MobileNet V2论文阅读和代码解析
目录
论文阅读
代码解析
小结
论文阅读
1.前言
神经网络在机器智能的很多领域都有革命性的改进,在图像识别的领域精确度已经能够超过人类。然而,为了提高精确度常常会带来消耗,需要更高的计算资源,是很多手机和嵌入式设备所不具有的。这篇文章介绍了一个新神经网络结构,是专门为手机和资源有限的环境量身定制的。我们的网络通过减少计算次数和内存占用,推进了为移动设备量身定制的计算机视觉模型达到一个更先进的水平。
我们主要的贡献是具有线性瓶颈的倒置残差。这个模型对输入的低维度的表现先扩展到高维度,然后进行轻量级depthwise卷积运算,特征再进行一个线性的卷积回到低维度的表现。
2.细节讨论
2.1Depthwise Separable Convolutions
深度分离卷积块对很多高效的网络结构都是很关键的,在本篇论文的模型中也使用了这种结构。用分解成两层的卷积来替代原始的卷积。分解后的两层第一层叫做depthwise卷积,它的filter的参数很少,是对输入的每一个channel进行单独的卷积运算。第二层是一个1x1的卷积,叫做pointwise卷积,可以改变channel的个数。
对于标准的卷积运算,假设输入是![]() ,卷积kernel
,卷积kernel![]() ,输出为
,输出为![]() ,那么需要消耗的计算量为
,那么需要消耗的计算量为![]() ,而如果是Depthwise separable卷积,需要的计算量为
,而如果是Depthwise separable卷积,需要的计算量为
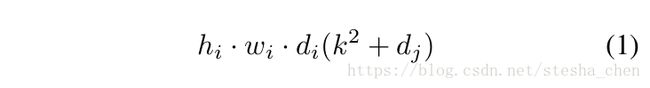
如果标准卷积的k为3,那么用depthwise可以减少接近8/9的计算量而只会有些微的精度损失。
2.2 Linear Bottlenecks
当channel的个数比较少的时候,所有的信息都集中在比较窄的channel中,这这时候进行非线性激活比如RELU,会丢失很多信息。而在MobileNet V1中引入的一个超参数width multiplier会缩减channel,这样看起来就像一个瓶子的颈部一样。这种情况下用RELU激活机会丢失掉不少信息。

上图是作者展示用RELU激活时,当channel越小,丢失的信息越多,当channel越大,丢失的信息越少。其实不难理解,当channel为2时,信息都集中在这两个channel中,如果有部分数值小于0就会被RELU激活丢失掉。而如果channel为30,其实信息是分散的,而且具有了冗余,所以通过RELU激活后归于0的值可能并不会影响太多信息的存储。
