ZooKeeper分布式协调服务-本质是一种小的分布式文件系统
ZooKeeper
Created Tuesday 13 March 2018
ZooKeeper分布式协调服务
ZooKeeper本质上是一个分布式的小文件系统
1.全局数据一致性
无论客户端链接到哪个server,展示的数据都是一致的,因为每个server保存一份相同的数据副本。
2.可靠性
如果消息被其中一台服务器接受,那么将被所有的服务器接受
3.顺序性
全局有序:一台服务器上消息a在消息b前发布,则在所有的server上消息a都将在消息b前被发布
偏序:一个消息b在消息a后被同一个发送者发布,a必须将排在b前面。
4.数据更新的原子性
一个数据跟新要么成功,要么失败。成功的标准是半数的server成功
5.实时性
保证客户端在一个时间间隔范围内获得服务器的跟新信息,或失败消息
ZooKeeper集群角色
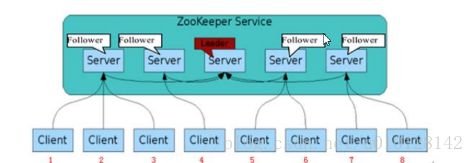
Leader:zookeeper的核心,事物请求的唯一调度和处理者,保证集群事务处理的顺序性,是集群内部各个服务器的协调者。事务就是增删该的操作。
Follower:处理客户端的非事务性请求:读操作
搭建ZooKeeper集群:
一般搭建2n+1(奇数)台server

安装jdk:
1.卸载openjdk。

2.解压tar.gz
tar -vzxf xxx.tar.gz
3.在/etc/profile中设置jdk环境变量
4.source /etc/profile重新加载profile文件。
zookeeper集群搭建:
1.安装前需要安装好jdk
2.检测集群的时间是否同步
3.检测防火墙是否关闭
4.检测主机名,ip映射有没有配置好
主要注意修改:dataDir
配置服务器ip和主机名的映射。
6.在每台主机上面启动zkServer.sh start
zookeeper数据模型:
采用树型的文件结构。树中的每个节点叫znode
1.znode兼具文件和目录的两种特点。
2.znode具有原子性操作。
3.znode存储数据大小有限制,通常kB大小文件。限制每个znode大小至多为1M
4.访问znode需要绝对路径。
每个Znode有三部分组成:
1.stat:状态信息,znode版本,权限消息
2.data:与该znode关联的数据
3.chiledren:该znode下的子节点
节点的属性:
每个znode都包含一系列的属性,通过命令get,可以获得节点的属性。
dataVersion:数据版本号, 每次对节点进行set操作,dataVersion的值都会+1
cversion:子节点版本号,当znode的子节点有变化,cversion的值就会+1
cZxid:Znode创建的事务id
mZxid:Znode被修改的事务id
ctime:节点创建时的时间戳
mtime:节点最新一次跟新发生的时间戳、
ephemeralOwner:如果该节点是临时节点,ephemeralOwner值表示与该节点绑定的session id,如果不是,ephemeralOwner值为0
节点类型:
znode:临时节点,永久节点
节点的类型在创建的时候就被确定了,并且不能改变
临时节点:该节点的生命周期依赖于创建它们的会话,一旦会话结束了,临时节点不允许拥有子节点。
永久节点:该节点的生命周期不依赖于会话,并且只在客户端显示执行删除操作的时候,它们才能被删除。
znode还有一个序列化的特性,如果创建的时候指定的话,该Znode的名字后面会自动追加一个不断增加的序列号。序列号对于此节点的父节点来说是唯一的,这样便会记录每个子节点创建的先手顺序。
zookeeper shell
客户端链接:
zkCli.sh -server ip:链接到ip主机上
creat [-s] [-e] path data acl:-s或-e分别指定节点的特性,顺序或者临时节点,如果不指定,则表示持久节点,acl用于权限控制。
创建节点:
creat -e /zktmp 123456:创建一个zktemp节点的临时节点。客户端链接断开后,会过一段时间删除
creat -s /a 123:创建一个/a 内容是123的序列话节点。
读取节点:
ls /:查看根节点下的节点
ls /hellowk:查看hellowk下面的节点。
get /hellowk:查看节点保存的数据
更新节点:
set path data
set /hellozk 455:把hellozk数据节点改变,其中该节点的事务id,dataversion也会改变,修改的时候指定的版本号要和dataversion一致。
删除节点:
delete /hellozk [version]:删除节点,删除节点必须先删除该节点的子节点。
quota命令:
setquota -n | -b val path:对节点增加限制是软性的限制,只会在日志中加入warn
-n:子节点最大个数
-b:表示数据的最大长度-1就是不限制
val:子节点最大个数或数据之的最大长度
path:节点的路径
delquota:删除quota
history:列出命令的历史。redo重新执行历史命令。
ZooKeeper watcher:
ZooKeeper中,引入了watcher机制来实现这种分布式的通知功能。ZooKeeper允许客户端向服务器端注册一个watcher监听,当服务端的一些事件触发了这个watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能,实现一个一对多的关系,能让多个订阅者监听某一个主题对象。
触发的事件:节点的创建,节点删除,节点的改变,子节点改变等。
watcher分为三个过程:客户端向服务器端注册watcher,服务器端事件发生触发watcher,客户端回调watcher得到触发的事件报告。
watch机制特点:
一次性触发:监听的效果是一次性的,后续再次发生同样的事件,不会再次触发。
事件封装:ZooKeeper使用watchedEvent对象来封装服务器端事件并传递。
watchedEvent包含了每一个事件的三个基本属性:
通知状态(KeeperState),事件类型(EventType)和节点路径(path)
event异步发送:watcher的通知事件从服务器发送到客户端是异步的。
先注册再触发:
ZooKeeper中的watch机制,必须客户端先去服务器端注册监听,这样事件发送才会触发监听,通知给客户端。
