PythonNLP学习进阶:第二章练习题(Python自然语言处理)
python自然语言处理.2014年7月第一版课后习题练习
1.
>>> phrase=["Valentine's"]
>>> phrase=["lonely"]+phrase+["day"]
>>> phrase
['lonely', "Valentine's", 'day']
>>> phrase[1]
"Valentine's"
>>> phrase[1][1]
'a'
>>> phrase.index('day')
2
>>> sorted(phrase)
["Valentine's", 'day', 'lonely']
>>> phrase[1:2]
["Valentine's"]
>>> phrase*3
['lonely', "Valentine's", 'day', 'lonely', "Valentine's", 'day', 'lonely', "Valentine's", 'day']2.
>>> from nltk.corpus import gutenberg
>>> gutenberg.fileids()
[u'austen-emma.txt', u'austen-persuasion.txt', u'austen-sense.txt', u'bible-kjv.txt', u'blake-poems.txt', u'bryant-stories.txt', u'burgess-busterbrown.txt', u'carroll-alice.txt', u'chesterton-ball.txt', u'chesterton-brown.txt', u'chesterton-thursday.txt', u'edgeworth-parents.txt', u'melville-moby_dick.txt', u'milton-paradise.txt', u'shakespeare-caesar.txt', u'shakespeare-hamlet.txt', u'shakespeare-macbeth.txt', u'whitman-leaves.txt']
>>> persuasion=gutenberg.words('austen-persuasion.txt')
>>> len(persuasion)
98171
>>> len(set(persuasion))//词类型,我不知道是不是指有多少个不一样的词
6132
>>> from nltk.corpus import brown
>>> brown.categories()
[u'adventure', u'belles_lettres', u'editorial', u'fiction', u'government', u'hobbies', u'humor', u'learned', u'lore', u'mystery', u'news', u'religion', u'reviews', u'romance', u'science_fiction']
>>> brown.words(categories='lore')
[u'In', u'American', u'romance', u',', u'almost', ...]
>>> brown.words(categories='mystery')
[u'There', u'were', u'thirty-eight', u'patients', ...]
>>> from nltk.corpus import webtext
>>> webtext.fileids()
[u'firefox.txt', u'grail.txt', u'overheard.txt', u'pirates.txt', u'singles.txt', u'wine.txt']
>>> webtext.words('firefox.txt')
[u'Cookie', u'Manager', u':', u'"', u'Don', u"'", u't', ...]
>>> webtext.words('grail.txt')
[u'SCENE', u'1', u':', u'[', u'wind', u']', u'[', ...]4.
>>> from nltk.corpus import state_union as su
>>> su.fileids()
[u'1945-Truman.txt', u'1946-Truman.txt', u'1947-Truman.txt', u'1948-Truman.txt', u'1949-Truman.txt', u'1950-Truman.txt', u'1951-Truman.txt', u'1953-Eisenhower.txt', u'1954-Eisenhower.txt', u'1955-Eisenhower.txt', u'1956-Eisenhower.txt', u'1957-Eisenhower.txt', u'1958-Eisenhower.txt', u'1959-Eisenhower.txt', u'1960-Eisenhower.txt', u'1961-Kennedy.txt', u'1962-Kennedy.txt', u'1963-Johnson.txt', u'1963-Kennedy.txt', u'1964-Johnson.txt', u'1965-Johnson-1.txt', u'1965-Johnson-2.txt', u'1966-Johnson.txt', u'1967-Johnson.txt', u'1968-Johnson.txt', u'1969-Johnson.txt', u'1970-Nixon.txt', u'1971-Nixon.txt', u'1972-Nixon.txt', u'1973-Nixon.txt', u'1974-Nixon.txt', u'1975-Ford.txt', u'1976-Ford.txt', u'1977-Ford.txt', u'1978-Carter