机器学习之Fisher判别分析
机器学习之Fisher判别分析
- 一、算法描述
- 1、W的确定
- 2、阈值的确定
- 3、Fisher线性判别的决策规则
- 4、群内离散度”(样本类内离散矩阵)、“群间离散度”(总类内离散矩阵)
- 二、Python代码实现
一、算法描述
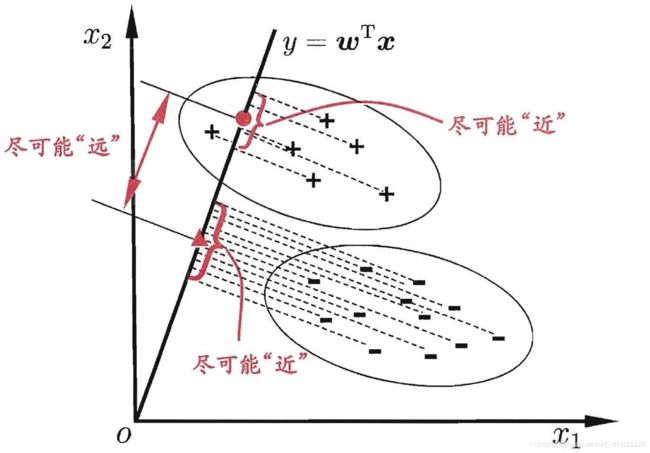
Fisher线性判别分析的基本思想:选择一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,同时变换后的一维数据满足每一类内部的样本尽可能聚集在一起,不同类的样本相隔尽可能地远。
Fisher线性判别分析,就是通过给定的训练数据,确定投影方向W和阈值w0, 即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
Fisher判别分析是要实现有最大的类间距离,以及最小的类内距离
线性判别函数的一般形式可表示成:
![]()
其中

Fisher选择投影方向W的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求。 如下为具体步骤:
1、W的确定
各类样本均值向量mi

样本类内离散度矩阵Si和总类内离散度矩阵Sw

![]()
样本类间离散度矩阵Sb
![]()
在投影后的一维空间中,各类样本均值
样本类内离散度和总类内离散度![]()
样本类间离散度![]()
Fisher准则函数为
2、阈值的确定
W0是个常数,称为阈值权,对于两类问题的线性分类器可以采用下属决策规则:
令

则:
如果g(x)>0,则决策x∈W1;如果g(x)<0,则决策x∈W2;如果g(x)=0,则可将x任意分到某一类,或拒绝。
3、Fisher线性判别的决策规则
Fisher准则函数满足两个性质:
1.投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
2.投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据这个性质确定准则函数,根据使准则函数取得最大值,可求出
这就是Fisher判别准则下的最优投影方向。
最后得到决策规则
若

则

对于某一个未知类别的样本向量x,如果 ![]() x>y0,则x∈w1;否则x∈w2。
x>y0,则x∈w1;否则x∈w2。
4、群内离散度”(样本类内离散矩阵)、“群间离散度”(总类内离散矩阵)
样本在d维特征空间的描述量,根据上面的推导可以发现:
群内离散度”(样本类内离散矩阵)Si的计算公式为:

群间离散度”(总体类离散度矩阵)Sw的计算公式为:
![]()
二、Python代码实现
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
path=r'D:\Workspaces\Jupyter-notebook\datasets\mldata\Iris.data'
df = pd.read_csv(path, header=0)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):
a=Iris1[i,:]-m1
a=np.array([a])
b=a.T
s1=s1+np.dot(b,a)
for i in range(0,30,1):
c=Iris2[i,:]-m2
c=np.array([c])
d=c.T
s2=s2+np.dot(d,c)
#s2=s2+np.dot((Iris2[i,:]-m2).T,(Iris2[i,:]-m2))
for i in range(0,30,1):
a=Iris3[i,:]-m3
a=np.array([a])
b=a.T
s3=s3+np.dot(b,a)
sw12=s1+s2
sw13=s1+s3
sw23=s2+s3
#投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
#判别函数以及T
#需要先将m1-m2转化成矩阵才能进行求其转置矩阵
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c=m2-m3
c=np.array([c])
c=c.T
w12=(np.dot(np.linalg.inv(sw12),a)).T
w13=(np.dot(np.linalg.inv(sw13),b)).T
w23=(np.dot(np.linalg.inv(sw23),c)).T
#print(m1+m2) #1x4维度 invsw12 4x4维度 m1-m2 4x1维度
T12=-0.5*(np.dot(np.dot((m1+m2),np.linalg.inv(sw12)),a))
T13=-0.5*(np.dot(np.dot((m1+m3),np.linalg.inv(sw13)),b))
T23=-0.5*(np.dot(np.dot((m2+m3),np.linalg.inv(sw23)),c))
kind1=0
kind2=0
kind3=0
newiris1=[]
newiris2=[]
newiris3=[]
for i in range(29,49):
x=Iris1[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
kind1=kind1+1
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
#print(newiris1)
for i in range(29,49):
x=Iris2[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
kind2=kind2+1
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(29,49):
x=Iris3[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
kind3=kind3+1
#花瓣与花萼的长度散点图
plt.scatter(df.values[:50, 3], df.values[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(df.values[50:100, 3], df.values[50: 100, 1], color='blue', marker='x', label='versicolor')
plt.scatter(df.values[100:150, 3], df.values[100: 150, 1], color='green', label='virginica')
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.title("花瓣与花萼长度的散点图")
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
plt.legend(loc='upper left')
plt.show()
#花瓣与花萼的宽度度散点图
plt.scatter(df.values[:50, 4], df.values[:50, 2], color='red', marker='o', label='setosa')
plt.scatter(df.values[50:100, 4], df.values[50: 100, 2], color='blue', marker='x', label='versicolor')
plt.scatter(df.values[100:150, 4], df.values[100: 150, 2], color='green', label='virginica')
plt.xlabel('petal width')
plt.ylabel('sepal width')
plt.title("花瓣与花萼宽度的散点图")
plt.legend(loc='upper left')
plt.show()
correct=(kind1+kind2+kind3)/60
print("样本类内离散度矩阵S1:",s1,'\n')
print("样本类内离散度矩阵S2:",s2,'\n')
print("样本类内离散度矩阵S3:",s3,'\n')
print('-----------------------------------------------------------------------------------------------')
print("总体类内离散度矩阵Sw12:",sw12,'\n')
print("总体类内离散度矩阵Sw13:",sw13,'\n')
print("总体类内离散度矩阵Sw23:",sw23,'\n')
print('-----------------------------------------------------------------------------------------------')
print('判断出来的综合正确率:',correct*100,'%')
参考文献
参考地址1
参考地址2