DeepLearning.ai作业:(5-3) -- 序列模型和注意力机制
title: ‘DeepLearning.ai作业:(5-3) – 序列模型和注意力机制’
id: dl-ai-5-3h
tags:
- dl.ai
- homework
categories: - AI
- Deep Learning
date: 2018-10-18 18:39:15

这周作业分为了两部分:
- 机器翻译
- 触发关键字
Part1:机器翻译
你将建立一个将人类可读日期(“2009年6月25日”)转换为机器可读日期(“2009-06-25”)的神经机器翻译(NMT)模型。 你将使用注意力机制来执行此操作,这是模型序列中最尖端的一个序列。
你将创建的模型可用于从一种语言翻译为另一种语言,如从英语翻译为印地安语。 但是,语言翻译需要大量的数据集,并且通常需要几天的GPU训练。 在不使用海量数据的情况下,为了让你有机会尝试使用这些模型,我们使用更简单的“日期转换”任务。
网络以各种可能格式(例如“1958年8月29日”,“03/30/1968”,“1987年6月24日”)写成的日期作为输入,并将它们转换成标准化的机器可读的日期(例如“1958 -08-29“,”1968-03-30“,”1987-06-24“),让网络学习以通用机器可读格式YYYY-MM-DD输出日期。
- X: 经过处理的训练集中人类可读日期,其中每个字符都替换为其在human_vocab中映射到的索引。 每个日期用特殊字符进一步填充为Tx长度。 X.shape =(m,Tx)
- Y: 经过处理的训练集中机器可读日期,其中每个字符都替换为其在machine_vocab中映射到的索引。 你应该有Y.shape =(m,Ty)。
- Xoh:X的one-hot向量,Xoh.shape = (m,Tx,len(human_vocab))
- Yoh:Y的one-hot向量,Yoh.shape = (m,Tx,len(machine_vocab))
采用注意力机制的机器翻译
定义一些layers
# Defined shared layers as global variables
repeator = RepeatVector(Tx)
concatenator = Concatenate(axis=-1)
densor1 = Dense(10, activation = "tanh")
densor2 = Dense(1, activation = "relu")
activator = Activation(softmax, name='attention_weights') # We are using a custom softmax(axis = 1) loaded in this notebook
dotor = Dot(axes = 1)
然后根据a 和 s 得到context
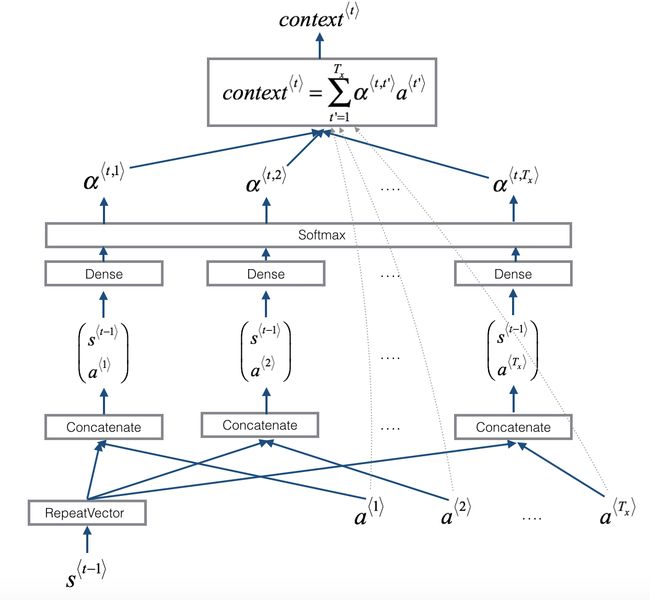
# GRADED FUNCTION: one_step_attention
def one_step_attention(a, s_prev):
"""
Performs one step of attention: Outputs a context vector computed as a dot product of the attention weights
"alphas" and the hidden states "a" of the Bi-LSTM.
