Java爬虫:脚本之家电子书的信息提取
文章目录
- 概述
- 提取链接
- 代理池的搭建及应用
- 多线程的应用以提高提取电子书信息的速度
- 信息提取
- 信息存储
- 遇到到问题及解决方案
- 运行结果
- 总结
1.概述
本次对脚本之家电子书信息提取采用结构化信息提取。结构化提取是指把提取的数据结构定义成一个类,然后有一个解析网页的方法根据输入网页返回解析出来的类实例,具体内容可参考《解密搜索引擎技术实战》第三章索引内容的提取。定义好用来接收网页数据的电子书信息类,部分代码如下
public class JBContent {
String bookName;//书名
String bookSize;//书大小
String bookDesc;//书描述
String bookBelong;//书类别
String bookTime;//更新时间
String bookShare;//书分享码
String bookDowlink;//书下载页面链接
public JBContent(String bookName,String bookSize,String bookDesc,String bookBelong,
String bookShare,String bookDowlink,String bookTime){
this.bookName = bookName;
this.bookSize = bookSize;
this.bookDesc = bookDesc;
this.bookBelong = bookBelong;
this.bookShare = bookShare;
this.bookDowlink = bookDowlink;
this.bookTime = bookTime;
}
2.提取链接
脚本之家电子书籍热门导航下所属种类(如网页制作,CSS教程等)链接的提取
public static Map getUrl(String mainUrl)//采集热门导航下电子书种类的所有链接
{
Map map = new HashMap();
try {
Document doc = Jsoup.connect(mainUrl)
.header("User_Agent",getUserAgent())
.get();
Elements elements1 = doc.select(".cate.app > p > a");
for(int i= 0;i p > a");
for(int i = 0;i p > a");
for(int i = 0;i 3.代理池的搭建及应用
由于提取链接较多,访问次数频繁,为防止同一个IP访问次数达到一定的限制后封IP,也就是把这个IP列入黑名单,超过一段时间后再解封的问题。本例采用搭建代理池,用随机IP访问网页,至于搭建代理池的方法,可参靠这里,应用如下
- 收集User_Agent
static List USER_AGENT = new ArrayList() {
{
add("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Safari/537.36 Edge/13.10586");
add("Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko");
add("Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)");
add("Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0");
add("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)");
add("Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36");
add("Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0)");
add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 BIDUBrowser/8.3 Safari/537.36");
add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0");
add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.87 Safari/537.36 OPR/37.0.2178.32");
add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2");
add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
}
};
- 随机获取User_Agent
public static String getUserAgent()
{
Random random = new Random();
int i = random.nextInt(USER_AGENT.size());
String userAgent = USER_AGENT.get(i);
return userAgent;
}
- 建立随机Socket代理
public static Proxy randomProxy() //随机获得proxy
{
String proxyUrl = "http://127.0.0.1:5010/get/";
Proxy randomProxy = null;
HttpClient client = new DefaultHttpClient();
HttpGet httpget = new HttpGet(proxyUrl);
HttpResponse response = null;
try{
response = client.execute(httpget);
if(response.getStatusLine().getStatusCode()==200)
{
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity,"UTF-8");
JSONObject data = JSON.parseObject(content);
String proxydata = data.getString("proxy");
int pos = proxydata.indexOf(":");
if(pos > 0){
String port = proxydata.substring(pos+1);
String proxyaddr = proxydata.substring(0,pos);
int proxyPort = Integer.parseInt(port);
SocketAddress socketAddress = new InetSocketAddress(proxyaddr,proxyPort);
randomProxy = new Proxy(Proxy.Type.HTTP,socketAddress);
}
}
}catch(Exception e){
System.out.println("处理:"+proxyUrl+"失败,返回状态码:"+response.getStatusLine().getStatusCode());
return null;
}finally{
