R语言︱LDA主题模型——最优主题数选取(topicmodels)+LDAvis可视化(lda+LDAvis)
笔者寄语:在自己学LDA主题模型时候,发现该模型有这么几个未解决的问题:
1、LDA主题数量,多少个才是最优的。
2、作出主题之后,主题-主题,主题与词语之间关联如何衡量。
于是在查阅几位老师做的成果之后,将他们的成果撮合在一起。笔者发现R里面目前有两个包可以做LDA模型,是lda包+topicmodels包,两个包在使用的过程中,需要整理的数据都是不一样的,所以数据处理会是一个不省心的过程。
主题模型的概念,网络上的博客很多都有介绍,算是比较成型的一个方法,笔者推荐以下博客:
1、主题模型-LDA浅析
2、LDA-math-LDA 文本建模
3、主题模型
—————————————————————————————————————————
两种的估计方法——VEM 以及 gibbs
通常逼近这个后验分布的方法可以分为两类:
1. 变异算法(variational algorithms),这是一种决定论式的方法。变异式算法假设一些参数分布,并根据这些理想中的分布与后验的数据相比较,并从中找到最接近的。由此,将一个估计问题转化为最优化问题。最主要的算法是变异式的期望最大化算法(variational expectation-maximization,VEM)。这个方法是最主要使用的方法。在R软件的tomicmodels包中被重点使用。
2. 基于抽样的算法。抽样的算法,如吉布斯抽样(gibbs sampling)主要是构造一个马尔科夫链,从后验的实证的分布中抽取一些样本,以之估计后验分布。吉布斯抽样的方法在R软件的lda包中广泛使用。
参考:使用R做主题模型:词语筛选和主题数量确定
————————————————————————————————————————————————————————
R包列举——lda和topicmodel
在R语言中,有两个包(package)提供了LDA模型:lda和topicmodels。
lda提供了基于Gibbs采样的经典LDA、MMSB(the mixed-membership stochastic blockmodel )、RTM(Relational Topic Model)和基于VEM(variational expectation-maximization)的sLDA (supervised LDA)、RTM.。
topicmodels基于包tm,提供LDA_VEM、LDA_Gibbs、CTM_VEM(correlated topics model)三种模型。
另外包textir也提供了其他类型的主题模型。
参考:R之文档主题模型
—————————————————————————————————————————————————
R语言第三包:LDA主题模型又有了一个新包:text2vec包
LDA主题模型是基于lda包开发的(Jonathan Chang),在下次发布的时候该主题模型的引擎就会嵌入到lda包之中,目前text2vec开发模型要比lda快2倍,比topicmodels包快10倍。LSA模型是基于irlab包。
可参考博客:
重磅︱R+NLP:text2vec包简介(GloVe词向量、LDA主题模型、各类距离计算等)
————————————————————————————————————————
R语言第四包:dfrtopics
dfrtopics历史很悠久,但是国内很少有人提及这个packages,这个包是通过调用java里面的MALLET 来进行运作。
github主页:https://github.com/agoldst/dfrtopics
介绍几个函数:
1、top_words
## topic word weight
##
## 1 1 two 3602
## 2 1 evidence 1779
## 3 1 original 1472
## 4 1 fact 1452
## 5 1 lines 1410
## 6 1 case 1350
## 7 1 found 1221
## 8 1 line 1086
## 9 1 given 1029
## 10 1 question 968
## # ... with 390 more rows 2、逆天功能
查看主题随着时间的趋势波动情况,topic_series
srs <- topic_series(m, breaks="years")
head(srs)
## topic pubdate weight
## 1 1 1906-01-01 0.05454418
## 2 1 1907-01-01 0.02907561
## 3 1 1908-01-01 0.05912942
## 4 1 1909-01-01 0.06755607
## 5 1 1910-01-01 0.04966935
## 6 1 1911-01-01 0.07378674还有可视化功能
————————————————————————————————————————
一、最优主题数选取
本部分来自于大音如霜(公众号)团队,用不同主体数量下的复杂度以及对数似然值作为评判指标。
对于未知分布q,复杂度的值越小,说明模型越好,而对数似然值越大越好,刚好相反。基于复杂度和对数似然值判断语料库中的主题数量,就是计算不同主题数量下的复杂度和对数似然值之间的变化。可以将复杂度和对数似然值变化的拐点对应的主题数作为标准主题数,拐点以后复杂度和对数似然值的变化区域平缓。观察拐点和趋势需要对数据可视化,因此,分别做复杂度、对数似然值与主题数目的趋势图。
关于主题数的选择,网络中大多是在topicmodels包之上开发而得:
fold_num = 10
kv_num = c(5, 10*c(1:5, 10))
seed_num = 2003
smp<-function(cross=fold_num,n,seed)
{
set.seed(seed)
dd=list()
aa0=sample(rep(1:cross,ceiling(n/cross))[1:n],n)
for (i in 1:cross) dd[[i]]=(1:n)[aa0==i]
return(dd)
}
selectK<-function(dtm,kv=kv_num,SEED=seed_num,cross=fold_num,sp) # change 60 to 15
{
per_ctm=NULL
log_ctm=NULL
for (k in kv)
{
per=NULL
loglik=NULL
for (i in 1:3) #only run for 3 replications#
{
cat("R is running for", "topic", k, "fold", i,
as.character(as.POSIXlt(Sys.time(), "Asia/Shanghai")),"\n")
te=sp[[i]]
tr=setdiff(1:nrow(dtm),te)
# VEM = LDA(dtm[tr, ], k = k, control = list(seed = SEED)),
# VEM_fixed = LDA(dtm[tr,], k = k, control = list(estimate.alpha = FALSE, seed = SEED)),
CTM = CTM(dtm[tr,], k = k,
control = list(seed = SEED, var = list(tol = 10^-4), em = list(tol = 10^-3)))
# Gibbs = LDA(dtm[tr,], k = k, method = "Gibbs",
# control = list(seed = SEED, burnin = 1000,thin = 100, iter = 1000))
per=c(per,perplexity(CTM,newdata=dtm[te,]))
loglik=c(loglik,logLik(CTM,newdata=dtm[te,]))
}
per_ctm=rbind(per_ctm,per)
log_ctm=rbind(log_ctm,loglik)
}
return(list(perplex=per_ctm,loglik=log_ctm))
}
sp=smp(n=nrow(dtm),seed=seed_num)
system.time((ctmK=selectK(dtm=dtm,kv=kv_num,SEED=seed_num,cross=fold_num,sp=sp)))
## plot the perplexity
m_per=apply(ctmK[[1]],1,mean)
m_log=apply(ctmK[[2]],1,mean)
k=c(kv_num)
df = ctmK[[1]] # perplexity matrix
matplot(k, df, type = c("b"), xlab = "Number of topics",
ylab = "Perplexity", pch=1:5,col = 1, main = '')
legend("bottomright", legend = paste("fold", 1:5), col=1, pch=1:5) 有趣的是计算时间:
> system.time((ctmK=selectK(dtm=dtm,kv=kv_num,SEED=seed_num,cross=fold_num,sp=sp)))
R is running for topic 5 fold 1 2013-08-31 18:26:32
R is running for topic 5 fold 2 2013-08-31 18:26:39
R is running for topic 5 fold 3 2013-08-31 18:26:45
R is running for topic 10 fold 1 2013-08-31 18:26:50
R is running for topic 10 fold 2 2013-08-31 18:27:14
R is running for topic 10 fold 3 2013-08-31 18:27:36
R is running for topic 20 fold 1 2013-08-31 18:27:57
R is running for topic 20 fold 2 2013-08-31 18:29:42
R is running for topic 20 fold 3 2013-08-31 18:32:00
R is running for topic 30 fold 1 2013-08-31 18:33:42
R is running for topic 30 fold 2 2013-08-31 18:37:39
R is running for topic 30 fold 3 2013-08-31 18:45:46
R is running for topic 40 fold 1 2013-08-31 18:52:52
R is running for topic 40 fold 2 2013-08-31 18:57:26
R is running for topic 40 fold 3 2013-08-31 19:00:31
R is running for topic 50 fold 1 2013-08-31 19:03:47
R is running for topic 50 fold 2 2013-08-31 19:04:02
R is running for topic 50 fold 3 2013-08-31 19:04:52
R is running for topic 100 fold 1 2013-08-31 19:05:42
R is running for topic 100 fold 2 2013-08-31 19:06:05
R is running for topic 100 fold 3 2013-08-31 19:06:28
user system elapsed
2417.801.13 2419.28 看一下最终绘制的perplexity的图,如下可见,在本例当中,当主题数量为30的时候,perplexity最小,模型的最大似然率最高,由此确定主题数量为30。 (code参考:使用R做主题模型:词语筛选和主题数量确定)
————————————————————————————————————————
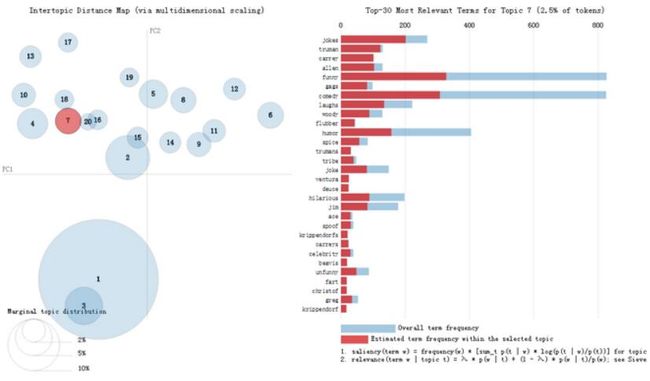
二、LDAvis可视化
该包作者探究了主题-主题,主题-词语之间的关联,主题-主题用多维标度的方式,将两者投影在低维空间,从而进行比较。
主题与词语之间的关联,以前一般是直接用每个词条的词频、TFIDF来衡量主题与词语的关联,作者用了以下的公式(公式整理来自计算传播网)
relevance(term w | topic t) = λ * p(w | t) + (1 - λ) * p(w | t)/p(w);该主题-词语关联度大概就是综合了,词频+词语的独特性,两种属性,其中这个λ就是调节两种属性哪个重要的参数。在0-1之间,可以由研究者自己调节,当然这个λ究竟多少为好,看具体案例具体分析。
笔者在实践的过程中,因为分词的过程中没有把无效词洗干净,最后主题数会出现很多垃圾词,通过调节这个λ,碰运气可以消除一些垃圾词,笔者还没找出λ最优办法,基本靠蒙...
打开文件需要用特殊的浏览器:Mozilla Firefox(如图)
————————————————————————————————————————
三、topicmodels+lda+LDAvis包的使用
三个包的使用,所需要的数据结构都是不一样的,一个个来看一下。当然最开始的基本文本处理都是一样的,整理文本,分词,清洗,去停用词,去垃圾词之类的。
特别是去垃圾词这个步骤,对结果影响很大,很多无效词凭借着高出现率,占据每个主题的较高排名。去除无效词的清洗过程,一定要反复执行,清洗。
topicmodels包+lda包都需要将文本数据,转化成list,一个list装着一个文档的词语,笔者跟着大音如霜老师,拿到的46个政府工作报告。于是list存着46个文档,每个list存在每年政府工作报告的所有单词(假设该数据名字为list)(Mark:标记(一)中的第90行代码)。
1、LDA建模——topicmodels包
需要把list成为文档-词频矩阵,用tm包可以实现。此包解释不如lda包,因为里面有很多的东西都没作出比较好的解释。
wordcorpus <- Corpus(VectorSource(list))
# `VectorSource`是将vector转化为Source,`Corpus`函数再将Source对象转化为Corpus对象
library(tm)
dtm <- DocumentTermMatrix(wordcorpus,
control = list(
wordLengths=c(2, Inf), # 限制词长
bounds = list(global = c(5,Inf)), # 设置词的最小频率
removeNumbers = TRUE, #removeNumbers设置是否移除数字
weighting = weightTf, #词频率权重,以TF(词频),还可以设置weighTfIdf,weightBin,weightSMART
encoding = "UTF-8"))2.LDA建模——lda包
lda包需要两个特殊数据集。一个是全文档的单词数据vocab、一个是每个文档的固定格式的数据documents。
vocab就是所有文档放在一起的一个chr格式文件。
![]()
documents是一个list格式,每个文档存放一个list。

上图是documents的数据结构,46个文档中的一个文档,第一行代表某个词的序号,第二行代表某个词出现在这个文档中的词频。
get.terms <- function(x) {
index <- match(x, vocab) #获取词的ID
index <- index[!is.na(index)] #去掉没有查到的,也就是去掉了的词
rbind(as.integer(index - 1), as.integer(rep(1, length(index)))) #生成上图结构
}
documents <- lapply(list, get.terms)3、可视化包——LDAvis包
可视化对数据的要求比较高,从以下的代码可以看出,需要主题-词语分布矩阵(phi)、文档—主题分布矩阵(theta)、单词(vocab)、每篇文章单词个数(doc.length)、
词频(term.frequency)。
library(LDAvis)
json <- createJSON(phi = phi, theta = theta,
doc.length = doc.length, vocab = vocab,
term.frequency = term.frequency)单词,4855个,chr字符型;
词频,4855个,int整数型;
主题-词语分布矩阵(phi)为一个大矩阵,30*4855(主题*词语),Matrix格式,具体计算过程可参考计算传播网;
文档—主题分布矩阵(theta),46*30(文档*主题),matrix格式,参考计算传播网;
每篇文章单词个数,46个,Int整数型,46个文档46个数字。