所以作者建议对于channel数很少的那些层做线性激活。bottlenect就表示缩减的层,linear bottleneck表示对channel缩减的层做线性激活。如果要用RELU激活需要先增加channel数再做RELU激活。
2.3 Inverted residuals
因为channel比较少的tensor信息特别集中,而且使用非线性激活会损失信息,所以作者想到对channel比较少的tensor进行channel的扩张。而残差block是先进行channel缩减,然后扩张,这样可能会丢失信息。作者就想到了一种倒置的残差block,先进行channel扩张,然后进行channel缩减。如下图显示对比,虚线的tensor后进行线性激活,这种倒置残差block是作者对残差block提出的一个改进。
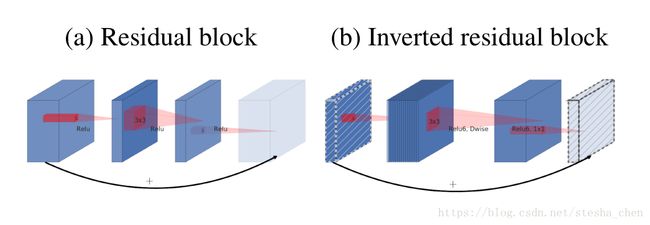
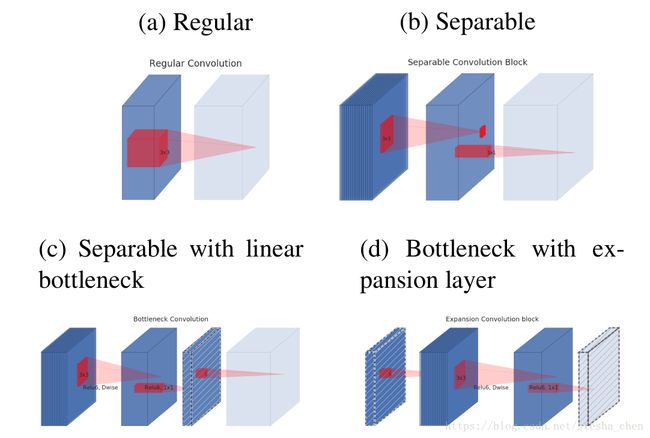
上面这张图是作者展示的各种结构的对比,a是普通卷积,b是深度分离卷积,c是有bottlenect的分离卷积,d是对bottlenect进行扩张后的分离卷积。同样所有虚线的tensor后面都是线性激活。d的结构和导致残差结构就是有无shorcut连接的差别。

如上图,进行channel扩张后分离卷积的步骤由两步变成了三步,第一步就是将channel k扩张为tk,后面两步就是正常的深度分离卷积。
2.4模型结构
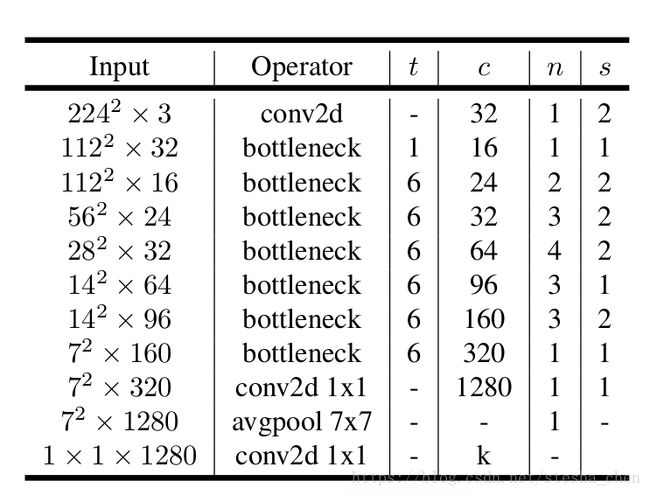
上面的表格就是网络结构,t列表示expansion的比例,比如input channel为16,需要output channel为24,中间扩张的channel为16*6=96。c列表示output的channel。n表示重复几次,s表示stride。当重复n次时,第一次重复时s为图表中的数值,后面n-1次重复时s为1。所有的kernel为3x3。
另外作者提出所有非线性激活都用RELU6,RELU6=min(max(features, 0), 6),作者认为这个激活函数会更加优秀,能保留更多的信息。
代码阅读
mobilenet_v2.py
代码的实现和mobilenet_v1非常类似,都是将网络结构列在一个dict中,后面在代码中依次取出dict中的网络来逐步实现。
1.V2_DEF
V2_DEF有两部分内容,第一部分的default是为expanded_conv,separable_conv2d等设置默认值。第二部分就是根据论文中的网络模型而列出的网络结构,这里面已经把论文图表中的循环拆开了,比如n=3,就写成三行。
