面试问题
1.事件冒泡,阻止冒泡(事件轮询)
何为事件冒泡:
HTML DOM模型是个树形结构,元素之间有相互嵌套的关系,比如
中div是父元素而a是子元素。如果父子元素都绑定了同一个事件比如onClick,当内层的子元素的事件被触发时,该事件会被传递到父元素中。1. 阻止冒泡事件
主要是用于阻止事件传播。阻止它被分派到其他的DOM节点上,在事件传播的任何阶段都能使用。使用方法如下(兼容IE):
function stopBubble(event){ if(window.event){//兼容IE window.event.cancelBubble=true; }else{ event.stopPropagation(); }
2. 阻止默认事件
像submit这类的表单元素,都会绑定默认事件,如果不阻止默认事件,则绑定的其他方法也会无效。使用方法如下(兼容IE):
function stopDefaultEvent(event){ if(window.event){//兼容IE window.event.returnValue=false; }else{ event.preventDefault() } return false; }
jQuery中如何同时阻止事件冒泡和阻止事件默认行为:在事件处理函数中执行return false;
2.call apply extend 区别(继承)
call函数和apply函数用于改变函数中this的指向,用于对象A调用对象B的方法,call函数和apply函数的区别在于传参的类型不同,apply(x,y),x表示的是执行函数的对象,而y则表示执行函数所需要调用的参数,是一个数组,并且可以传参为argument数组,而call(x,y)中的y之后的变量则是实实在在的变量;
apply:方法能劫持另外一个对象的方法,继承另外一个对象的属性.Function.apply(obj,args)方法能接收两个参数
call:和apply的意思一样,只不过是参数列表不一样. Function.call(obj,[param1[,param2[,…[,paramN]]]])
对象的继承,一般的做法是复制:Object.extend
3.处理跨域的办法
什么是跨域?
跨域是指一个域下的文档或脚本试图去请求另一个域下的资源,这里跨域是广义的。
广义的跨域:
1.) 资源跳转: A链接、重定向、表单提交
2.) 资源嵌入: 、2.)子窗口:(child.domain.com/b.html)
三、 location.hash + iframe跨域
实现原理: a欲与b跨域相互通信,通过中间页c来实现。 三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信。
具体实现:A域:a.html -> B域:b.html -> A域:c.html,a与b不同域只能通过hash值单向通信,b与c也不同域也只能单向通信,但c与a同域,所以c可通过parent.parent访问a页面所有对象。
1.)a.html:(www.domain1.com/a.html)
2.)b.html:(www.domain2.com/b.html)
3.)c.html:(www.domain1.com/c.html)
四、 window.name + iframe跨域
window.name属性的独特之处:name值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
1.)a.html:(www.domain1.com/a.html)
var proxy = function(url, callback) {
var state = 0;
var iframe = document.createElement('iframe');
// 加载跨域页面
iframe.src = url;
// onload事件会触发2次,第1次加载跨域页,并留存数据于window.name
iframe.onload = function() {
if (state === 1) {
// 第2次onload(同域proxy页)成功后,读取同域window.name中数据
callback(iframe.contentWindow.name);
destoryFrame();
} else if (state === 0) {
// 第1次onload(跨域页)成功后,切换到同域代理页面
iframe.contentWindow.location = 'http://www.domain1.com/proxy.html';
state = 1;
}
};
document.body.appendChild(iframe);
// 获取数据以后销毁这个iframe,释放内存;这也保证了安全(不被其他域frame js访问)
function destoryFrame() {
iframe.contentWindow.document.write('');
iframe.contentWindow.close();
document.body.removeChild(iframe);
}
};
// 请求跨域b页面数据
proxy('http://www.domain2.com/b.html', function(data){
alert(data);
});2.)proxy.html:(www.domain1.com/proxy....