Arguments:
a -- hidden state output of the Bi-LSTM, numpy-array of shape (m, Tx, 2*n_a)
s_prev -- previous hidden state of the (post-attention) LSTM, numpy-array of shape (m, n_s)
Returns:
context -- context vector, input of the next (post-attetion) LSTM cell
"""
### START CODE HERE ###
# Use repeator to repeat s_prev to be of shape (m, Tx, n_s) so that you can concatenate it with all hidden states "a" (≈ 1 line)
s_prev = repeator(s_prev)
# Use concatenator to concatenate a and s_prev on the last axis (≈ 1 line)
concat = concatenator([a, s_prev])
# Use densor1 to propagate concat through a small fully-connected neural network to compute the "intermediate energies" variable e. (≈1 lines)
e = densor1(concat)
# Use densor2 to propagate e through a small fully-connected neural network to compute the "energies" variable energies. (≈1 lines)
energies = densor2(e)
# Use "activator" on "energies" to compute the attention weights "alphas" (≈ 1 line)
alphas = activator(energies)
# Use dotor together with "alphas" and "a" to compute the context vector to be given to the next (post-attention) LSTM-cell (≈ 1 line)
context = dotor([alphas, a])
### END CODE HERE ###
return context
实现model()

n_a = 32
n_s = 64
post_activation_LSTM_cell = LSTM(n_s, return_state = True)
output_layer = Dense(len(machine_vocab), activation=softmax)
# GRADED FUNCTION: model
def model(Tx, Ty, n_a, n_s, human_vocab_size, machine_vocab_size):
"""
Arguments:
Tx -- length of the input sequence
Ty -- length of the output sequence
n_a -- hidden state size of the Bi-LSTM
n_s -- hidden state size of the post-attention LSTM
human_vocab_size -- size of the python dictionary "human_vocab"
machine_vocab_size -- size of the python dictionary "machine_vocab"
Returns:
model -- Keras model instance
"""
# Define the inputs of your model with a shape (Tx,)
# Define s0 and c0, initial hidden state for the decoder LSTM of shape (n_s,)
X = Input(shape=(Tx, human_vocab_size))
s0 = Input(shape=(n_s,), name='s0')
c0 = Input(shape=(n_s,), name='c0')
s = s0
c = c0
# Initialize empty list of outputs
outputs = []
### START CODE HERE ###
# Step 1: Define your pre-attention Bi-LSTM. Remember to use return_sequences=True. (≈ 1 line)
a = Bidirectional(LSTM(n_a, return_sequences=True))(X)
# Step 2: Iterate for Ty steps
for t in range(Ty):
# Step 2.A: Perform one step of the attention mechanism to get back the context vector at step t (≈ 1 line)
context = one_step_attention(a ,s)
# Step 2.B: Apply the post-attention LSTM cell to the "context" vector.
# Don't forget to pass: initial_state = [hidden state, cell state] (≈ 1 line)
s, _, c = post_activation_LSTM_cell(context, initial_state=[s, c])
# Step 2.C: Apply Dense layer to the hidden state output of the post-attention LSTM (≈ 1 line)
out = output_layer(s)
# Step 2.D: Append "out" to the "outputs" list (≈ 1 line)
outputs.append(out)
# Step 3: Create model instance taking three inputs and returning the list of outputs. (≈ 1 line)
model = Model(inputs=[X,s0,c0], outputs=outputs)
### END CODE HERE ###
return model
Part2:Trigger Word Detection
做触发关键字的检测。
X: 这里把每一段音频分为了10s,而10s内细分为了5511个小的片段,也就是Tx = 5511
Y: Ty = 1375,每个y都是一个布尔值,用来记录有没有收到触发关键字。
生成一个训练示例
这里把样本分为了三种,背景音乐,正向的音频,反向的音频,合成训练示例:
- 随机选择一个10秒的背景音频剪辑
- 随机将0-4个正向音频片段插入此10秒剪辑中
- 随机将0-2个反向音频片段插入此10秒剪辑中
合成后类似这样:

定义一个随机插入片段起始和终点位置的函数:
def get_random_time_segment(segment_ms):
"""
Gets a random time segment of duration segment_ms in a 10,000 ms audio clip.
Arguments:
segment_ms -- the duration of the audio clip in ms ("ms" stands for "milliseconds")
Returns:
segment_time -- a tuple of (segment_start, segment_end) in ms
"""
segment_start = np.random.randint(low=0, high=10000-segment_ms) # Make sure segment doesn't run past the 10sec background
segment_end = segment_start + segment_ms - 1
return (segment_start, segment_end)
然后需要判断在别的片段插入的时候,有没有被占用:
# GRADED FUNCTION: is_overlapping
def is_overlapping(segment_time, previous_segments):
"""
Checks if the time of a segment overlaps with the times of existing segments.
Arguments:
segment_time -- a tuple of (segment_start, segment_end) for the new segment
previous_segments -- a list of tuples of (segment_start, segment_end) for the existing segments
Returns:
True if the time segment overlaps with any of the existing segments, False otherwise
"""
segment_start, segment_end = segment_time
### START CODE HERE ### (≈ 4 line)
# Step 1: Initialize overlap as a "False" flag. (≈ 1 line)
overlap = False
# Step 2: loop over the previous_segments start and end times.
# Compare start/end times and set the flag to True if there is an overlap (≈ 3 lines)
for previous_start, previous_end in previous_segments:
if segment_start <= previous_end and segment_end >= previous_start:
overlap = True
### END CODE HERE ###
return overlap
生成input音频片段:
# GRADED FUNCTION: insert_audio_clip
def insert_audio_clip(background, audio_clip, previous_segments):
"""
Insert a new audio segment over the background noise at a random time step, ensuring that the
audio segment does not overlap with existing segments.
Arguments:
background -- a 10 second background audio recording.
audio_clip -- the audio clip to be inserted/overlaid.
previous_segments -- times where audio segments have already been placed
Returns:
new_background -- the updated background audio
"""
# Get the duration of the audio clip in ms
segment_ms = len(audio_clip)
### START CODE HERE ###
# Step 1: Use one of the helper functions to pick a random time segment onto which to insert
# the new audio clip. (≈ 1 line)
segment_time = get_random_time_segment(segment_ms)
# Step 2: Check if the new segment_time overlaps with one of the previous_segments. If so, keep
# picking new segment_time at random until it doesn't overlap. (≈ 2 lines)
while is_overlapping(segment_time,previous_segments):
segment_time = get_random_time_segment(segment_ms)
# Step 3: Add the new segment_time to the list of previous_segments (≈ 1 line)
previous_segments.append(segment_time)
### END CODE HERE ###
# Step 4: Superpose audio segment and background
new_background = background.overlay(audio_clip, position = segment_time[0])
return new_background, segment_time
生成y标签:
# GRADED FUNCTION: insert_ones
def insert_ones(y, segment_end_ms):
"""
Update the label vector y. The labels of the 50 output steps strictly after the end of the segment
should be set to 1. By strictly we mean that the label of segment_end_y should be 0 while, the
50 followinf labels should be ones.
Arguments:
y -- numpy array of shape (1, Ty), the labels of the training example
segment_end_ms -- the end time of the segment in ms
Returns:
y -- updated labels
"""
# duration of the background (in terms of spectrogram time-steps)
segment_end_y = int(segment_end_ms * Ty / 10000.0)
# Add 1 to the correct index in the background label (y)
### START CODE HERE ### (≈ 3 lines)
for i in range(segment_end_y+1, segment_end_y+51):
if i < Ty:
y[0, i] = 1
### END CODE HERE ###
return y
# GRADED FUNCTION: create_training_example
def create_training_example(background, activates, negatives):
"""
Creates a training example with a given background, activates, and negatives.