V2_DEF = dict(
defaults={
# Note: these parameters of batch norm affect the architecture
# that's why they are here and not in training_scope.
(slim.batch_norm,): {'center': True, 'scale': True},
(slim.conv2d, slim.fully_connected, slim.separable_conv2d): {
'normalizer_fn': slim.batch_norm, 'activation_fn': tf.nn.relu6
},
(ops.expanded_conv,): {
'expansion_size': expand_input(6),
'split_expansion': 1,
'normalizer_fn': slim.batch_norm,
'residual': True
},
(slim.conv2d, slim.separable_conv2d): {'padding': 'SAME'}
},
spec=[
op(slim.conv2d, stride=2, num_outputs=32, kernel_size=[3, 3]),
op(ops.expanded_conv,
expansion_size=expand_input(1, divisible_by=1),
num_outputs=16),
op(ops.expanded_conv, stride=2, num_outputs=24),
op(ops.expanded_conv, stride=1, num_outputs=24),
op(ops.expanded_conv, stride=2, num_outputs=32),
op(ops.expanded_conv, stride=1, num_outputs=32),
op(ops.expanded_conv, stride=1, num_outputs=32),
op(ops.expanded_conv, stride=2, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=64),
op(ops.expanded_conv, stride=1, num_outputs=96),
op(ops.expanded_conv, stride=1, num_outputs=96),
op(ops.expanded_conv, stride=1, num_outputs=96),
op(ops.expanded_conv, stride=2, num_outputs=160),
op(ops.expanded_conv, stride=1, num_outputs=160),
op(ops.expanded_conv, stride=1, num_outputs=160),
op(ops.expanded_conv, stride=1, num_outputs=320),
op(slim.conv2d, stride=1, kernel_size=[1, 1], num_outputs=1280)
],
)并且op的实现如下,实际上返回的是一个有名字的数组_Op,里面有三个参数,一个op,一个params,一个multiplier_func,如果用户没有设定multiplier_transorm,那么multiplier_func默认就是depth_multiplier函数。
@slim.add_arg_scope
def depth_multiplier(output_params,
multiplier,
divisible_by=8,
min_depth=8,
**unused_kwargs):
if 'num_outputs' not in output_params:
return
d = output_params['num_outputs']
output_params['num_outputs'] = _make_divisible(d * multiplier, divisible_by,
min_depth)
_Op = collections.namedtuple('Op', ['op', 'params', 'multiplier_func'])
def op(opfunc, **params):
multiplier = params.pop('multiplier_transorm', depth_multiplier)
return _Op(opfunc, params=params, multiplier_func=multiplier)2.mobilenet
这个函数主要是做一个准备工作比如conv_defs = V2_DEF,然后调用了lib.mobilenet
with slim.arg_scope((lib.depth_multiplier,), **depth_args):
return lib.mobilenet(
input_tensor,
num_classes=num_classes,
conv_defs=conv_defs,
scope=scope,
multiplier=depth_multiplier,
**kwargs)3.lib.mobilenet
这个函数的实现在mobilenet.py中
#先调用mobilenet_base来搭建主要的网络
net, end_points = mobilenet_base(inputs, scope=scope, **mobilenet_args)
#然后实现了网络结构中的最后一行
#dropout
net = slim.dropout(net, scope='Dropout', is_training=is_training)
#1x1 conv,生成1 x 1 x num_classes
logits = slim.conv2d(
net,
num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
biases_initializer=tf.zeros_initializer(),
scope='Conv2d_1c_1x1')
#softmax
end_points['Predictions'] = prediction_fn(logits, 'Predictions')4.mobilenet_base
网络结构的主体实现都在这个函数中,会根据V2_DEF中的配置在搭建网络。
第一步
conv_defs就是V2_DEF,取出defaults和overrides。overrides我想是让用户可以进行自定义设置的。
conv_defs_defaults = conv_defs.get('defaults', {})
conv_defs_overrides = conv_defs.get('overrides', {})第二步
