode的文件夹data、namesecondary。
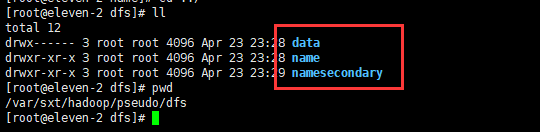
可以查看三个角色的clusterId(集群id)都相同,说明是在一个集群中。
3.3 测试
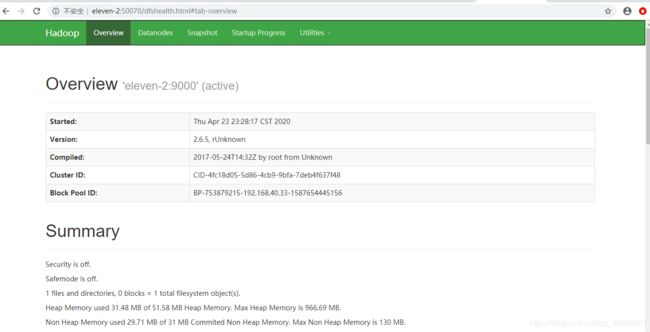
hadoop提供可视化管理工具 ,可以用外部浏览器访问管理页面,
解释:所有的计算和文件管理操作都是在datanode节点上执行的,但是都是通过namenode节点去操作的datanode节点,也就是namenode管理着所有的datanode。所以此处访问的管理界面也就是namenode。
浏览器请求 当前虚拟机ip:端口号
先查看当前服务器对外提供的浏览器端口,执行命令 ss -nal
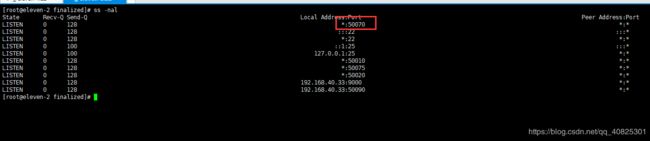
浏览器访问 eleven-2:50070 ,,注意:前提是windows下配置了hosts.否则用ip访问
3.4 关闭hadoop
stop-dfs.sh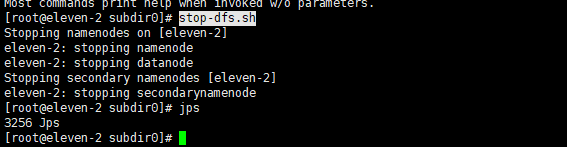
四、上传文件操作
hadoop中,数据的客户端操作指令是由hdfs dfs来管理的,基本和linux相似。
上传文件是通过客户端和namanode节点进行交互,然后将数据切分成black(块),放置到datanode上。
在上传之前先创建路径,datanode的black块存放路径。/user/root为默认的上传 路径

上传命令:后面的 路径可以省略,默认就是/user/root
hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
