JVM 第二阶段--Java字节码机制(2020-02)
初识字节码
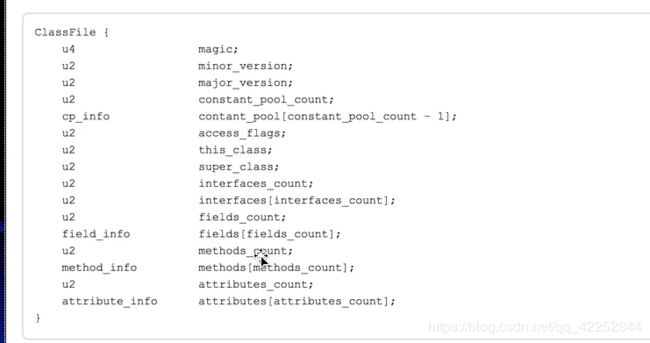
1.使用javap -verbose命令分析一个字节码文件时,将会分析该字节码文件的魔数、版本号、常量池、类信息、类的构造方法、类的方法信息、类变量和成员变量等信息
2.魔数:所有的.class字节码文件的前4个字节都是魔数,魔数值为固定值:OxCAFEBABE
3.魔数之后的四个字节为版本信息,前两个字节表示minor version(次版本号),后两个字节表示major version(主办本号).这里版本号为00 00 00 34,换算成十进制,表示此版本号为0,主版本号为52.所以,该文件的版本号为1.8.0.可以通过java -version命令来验证这一点.
4.常量池(constant pool):紧接着主版本号之后的就是常量池入口.一个java类定义的很多信息都是由常量池来维护和描述的,可以将常量池看作是Class文件的资源仓库,比如说Java类中定义的方法和变量信息,都是存储在常量池中.常量池中主要存储两类常量:字面量和符号引用.字面量:文本字符串,Java中声明为final的常量值等.符号引用:比如类和接口的全局限定名,字段的名称和描述符,方法名称和描述等.
5.常量池的总体结构:Java类所对应的常量池主要由常量池数量和常量池数组这两部分组成.常量池数量紧跟在主办本号后面,占两个字节,常量池数组则紧跟在常量池数量后面.常量池数组与一般数组不同的是:常量池数组中不同的元素的类型、结构都是不同的,长度当然也就不同;但是每一种元素的第一个数据都是一个u1类型,该字节为标志位,占据一个字节.JVM解析常量池时,会根据这个u1类型来获取元素的具体类型.值得注意的是:常量池数组中元素的个数=常量池数-1(其中0暂时不使用)目的是满足某些常量池索引值在特定情况下需要表达[不引用任何一个常量池]的含义;根本原因在于,索引位0也是一个常量(JVM保留常量),只不过它不位于常量表中,这个常量就对应null值;所以,常量池的索引从1而非0开始.

6.在JVM规范中,每个变量/字段都有描述信息,描述信息主要的作用是描述字段的数据类型、方法的参数列表(包括数量、类型和顺序)与返回值.根据描述符规则,基本数据类型和代表无返回值的void类型都用一个大写字符来表示,对象类型则使用字符L加对象的全限定类名来表示.为了压缩字节码文件的体积,对于基本数据类型,JVM都只使用一个大写字母来表示,如下所示:B-byte;C-char;D-double;I-int;F-float;S-short;Z-boolean;V-void;J-long;L-对象类型,如Ljava/lang/String;
7.对于数组类型来说,每一个维度使用一个前置的[来表示,比如int[]被记录位[I;String[][]被记录位[[Ljava/lang/String;
8.用描述符来描述方法时,按照先参数列表,后返回值的顺序来描述.参数列表按照参数的严格顺序放在一组()值内,如方法:String getNameById(int id,String name)的描述符:(I,Ljava/lang/String) Ljava/lang/String;







Synchronized生成的字节码详解

public class MyTest2 {
String str = "Welcome";
private int x = 5;
public static Integer in = 10;
private Object object = new Object();
public static void main(String[] args) {
MyTest2 myTest2 = new MyTest2();
myTest2.setX(8);
in = 20;
}
private synchronized void setX(int x) {
this.x = x;
}
private void test(String str){
synchronized (str){
System.out.println("hello world");
}
}
}
0 aload_1
1 dup
2 astore_2
3 monitorenter
4 getstatic #12 <java/lang/System.out>
7 ldc #13 <hello world>
9 invokevirtual #14 <java/io/PrintStream.println>
12 aload_2
13 monitorexit
14 goto 22 (+8)
17 astore_3
18 aload_2
19 monitorexit
20 aload_3
21 athrow
22 return
this关键字异常表和分析
public class MyTest3 {
public void test(){
try {
FileInputStream fileInputStream = new FileInputStream("test.txt");
ServerSocket serverSocket = new ServerSocket(9999);
serverSocket.accept();
}catch (FileNotFoundException ex){
}catch (IOException ex){
}catch (Exception e){
}
}
}
Last modified 2020-2-19; size 848 bytes
MD5 checksum f01377fad4ed1931d17a4c1a593af052
Compiled from "MyTest3.java"
public class com.cy.jvm.byteCode.MyTest3
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #12.#31 // java/lang/Object."":()V
#2 = Class #32 // java/io/FileInputStream
#3 = String #33 // test.txt
#4 = Methodref #2.#34 // java/io/FileInputStream."":(Ljava/lang/String;)V
#5 = Class #35 // java/net/ServerSocket
#6 = Methodref #5.#36 // java/net/ServerSocket."":(I)V
#7 = Methodref #5.#37 // java/net/ServerSocket.accept:()Ljava/net/Socket;
#8 = Class #38 // java/io/FileNotFoundException