中间代理页,与a.html同域,内容为空即可。
3.)b.html:(www.domain2.com/b.html)
总结:通过iframe的src属性由外域转向本地域,跨域数据即由iframe的window.name从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
五、 postMessage跨域
postMessage是HTML5 XMLHttpRequest Level 2中的API,且是为数不多可以跨域操作的window属性之一,它可用于解决以下方面的问题:
a.) 页面和其打开的新窗口的数据传递
b.) 多窗口之间消息传递
c.) 页面与嵌套的iframe消息传递
d.) 上面三个场景的跨域数据传递
用法:postMessage(data,origin)方法接受两个参数
data: html5规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用JSON.stringify()序列化。
origin: 协议+主机+端口号,也可以设置为"*",表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为"/"。
1.)a.html:(www.domain1.com/a.html)
2.)b.html:(www.domain2.com/b.html)
六、 跨域资源共享(CORS)
普通跨域请求:只服务端设置Access-Control-Allow-Origin即可,前端无须设置。
带cookie请求:前后端都需要设置字段,另外需注意:所带cookie为跨域请求接口所在域的cookie,而非当前页。
目前,所有浏览器都支持该功能(IE8+:IE8/9需要使用XDomainRequest对象来支持CORS)),CORS也已经成为主流的跨域解决方案。
1、 前端设置:
1.)原生ajax
// 前端设置是否带cookie
xhr.withCredentials = true;示例代码:
var xhr = new XMLHttpRequest(); // IE8/9需用window.XDomainRequest兼容
// 前端设置是否带cookie
xhr.withCredentials = true;
xhr.open('post', 'http://www.domain2.com:8080/login', true);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.send('user=admin');
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
alert(xhr.responseText);
}
};2.)jQuery ajax
$.ajax({
...
xhrFields: {
withCredentials: true // 前端设置是否带cookie
},
crossDomain: true, // 会让请求头中包含跨域的额外信息,但不会含cookie
...
});3.)vue框架在vue-resource封装的ajax组件中加入以下代码:
Vue.http.options.credentials = true2、 服务端设置:
若后端设置成功,前端浏览器控制台则不会出现跨域报错信息,反之,说明没设成功。
1.)Java后台:
/*
* 导入包:import javax.servlet.http.HttpServletResponse;
* 接口参数中定义:HttpServletResponse response
*/
response.setHeader("Access-Control-Allow-Origin", "http://www.domain1.com"); // 若有端口需写全(协议+域名+端口)
response.setHeader("Access-Control-Allow-Credentials", "true");2.)Nodejs后台示例:
var http = require('http');
var server = http.createServer();
var qs = require('querystring');
server.on('request', function(req, res) {
var postData = '';
// 数据块接收中
req.addListener('data', function(chunk) {
postData += chunk;
});
// 数据接收完毕
req.addListener('end', function() {
postData = qs.parse(postData);
// 跨域后台设置
res.writeHead(200, {
'Access-Control-Allow-Credentials': 'true', // 后端允许发送Cookie
'Access-Control-Allow-Origin': 'http://www.domain1.com', // 允许访问的域(协议+域名+端口)
'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly:脚本无法读取cookie
});
res.write(JSON.stringify(postData));
res.end();
});
});
server.listen('8080');
console.log('Server is running at port 8080...');七、 nginx代理跨域
1、 nginx配置解决iconfont跨域
浏览器跨域访问js、css、img等常规静态资源被同源策略许可,但iconfont字体文件(eot|otf|ttf|woff|svg)例外,此时可在nginx的静态资源服务器中加入以下配置。
location / {
add_header Access-Control-Allow-Origin *;
}2、 nginx反向代理接口跨域
跨域原理: 同源策略是浏览器的安全策略,不是HTTP协议的一部分。服务器端调用HTTP接口只是使用HTTP协议,不会执行JS脚本,不需要同源策略,也就不存在跨越问题。
实现思路:通过nginx配置一个代理服务器(域名与domain1相同,端口不同)做跳板机,反向代理访问domain2接口,并且可以顺便修改cookie中domain信息,方便当前域cookie写入,实现跨域登录。
nginx具体配置:
#proxy服务器
server {
listen 81;
server_name www.domain1.com;
location / {
proxy_pass http://www.domain2.com:8080; #反向代理
proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名
index index.html index.htm;
# 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用
add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为*
add_header Access-Control-Allow-Credentials true;
}
}1.) 前端代码示例:
var xhr = new XMLHttpRequest();
// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;
// 访问nginx中的代理服务器
xhr.open('get', 'http://www.domain1.com:81/?user=admin', true);
xhr.send();2.) Nodejs后台示例:
var http = require('http');
var server = http.createServer();
var qs = require('querystring');
server.on('request', function(req, res) {
var params = qs.parse(req.url.substring(2));
// 向前台写cookie
res.writeHead(200, {
'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly:脚本无法读取
});