调用了_set_arg_scope_defaults(conv_defs_defaults),这个函数是将defaults中的默认配置都应用到卷积运算上。
_set_arg_scope_defaults(conv_defs_defaults)经过这个操作后,在不改变defaults信息的情况下,有以下默认值
with slim.arg_scope(slim.batch_norm, center=True, scale=True):
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.separable_conv2d], normalizer_fn=slim.batch_norm, activation_fn=tf.nn.relu6):
with slim.arg_scope(ops.expanded_conv, expansion_size=expand_input(6), split_expansion=1, normalizer_fn=slim.batch_norm, residual=True):
with slim.arg_scope([slim.conv2d, slim.separable_conv2d], padding=SAME):第三步
通过循环取出V2_DEF中spec部分的网络结构
for i, opdef in enumerate(conv_defs['spec']):
params = dict(opdef.params)
#调用depth_multiplier将output_params['num_outputs']做修正,其实就是要保证output的channel可以被8整除,因为我们后面会有4次stride为2
opdef.multiplier_func(params, multiplier)
stride = params.get('stride', 1)
try:
#调用表格中的卷积计算,ops.expanded_conv
net = opdef.op(net, **params)
except Exception:
print('Failed to create op %i: %r params: %r' % (i, opdef, params))
raise关键点是调用了ops.expanded_conv,而这个函数的实现在conv_blocks.py中
5.expanded_conv
这个函数是这个网络结构的核心,实现了论文中Inverted residuals的结构。在传入的参数中depthwise_location可能有三种值'input', 'output', 'expansion',这三种值关系到调用的位置实在输入的时候,还在expansion的时候,还是输出的时候,这里面以depthwise_location='expansion'为例子来看流程。
第一步
将slim.separable_conv2d函数以及后面的一系列参数简化成depthwise_func形式,后面如果调用depthwise_func就是调用slim.separable_conv2d以及这一系列的参数。但是需要注意的是num_outputs=None,所以这个函数会跳过后面的pointwise卷积
depthwise_func = functools.partial(
slim.separable_conv2d,
num_outputs=None,
kernel_size=kernel_size,
depth_multiplier=depthwise_channel_multiplier,
stride=stride,
rate=rate,
normalizer_fn=normalizer_fn,
padding=padding,
scope='depthwise')第二步
inner_size是expansion的尺寸,是前面用6与输入的channel相乘得到的,所以下面这个判断条件成立,split_conv函数就是做expansion。
在split_conv中的实现其实就是调用了conv2d进行channel扩张
return slim.conv2d(input_tensor, num_outputs, [1, 1], scope=scope, **kwargs)
if inner_size > net.shape[3]:
net = split_conv(
net,
inner_size,
num_ways=split_expansion,
scope='expand',
stride=1,
normalizer_fn=normalizer_fn)第三步
channel扩张之后调用slim.separable_conv2d
if depthwise_location == 'expansion':
if use_explicit_padding:
net = _fixed_padding(net, kernel_size, rate)
net = depthwise_func(net)第四步
因为前面slim.separable_conv2d跳过了pointwise的卷积,所以这里再进行一次卷积将channel运算成期待的output channel,我想把本来separable_conv2d可以一步完成的操作分成两步是因为channel缩减后要不能进行非线性激活。project_activation_fn=tf.identity,表示确实如论文中提出的使用的是线性激活函数。因为激活函数都是在先进行卷积运算后再运算激活函数,当卷积运算后channel已经比较窄了,所以激活函数用线性激活。
net = split_conv(
net,
num_outputs,
num_ways=split_projection,
stride=1,
scope='project',
normalizer_fn=normalizer_fn,
activation_fn=project_activation_fn)第五步
最后如果residual为true就进行tensor的相加
如果residual为true就是Inverted residual block,如果为false就是Bottleneck with expansion layer
elif (residual and
# stride check enforces that we don't add residuals when spatial
# dimensions are None
stride == 1 and
# Depth matches
net.get_shape().as_list()[3] ==
input_tensor.get_shape().as_list()[3]):
net += input_tensor
小结
MobilenetV2的提出就是因为作者发现如果channel很小的时候进行非线性激活会丢失很多信息,尤其是在MobileNetV1中channel数与depth multiplier相乘后channel会更小,导致准确率下降。所以想到先进行channel的扩张,再进行计算。可以在计算的过程中保留大量有效信息而提高准确率。
以上为本文的所有内容,感谢阅读,欢迎讨论。