client.getConnectionManager().shutdown();
}
return randomProxy;
}
4.多线程的应用以提高提取电子书信息的速度
由于解析内容较多,单线程耗时长,可以考虑多线程以节约时间。实现如下
- 获得该种类下页面总数
public String getpageSum(String request) //获得页面总数
{
String snum ;
try{
Document doc = Jsoup.connect(request)
.userAgent(getUserAgent())
.get();
Element element = doc.select(".plist > a[href]").last();
if(element != null){
String link = element.attr("href");
snum = link.substring(link.lastIndexOf("_")+1,link.lastIndexOf("."));
}else{
snum = "1";
System.out.println("请检查:"+request+";是否为1页,已默认为1页");
}
}catch(IOException e){
snum = "1";
System.out.println("链接:"+request+"处理失败,已默认为1页");
}
return snum;
}
- 多线程的建立
ExecutorService threadPool = new ThreadPoolExecutor(4,10 ,60,
TimeUnit.SECONDS,new LinkedBlockingQueue<>());
public void run(){
lists = new LinkedBlockingQueue<>();
Map map = getUrl(mainUrl);
Set set = map.keySet();
Iterator it = set.iterator();
while(it.hasNext()){
String request = it.next();
String keyValue = map.get(request);
System.out.println("正在处理:"+request+";该"+keyValue+"共计"+getpageSum(request)+"页。");
int snum = Integer.parseInt(getpageSum(request));
for(int sum = 0;sum list = parseUrl(url);
if(list!=null){
lists.add(list);
}else {
}//什么都不做
System.out.println(url+"解析已经完成,准备写入Excel");
writeToExcel();
System.out.println(url+";已经写入Excel");
}
}
try{
Thread.sleep(60);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
- 解析内容
public static List parseUrl(String request)
{
List list = new ArrayList<>();
Proxy proxy = randomProxy();
long sleepMillis = 0;
for(int i = 0;i<5;i++)//IP代理出现问题时,循环
{
if (sleepMillis != 0) {
try {
Thread.sleep(sleepMillis);
} catch (InterruptedException e) {
e.printStackTrace();
}
sleepMillis = 0;
}
try {
Document doc = Jsoup.connect(request)
.proxy(proxy)
.userAgent(getUserAgent())
.validateTLSCertificates(false)//javax.net.ssl.SSLHandshakeException
.timeout(6000)
.get();
Elements elements = doc.select(".c-list.clearfix > li");
for (int j = 0; j < elements.size(); j++) {
String bookName = elements.get(j).select(".top-tit > .tit > a").text();
String bookDowlink = elements.get(j).select(".top-tit > .tit > a").attr("abs:href");
String bookBelong = elements.get(j).select(".item > .con > .rinfo > .other > .intro > a").text();
String size = elements.get(j).select(".item > .con > .rinfo > .other > span:nth-child(2)").text();
String bookSize = size.substring(size.lastIndexOf(":")+1);
String time = elements.get(j).select(".item > .con > .rinfo > .other > span:nth-child(3)").text();
String bookTime = time.substring(time.lastIndexOf(":")+1);
String bookDesc = elements.get(j).select(".item > .con > .rinfo > .desc").text();
String bookShare = bookDowlink.substring(bookDowlink.lastIndexOf("/") + 1, bookDowlink.lastIndexOf("."));
list.add(new JBContent(bookName, bookSize, bookDesc, bookBelong, bookShare, bookDowlink, bookTime));
}
}catch(IOException e){
System.out.println("处理:" + request + "失败,代理Proxy:" +proxy+";"+"\n"+"原因:"+e.toString());
proxy = randomProxy();
sleepMillis = 1000;
continue;
}
break;
}
if(list.size()==0)return null;
return list;
}
6.信息的存储
本例采用存入Excel,未采用存入数据库的方式,主要是加深对Java POI的应用
public void writeToExcel() {
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("zhangling");
HSSFRow row = sheet.createRow(0);
//设置列宽
sheet.setColumnWidth((short) 0, (short) (20 * 256));