res.write(JSON.stringify(params));
res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');八、 Nodejs中间件代理跨域
node中间件实现跨域代理,原理大致与nginx相同,都是通过启一个代理服务器,实现数据的转发。
1、 非vue框架的跨域(2次跨域)
利用node + express + http-proxy-middleware搭建一个proxy服务器。
1.)前端代码示例:
var xhr = new XMLHttpRequest();
// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;
// 访问http-proxy-middleware代理服务器
xhr.open('get', 'http://www.domain1.com:3000/login?user=admin', true);
xhr.send();2.)中间件服务器:
var express = require('express');
var proxy = require('http-proxy-middleware');
var app = express();
app.use('/', proxy({
// 代理跨域目标接口
target: 'http://www.domain2.com:8080',
changeOrigin: true,
// 修改响应头信息,实现跨域并允许带cookie
onProxyRes: function(proxyRes, req, res) {
res.header('Access-Control-Allow-Origin', 'http://www.domain1.com');
res.header('Access-Control-Allow-Credentials', 'true');
},
// 修改响应信息中的cookie域名
cookieDomainRewrite: 'www.domain1.com' // 可以为false,表示不修改
}));
app.listen(3000);
console.log('Proxy server is listen at port 3000...');3.)Nodejs后台同(六:nginx)
2、 vue框架的跨域(1次跨域)
利用node + webpack + webpack-dev-server代理接口跨域。在开发环境下,由于vue渲染服务和接口代理服务都是webpack-dev-server同一个,所以页面与代理接口之间不再跨域,无须设置headers跨域信息了。
webpack.config.js部分配置:
module.exports = {
entry: {},
module: {},
...
devServer: {
historyApiFallback: true,
proxy: [{
context: '/login',
target: 'http://www.domain2.com:8080', // 代理跨域目标接口
changeOrigin: true,
cookieDomainRewrite: 'www.domain1.com' // 可以为false,表示不修改
}],
noInfo: true
}
}九、 WebSocket协议跨域
WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。原生WebSocket API使用起来不太方便,我们使用Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。
1.)前端代码:
user input:
2.)Nodejs socket后台:
var http = require('http');
var socket = require('socket.io');
// 启http服务
var server = http.createServer(function(req, res) {
res.writeHead(200, {
'Content-type': 'text/html'
});
res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');
// 监听socket连接
socket.listen(server).on('connection', function(client) {
// 接收信息
client.on('message', function(msg) {
client.send('hello:' + msg);
console.log('data from client: ---> ' + msg);
});
// 断开处理
client.on('disconnect', function() {
console.log('Client socket has closed.');
});
});4.算法
5.http协议
HTTP简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-NG(Next Generation of HTTP)的建议已经提出。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
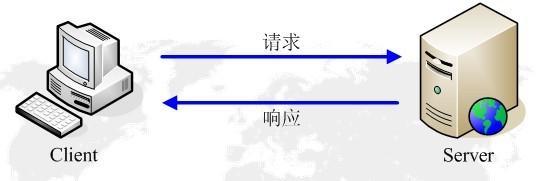
http请求-响应模型.jpg
主要特点
1、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5、支持B/S及C/S模式。
HTTP之URL
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
1.协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
2.域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
3.端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
4.虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
5.文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
6.锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
7.参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
(原文:http://blog.csdn.net/ergouge/article/details/8185219 )
URI和URL的区别
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的
URI一般由三部组成:
①访问资源的命名机制
②存放资源的主机名
③资源自身的名称,由路径表示,着重强调于资源。
URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成:
①协议(或称为服务方式)
②存有该资源的主机IP地址(有时也包括端口号)
③主机资源的具体地址。如目录和文件名等
URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:[email protected]。
URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例。
在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。
在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。
相反的是,URL类可以打开一个到达资源的流。
HTTP之请求消息Request
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。

Http请求消息结构.png
- 请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。
Get请求例子,使用Charles抓取的request:
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.
