机器学习中模型评估与旋转概念及利用Jupyter编程完成对手写体Mnist数据集中10个字符 (0-9)的分类识别
机器学习概念及分类识别
- 一、阅读“机器学习”(周志华著)第二章“模型评估与旋转”,理解“查准率”、“查全率”、“F1-Score”、“ROC”、“混淆矩阵”的定义。
- 1.查准率定义
- 2.查全率定义
- 3.F1-Score定义
- 4.ROC定义
- 5.混淆矩阵定义
- 二、学习“机器学习实战”第三章-分类器,Jupyter编程完成对手写体Mnist数据集中10个字符 (0-9)的分类识别
- 1.使用sklearn的函数来获取MNIST数据集
- 2.由于sklearn获取数据集所需时间较长,我们可以把这个程序运行时间计算出来,运行速度取决于电脑的性能。
- 3.数据集排序,生成数据集矩阵
- 4.查看数据集维度
- 5.展示图片
- 6.完成对手写体Mnist数据集中10个字符 (0-9)的分类识别
一、阅读“机器学习”(周志华著)第二章“模型评估与旋转”,理解“查准率”、“查全率”、“F1-Score”、“ROC”、“混淆矩阵”的定义。
1.查准率定义
查准率(Precision)(精度)是衡量某一检索系统的信号噪声比的一种指标,即检出的相关文献与检出的全部文献的百分比
查 准 率 = 检 索 出 的 相 关 信 息 量 检 索 出 的 信 息 量 ∗ 100 % 查准率=\frac{检索出的相关信息量}{检索出的信息量} *100 \% 查准率=检索出的信息量检索出的相关信息量∗100%
2.查全率定义
查全率(召回率,recall),是衡量某一检索系统从文献集合中检出相关文献成功度的一项指标,即检出的相关文献与全部相关文献的百分比。
查 全 率 = 检 索 出 的 相 关 信 息 量 系 统 中 的 相 关 信 息 量 ∗ 100 % 查全率=\frac{检索出的相关信息量}{系统中的相关信息量} *100 \% 查全率=系统中的相关信息量检索出的相关信息量∗100%
3.F1-Score定义
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种加权平均,它的最大值是1,最小值是0。
数学定义:F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为精确率和召回率的调和平均数。
F 1 = 2 ∗ p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l F1=2*\frac{precision∗recall }{precision+recall } F1=2∗precision+recallprecision∗recall
4.ROC定义
ROC的全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线——ROC 曲线。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过(0, 0),(1, 1)的曲线,这就是此分类器的ROC曲线。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。
5.混淆矩阵定义
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。
在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。
在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
二、学习“机器学习实战”第三章-分类器,Jupyter编程完成对手写体Mnist数据集中10个字符 (0-9)的分类识别
1.使用sklearn的函数来获取MNIST数据集
# 使用sklearn的函数来获取MNIST数据集
from sklearn.datasets import fetch_openml
import numpy as np
import os
import datetime
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 为了显示中文
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 耗时巨大
def sort_by_target(mnist):
reorder_train=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[:60000])]))[:,1]
reorder_test=np.array(sorted([(target,i) for i, target in enumerate(mnist.target[60000:])]))[:,1]
mnist.data[:60000]=mnist.data[reorder_train]
mnist.target[:60000]=mnist.target[reorder_train]
mnist.data[60000:]=mnist.data[reorder_test+60000]
mnist.target[60000:]=mnist.target[reorder_test+60000]
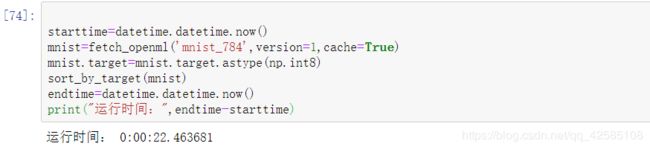
2.由于sklearn获取数据集所需时间较长,我们可以把这个程序运行时间计算出来,运行速度取决于电脑的性能。
starttime=datetime.datetime.now()
mnist=fetch_openml('mnist_784',version=1,cache=True)
mnist.target=mnist.target.astype(np.int8)
sort_by_target(mnist)
endtime=datetime.datetime.now()
print("运行时间:",endtime-starttime)
运行结果:
3.数据集排序,生成数据集矩阵
mnist["data"], mnist["target"]
运行结果:

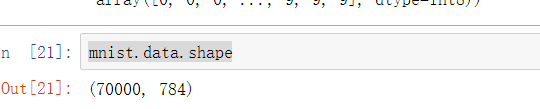
4.查看数据集维度
方法一:
mnist.data.shape
运行结果:
方法二:
X,y=mnist["data"],mnist["target"]
X.shape
运行结果:

方法三:
y.shape
28*28

5.展示图片
# 展示图片
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
some_digit = X[36000]
plot_digit(X[36000].reshape(28,28))
运行结果:

y[36000]
运行结果:
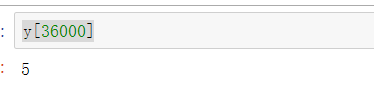
说明上图的的数字为5
6.完成对手写体Mnist数据集中10个字符 (0-9)的分类识别
# 更好看的图片展示
def plot_digits(instances,images_per_row=10,**options):
size=28
# 每一行有一个
image_pre_row=min(len(instances),images_per_row)
images=[instances.reshape(size,size) for instances in instances]
# 有几行
n_rows=(len(instances)-1) // image_pre_row+1
row_images=[]
n_empty=n_rows*image_pre_row-len(instances)
images.append(np.zeros((size,size*n_empty)))
for row in range(n_rows):
# 每一次添加一行
rimages=images[row*image_pre_row:(row+1)*image_pre_row]
# 对添加的每一行的额图片左右连接
row_images.append(np.concatenate(rimages,axis=1))
# 对添加的每一列图片 上下连接
image=np.concatenate(row_images,axis=0)
plt.imshow(image,cmap=mpl.cm.binary,**options)
plt.axis("off")
plt.figure(figsize=(9,9))
example_images=np.r_[X[:12000:600],X[13000:30600:600],X[30600:60000:590]]
plot_digits(example_images,images_per_row=10)
plt.show()
运行结果:
