R语言文本分析入门
1.
文本挖掘概述
文本挖掘是指从文本中提取有用的信息。成功应用主要有如下几方面:信息检索、内容管理、市场监测、市场分析等方面。文本挖掘被描述为 “自动化或半自动化处理文本的过程”,包含了文档聚类、文档分类、自然语言处理、文体变化分析及网络挖掘等领域内容。对于文本处理过程首先要拥有分析的语料,比如报告、信函、出版物等。而后根据这些语料建立半结构化的文本库。而后生成包含词频的结构化的词条-文档矩阵。
2. R语言实现过程
本文以R语言为例,介绍文本挖掘的实现过程,内容浅显易懂。
#step0:加载文本挖掘所需包
#关于包的信息,可通过命令“?包名”查询,在此不再赘述
#加载包如果不成功,可将包下载到本地,尝试本地安装:程序包->从本地zip文件安装程序包。若是再不成功,可能存在包不兼容问题,需要更换包。
library(tm);
library(rJava);
library(Rwordseg);
library (RColorBrewer);
library(wordcloud);
library(tmcn);
#### step2:读取文本 #############
long = readLines("tmp.txt");

#### step3:分词 ################
long.seg = unlist(lapply(X = long,FUN = segmentCN));

#### step4:计算词频 #############
long.freq = getWordFreq(string = unlist(long.seg))

#### step5:绘制词云图用RColorBrewer包中的brewer.pal来选择适合的调色板:
wordcloud(long.seg);
注:由于样例数据比较少,词云图比较稀疏,不过足以说明问题。

采用调色板绘制词云图:
mypalette<-brewer.pal(7,"Greens");#### 定制调色板
wordcloud(long.seg,col=mypalette)

#### step5:词典新增词汇。为了分词的准确性,有时需要自定义词典 ####
新增词汇前:
segmentCN("生产管理系统测试应用服务器")

新增词汇后:
insertWords(c("生产管理系统测试应用服务器"))

2.2 数据库长文本分析过程
数据实例:
select alertid,message from scott.t_alerms where rownum<=10;
library(RODBC);
##### step1:建立数据库连接 ###########
channel=odbcConnect("my_orcl",uid="scott",pwd="tiger"); #连接配置好的数据库
##### step2:浏览表,读取记录 ###########
odbcQuery (channel, "select alertid,message from scott.t_alerms")
alerms.record=sqlGetResults(channel, as.is=FALSE, errors=FALSE, max=5)
message1=alerms.record$MESSAGE; ### 读取MESSAGE动作信息
message=gsub("zabbix2.2.2","",gsub(":"," ", message1));#去除“: ”
message
#### step3:加载文本挖掘所需包 ##########
library(tm);
#install.packages("rJava")
library(rJava);
library(Rwordseg);
#install.packages('RColorBrewer', depend=TRUE)
library(RColorBrewer);
library(wordcloud);
library(tmcn);
#### step4:安装自定义词典 #############
#安装自定义txt词典
installDict(dictpath="D:\\Program Files\\R-Dictionary\\dict.txt",
dictname="dict",
dicttype = "text", load = TRUE);
#安装搜狗自定义词典
#installDict(dictpath="D:\\Program Files\\R-Dictionary\\计算机词汇大全.scel",
dictname="计算机",
dicttype="scel")
#### step5:分词 ################
#含标点符号分词,返回列表
message.seg1=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = FALSE,
returnType = c("tm"), isfast = FALSE,
outfile = "", blocklines = 1000);##"vector"
message.seg1
#含标点符号分词,返回向量
message.seg2=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = FALSE,
returnType = c("vector"), isfast = FALSE,
outfile = "", blocklines = 1000);
message.seg2
# 不含标点符号分词,返回列表
message.seg3=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = TRUE,
returnType = c("tm"), isfast = FALSE,
outfile = "", blocklines = 1000);
message.seg3
# 不含标点符号分词,返回向量
message.seg4=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = TRUE,
returnType = c("vector"), isfast = FALSE,
outfile = "", blocklines = 1000);
#保存结果至txt文本
write.table(message.seg1,"message01.txt")
write.table(message.seg2,"message02.txt")
#保存结果至oracle数据库
sqlSave(channel, as.data.frame(message.seg1), rownames = "State", verbose = TRUE)
#### step8:绘制词云图,用brewer.pal来选择适合的调色板:
wordcloud(message.seg3);
mypalette=brewer.pal(7,"Greens")
wordcloud(message.seg3,col=mypalette)
#### step9:关闭数据库连接 #######
close(channel); ## 关闭数据库连接
####
文本挖掘是指从文本中提取有用的信息。成功应用主要有如下几方面:信息检索、内容管理、市场监测、市场分析等方面。文本挖掘被描述为 “自动化或半自动化处理文本的过程”,包含了文档聚类、文档分类、自然语言处理、文体变化分析及网络挖掘等领域内容。对于文本处理过程首先要拥有分析的语料,比如报告、信函、出版物等。而后根据这些语料建立半结构化的文本库。而后生成包含词频的结构化的词条-文档矩阵。
2. R语言实现过程
本文以R语言为例,介绍文本挖掘的实现过程,内容浅显易懂。
R语言版本:3.2.4 (可从官网https://www.r-project.org/下载,我选择的链接是https://mirrors.tuna.tsinghua.edu.cn/CRAN/)。
2.1
文本文件分析过程
数据实例:tmp.txt(文档记录了少量服务器告警动作信息)。