GET说明请求类型为GET,[/562f25980001b1b106000338.jpg]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息
从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
第三部分:空行,请求头部后面的空行是必须的
即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。
这个例子的请求数据为空。
POST请求例子,使用Charles抓取的request:
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley第一部分:请求行,第一行明了是post请求,以及http1.1版本。
第二部分:请求头部,第二行至第六行。
第三部分:空行,第七行的空行。
第四部分:请求数据,第八行。
HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。

http响应消息格式.jpg
例子
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头,
Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的html部分为响应正文。
HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常更多状态码http://www.runoob.com/http/http-status-codes.html
HTTP请求方法
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1、浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
3、浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP连接;
6、浏览器将该 html 文本并显示内容;
GET和POST请求的区别
GET请求
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive注意最后一行是空行
POST请求
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley1、GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据
因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
2、传输数据的大小:首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。
而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系 统的支持。
因此对于GET提交时,传输数据就会受到URL长度的 限制。
POST:由于不是通过URL传值,理论上数据不受 限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
3、安全性
POST的安全性要比GET的安全性高。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存;(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击
4、Http get,post,soap协议都是在http上运行的
(1)get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的
查询字符串的长度受到web浏览器和web服务器的限制(如IE最多支持2048个字符),不适合传输大型数据集同时,它很不安全
(2)post:请求参数是在http标题的一个不同部分(名为entity body)传输的,这一部分用来传输表单信息,因此必须将Content-type设置为:application/x-www-form- urlencoded。post设计用来支持web窗体上的用户字段,其参数也是作为key/value对传输。
但是:它不支持复杂数据类型,因为post没有定义传输数据结构的语义和规则。
(3)soap:是http post的一个专用版本,遵循一种特殊的xml消息格式
Content-type设置为: text/xml 任何数据都可以xml化。
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
我们看看GET和POST的区别
-
-
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
-
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
-
GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
-
GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
-
6.面向对象是什么
把一组数据结构和处理它们的方法组成对象,把相同行为的对象归纳为类(class),通过类的封装(encapsulation)隐藏内部细节,通过继承(inheritance)实现类的特化(specialization)/泛化(generalization),通过多态(polymorphism)实现基于对象类型的动态分派(dynamic dispatch)。
7.promise有什么参数
1.Promise的含义
Promise是异步编程的一种解决方案,比传统的解决方案(回调函数和事件)更合理更强大。
所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件 (通常是一个异步操作)的结果。从语法上说,Promise是一个对象,从它可以获取异步操作的消息。
Promise对象有以下2个特点:
1.对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:Pending(进行中)、Resolved(已完成)和Rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
2.一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从Pending变为Resolved;从Pending变为Rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果。就算改变已经发生了,你再对Promise对象田静回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