.txt', u'1979-Carter.txt', u'1980-Carter.txt', u'1981-Reagan.txt', u'1982-Reagan.txt', u'1983-Reagan.txt', u'1984-Reagan.txt', u'1985-Reagan.txt', u'1986-Reagan.txt', u'1987-Reagan.txt', u'1988-Reagan.txt', u'1989-Bush.txt', u'1990-Bush.txt', u'1991-Bush-1.txt', u'1991-Bush-2.txt', u'1992-Bush.txt', u'1993-Clinton.txt', u'1994-Clinton.txt', u'1995-Clinton.txt', u'1996-Clinton.txt', u'1997-Clinton.txt', u'1998-Clinton.txt', u'1999-Clinton.txt', u'2000-Clinton.txt', u'2001-GWBush-1.txt', u'2001-GWBush-2.txt', u'2002-GWBush.txt', u'2003-GWBush.txt', u'2004-GWBush.txt', u'2005-GWBush.txt', u'2006-GWBush.txt']
>>> fdist1=nltk.ConditionalFreqDist(
... (object,file[0:4])
... for file in su.fileids()
... for w in su.words(file)
... for object in ['men','women','people']
... if w.lower().startswith(object))
>>> fdist1.plot()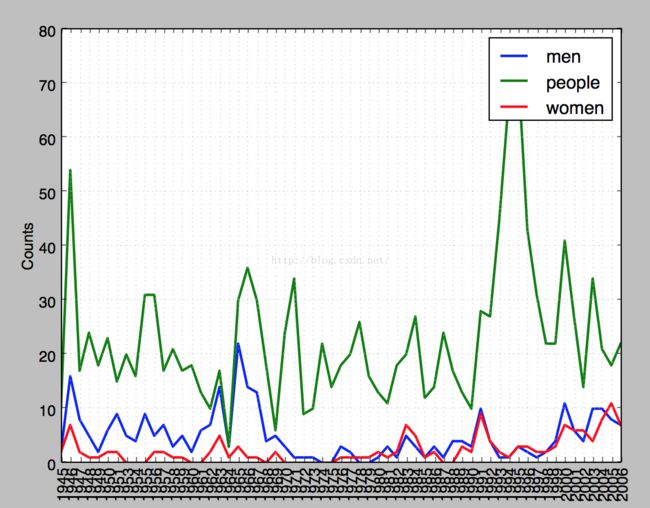
可以思考女权运动这个问题
5.
首先,复习一下2.5 WordNet
(1)意义与同义词(类属关系 AKO)
synset--同义词 lemma--词条
- 词条:motorcar 属于哪一个同义词集合
>>> from nltk.corpus import wordnet as wn >>> a=wn.synsets("motorcar") >>> a [Synset('car.n.01')]- 该同义词集合有哪些词条,也可以仅仅显示词条的名称
>>> wn.synset('car.n.01').lemmas() [Lemma('car.n.01.car'), Lemma('car.n.01.auto'), Lemma('car.n.01.automobile'), Lemma('car.n.01.machine'), Lemma('car.n.01.motorcar')] >>> wn.synset('car.n.01').lemma_names() [u'car', u'auto', u'automobile', u'machine', u'motorcar']也可以显示词条的定义和事例>>> wn.synset('car.n.01').definition() u'a motor vehicle with four wheels; usually propelled by an internal combustion engine' >>> wn.synset('car.n.01').examples() [u'he needs a car to get to work']- 提示:在课本上事例为:
>>> wn.synset('car.n.01').definition
答案会显示异常
(2) WordNet的层次结构
2.1上下位词( hyponyms hypernyms)(
类属关系中ISA的关系
)
计算到car.n.01的路径数>>> a=wn.synset('car.n.01') >>> print(a.hyponyms()) [Synset('ambulance.n.01'), Synset('beach_wagon.n.01'), Synset('bus.n.04'), Synset('cab.n.03'), Synset('compact.n.03'), Synset('convertible.n.01'), Synset('coupe.n.01'), Synset('cruiser.n.01'), Synset('electric.n.01'), Synset('gas_guzzler.n.01'), Synset('hardtop.n.01'), Synset('hatchback.n.01'), Synset('horseless_carriage.n.01'), Synset('hot_rod.n.01'), Synset('jeep.n.01'), Synset('limousine.n.01'), Synset('loaner.n.02'), Synset('minicar.n.01'), Synset('minivan.n.01'), Synset('model_t.n.01'), Synset('pace_car.n.01'), Synset('racer.n.02'), Synset('roadster.n.01'), Synset('sedan.n.01'), Synset('sport_utility.n.01'), Synset('sports_car.n.01'), Synset('stanley_steamer.n.01'), Synset('stock_car.n.01'), Synset('subcompact.n.01'), Synset('touring_car.n.01'), Synset('used-car.n.01')] >>> print(a.hypernyms()) [Synset('motor_vehicle.n.01')]>>> path=a.hypernym_paths() >>> len(path) 2 >>> [synset.name() for synset in path[0]] [u'entity.n.01', u'physical_entity.n.01', u'object.n.01', u'whole.n.02', u'artifact.n.01', u'instrumentality.n.03', u'container.n.01', u'wheeled_vehicle.n.01', u'self-propelled_vehicle.n.01', u'motor_vehicle.n.01', u'car.n.01'] >>> [synset.name() for synset in path[1]] [u'entity.n.01', u'physical_entity.n.01', u'object.n.01', u'whole.n.02', u'artifact.n.01', u'instrumentality.n.03', u'conveyance.n.03', u'vehicle.n.01', u'wheeled_vehicle.n.01', u'self-propelled_vehicle.n.01', u'motor_vehicle.n.01', u'car.n.01']
2.2 蕴含关系
>>> wn.synset('walk.v.01').entailments() [Synset('step.v.01')]
2.3 反义关系——互斥
>>> wn.lemma('rush.v.01.rush').antonyms() [Lemma('linger.v.04.linger')]
2.4 查看词条拥有哪些关系
>>> dir(wn.synset('harmony.n.02')) ['__class__', '__delattr__', '__dict__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '__unicode__', '__weakref__', '_all_hypernyms', '_definition', '_examples', '_frame_ids', '_hypernyms', '_instance_hypernyms', '_iter_hypernym_lists', '_lemma_names', '_lemma_pointers', '_lemmas', '_lexname', '_max_depth', '_min_depth', '_name', '_needs_root', '_offset', '_pointers', '_pos', '_related', '_shortest_hypernym_paths', '_wordnet_corpus_reader', 'also_sees', 'attributes', 'causes', 'closure', 'common_hypernyms', 'definition', 'entailments', 'examples', 'frame_ids', 'hypernym_distances', 'hypernym_paths', 'hypernyms', 'hyponyms', 'instance_hypernyms', 'instance_hyponyms', 'jcn_similarity', 'lch_similarity', 'lemma_names', 'lemmas', 'lexname', 'lin_similarity', 'lowest_common_hypernyms', 'max_depth', 'member_holonyms', 'member_meronyms', 'min_depth', 'name', 'offset', 'part_holonyms', 'part_meronyms', 'path_similarity', 'pos', 'region_domains', 'res_similarity', 'root_hypernyms', 'shortest_path_distance', 'similar_tos', 'substance_holonyms', 'substance_meronyms', 'topic_domains', 'tree', 'unicode_repr', 'usage_domains', 'verb_groups', 'wup_similarity']
回顾完毕!
这一题属于以下关系
2.5 整体部分关系
整体与部分关系有三种:member_
holonyms() 集合概念,把事物看成构成的一部分;
part_meronyms()
肢解后的小部分;
substance_meronyms()
事物构成的本质
>>> wn.synset('tree.n.01').member_holonyms()//树的集合是森林 [Synset('forest.n.01')]>>> wn.synset('dog.n.01').member_holonyms()//第一个:狗是犬属 [Synset('canis.n.01'), Synset('pack.n.06')]>>> wn.synset('hand.n.01').part_meronyms()//下面为hand的构成部分 [Synset('ball.n.10'), Synset('digital_arteries.n.01'), Synset('finger.n.01'), Synset('intercapitular_vein.n.01'), Synset('metacarpal_artery.n.01'), Synset('metacarpal_vein.n.01'), Synset('metacarpus.n.01'), Synset('palm.n.01')]>>> wn.synset('tree.n.01').substance_meronyms()//树的实质是心材和边材 [Synset('heartwood.n.01'), Synset('sapwood.n.01')]
6.
不懂~
7.
wwe