#step0:加载文本挖掘所需包
#关于包的信息,可通过命令“?包名”查询,在此不再赘述
#加载包如果不成功,可将包下载到本地,尝试本地安装:程序包->从本地zip文件安装程序包。若是再不成功,可能存在包不兼容问题,需要更换包。
library(tm);
library(rJava);
library(Rwordseg);
library (RColorBrewer);
library(wordcloud);
library(tmcn);
#### step2:读取文本 #############
long = readLines("tmp.txt");
#### step3:分词 ################
long.seg = unlist(lapply(X = long,FUN = segmentCN));
#### step4:计算词频 #############
long.freq = getWordFreq(string = unlist(long.seg))
#### step5:绘制词云图用RColorBrewer包中的brewer.pal来选择适合的调色板:
wordcloud(long.seg);
注:由于样例数据比较少,词云图比较稀疏,不过足以说明问题。
采用调色板绘制词云图:
mypalette<-brewer.pal(7,"Greens");#### 定制调色板
wordcloud(long.seg,col=mypalette)
#### step5:词典新增词汇。为了分词的准确性,有时需要自定义词典 ####
新增词汇前:
segmentCN("生产管理系统测试应用服务器")
新增词汇后:
insertWords(c("生产管理系统测试应用服务器"))
2.2 数据库长文本分析过程
数据实例:
select alertid,message from scott.t_alerms where rownum<=10;
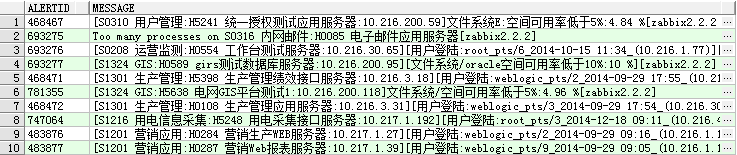
##### step0:加载包RODBC ############
#install.packages("RODBC");library(RODBC);
##### step1:建立数据库连接 ###########
channel=odbcConnect("my_orcl",uid="scott",pwd="tiger"); #连接配置好的数据库
##### step2:浏览表,读取记录 ###########
odbcQuery (channel, "select alertid,message from scott.t_alerms")
alerms.record=sqlGetResults(channel, as.is=FALSE, errors=FALSE, max=5)
message1=alerms.record$MESSAGE; ### 读取MESSAGE动作信息
message=gsub("zabbix2.2.2","",gsub(":"," ", message1));#去除“: ”
message
#### step3:加载文本挖掘所需包 ##########
library(tm);
#install.packages("rJava")
library(rJava);
library(Rwordseg);
#install.packages('RColorBrewer', depend=TRUE)
library(RColorBrewer);
library(wordcloud);
library(tmcn);
#### step4:安装自定义词典 #############
#安装自定义txt词典
installDict(dictpath="D:\\Program Files\\R-Dictionary\\dict.txt",
dictname="dict",
dicttype = "text", load = TRUE);
#安装搜狗自定义词典
#installDict(dictpath="D:\\Program Files\\R-Dictionary\\计算机词汇大全.scel",
dictname="计算机",
dicttype="scel")
#### step5:分词 ################
#含标点符号分词,返回列表
message.seg1=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = FALSE,
returnType = c("tm"), isfast = FALSE,
outfile = "", blocklines = 1000);##"vector"
message.seg1
#含标点符号分词,返回向量
message.seg2=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = FALSE,
returnType = c("vector"), isfast = FALSE,
outfile = "", blocklines = 1000);
message.seg2
# 不含标点符号分词,返回列表
message.seg3=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = TRUE,
returnType = c("tm"), isfast = FALSE,
outfile = "", blocklines = 1000);
message.seg3
# 不含标点符号分词,返回向量
message.seg4=segmentCN(message,
analyzer = get("Analyzer", envir = .RwordsegEnv),
nature = FALSE, nosymbol = TRUE,
returnType = c("vector"), isfast = FALSE,
outfile = "", blocklines = 1000);
message.seg4
#### step6:保存结果 ##############
#保存结果至txt文本
write.table(message.seg1,"message01.txt")
write.table(message.seg2,"message02.txt")
#保存结果至oracle数据库
sqlSave(channel, as.data.frame(message.seg1), rownames = "State", verbose = TRUE)
注:每行分词个数不一样多,会导致数据写入数据库报错。
#### step7:计算词频 #############
message.freq = getWordFreq(string = unlist(message.seg4));
#### step8:绘制词云图,用brewer.pal来选择适合的调色板:
wordcloud(message.seg3);
mypalette=brewer.pal(7,"Greens")
wordcloud(message.seg3,col=mypalette)
#### step9:关闭数据库连接 #######
close(channel); ## 关闭数据库连接
####