朴素贝叶斯
http://www.cnblogs.com/marc01in/p/4775440.html
引
和师弟师妹聊天时经常提及,若有志于从事数据挖掘、机器学习方面的工作,在大学阶段就要把基础知识都带上。 机器学习在大数据浪潮中逐渐展示她的魅力,其实《概率论》、《微积分》、《线性代数》、《运筹学》、《信息论》等几门课程算是前置课程,当然要转化为工程应用的话,编程技能也是需要的,而作为信息管理专业的同学,对于信息的理解、数据的敏感都是很好的加分项。
不过光说不练,给人的留下的印象是极为浅薄的,从一些大家都熟悉的角度切入,或许更容易能让人有所体会。
下面进入正题。
BTW,如果观点错误或者引用侵权的欢迎指正交流。
一、朴素贝叶斯算法介绍
朴素贝叶斯,之所以称为朴素,是因为其中引入了几个假设(不用担心,下文会提及)。而正因为这几个假设的引入,使得模型简单易理解,同时如果训练得当,往往能收获不错的分类效果,因此这个系列以naive bayes开头和大家见面。
因为朴素贝叶斯是贝叶斯决策理论的一部分,所以我们先快速了解一下贝叶斯决策理论。
假设有一个数据集,由两类组成(简化问题),对于每个样本的分类,我们都已经知晓。数据分布如下图(图取自MLiA):

现在出现一个新的点new_point (x,y),其分类未知。我们可以用p1(x,y)表示数据点(x,y)属于红色一类的概率,同时也可以用p2(x,y)表示数据点(x,y)属于蓝色一类的概率。那要把new_point归在红、蓝哪一类呢?
我们提出这样的规则:
如果p1(x,y) > p2(x,y),则(x,y)为红色一类。
如果p1(x,y) 换人类的语言来描述这一规则:选择概率高的一类作为新点的分类。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。 用条件概率的方式定义这一贝叶斯分类准则: 如果p(red|x,y) > p(blue|x,y), 则(x,y)属于红色一类。 如果p(red|x,y) < p(blue|x,y), 则(x,y)属于蓝色一类。 也就是说,在出现一个需要分类的新点时,我们只需要计算这个点的 max(p(c1 | x,y),p(c2 | x,y),p(c3 | x,y)...p(cn| x,y))。其对于的最大概率标签,就是这个新点的分类啦。 那么问题来了,对于分类i 如何求解p(ci| x,y)? 没错,就是贝叶斯公式: 公式暂不推导,先描述这个转换的重要性。红色、蓝色分类是为了帮助理解,这里要换成多维度说法了,也就是第二部分的实例:判断一条微信朋友圈是不是广告。 前置条件是:我们已经拥有了一个平日广大用户的朋友圈内容库,这些朋友圈当中,如果真的是在做广告的,会被“热心网友”打上“广告”的标签,我们要做的是把所有内容分成一个一个词,每个词对应一个维度,构建一个高维度空间 (别担心,这里未出现向量计算)。 当出现一条新的朋友圈new_post,我们也将其分词,然后投放到朋友圈词库空间里。 这里的X表示多个特征(词)x1,x2,x3...组成的特征向量。 P(ad|x)表示:已知朋友圈内容而这条朋友圈是广告的概率。 利用贝叶斯公式,进行转换: P(ad|X) = p(X|ad) p(ad) / p(X) P(not-ad | X) = p(X|not-ad)p(not-ad) / p(X) 比较上面两个概率的大小,如果p(ad|X) > p(not-ad|X),则这条朋友圈被划分为广告,反之则不是广告。 看到这儿,实际问题已经转为数学公式了。 看公式推导 (公式图片引用): 朴素贝叶斯分类的正式定义如下: 1、设 2、有类别集合 3、计算 4、如果 那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做: 1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2、统计得到在各类别下各个特征属性的条件概率估计。即。 3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: 因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有: 这里要引入朴素贝叶斯假设了。如果认为每个词都是独立的特征,那么朋友圈内容向量可以展开为分词(x1,x2,x3...xn),因此有了下面的公式推导: P(ad|X) = p(X|ad)p(ad) = p(x1, x2, x3, x4...xn | ad) p(ad) 假设所有词相互条件独立,则进一步拆分: P(ad|X) = p(x1|ad)p(x2|ad)p(x3|ad)...p(xn|ad) p(ad) 虽然现实中,一条朋友圈内容中,相互之间的词不会是相对独立的,因为我们的自然语言是讲究上下文的╮(╯▽╰)╭,不过这也是朴素贝叶斯的朴素所在,简单的看待问题。 看公式p(ad|X)=p(x1|ad)p(x2|ad)p(x3|ad)...p(xn|ad) p(ad) 至此,P(xi|ad)很容易求解,P(ad)为词库中广告朋友圈占所有朋友圈(训练集)的概率。我们的问题也就迎刃而解了。 到这里,应该已经有心急的读者掀桌而起了,捣鼓半天,没有应用。 (╯‵□′)╯︵┻━┻ "Talk is cheap, show me the code." 逻辑均在代码注释中,因为用python编写,和伪代码没啥两样,而且我也懒得画图…… 代码测试效果: 1、训练。 2、实例测试。 分类为1则归为广告,0为普通文本。 
 为一个待分类项,而每个a为x的一个特征属性。
为一个待分类项,而每个a为x的一个特征属性。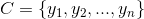 。
。 。
。 ,则
,则  。
。
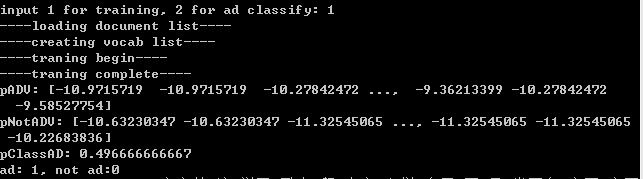
二、构造一个文字广告过滤器。
 View Code
View Code