有了Promise对象,就可以把异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数。此外,Promise对象提供了统一的接口,使得控制异步操作更加容易。
2.基本用法
ES6规定,Promise对象是一个构造函数,用来生成Promise实例
var promise = new Promise(function(resolve,reject){
// ... some code
if(/* 异步操作成功 */){
resolve(value);
}else{
reject(error);
}
});
1
2
3
4
5
6
7
8
Promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,又JavaScript引擎提供,不是自己部署。
resolve函数的作用,将Promise对象的状态从“未完成”变成“成功”(即从Pending变为Resolved),在异步操作成功时调用,并将异步操作的结果,作为参数传递出去;
reject函数的作用是,在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去。
Promise实例生成以后,可以用then方法分别制定Resolved状态和Rejected状态的回调函数:
promise.then(function(value){
// sucess
},function(error){
// failure
});
1
2
3
4
5
then方法可以接受2个回调函数作为参数,第二个函数是可选的,不一定要提供。这两个函数都接受Promise对象传出的值作为参数。
下面是一个Promise对象的简单例子:
function timeout(ms){
return new Promise((resolve,reject)=>{
setTimeout(resolve,ms,'done');
});
}
timeout(100).then((value)=>{
console.log(value);
});
1
2
3
4
5
6
7
8
9
上面代码中,timeout方法返回一个Promise实例,表示一段事件以后才会发生的结果。过了指定的时间(ms参数)以后,Promise实例的状态变为Resolved,就会触发then方法绑定的回调函数。
Promise新建后就会立即执行
let promise = new Promise(function(resolve,rejeact){
console.log('Promise');
resolve();
});
promise.then(function(){
console.log('Resolved');
});
console.log('Hi');
// Promise
// Hi
// Resolved
1
2
3
4
5
6
7
8
9
10
11
12
13
14
上面代码中,Promise新建后立即执行,所以首先输出的是”Promise”,然后then方法指定的回调函数,将在当前脚本所有同步任务执行完才会执行,所以”Resolved”最后输出。
下面是异步加载图片的例子:
function loadImageAsync(url){
return new Promise(function(resolve,reject){
var image = new Image();
image.onload = function(){
resolve(image);
};
image.onerror = function(){
reject(new Error('Could not load image at' + url));
};
image.src = url;
});
}
1
2
3
4
5
6
7
8
9
10
11
12
13
下面是一个用Promise对象实现Ajax操作的例子:
var getJSON = function(url){
var promise = new Promise(function(resolve,reject){
var client = new XMLHttpRequest();
client.open('GET',url);
client.onreadystatechange = handler;
client.responseType = 'json';
client.setRequestHeader('Accept','application/json');
client.send();
function handler(){
if(this.readyState !== 4){
return;
}
if(this.status === 200){
resolve(this.response);
}else{
reject(new Error(this.statusText));
}
}
});
return promise;
};
//
getJSON('/posts.jons').then(function(json){
consoloe.log(json);
},function(error){
console.log('出错了');
});
8.opacity rgba的区别
首先来看rgba:
R:红色值。正整数 | 百分数
G:绿色值。正整数 | 百分数
B:蓝色值。正整数 | 百分数
A:Alpha透明度。取值0~1之间。
再看opacity:
后面的取值为从 0.0 (完全透明)到 1.0(完全不透明)。
两者的区别:opacity会继承父元素的 opacity 属性,而RGBA设置的元素的后代元素不会继承不透明属性。
9.如何水平垂直居中一个不知道宽高的盒子
方法一:使用CSS3 transform
父盒子设置:position:relative;
div设置:position:absolute;transform:translate(-50%,-50%);top:50%;left:50%;
方法二:使用display:table-cell
父盒子设置:display:table-cell;text-align:center;vertical-align:middle;
div设置:display:inline-block;vertical-align:middle;
方法三:使用CSS3 flex
父盒子设置:display:flex;justify-content:center;align-items:center;
10.读没读过jquery源码,有什么优点
jquery其实是利用闭包的原理,用立即执行函数进行包裹,模仿块级作用域,避免了全局变量的污染。另外此函数最终返回的是jQuery,它是一个内部定义的函数,这样的作用是将内部变量以及实现方法隐藏,仅暴露jQuery对象以供调用。