sheet.setColumnWidth((short) 2, (short) (15 * 256));
sheet.setColumnWidth((short) 3, (short) (15 * 256));
sheet.setColumnWidth((short) 5, (short) (30 * 256));
sheet.setColumnWidth((short) 6, (short) (40 * 256));
HSSFCellStyle style = wb.createCellStyle();
style.setAlignment(HSSFCellStyle.ALIGN_CENTER);
HSSFCell cell2 = row.createCell(0);
cell2.setCellValue("书名");
cell2.setCellStyle(style);
HSSFCell cell3 = row.createCell(1);
cell3.setCellValue("大小");
cell3.setCellStyle(style);
HSSFCell cell4 = row.createCell(2);
cell4.setCellValue("更新时间");
cell4.setCellStyle(style);
HSSFCell cell5 = row.createCell(3);
cell5.setCellValue("类别");
cell5.setCellStyle(style);
HSSFCell cell6 = row.createCell(4);
cell6.setCellValue("分享码");
cell6.setCellStyle(style);
HSSFCell cell7 = row.createCell(5);
cell7.setCellValue("下载页面");
cell7.setCellStyle(style);
HSSFCell cell8 = row.createCell(6);
cell8.setCellValue("描述");
cell8.setCellStyle(style);
if (!lists.isEmpty()) {
FileOutputStream fos;
HSSFCellStyle style1 = wb.createCellStyle();
style1.setVerticalAlignment(HSSFCellStyle.VERTICAL_CENTER);//垂直居中
style1.setWrapText(true);//内容可换行
for (List list : lists) {
for (int j = 0; j < list.size(); j++) {
try {
row = sheet.createRow((short) sheet.getLastRowNum() + 1);
row.setHeight((short) (150 * 20));//设置行高,POI中的行高=Excel的行高度*20
HSSFCell cella = row.createCell(0);
cella.setCellValue(list.get(j).getBookName());
cella.setCellStyle(style1);
HSSFCell cellb = row.createCell(1);
cellb.setCellValue(list.get(j).getBookSize());
cellb.setCellStyle(style1);
HSSFCell cellc = row.createCell(2);
cellc.setCellValue(list.get(j).getBookTime());
cellc.setCellStyle(style1);
HSSFCell celld = row.createCell(3);
celld.setCellValue(list.get(j).getBookBelong());
celld.setCellStyle(style1);
HSSFCell celle = row.createCell(4);
celle.setCellValue(list.get(j).getBookShare());
celle.setCellStyle(style1);
HSSFCell cellg = row.createCell(5);
cellg.setCellValue(list.get(j).getBookDowlink());
cellg.setCellStyle(style1);
HSSFCell cellh = row.createCell(6);
cellh.setCellValue(list.get(j).getBookDesc());
cellh.setCellStyle(style1);
fos = new FileOutputStream(new File("C:Users/Xiao Mi/Desktop/gaiext.xls"));
wb.write(fos);
fos.flush();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
7.遇到到问题及解决方案
- javax.net.ssl.SSLHandshakeException;可参考这里解决方法如下
Document doc = Jsoup.connect(request)
.proxy(proxy)
.userAgent(getUserAgent())
.validateTLSCertificates(false)//javax.net.ssl.SSLHandshakeException
.timeout(6000)
.get();
2.java.util.NoSuchElementException;未解决,但不影响程序的运行
运行结果
主要的结果图如下
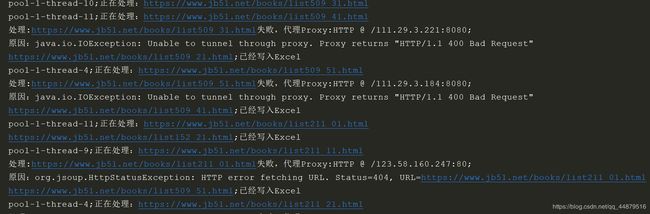
总结
由于第一次学习Java,代码总有不足之处,还需要继续学习,不断完善。脚本之家的下载地址大部分都放在百度网盘上,本次未能提取网盘地址,可参考方法如下:
public static String getPanaddr(String bookDowlink,Proxy proxy,String userAgent){
String panAddr;
try{
Document doc = Jsoup.connect(bookDowlink)
.validateTLSCertificates(false)//javax.net.ssl.SSLHandshakeException
.timeout(6000)
.userAgent(userAgent)
.proxy(proxy)
.get();
Element element = doc.select("li.baidu > a").first();
if(element != null){
panAddr = element.attr("href");
}else{
return null;
}
}catch(IOException e){
System.out.println("链接:"+bookDowlink+";获取网盘地址失败");
return null;
}
return panAddr;
}
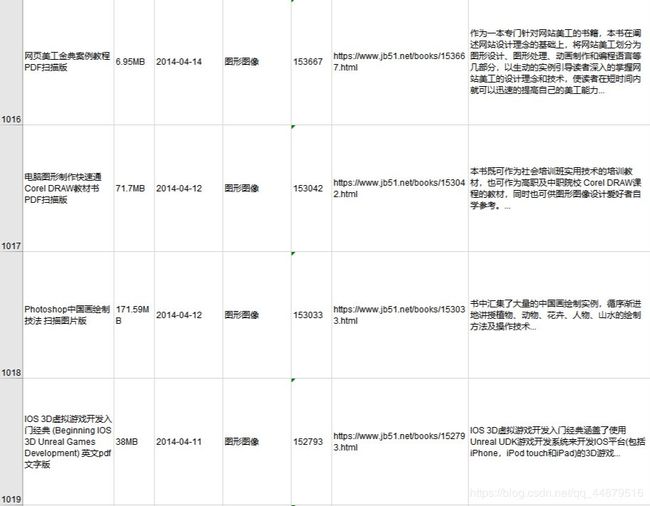
最终结果图如下
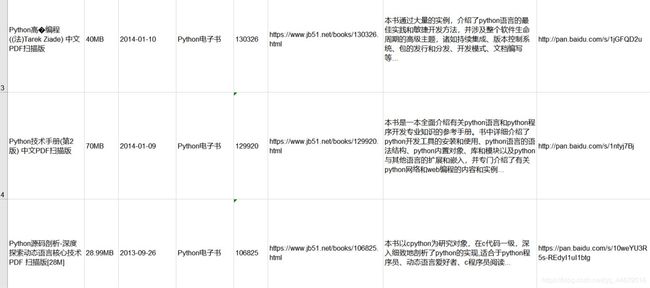
初次使用Java,如有不足,请多多原谅!!!