#9 = Class #39 // java/io/IOException
#10 = Class #40 // java/lang/Exception
#11 = Class #41 // com/cy/jvm/byteCode/MyTest3
#12 = Class #42 // java/lang/Object
#13 = Utf8 <init>
#14 = Utf8 ()V
#15 = Utf8 Code
#16 = Utf8 LineNumberTable
#17 = Utf8 LocalVariableTable
#18 = Utf8 this
#19 = Utf8 Lcom/cy/jvm/byteCode/MyTest3;
#20 = Utf8 test
#21 = Utf8 fileInputStream
#22 = Utf8 Ljava/io/FileInputStream;
#23 = Utf8 serverSocket
#24 = Utf8 Ljava/net/ServerSocket;
#25 = Utf8 StackMapTable
#26 = Class #38 // java/io/FileNotFoundException
#27 = Class #39 // java/io/IOException
#28 = Class #40 // java/lang/Exception
#29 = Utf8 SourceFile
#30 = Utf8 MyTest3.java
#31 = NameAndType #13:#14 // "":()V
#32 = Utf8 java/io/FileInputStream
#33 = Utf8 test.txt
#34 = NameAndType #13:#43 // "":(Ljava/lang/String;)V
#35 = Utf8 java/net/ServerSocket
#36 = NameAndType #13:#44 // "":(I)V
#37 = NameAndType #45:#46 // accept:()Ljava/net/Socket;
#38 = Utf8 java/io/FileNotFoundException
#39 = Utf8 java/io/IOException
#40 = Utf8 java/lang/Exception
#41 = Utf8 com/cy/jvm/byteCode/MyTest3
#42 = Utf8 java/lang/Object
#43 = Utf8 (Ljava/lang/String;)V
#44 = Utf8 (I)V
#45 = Utf8 accept
#46 = Utf8 ()Ljava/net/Socket;
{
public com.cy.jvm.byteCode.MyTest3();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
LineNumberTable:
line 8: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/cy/jvm/byteCode/MyTest3;
public void test();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=3, locals=3, args_size=1
0: new #2 // class java/io/FileInputStream
3: dup
4: ldc #3 // String test.txt
6: invokespecial #4 // Method java/io/FileInputStream."":(Ljava/lang/String;)V
9: astore_1
10: new #5 // class java/net/ServerSocket
13: dup
14: sipush 9999
17: invokespecial #6 // Method java/net/ServerSocket."":(I)V
20: astore_2
21: aload_2
22: invokevirtual #7 // Method java/net/ServerSocket.accept:()Ljava/net/Socket;
25: pop
26: goto 38
29: astore_1
30: goto 38
33: astore_1
34: goto 38
37: astore_1
38: return
Exception table:
from to target type
0 26 29 Class java/io/FileNotFoundException
0 26 33 Class java/io/IOException
0 26 37 Class java/lang/Exception
LineNumberTable:
line 12: 0
line 13: 10
line 14: 21
line 21: 26
line 15: 29
line 21: 30
line 17: 33
line 21: 34
line 19: 37
line 22: 38
LocalVariableTable:
Start Length Slot Name Signature
10 16 1 fileInputStream Ljava/io/FileInputStream;
21 5 2 serverSocket Ljava/net/ServerSocket;
0 39 0 this Lcom/cy/jvm/byteCode/MyTest3;
StackMapTable: number_of_entries = 4
frame_type = 93 /* same_locals_1_stack_item */
stack = [ class java/io/FileNotFoundException ]
frame_type = 67 /* same_locals_1_stack_item */
stack = [ class java/io/IOException ]
frame_type = 67 /* same_locals_1_stack_item */
stack = [ class java/lang/Exception ]
frame_type = 0 /* same */
}
SourceFile: "MyTest3.java"
args_size=1:对于Java类中的每一个实例方法(非static)方法,其在编译所生成的字节码当中,方法参数的数量总是会比源代码中方法参数的数量多一个(this),他位于方法的第一个参数位置处;这样,我们就可以在Java的实例方法中使用this来去访问当前对象的属性及其其他方法.