if ( !noGlobal ) {
window.jQuery = window.$ = jQuery;
}
return jQuery;
} );
事件机制:通过bind、delegate、on可为dom元素绑定事件。其中bind方法只能绑定此刻已经存在于dom树中的节点。其中click()这种写法就是bind方法的简写形式,delegate和on方法都能实现事件的委托。其中delegate方法选择最近的稳定元素进行委托,而on方法无此限制。通过阅读源码我们可以看到bind以及delegate方法最终也是通过on方法进行实现。我们查看on方法源码后,发现内部实现未参数的处理以及调用jquery.event.add方法,所以事件处理的关键就是这个jquery.event.add方法。这个方法主要是将注册函数与dom本身解耦,将事件相关的内容存储到缓存系统中(dataPriv),每个结点在cache中有一份关联的数据elemData,存储所有相关的数据,事件相关的内容存放在elemData.events中,是jquery内部维护的事件队列,jquery并没有将自定义的回调函数直接作为事件触发回调,而是对其进行一层抽象,保存到elemData.handle中(包括type,data.handler.selector等),然后把这个抽象的回调函数添加到事件注册列表中。下面将对这个方法进行详细介绍。
一。将jquery.event.add方法源码从上到下挑选重要部分进行描述:
1.首先elemData=dataPriv.get(elem);此句是将elem以key-value形式缓存在Data缓存对象中 这个方法会进而调用cache方法。若事件被注册过,用get方法从缓存中拿,若缓存中没有,就创建一个用于elem映射的缓存区,这个处理主要是合并同个元素绑定多个事件的问题,就是把相同元素绑定的不同行为都合并到一个缓存里。
2.进行handler selector等进行判断,看是否有效,创建编号,用来查找和删除事件。
3.为elemData的handle属性添加匿名函数。在匿名函数中返回jQuery.event.dispatch.apply(elem,arguments),此处作用是在elem作用域内调用dispatch方法。eventHandle是作用到addeventlistener的回调函数。回调函数设为dispatch。
event.handle会在这个节点任意事件触发的时候调用到,然后执行dispatch方法。
4.事件可能是通过空格键分割的字符串,将types变成字符串数组,遍历所有事件,若第一次使用,初始化事件处理队列,引入handlers,把事件handleobj全部push到handlers里一个个执行,还区分了委托和其他事件。
5.执行addeventlistener函数,callback函数是dispatch。
二。在dispatch中对传入的event进行重新包装成$.event对象,jquery.event.fix(event)屏蔽掉各浏览器间差异,获取回调函数列表后,将它们放入队列,并根据它们对应的选择器依次决定是否需要执行
11.有没有了解过浏览器垃圾回收机制
垃圾回收机制
垃圾收集器必须跟踪哪个变量有用哪个变量没用,对于不再有用的变量打上标记,以备将来收回其占用的内存,内存泄露和浏览器实现的垃圾回收机制息息相关, 而浏览器实现标识无用变量的策略主要有下两个方法:
引用计数
跟踪记录每个值被引用的次数。当声明一个变量并将引用类型的值赋给该变量时,则这个值的引用次数就是1。如果同一个值又被赋给另一个变量,则该值的引用次 数加1.相反,如果包含对这个值引用的变量又取得另外一个值,则这个值的引用次数减1.当这个值的引用次数变成0时,则说明没有办法访问这个值了,因此就 可以将其占用的内存空间回收回来。
所以这时对象{}不会被回收;
IE 6, 7 对DOM对象进行引用计数回收, 这样简单的垃圾回收机制,非常容易出现循环引用问题导致内存不能被回收, 进行导致内存泄露等问题, 如:a();//函数a执行完后,本来x, y对象都应该在垃圾回收阶段被回收, 可是由于存在循环引用,也不能被回收。
标记清除(mark-and-sweep)
到2008年为止,IE,Firefox,Opera,Chrome和Safari的javascript实现使用的都是标记清除式的垃圾收集策略(或类似的策略),只不过垃圾收集的时间间隔互有不同。
标记清除的算法分为两个阶段,标记(mark)和清除(sweep). 第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除
12.深拷贝浅拷贝
1、javaScript的变量类型
(1)基本类型:
5种基本数据类型Undefined、Null、Boolean、Number 和 String,变量是直接按值存放的,存放在栈内存中的简单数据段,可以直接访问。
(2)引用类型:
存放在堆内存中的对象,变量保存的是一个指针,这个指针指向另一个位置。当需要访问引用类型(如对象,数组等)的值时,首先从栈中获得该对象的地址指针,然后再从堆内存中取得所需的数据。
JavaScript存储对象都是存地址的,所以浅拷贝会导致 obj1 和obj2 指向同一块内存地址。改变了其中一方的内容,都是在原来的内存上做修改会导致拷贝对象和源对象都发生改变,而深拷贝是开辟一块新的内存地址,将原对象的各个属性逐个复制进去。对拷贝对象和源对象各自的操作互不影响。
例如:数组拷贝
?
| 1 2 3 4 5 6 |
|
2、浅拷贝的实现
2.1、简单的引用复制
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
2.2、Object.assign()
Object.assign() 方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。Object.assign会跳过那些值为 null 或 undefined 的源对象。
?
| 1 2 3 4 5 6 7 |
|
3、深拷贝的实现
3.1、Array的slice和concat方法
Array的slice和concat方法不修改原数组,只会返回一个浅复制了原数组中的元素的一个新数组。之所以把它放在深拷贝里,是因为它看起来像是深拷贝。而实际上它是浅拷贝。原数组的元素会按照下述规则拷贝:
- 如果该元素是个对象引用 (不是实际的对象),slice 会拷贝这个对象引用到新的数组里。两个对象引用都引用了同一个对象。如果被引用的对象发生改变,则新的和原来的数组中的这个元素也会发生改变。
- 对于字符串、数字及布尔值来说(不是 String、Number 或者 Boolean 对象),slice 会拷贝这些值到新的数组里。在别的数组里修改这些字符串或数字或是布尔值,将不会影响另一个数组。
如果向两个数组任一中添加了新元素,则另一个不会受到影响。例子如下:
?
