让你python代码更快的3个小技巧
大家好!今天呢,我们来聊一聊如何加速你的 python 代码。
Python 语言的优点可以列举出许多,语法简单易懂、模块丰富、应用广泛等等。但是世界上没有有完美的东西,python 一个明显缺点就是运行速度慢,至少跟 C 语言没法比。

所以,不安于现状的 Pythoner 就开发了许多工具。其中,最著名的莫过于 Cython 和 Numba。其中 Cython 可以把 Python 代码转成 C 代码执行,而 Numba 则是 Python 中的一个 JIT 编译器(即时编译器),以此提高运行效率。

不过我们今天不讲这些复杂的工具,看看能不能只通过改进你的 Python 代码以提高速度。
一、函数
函数可以提高代码的可读性,那么用了函数对程序的执行效率是否有影响呢?我们来做个对比实验。
先来看一个不用函数的版本:
import math
import time
start = time.time() # 开始计时
lst = [] # 定义一个空列表
for i in range(1, 10000000):
lst.append(math.sqrt(i)) # 疯狂地往列表里添加计算结果
end = time.time() # 停止计时
print(end-start)
此代码在我的电脑上输出为 2.124 (不同配置的电脑结果不一样,可多次运行取平均值)。再来加上函数试一下:
import math
import time
def func():
lst = [] # 定义一个空列表
for i in range(1, 10000000):
lst.append(math.sqrt(i)) # 疯狂地往列表里添加计算结果
return lst # 返回结果
start = time.time() # 开始计时
lst = func()
end = time.time() # 停止计时
print(end-start)
在我的电脑上, 使用了函数的程序用了大概花了 1.743 秒。多次尝试,基本上都会比上一个版本节省 15~20% 左右时间,这个差距还是存在的。
有人可能会觉得,增加了 函数 调用,效率可能会低。但实际上,我们这里只是增加了一次调用,影响甚微。而由于 Python 中 局部变量 和 全局变量 的实现方式不同, 使用局部变量效率会高些 。
所以使用函数不仅提高可读性,用得好还能让代码运行得更快。
二、去掉属性访问
再来看另一个例子,还是刚才的函数版本,我们做一点修改,改变其中导入函数的方式,由 math.sqrt 改为 sqrt:
from math import sqrt # 直接引用特定函数或属性
import time
def func():
lst = []
for i in range(1, 10000000):
lst.append(sqrt(i)) # 直接调用 sqrt
return lst
start = time.time()
lst = func()
end = time.time()
print(end-start)
在其它代码均没有变动的情况下,这个程序的输出时间变成了……
1.413 秒!
居然更快了。这又是为什么呢?
因为在进行 属性访问 的时候啊,会调用这个对象的 __getattribute__ 或者 __getattr__ 方法,造成了额外的开销,所以导致速度变慢。
三、列表推导式
最后再来看看 列表推导式(List Comprehension) ,它的效率和普通 for 循环会有不一样吗?
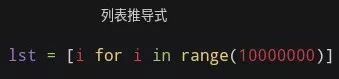
继续在上一个版本上修改:
from math import sqrt
import time
def func():
# for 循环改为列表推导式
lst = [sqrt(i) for i in range(1, 10000000)]
return lst
start = time.time()
lst = func()
end = time.time()
print(end-start)
结果是 0.968 秒!
这又是为什么呢?因为 列表推导式内的迭代是 C 实现 的,所以效率更高。
同最初的版本相比,实现同样的效果,我们仅通过调整代码的写法,速度就提高了一倍还多。
各位 Pythoner,你们学到了吗?
大家好!今天呢,我们来聊一聊如何加速你的 python 代码。
Python 语言的优点可以列举出许多,语法简单易懂、模块丰富、应用广泛等等。但是世界上没有有完美的东西,python 一个明显缺点就是运行速度慢,至少跟 C 语言没法比。
所以,不安于现状的 Pythoner 就开发了许多工具。其中,最著名的莫过于 Cython 和 Numba。其中 Cython 可以把 Python 代码转成 C 代码执行,而 Numba 则是 Python 中的一个 JIT 编译器(即时编译器),以此提高运行效率。
不过我们今天不讲这些复杂的工具,看看能不能只通过改进你的 Python 代码以提高速度。
一、函数
函数可以提高代码的可读性,那么用了函数对程序的执行效率是否有影响呢?我们来做个对比实验。
先来看一个不用函数的版本:
import mathimport timestart = time.time() # 开始计时lst = [] # 定义一个空列表for i in range(1, 10000000):lst.append(math.sqrt(i)) # 疯狂地往列表里添加计算结果end = time.time() # 停止计时print(end-start)
此代码在我的电脑上输出为 2.124(不同配置的电脑结果不一样,可多次运行取平均值)。再来加上函数试一下:
import mathimport timedef func():lst = [] # 定义一个空列表for i in range(1, 10000000):lst.append(math.sqrt(i)) # 疯狂地往列表里添加计算结果return lst # 返回结果start = time.time() # 开始计时lst = func()end = time.time() # 停止计时print(end-start)
在我的电脑上,使用了函数的程序用了大概花了 1.743 秒。多次尝试,基本上都会比上一个版本节省 15~20% 左右时间,这个差距还是存在的。
有人可能会觉得,增加了函数调用,效率可能会低。但实际上,我们这里只是增加了一次调用,影响甚微。而由于 Python 中局部变量和全局变量的实现方式不同,使用局部变量效率会高些。
所以使用函数不仅提高可读性,用得好还能让代码运行得更快。
二、去掉属性访问
再来看另一个例子,还是刚才的函数版本,我们做一点修改,改变其中导入函数的方式,由 math.sqrt 改为 sqrt:
from math import sqrt # 直接引用特定函数或属性import timedef func():lst = []for i in range(1, 10000000):lst.append(sqrt(i)) # 直接调用 sqrtreturn lststart = time.time()lst = func()end = time.time()print(end-start)
在其它代码均没有变动的情况下,这个程序的输出时间变成了……
1.413 秒!
居然更快了。这又是为什么呢?
因为在进行属性访问的时候啊,会调用这个对象的 __getattribute__ 或者 __getattr__ 方法,造成了额外的开销,所以导致速度变慢。
三、列表推导式
最后再来看看列表推导式(List Comprehension),它的效率和普通 for 循环会有不一样吗?
继续在上一个版本上修改:
from math import sqrtimport timedef func():# for 循环改为列表推导式lst = [sqrt(i) for i in range(1, 10000000)]return lststart = time.time()lst = func()end = time.time()print(end-start)
结果是 0.968 秒!
这又是为什么呢?因为列表推导式内的迭代是 C 实现的,所以效率更高。
同最初的版本相比,实现同样的效果,我们仅通过调整代码的写法,速度就提高了一倍还多。
各位 Pythoner,你们学到了吗?