这个操作是在编译期间完成的,即由javac编译器在编译的时候讲this的访问转化为对一个普通实例方法参数的访问,接下来在运行期间,有JVM在调用实例方法时,自动向实例方法传入该this参数.所以,在实例方法的局部变量表中,至少有一个指向当前对象的局部变量.
locals=4:方法执行期间创建的局部变量的数目,包含用来表示传入的参数的局部变量:this;in;serverSocket;ex;
stack:表示这个方法运行的任何时刻所能达到的操作数栈道最大深度
java字节码对于异常的处理方式:
1.统一采用异常表的方式来对异常进行处理
2.在jdk1.4.2之前的版本中,并不是使用异常表的方式来对异常进行处理的,而是采用特定的指令处理
3.当异常处理存在finally语句块时,现代化的JVM采取处理方式将finally语句块的字节码拼接到每一个catch块后面,换句话说,程序中存在多少个catch块,就会在每一个catch块后面重复多少个finally语句块的字节码.
栈桢和符号引用与直接引用的转换
/**
* 栈桢(stask frame)
*
* 栈桢是用于帮助虚拟机执行方法调用与方法执行的数据结构
*
* 栈桢本身是一种数据结构 封装了方法的局部变量表、动态链接信息、方法的返回地址以及操作数栈
* 等信息
*
* 符号引用,直接引用
*
* 有些符号引用是在类加载阶段或者是第一次使用是就会转换成直接引用,这种转换叫做静态解析;
* 另外一些符号则是在每次运行期转换为直接引用,这种转换叫做动态链接,这体现Java的多态性
*
* 1.invokeinterface:调用接口中的方法,实际上是在运行期来决定的,
* 决定到底调用实现该接口的哪个对象的特定方法
* 2.invokestatic:调用静态方法(解析阶段)
* 3.invokespecial:调用自己的私有方法,构造方法 以及父类的方法(解析阶段)
* 4.invokevirtual:调用虚方法,运行期动态查找的过程
* 5.invokedynamic:动态调用方法
*/
/**
* 静态解析的方法的四种情景:
* 1.静态方法
* 2.父类方法
* 3.构造方法
* 4.私有方法
* 他们都是(非虚方法)不能被重写 可以在类加载阶段可以将符号引用转换成直接引用的
*/
public class MyTest5 {
public void test(Grandpa g) {
System.out.println("Grandpa");
}
public void test(Father f) {
System.out.println("Father");
}
public void test(Son s) {
System.out.println("Son");
}
public static void main(String[] args) {
Grandpa grandpa1 = new Father();
Grandpa grandpa2 = new Son();
MyTest5 myTest5 = new MyTest5();
myTest5.test(grandpa1);
myTest5.test(grandpa2);
}
}
class Grandpa {
}
class Father extends Grandpa {
}
class Son extends Father {
}
Grandpa
Grandpa
方法的静态分派:
Grandpa grandpa1 = new Father();
以上代码,g1的静态类型是Grandpa,而g1的实际类型(真正指向的类型)是Father.
结论:变量的静态类型是不易发生变化的,而变量的实际类型则是可以发生变化的(多态的一种体现),
实际类型是运行期方可确定.
方法重载:
是一种静态行为,myTest5.test(grandpa1) 是根据其静态类型来进行方法调用.编译期可以确定
方法的动态分派和静态分派
案例一:
/**
* 方法的动态分派
* 方法动态分派涉及到一个重要概念:方法接受者
*
* invokevirtual字节码指令的多态查找流程
* 比较方法重载和方法重写 可以得出结论:方法重载是静态的,是编译期行为;
* 方法重写是动态的,是运行期行为;
* 方法的调用者不同(鲜明不同)
*/
public class MyTest6 {
public static void main(String[] args) {
Fruit apple = new Apple();
Fruit orange = new Orange();
apple.test();
orange.test();
apple = new Orange();
apple.test();
}
}
class Fruit {
public void test() {
System.out.println("Friut");
}
}
class Apple extends Fruit {
@Override
public void test() {
System.out.println("Apple");
}
}
class Orange extends Fruit {
@Override
public void test() {
System.out.println("Orange");
}
}
Apple
Orange
Orange
0 new #2 <com/cy/jvm/byteCode/Apple>
3 dup
4 invokespecial #3 <com/cy/jvm/byteCode/Apple.<init>>
7 astore_1
8 new #4 <com/cy/jvm/byteCode/Orange>
11 dup
12 invokespecial #5 <com/cy/jvm/byteCode/Orange.<init>>
15 astore_2
16 aload_1
