Linux性能监控(CPU监控)
Linux性能监控(CPU监控)
主要分为四类:
cup监控
内存监控命令
IO性能
网络性能
cup监控
关于CPU,有3个重要的概念:上下文切换(context switchs),运行队列(Run queue)和使用率(utilization)。
上下文切换:
目前流行的CPU在同一时间内只能运行一个线程,超线程的处理器可以在同一时间运行多个线程(包括多核CPU),Linux内核会把多核的处理器当作多个单独的CPU来识别。
一个标准的Linux内核何以支持运行50~50000个进程运行,对于普通的CPU,内核会调度和执行这些进程。每个进程都会分到CPU的时间片来运行,当一个进程用完时间片或者被更高优先级的进程抢占后,它会备份到CPU的运行队列中,同时其他进程在CPU上运行。这个进程切换的过程被称作上下文切换。过多的上下文切换
会造成系统很大的开销。
运行队列:
每个CPU都会维持一个运行队列,理想情况下,调度器会不断让队列中的进程运行。进程不是处在sleep状态就是run able状态。如果CPU过载,就会出现调度器跟不上系统的要求,导致可运行的进程会填满队列。队列愈大,程序执行时间就愈长。“load”用来表示运行队列,用top 命令我们可以看到CPU一分钟,5分钟和15分钟内的运行队列的大小。这个值越大表明系统负荷越大。
CPU使用率:
CPU使用率可分为一下几个部分
User Time—执行用户进程的时间百分比;
System Time—执行内核进程和中断的时间百分比;
Wait IO—因为IO等待而使CPU处于idle状态的时间百分比;
Idle—CPU处于Idle状态的时间百分比。
以下是一些对于CPU很普遍的性能要求:
- 对于每一个CPU来说运行队列不要超过3,例如,如果是双核CPU就不要超过6;
- 如果CPU在满负荷运行,应该符合下列分布,
a) User Time:65%~70%
b) System Time:30%~35%
c) Idle:0%~5% - 对于上下文切换要结合CPU使用率来看,如果CPU使用满足上述分布,大量的上下文切换也是可以接受的。
top命令
TOP是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定。
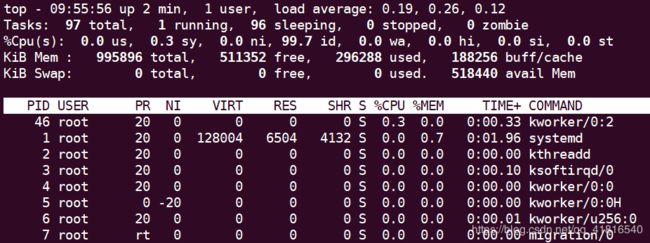
前五行是统计信息:
1、第一行是任务队列信息,同uptime命令的执行结果一样
![]()
其内容如下:
09:57:07 当前时间
up 3 min 系统运行时间
1 user 当前登录用户数
load average: 0.06, 0.20, 0.11 系统负载,即任务队列的平均长度。分别为1分钟,5分钟,15分钟前到现在的平均值。
2、第二行为进程信息统计数据
Tasks — 任务(进程)
otal 进程总数
running 正在运行的进程数
sleeping 睡眠的进程数
stopped 停止的进程数
zombie 僵尸进程数
3、第三行CPU信息统计数据:
Cpu(s):
0.0% us: 用户空间占用CPU百分比
0.3% sy: 内核(系统)空间占用CPU百分比
0.0% ni: 用户进程空间内改变过优先级的进程占用CPU百分比
99.7% id: 空闲CPU百分比
0.0% wa: 等待输入输出的CPU时间百分比
0.0%hi: 硬件CPU中断占用百分比
0.0%si: 软中断占用百分比
0.0%st: 虚拟机(虚拟化技术)占用百分比
4、第四、五行为内存信息系统数据:
Men:
995896k total: 物理内存总量
296288k used: 使用的物理内存总量
511352k free: 空闲内存总量
188256k buffers: 用作内核缓存的内存量
Swap:
0k total: 交换区总量
0k used: 使用的交换区总量
0k free: 空闲交换区总量
518440k cached:缓冲的交换区总量(内存中的数据被移动至交换区而后又被送至内存空间,但是使用过的交换区尚未被覆盖,其空间大小即为这些数据已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再次对交换区写入)
内存空间还剩多少空闲呢?
totalfree = total 995896 - free 511352 + buffer 188256 + cached 518440 (即:物理空闲内存 = 总物理内存 - 空闲内存总量 + 内核缓存的内存量 + 缓冲的交换区总量)
vmstat命令
安装:
CentOS, RedHat or Fedora,运行下列命令来安装mpstat
yum install sysstat
Debian, Ubuntu or 它的衍生版, 运行下列命令来安装mpstat
apt-get install sysstat
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、IO读写、CPU活动等进行监视。它是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。

