TF-IDF的理解
一直对TF-IDF的概念理解的不太清楚,所以写篇博客来理一理。
1.定义(概括)
在信息检索中,tf-idf(词频-逆文档频率)是一种统计方法,用以评估一个单词在一个文档集合或语料库中的重要程度。经常被用作信息检索、文本挖掘以及用户模型的权重因素。tf-idf的值会随着单词在文档中出现的次数的增加而增大,也会随着单词在语料库中出现的次数的增多而减小。tf-idf是如今最流行的词频加权方案之一。
tf-idf的各种改进版本经常被搜索引擎用作在给定用户查询时对文档的相关性进行评分和排序的主要工具。tf-idf可以成功地用于各种主题字段的停用词过滤,包括文本摘要和分类。
最简单的排序函数之一就是通过对每个查询项的tf-idf值求和得到的;许多更复杂的排序函数就是这个简单模型的变体。
2.TF和IDF各自的含义
TF(词频)
假设我们有一组英文文本文档集合,现在希望根据对查询词条的重要性(哪个文档对该词条来说相关性最强)来对这些文档进行排序,假设查询词条为,“the brown cow"。初始,一个最简单的方法是,删除所有不包含"the","brwon","cow"的文档,但是删除之后,仍然会留下许多文档。为了进一步区分它们,我们可以计算每个词条在每个文档中出现的次数(词频)。然而,在文档长度变化很大的情况下,需经常进行调整,词频加权的第一种形式是由Hans Peter Luhn(1957)提出来的,可简要概括如下:
一篇文档中出现某一词条的权重与词频呈简单的正比关系。
IDF(逆文档频率)
由于词条"the"非常常见,词频往往会错误地强调频繁使用"the"这个词条的文件,而不能给一些更优意义的词条"brown","cow"足够的权重。词条"the"并不像较为少见的"brown"和"cow"一样,是能区分相关文档和不相关文档的关键词,因此,引入了逆文档频率因子,它减少了在文档集中出现非常频繁的词条的权重,并且增加了出现很少的词频的权重。
Karen Sparck Jones(1972)提出了词条特异性的统计学解释,称之为逆文档频率(IDF):
词条的特异性可以被量化为包含该词的文档数的逆函数。
3.数学定义
tf-idf是两个统计量,词频和逆文档频率的乘积。有多种方法可以用来确定两个统计量的确切值。
TF
在一份给定的文件里,词频(TF)指的是某一个给定的词在该文件中出现的频率。这个数字是怼词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比在短文件里有更高的词数,而不管该词语重要与否)对于在某一个特定文件里的词语ti来说,它的重要性可以表示为:

其中 ni,j 是该词在文件 dj 中出现的次数,而分母则是文件 dj 中所有词汇出现的次数总和。更通俗的表示方式就是:

IDF
逆文档频率(IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
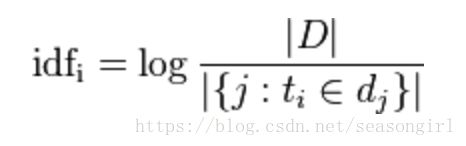
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|。同样,如果用更直白的语言表示就是

最后,便可以来计算 TF-IDF(t) = TF(t) * IDF(t) 。
4.参考资料
[1] https://en.wikipedia.org/wiki/Tf%E2%80%93idf
[2] https://blog.csdn.net/baimafujinji/article/details/51476117
[3] https://blog.csdn.net/sangyongjia/article/details/52440063