Arguments:
background -- a 10 second background audio recording
activates -- a list of audio segments of the word "activate"
negatives -- a list of audio segments of random words that are not "activate"
Returns:
x -- the spectrogram of the training example
y -- the label at each time step of the spectrogram
"""
# Set the random seed
np.random.seed(18)
# Make background quieter
background = background - 20
### START CODE HERE ###
# Step 1: Initialize y (label vector) of zeros (≈ 1 line)
y = np.zeros((1, Ty))
# Step 2: Initialize segment times as empty list (≈ 1 line)
previous_segments = []
### END CODE HERE ###
# Select 0-4 random "activate" audio clips from the entire list of "activates" recordings
number_of_activates = np.random.randint(0, 5)
random_indices = np.random.randint(len(activates), size=number_of_activates)
random_activates = [activates[i] for i in random_indices]
### START CODE HERE ### (≈ 3 lines)
# Step 3: Loop over randomly selected "activate" clips and insert in background
for random_activate in random_activates:
# Insert the audio clip on the background
background, segment_time = insert_audio_clip(background, random_activate, previous_segments)
# Retrieve segment_start and segment_end from segment_time
segment_start, segment_end = segment_time
# Insert labels in "y"
y = insert_ones(y, segment_end)
### END CODE HERE ###
# Select 0-2 random negatives audio recordings from the entire list of "negatives" recordings
number_of_negatives = np.random.randint(0, 3)
random_indices = np.random.randint(len(negatives), size=number_of_negatives)
random_negatives = [negatives[i] for i in random_indices]
### START CODE HERE ### (≈ 2 lines)
# Step 4: Loop over randomly selected negative clips and insert in background
for random_negative in random_negatives:
# Insert the audio clip on the background
background, _ = insert_audio_clip(background, random_negative, previous_segments)
### END CODE HERE ###
# Standardize the volume of the audio clip
background = match_target_amplitude(background, -20.0)
# Export new training example
file_handle = background.export("train" + ".wav", format="wav")
print("File (train.wav) was saved in your directory.")
# Get and plot spectrogram of the new recording (background with superposition of positive and negatives)
x = graph_spectrogram("train.wav")
return x, y
实现model()

# GRADED FUNCTION: model
def model(input_shape):
"""
Function creating the model's graph in Keras.
Argument:
input_shape -- shape of the model's input data (using Keras conventions)
Returns:
model -- Keras model instance
"""
X_input = Input(shape = input_shape)
### START CODE HERE ###
# Step 1: CONV layer (≈4 lines)
X = Conv1D(filters=196,kernel_size=15,strides=4)(X_input) # CONV1D
X = BatchNormalization()(X) # Batch normalization
X = Activation('relu')(X) # ReLu activation
X = Dropout(0.8)(X) # dropout (use 0.8)
# Step 2: First GRU Layer (≈4 lines)
X = GRU(units = 128, return_sequences = True)(X) # GRU (use 128 units and return the sequences)
X = Dropout(0.8)(X) # dropout (use 0.8)
X = BatchNormalization()(X) # Batch normalization
# Step 3: Second GRU Layer (≈4 lines)
X = GRU(units = 128, return_sequences = True)(X) # GRU (use 128 units and return the sequences)
X = Dropout(0.8)(X) # dropout (use 0.8)
X = BatchNormalization()(X) # Batch normalization
X = Dropout(0.8)(X) # dropout (use 0.8)
# Step 4: Time-distributed dense layer (≈1 line)
X = TimeDistributed(Dense(1, activation = "sigmoid"))(X) # time distributed (sigmoid)
### END CODE HERE ###
model = Model(inputs = X_input, outputs = X)
return model
这里载入预训练好的模型,不需要自己训练那么久了,
model = load_model('./models/tr_model.h5')
opt = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, decay=0.01)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=["accuracy"])
model.fit(X, Y, batch_size = 5, epochs=1)