输出的参数信息含义:
procs #进程
r(run):表示运行或等待CPU时间片的进程数,如果该值长期大于服务器CPU的个数,则说明CPU资源不足。一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险;
b(block):表示等待资源的进程数,这个资源指的是I/O、内存等。比如,当磁盘读写非常频繁时,写数据就会变得很慢,此时CPU运算很快就结束了,但进程需要把计算的结果写入磁盘,这样进程的任务才算完成,此时这个进程只能慢慢地等待磁盘了,这个进程就是这个b状态。该数值如果长时间大于1,则需要去查找问题;
memory #内存,单位:KB
swap:虚拟内存(swap空间)已使用的大小;
free:空闲的物理内存的大小;
buff:存放目录里面有什么内容,文件的属性以及权限等;
cache:用来记忆我们打开过的文件和程序,做文件缓冲(当程序使用内存时,buff/cache很快就会被使用);
swap #swap空间,单位:KB,内存够用时,si和so值都为0,如果这两个值长期大于0,表示内存不够用了,系统性能会受到影响
si:表示从swap空间写入内存的数据量;
so:表示从内存写入swap空间的数据库;
io #单位:块/秒
bi:每秒读取的块数(读磁盘),现在的Linux版本块的大小为1024bytes;
bo:每秒写入的块数(写磁盘);
system #系统,这2个值越大,会看到由内核消耗的CPU时间会越大
in:每秒CPU的中断次数,包括时间中断;
cs:每秒上下文切换数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进行上下文切换,这个值越小越好;
cpu #以百分比显示
us(user time):用户进程执行时间;
sy(system time):系统进程执行时间;
id:空闲时间(包括IO等待时间);
wa:等待IO时间,wa的值高时,说明IO等待比较严重,这可能由于磁盘大量做随机访问造成的,也有可能是磁盘出现瓶颈;
st:表示被偷走的CPU所占百分比(一般都为0,不用关注);
us + sy + id + wa =100% #这个是只是近似值
语法
vmstat (选项) (参数)
示例
一般vmstat工具的使用是通过两个数字参数来完成的,
第一个参数是采样的时间间隔,单位是秒,
第二个参数是采样的次数.
例如每隔1秒采样,共采样3次:

mpstat命令
mpstat是 Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPU系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
安装:
CentOS, RedHat or Fedora,运行下列命令来安装mpstat
yum install sysstat
Debian, Ubuntu or 它的衍生版, 运行下列命令来安装mpstat
apt-get install sysstat
语法:
mpstat [-P {cpu|ALL}] [internal [count]]
参数说明:
-P {cpu l ALL}:表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal:相邻的两次采样的间隔时间
count:采样的次数,count只能和delay一起使用
示例:
mpstat -P ALL 1 3
表示每1秒产生一个报告,总共产生3个。

输出的参数信息含义:
| 参数 | 释义 | 从/proc/stat获得数据 |
|---|---|---|
| CPU | 处理器号码。关键字ALL表示统计数据是以所有处理器之间的平均值计算的 | |
| %usr | 在internal时间段里,用户态的CPU时间(%),不包含 nice值为负进程 | usr/total*100 |
| %nice | 在internal时间段里,nice值为负进程的CPU时间(%) | nice/total*100 |
| %sys | 在internal时间段里,核心时间(%) | system/total*100 |
| %iowait | 在internal时间段里,硬盘IO等待时间(%) | iowait/total*100 |
| %irq | 在internal时间段里,硬中断时间(%) | irq/total*100 |
| %soft | 在internal时间段里,软中断时间(%) | softirq/total*100 |
| %steal | 显示虚拟机管理器在服务另一个虚拟处理器时虚拟CPU处在非自愿等待下花费时间的百分比 | steal/total*100 |
| %guest | 显示运行虚拟处理器时CPU花费时间的百分比 | guest/total*100 |
| %gnice | gnice/total*100 | |
| %idle | 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) | idle/total*100 |
pidstat命令
pidstat是sysstat工具的一个命令,用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况。pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
语法:
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
示例:
pidstat
默认显示了所有进程的cpu使用率。