17 invokevirtual #6 <com/cy/jvm/byteCode/Fruit.test>
20 aload_2
21 invokevirtual #6 <com/cy/jvm/byteCode/Fruit.test>
24 new #4 <com/cy/jvm/byteCode/Orange>
27 dup
28 invokespecial #5 <com/cy/jvm/byteCode/Orange.<init>>
31 astore_1
32 aload_1
33 invokevirtual #6 <com/cy/jvm/byteCode/Fruit.test>
36 return
案例二:
public class MyTest7 {
public static void main(String[] args) {
Animal animal = new Animal();
animal.test("");
Animal dog = new Dog();
dog.test(new Date());
}
}
class Animal {
public void test(String str) {
System.out.println("animal test str");
}
public void test(Date date) {
System.out.println("animal test date");
}
}
class Dog extends Animal{
@Override
public void test(String str) {
System.out.println("dog test str");
}
@Override
public void test(Date date) {
System.out.println("dog test date");
}
}
animal test str
dog test date
0 new #2 <com/cy/jvm/byteCode/Animal>
3 dup
4 invokespecial #3 <com/cy/jvm/byteCode/Animal.<init>>
7 astore_1
8 aload_1
9 ldc #4
11 invokevirtual #5 <com/cy/jvm/byteCode/Animal.test>
14 new #6 <com/cy/jvm/byteCode/Dog>
17 dup
18 invokespecial #7 <com/cy/jvm/byteCode/Dog.<init>>
21 astore_2
22 aload_2
23 new #8 <java/util/Date>
26 dup
27 invokespecial #9 <java/util/Date.<init>>
30 invokevirtual #10 <com/cy/jvm/byteCode/Animal.test>——————————Animal
33 return
如果子类中有方法A 父类没有A 那么 Father son = new Son(); son.A(); 就会报错 因为
invokevirtual #10

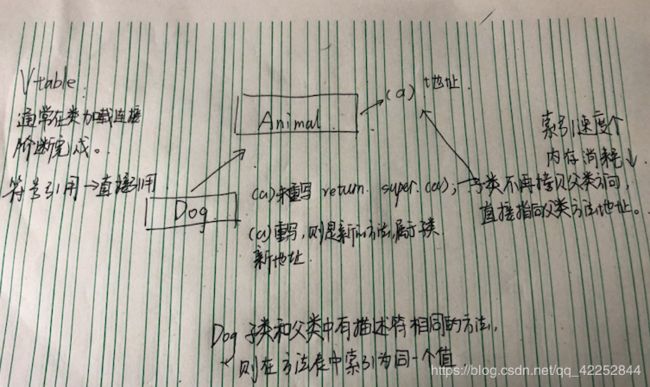
静态分派动态分派总结:
一是时间不同。静态分配发生在程序编译和连接的时候。动态分配则发生在程序调入和执行的时候。
二是空间不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由函数malloc进行分配。不过栈的动态分配和堆不同,他的动态分配是由编译器进行释放,无需我们手工实现。
基于栈的指令集与基于寄存器的指令集详细比对
现代JVM在执行Java代码时,通常都会将解释执行与编译执行二者结合起来进行
所谓解释执行,就是通过解释器来读取字节码,遇到相应的指令就去执行该指令
所谓编译执行,就是通过即时编译器(Just In Time,JIT)将字节码转换为本地机器码来执行;现代JVM会根据代码热点来生成相应的本地机器码
基于栈的指令集与基于寄存器的指令集之间的关系
1.JVM执行指令时所采取的方式是基于栈的指令集
2.基于栈的指令集主要的操作有入栈和出栈两种
3.基于栈的指令集的优势在于它可以在不同平台之间移植,而基于寄存器的指令集是与硬件架构紧密相关的,不能做道移植
4.基于栈道指令集的缺点在于完成相同的操作,指令数量通常要比基于寄存器的指令集数量要多;基于栈的指令集是在内存中完成操作的,而基于寄存器的指令集是直接由CPU来执行的,它是在高速缓冲区中进行执行的.速度要快很多.虽然虚拟机可以采用一些优化手段,但总体而言,基于栈的指令集的执行速度要慢一些
完成2-1的减法操作
1.iconst_1 将1压入栈顶
2.iconst_2 将2压入栈顶 1变成栈顶下面的数
3.isub 将栈顶以及栈顶下面的一个元素弹出执行减法得1,再将相减后的结果压入栈顶
4.istore_0 将1放入到局部变量表第0个位置上
JVM执行栈指令集实例剖析
public int myCalculate() {
int a = 1;
int b = 2;
int c = 3;
int d = 4;
int restlt = (a + b - c) * d;
return restlt;
}
Code:
stack=2, locals=6, args_size=1
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iconst_3
5: istore_3
6: iconst_4
7: istore 4
9: iload_1
10: iload_2
11: iadd
12: iload_3
13: isub
14: iload 4
16: imul
17: istore 5
19: iload 5
21: ireturn