- 想想蛮久没写了,这两天一直在弄pytorch直接转tensorRT的事情,考虑到部署设备的配置问题,这些加速还是得搞一搞
原来思路:
- 由于以为pytorch没有像tf一样集成tensorRT,准备转中间onnx,再有onnx转tensorRT
- 后来发现torch2trt这个包:传送门在此,于是对此做了一波尝试
安装
- 其实直接去看git上的README比较好,这里就给出插件版的安装命令
sudo apt-get install libprotobuf* protobuf-compiler ninja-build
git clone https://github.com/NVIDIA-AI-IOT/torch2trt
cd torch2trt
sudo python setup.py install --plugins
- 对于tensorRT的版本要求,如果你是linux or windows,5.1.x足以,如果是类似于Jetson Nano这种嵌入式,那么需要6.0,原因是太早版本的tensorRT不支持某些激活函数,或者别的什么层,用起来就是不方便,得自定义,而Jetson Nano这种开发板的系统架构是aarch,因此NVIDIA专门开了一个给这种架构用的版本,而5版本是没有Leaky_Relu 这个激活函数的:我的解决办法是更新
- 其余的根据提示安装就好
转换实现
- 具体代码实现是这位大佬的:git地址
- 瞅一眼他的README就清楚大致流程了
git clone https://github.com/DocF/YOLOv3-Torch2TRT.git
- 这个部分要求下载权重文件,这里我们可以用我们自己的训练出来的权重文件,当然相应的cfg得放到config里面
- check.py测试你的torch2trt是否正常,一般来说没啥问题
- detect.py就是我们要运行的代码了
这里面需要我们修改的地方如下
- 首先paser这边,是不用多说的,只是他好像没用用到
checkpoint_model这一项,所以,我们的自定义模型需要加载在weights_path中,其他部分按需修改
parser = argparse.ArgumentParser()
parser.add_argument("--image_folder", type=str, default="data/samples/", help="path to dataset")
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
parser.add_argument("--weights_path", type=str, default="weights/yolov3.weights", help="path to weights file")
parser.add_argument("--class_path", type=str, default="data/coco.names", help="path to class label file")
parser.add_argument("--conf_thres", type=float, default=0.8, help="object confidence threshold")
parser.add_argument("--nms_thres", type=float, default=0.4, help="iou thresshold for non-maximum suppression")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--n_cpu", type=int, default=0, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
parser.add_argument("--checkpoint_model", type=str, help="path to checkpoint model")
opt = parser.parse_args()
Speed_Test = True这句是测速,不用可以去掉,反正我是没有完整跑完过。- 下面这两项是代表是否用TensorRT加速,以及是否用半精度,需要提醒的是,这里有个小错误,如果Half=true,则下方的
input_imgs也要改成半精度的
TensorRT = True
Half = True
input_imgs = Variable(input_imgs.type(Tensor))
- 改完这些以及地址什么的,还有samples里面的测试图片(默认的可能不适合你),就可以跑了,以下是源代码
from __future__ import division
from models import *
from utils.utils import *
from utils.datasets import *
import os
import sys
import time
import datetime
import argparse
from PIL import Image
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.ticker import NullLocator
from torchstat import stat
from torch2trt import torch2trt
def Speed(TensorRT, Half):
if Half:
test_data = torch.rand(size=(1000, 1, 3, opt.img_size, opt.img_size)).cuda().half()
else:
test_data = torch.rand(size=(1000, 1, 3, opt.img_size, opt.img_size)).cuda()
print("Start test speed")
if TensorRT:
start = time.time()
for i in range(test_data.size()[0]):
detections = model_backbone(test_data[i])
end = time.time()
if Half is False:
print("Fp32 Backbone Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
else:
print("Fp16 Backbone Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
start = time.time()
for i in range(test_data.size()[0]):
detections = model_trt(test_data[i])
end = time.time()
if Half is False:
print("Fp32 TensorRT Backbone Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
else:
print("Fp16 TensorRT Backbone Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
start = time.time()
for i in range(test_data.size()[0]):
detections = yolo_head(model_trt(test_data[i]))
detections = non_max_suppression(detections, opt.conf_thres, opt.nms_thres, method=1)
end = time.time()
if Half is False:
print("Fp32 TensorRT Model Detect Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
else:
print("Fp16 TensorRT Model Detect Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
else:
start = time.time()
for i in range(test_data.size()[0]):
detections = model(test_data[i])
detections = non_max_suppression(detections, opt.conf_thres, opt.nms_thres, method=1)
end = time.time()
if Half is False:
print("Fp32 Original Model Detect Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
else:
print("Fp16 Original Model Detect Speed:", 1 / (end - start) * test_data.size()[0], "Hz")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--image_folder", type=str, default="data/samples/", help="path to dataset")
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