之后就可以开始建模了。
————————————————————————————————————————————————————
四、可视化图的其他、拓展
基于lda的拓展包有LDAvis,但是基于topicmodel就非常多。
1、词语网络图
有点知识图谱的雏形,原理就是社交网络的那套内容(可参考:R语言︱SNA-社会关系网络 R语言实现专题(基础篇)(一))

相关参考:东风夜放花千树:对宋词进行主题分析初探
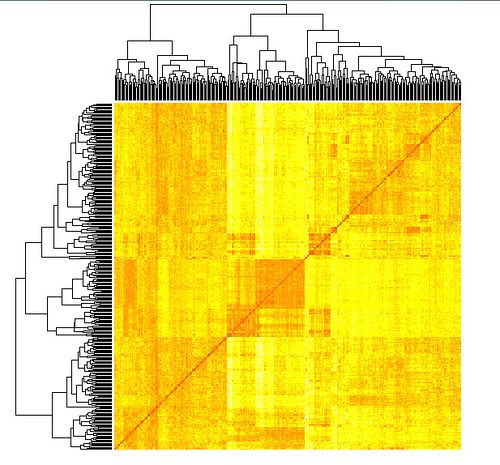
2、单词聚类图
通过LDA获取的词向量矩阵进行层次聚类而得到的,相关可参考:自然语言处理︱简述四大类文本分析中的“词向量”(文本词特征提取)

可参考:东风夜放花千树:对宋词进行主题分析初探
当然还有这个图还有一个比较实际的意义就是:
看LDA主题凝练的效果。与单纯用词频文档聚类而得的热力图对比如下:
参考:微博名人那些事儿
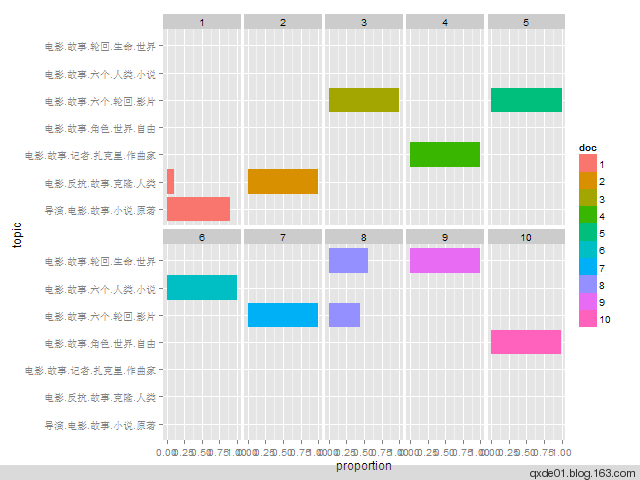
3、主题内容分布图
下图展示了所有文档主题概率分布,颜色越深,表示属于该主题的概率越高。对于训练集,大多数样本都可以归属到一个突出的主题,但也有不少样本归属不明显,对于测试集的预测效果更差。alpha初始值不同的情况下,每次运行结果可能不一样,有时差别可能很大。

参考:R之文档主题模型
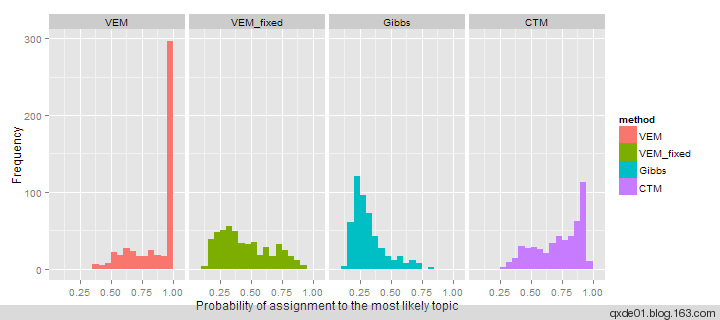
4、模型比较图
在topicmodel使用过程中,可能有很多的模型拿进来一起比较。根据主题归属合并词频矩阵, LDA_VEM、 LDA_Gibbs的主题余玄相似度如下图,颜色越浅(偏黄色)相似度越高,LDA_Gibbs主题之间的差异性比LDA_VEM要小。
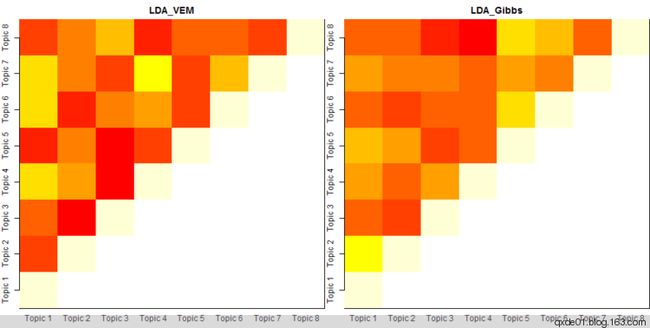
参考:R之文档主题模型
延伸一:论文解读:LDA+RNN,主题模型的深度学习化
这篇文章来自微软研究院和哥伦比亚大学的学者共同完成。作者中的Chong Wang以及John Paisley都有长期从事Graphical Models以及Topic Models的研究工作。
这篇文章想要做的事情非常直观,那就是想把在深度学习中非常有效的序列模型——RNN和在文档分析领域非常有效的Topic Models结合起来。这里面的原因就是,RNN比较能够抓住文档的“局部信息”(Local Structure),而Topic Models对于文档的“全局信息”(Global Structure)则更能有效把握。之前也有一些这样的尝试了,不过这篇文章提出了一种简单直观的模型。
首先,每一个文档有一个基于高斯分布的Topic Vector。这一步就和传统的latent Dirichlet allocation (LDA)有了区别,因为传统上这个Vector常常是基于Dirichlet分布。然后对于文档里面的每一个字,都采用了类似RNN的产生构造方法。首先,要产生每个字的一个隐含状态。这个隐含状态的产生,都基于之前的一个字本身,以及前面一个字的隐含状态。产生了隐含状态以后,这篇文章这里做了这么一个假设,那就是有两个类型的语言模型来控制文档里具体字的产生。一种是一个类似Stop Word的语言模型(Language Model),一种是普通的Topical语言模型。那么,在一个字的隐含状态产生以后,作者们有设计了一个基于当前字的隐含状态的伯努利分布,来决定当前这个字,是不是Stop Word。如果这个字是Stop Word,那这个字就从Stop Word的语言模型产生,如果这个词不是Stop Word,那就从Stop Word以及Topical语言模型产生。也就是说,作者们认为,Stop Word的影响是肯定有的,但Topical的影响则不一定有。这就是这个TopicRNN模型的一个简单描述。
文章采用了Variational Auto-encoder的方式来做Inference。这里就不复述了。
值得注意的是,文章本身提出的模型可以适用不同的RNN,比如文章在试验里就展示了普通的RNN、LSTM以及GRU的实现以及他们的结果。总的来说,使用了TopicRNN的模型比单独的RNN或者简单使用LDA的结果作为Feature要好,而且GRU的实现要比其他RNN的类型要好。
目前没有开源代码,关注中!