| 1 2 3 4 5 6 7 |
|
可以看出,concat和slice返回的不同的数组实例,这与直接的引用复制是不同的。而从另一个例子可以看出Array的concat和slice并不是真正的深复制,数组中的对象元素(Object,Array等)只是复制了引用。如下:
?
| 1 2 3 4 5 6 7 8 9 |
|
3.2、JSON对象的parse和stringify
JSON对象是ES5中引入的新的类型(支持的浏览器为IE8+),JSON对象parse方法可以将JSON字符串反序列化成JS对象,stringify方法可以将JS对象序列化成JSON字符串,借助这两个方法,也可以实现对象的深拷贝。
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
这种方法使用较为简单,可以满足基本的深拷贝需求,而且能够处理JSON格式能表示的所有数据类型,但是对于正则表达式类型、函数类型等无法进行深拷贝(而且会直接丢失相应的值)。还有一点不好的地方是它会抛弃对象的constructor。也就是深拷贝之后,不管这个对象原来的构造函数是什么,在深拷贝之后都会变成Object。同时如果对象中存在循环引用的情况也无法正确处理。
4、jQuery.extend()方法源码实现
jQuery的源码 - src/core.js #L121源码及分析如下:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
|
jQuery的extend方法使用基本的递归思路实现了浅拷贝和深拷贝,但是这个方法也无法处理源对象内部循环引用,例如:
?
| 1 2 3 4 5 |
|
5、自己动手实现一个拷贝方法
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
13.hash导航和history导航的原理
vue-router 的 hash 模式与 history 模式
提供两种模式的原因:
vue 是渐进式前端开发框架,为了实现 SPA ,需要引入前端路由系统(vue-router)。前端路由的核心是:改变视图的同时不会向后端发出请求。
为了达到这一目的,浏览器提供了 hash 和 history 两种模式。
hash :hash 虽然出现在 URL 中,但不会被包含在 http 请求中,对后端完全没有影响,因此改变 hash 不会重新加载页面。
history :history 利用了 html5 history interface 中新增的 pushState() 和 replaceState() 方法。这两个方法应用于浏览器记录栈,在当前已有的 back、forward、go 基础之上,它们提供了对历史记录修改的功能。只是当它们执行修改时,虽然改变了当前的 URL ,但浏览器不会立即向后端发送请求。
因此可以说, hash 模式和 history 模式都属于浏览器自身的属性,vue-router 只是利用了这两个特性(通过调用浏览器提供的接口)来实现路由。
实现的原理:
hash 模式的原理是 onhashchange 事件,可以在 window 对象上监听这个事件。
history :hashchange 只能改变 # 后面的代码片段,history api (pushState、replaceState、go、back、forward) 则给了前端完全的自由,通过在window对象上监听popState()事件。
pushState()、replaceState() 方法接收三个参数:stateObj、title、url。
// 设置状态
history.pushState({color: "red"}, "red", "red");
// 监听状态
window.onpopstate = function(event){
console.log(event.state);
if(event.state && event.state.color === "red"){
document.body.style.color = "red";
}
}
// 改变状态
history.back();
history.forward();
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
应用场景:
通过 pushState 把页面的状态保存在 state 对象中,当页面的 url 再变回到这个 url 时,可以通过 event.state 取到这个 state 对象,从而可以对页面状态进行还原,如页面滚动条的位置、阅读进度、组件的开关等。
调用 history.pushState() 比使用 hash 存在的优势:
pushState 设置的 url 可以是同源下的任意 url ;而 hash 只能修改 # 后面的部分,因此只能设置当前 url 同文档的 url
pushState 设置的新的 url 可以与当前 url 一样,这样也会把记录添加到栈中;hash 设置的新值不能与原来的一样,一样的值不会触发动作将记录添加到栈中
pushState 通过 stateObject 参数可以将任何数据类型添加到记录中;hash 只能添加短字符串
pushState 可以设置额外的 title 属性供后续使用
劣势:
history 在刷新页面时,如果服务器中没有相应的响应或资源,就会出现404。因此,如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面
hash 模式下,仅 # 之前的内容包含在 http 请求中,对后端来说,即使没有对路由做到全面覆盖,也不会报 404