parser.add_argument("--weights_path", type=str, default="weights/yolov3.weights", help="path to weights file")
parser.add_argument("--class_path", type=str, default="data/coco.names", help="path to class label file")
parser.add_argument("--conf_thres", type=float, default=0.8, help="object confidence threshold")
parser.add_argument("--nms_thres", type=float, default=0.4, help="iou thresshold for non-maximum suppression")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--n_cpu", type=int, default=0, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
parser.add_argument("--checkpoint_model", type=str, help="path to checkpoint model")
opt = parser.parse_args()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.makedirs("output", exist_ok=True)
Speed_Test = True
TensorRT = True
Half = True
if TensorRT is True:
if Half is True:
model_backbone = Darknet_Backbone(opt.model_def, img_size=opt.img_size).to(device).half()
else:
model_backbone = Darknet_Backbone(opt.model_def, img_size=opt.img_size).to(device)
if opt.weights_path.endswith(".weights"):
model_backbone.load_darknet_weights(opt.weights_path)
else:
model_backbone.load_state_dict(torch.load(opt.weights_path))
model_backbone.eval()
yolo_head = YOLOHead(config_path=opt.model_def)
if Half is True:
x = torch.rand(size=(1, 3, opt.img_size, opt.img_size)).cuda().half()
model_trt = torch2trt(model_backbone, [x], fp16_mode=True)
else:
x = torch.rand(size=(1, 3, opt.img_size, opt.img_size)).cuda()
model_trt = torch2trt(model_backbone, [x])
else:
if Half:
model = Darknet(opt.model_def, img_size=opt.img_size, TensorRT=False, Half=True).to(device).half()
else:
model = Darknet(opt.model_def, img_size=opt.img_size).to(device)
if opt.weights_path.endswith(".weights"):
model.load_darknet_weights(opt.weights_path)
else:
model.load_state_dict(torch.load(opt.weights_path))
model.eval()
if Speed_Test:
Speed(TensorRT, Half)
dataloader = DataLoader(
ImageFolder(opt.image_folder, img_size=opt.img_size),
batch_size=opt.batch_size,
shuffle=False,
num_workers=opt.n_cpu,
)
classes = load_classes(opt.class_path)
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
imgs = []
img_detections = []
print("\nPerforming object detection:")
prev_time = time.time()
for batch_i, (img_paths, input_imgs) in enumerate(dataloader):
input_imgs = Variable(input_imgs.type(Tensor))
with torch.no_grad():
if TensorRT:
detections = yolo_head(model_trt(input_imgs))
detections = non_max_suppression(detections, opt.conf_thres, opt.nms_thres, method=2)
else:
detections = model(input_imgs)
detections = non_max_suppression(detections, opt.conf_thres, opt.nms_thres, method=2)
current_time = time.time()
inference_time = datetime.timedelta(seconds=current_time - prev_time)
prev_time = current_time
print("\t+ Batch %d, Inference Time: %s" % (batch_i, inference_time))
imgs.extend(img_paths)
img_detections.extend(detections)
cmap = plt.get_cmap("tab20b")
colors = [cmap(i) for i in np.linspace(0, 1, 20)]
print("\nSaving images:")
for img_i, (path, detections) in enumerate(zip(imgs, img_detections)):
print("(%d) Image: '%s'" % (img_i, path))
img = np.array(Image.open(path))
plt.figure()
fig, ax = plt.subplots(1)
ax.imshow(img)
if detections is not None:
detections = rescale_boxes(detections, opt.img_size, img.shape[:2])
unique_labels = detections[:, -1].cpu().unique()
n_cls_preds = len(unique_labels)
bbox_colors = random.sample(colors, n_cls_preds)
for x1, y1, x2, y2, conf, cls_conf, cls_pred in detections:
print("\t+ Label: %s, Conf: %.5f" % (classes[int(cls_pred)], cls_conf.item()))
box_w = x2 - x1
box_h = y2 - y1
color = bbox_colors[int(np.where(unique_labels == int(cls_pred))[0])]
bbox = patches.Rectangle((x1, y1), box_w, box_h, linewidth=2, edgecolor=color, facecolor="none")
ax.add_patch(bbox)
plt.text(
x1,
y1,
s=classes[int(cls_pred)],
color="white",
verticalalignment="top",
bbox={"color": color, "pad": 0},
)
plt.axis("off")
plt.gca().xaxis.set_major_locator(NullLocator())
plt.gca().yaxis.set_major_locator(NullLocator())
filename = path.split("/")[-1].split(".")[0]
plt.savefig(f"output/{filename}.png", bbox_inches="tight", pad_inches=0.0)
plt.close()
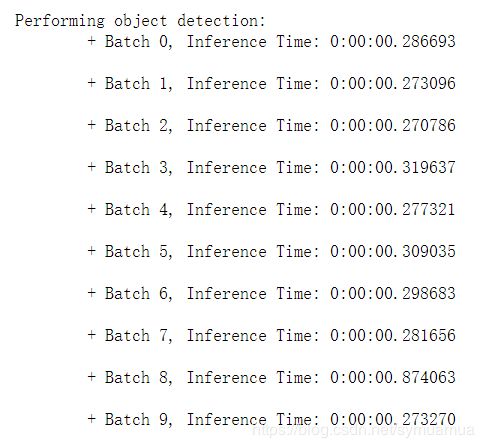
- 以下是在Jetson Nano上测试的数据,可以看到,接近4的FPS,相比之前的1FPS还是好了不少,故此可以判定tensorRT可以起作用
补充
- 经一位朋友提醒,speed 测试也需要改为False,那个是跑不通的,我的Nano确也没成功过,后来没想起来要改~