输出的参数信息含义:
PID:进程ID
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令
pidstat -u:cpu使用情况统计,和直接运行pidstat
pidstat -r:内存使用情况统计

输出的参数信息含义:
PID:进程标识符
Minflt/s:任务每秒发生的次要错误,不需要从磁盘中加载页
Majflt/s:任务每秒发生的主要错误,需要从磁盘中加载页
VSZ:虚拟地址大小,虚拟内存的使用KB
RSS:常驻集合大小,非交换区五里内存使用KB
Command:task命令名
pidstat -d:显示各个进程的IO使用情况

输出的参数信息含义:
PID:进程id
kB_rd/s:每秒从磁盘读取的KB
kB_wr/s:每秒写入磁盘KB
kB_ccwr/s:任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
COMMAND:task的命令名
dstat命令
dstat命令可以收集cpu、disk、net、system、内存、进程等系统信息;功能比vmstat强大,一条命令可以集成了uptime、vmstat、top等相关信息
安装:
CentOS, RedHat or Fedora,运行下列命令来安装
yum install -y dstat
Debian, Ubuntu or 它的衍生版, 运行下列命令来安装
apt-get install dstat
示例:
dstat

输出的参数信息含义:
显示CPU(cpu)、硬盘(disk)、网卡(network)、包(package)、系统(system)
usr:用户占用 sys:系统占用 idl:空闲 wai:等待的进程 hiq:硬中断 siq:软中断
read:磁盘读操作数 writ:磁盘写操作数
recv:接受请求数 send:发送请求数
in:系统分页 out:系统分页
int:系统中断次数 csw:上下文切换次数
dstat -c: 显示系统整体的cpu情况
dstat -d: 查看系统的磁盘的读写数据大小
dstat -n: 查看系统的网络状态
dstat -l : 查看系统的负载情况
dstat -m: 查看系统的内存信息
dstat -p: 查看系统的进程信息
dstat -r : 查看系统的I/O请求情况
dstat --socket: 查看系统的tcp,udp端口情况
nmon命令
Nmon (Nigel’s Monitor)是由IBM 提供、免费监控 AIX 系统与 Linux 系统资源的工具。该工具可将服务器系统资源耗用情况收集起来并输出一个特定的文件,并可利用 excel 分析工具(nmon analyser)进行数据的统计分析。
安装
CentOS, RedHat or Fedora,运行下列命令来安装
yum install -y nmon
Debian, Ubuntu or 它的衍生版, 运行下列命令来安装
apt-get install nmon
常用快捷键:
参数 作用
q 停止并退出 Nmon
h 查看帮助
c 查看 CPU 统计数据
m 查看内存统计数据
k 查看内核统计数据
n 查看网络统计数据
N 查看 NFS 统计数据
j 查看文件系统统计数据
t 查看高耗进程
V 查看虚拟内存统计数据
v 详细模式
查看 CPU 处理器
如果你想收集关于 CPU 性能相关的统计数据,你应该按下键盘上的c键,之后你将会看到下面的输出:

查看高耗进程统计数据
如果想收集系统正在运行的高耗进程的统计数据,按键盘上的t键,之后你将会看到下面的输出:

查看网络统计数据
如果想收集 Linux 系统的网络统计数据,按下n键,你将会看到下面输出:
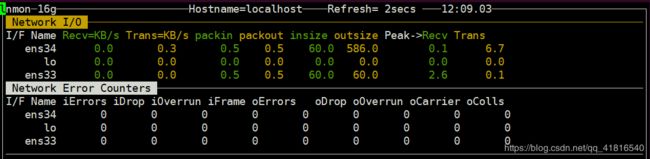
硬盘 I/O 图表
使用d 键获取硬盘相关的信息,你会看到下面输出:

查看内核信息
Nmon 一个非常重要的快捷键是k键,用来显示系统内核相关的概要信息。按下k键之后,会看到下面输出:

获取系统信息
对每个系统管理员来说一个非常有用的快捷键是r键,可以用来显示计算机的系统结构、操作系统版本号和 CPU 等不同资源的信息。按下r键之后会看到下面输出:
