MySql的基本常识和crud语句大全。。。。。
一、数据库的简介
* 之前做的操作都是使用xml当做数据库,操作xml使用dom4j技术进行操作,xml本身就是一个文件
* 数据库本身也是文件,使用标准的sql对数据库进行crud的操作
* 常见的数据库(6个)
** oracle数据库:oracle公司的产品,是一个收费的大型的数据库
** DB2数据库:IBM公司产品,是一个大型的收费的数据库
** SQLServer数据库:微软产品,中型的数据库
** MySQL数据库:现在已经被Oracle收购,MySQL在6.0开始收费的
** SQLite数据库:小型的嵌入式的数据库,用在安卓...
** sybase数据库:现在已经不使用,建模工具powerDesigner
* 上面列出这些数据库,都有一个通用的名字,是关系数据库
** 关系数据库里面存的是 实体之间的关系
** 画图说明实体之间的关系
*** 比如购物网站,用户 订单 商品

* 非关系数据库:mongodb redis....
二、mySQL数据库的安装和卸载
* mysql数据库的安装:上一篇博客已经讲了,傻瓜式的对着做就OK了
* mysql数据库的卸载:
** 停止MySQL服务
1、到安装目录里面找到my.ini文件,在这个文件里面找到
* 找到mysql的安装路径
** basedir="C:/Program Files (x86)/MySQL/MySQL Server 5.5/"
** datadir="C:/ProgramData/MySQL/MySQL Server 5.5/Data/"
2、在系统的控制面板里面删除程序中卸载MySQL
3、把第一步找到的两个路径里面的所有内容都删除
4、查看注册表:
使用这个命令regedit
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services
搜索mysql,找到一律删除!
* 安装的mysql版本是 mysql5.X版本
三、mysql数据库的存储结构
* 画图分析存储结构
* 数据库
* 数据库表:相当于javabean
* 表中记录:相当于javabean对象


* 对数据库crud操作
* 对数据库表crud操作
* 对表中的记录crud操作
* 标准sql:这种语句不仅可以在mysql数据库里面使用,也可以在其他数据库里面使用
* 在很多的数据库里面有自己特有的语句,这些语句只能在自己的数据库里面使用
** oracle里面:pl-sql
** sqlSERVLET里面:t-sql
4、SQL语言的简介
* Structured Query Language, 结构化查询语言
* 非过程性语言,不需要依赖于任何的条件就可以直接执行
** 比如java代码
if(i == 10) {
system.......
}
* sql的分类
DDL (数据定义语言)
数据定义语言 - Data Definition Language
用来定义数据库的对象,如数据表、视图、索引等
* 常用语句 create
DML (数据操纵语言)
数据处理语言 - Data Manipulation Language
在数据库表中更新,增加和删除记录
* 常用的语句 update, insert, delete
DCL (数据控制语言)
数据控制语言 – Data Control Language
指用于设置用户权限和控制事务语句
如grant,revoke,if…else,while,begin transaction
===== 上面的三个分类,是官方的分类
DQL (数据查询语言):非官方的分类
数据查询语言 – Data Query Language
* 常用的语句:select
5、对数据库进行操作
* 要对数据库进行操作,首先连接数据库
* 执行这个命令的前提:mysql服务必须是启动的
* 打开cmd窗口,在窗口里面输入一个命令
** mysql -u root -p
*** -u : username
*** -p :password
* 输入命令之后,当出现 mysql>,表示连接成功
* 创建数据库(后面不要写后缀名)
** 语句:create database 数据库的名称;
* 查看数据库(显示当前所有的数据库)
** 语句:show databases;
* 删除数据库
** 语句:drop database 要删除的数据库的名称;
* 切换数据库
** 语句:use 要进入的那个数据库的名称;
6、对数据库表进行操作
(1) 创建数据库表
** 如果想要创建表,首先要到某个数据库里面去
** 语句:(注意最后面的那个不要加逗号)
create table 表名 (
字段名称1 字段类型,
字段名称2 字段类型
);
** 向数据库表里面添加记录时候,如果记录类型是一个字符串类型或者日期类型,
*** 注意一:字符串类型需要写长度
*** 注意二:这两个类型的值必须使用引号括起来(单引号)
* 字段的类型
** 字符串型
VARCHAR、CHAR
** 如果把字段的类型设置成字符串类型,类型后面必须要加上长度 varchar(20) char(20)
** VARCHAR和CHAR区别:
*** char类型长度是固定的
*** 如果定义char(20),长度固定20,记录比如值aa,到数据库表里面存储的方式 aa加很多空格
*** varchar类型长度是可变的
*** 如果定义varchar(20),记录值是bb,到数据库表里面存储方式:直接存bb,没有空格
** 大数据类型
BLOB、TEXT
*** 主要用于存储文件到数据库,但是在实际应用中,不可能直接把文件存到数据库里面
** 数值型
TINYINT 、SMALLINT、INT、BIGINT、FLOAT、DOUBLE
***对应于java里面基本数据类型里面
byte short int long float double
** 逻辑性
BIT
*** 对应于java基本数据类型的boolean
日期型
DATE、TIME、DATETIME、TIMESTAMP
* data:只能表示日期
* time:只能表示实际
==========================
下面两个类型既可用表示日期,也可以表示时间
* datetime:需要手动输入日期的格式
* TIMESTAMP:不需要手动输入,字段添加当前的日期到数据库表里面
* 创建一个员工表 employee
字段 属性
id int型
name 字符型
sex 字符型
bir 字符型
job 字符型
sal int型
* 语句
create table employee (
id int,
name varchar(40),
sex varchar(20),
bir varchar(40),
job varchar(40),
sal int
)
(2) 查看创建的表结构
** 语句:desc 表名称;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(40) | YES | | NULL | |
| sex | varchar(20) | YES | | NULL | |
| bir | varchar(40) | YES | | NULL | |
| job | varchar(40) | YES | | NULL | |
| sal | int(11) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+

** 关于desc语句的使用中问题
*** 如果电脑上安装了杀毒软件,在某些情况下,这个语句不能执行,
*** 卖咖啡,卡巴斯基....
(3)创建带约束的标签
* 约束有三种
** 第一种约束:主键约束
* 定义的类型后面
* 语句:primary key :非空,唯一性
*** 自动增长:auto_increment
** 每次插入记录,自动增加一个值
** 比如添加第一条记录 自动添加一个值 1
** 比如添加第二条记录,在之前的基础之上+1


** 第二种约束:唯一性约束
* 这条记录值不能有重复的
* 定义的类型后面 unique
** 第三种约束:非空约束
* 表里面字段上面不能有空数据,必须有数据
* 语句 在name varchar(40) not null,
* 创建一个带约束的表
create table person1(
id int primary key,
name varchar(40) not null,
sex varchar(20) not null,
bir varchar(40) not null,
job varchar(40) not null,
sal int
)

(4)删除数据库表
* 语句 drop table 要删除的表;
(5)查看数据库里面所有的数据库表
* 语句 show tables;

(6)向数据库表中添加记录操作
* 语句 insert into 要添加的表名称 values(要添加的值);
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(40) | YES | | NULL | |
| sex | varchar(20) | YES | | NULL | |
| bir | varchar(40) | YES | | NULL | |
| job | varchar(40) | YES | | NULL | |
| sal | int(11) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
insert into employee values(100,'lucy','nv','2015-11-11','worker',500);
* 查看表中的记录
* 语句 select * from 表名;
insert into employee values(100,'lucy','nv','2015-11-11','worker',500)
insert into employee values(101,'小黑','unknow','2011-01-11','door',1000)
insert into employee values(102,'小白','nv','1911-11-11','it',2000)
insert into employee values(103,'大白','nan','1811-11-01','aaa',100000)
+------+------+------+------------+--------+------+
| id | name | sex | bir | job | sal |
+------+------+------+------------+--------+------+
| 100 | lucy | nv | 2015-11-11 | worker | 500 |
+------+------+------+------------+--------+------+
(7)修改表中的记录操作(别忘了,如果where后面是字符类型要写‘’(单引号))
* 语句 update 表名 set 要修改字段名称=要修改成的值 where ....
* 练习
** 将所有员工薪水修改为5000元。
update employee set sal=5000;
** 将姓名为’lucy’的员工薪水修改为3000元。
update employee set sal=3000 where name='lucy';
** 将姓名为’lucy’的员工薪水修改为4000元,job改为ccc。
update employee set sal=4000,job='ccc' where name='lucy';
** 将姓名为’lucy’的员工薪水在原有基础上增加1000元。
update employee set sal=sal+1000 where name='lucy';
(10)删除表中的记录的操作
* 语句 delete from 表名称 where...
** 如果添加where添加,根据添加进行删除;如果没有添加where,把表里面的所有数据都删除
* 练习
** 删除表中名称为’lucy’的记录。
delete from employee where name='lucy';
** 删除表中所有记录。
delete from employee;
===========================================================
查询语句是今天最重要的内容,重点掌握
7、查询数据库表中的记录
(1)sql分类:DQL (数据查询语言)
* 语句 select 要查询的字段(写*表示所有的字段) from 要查询的表名称 where ..........
** 关键字 DISTINCT:表示去除表中重复的记录
* 创建一个学生表
create table stu (
id int primary key auto_increment,
sname varchar(40),
chinese int,
english int,
math int
)
* +---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| sname | varchar(40) | YES | | NULL | |
| chinese | int(11) | YES | | NULL | |
| english | int(11) | YES | | NULL | |
| math | int(11) | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
* insert into stu values(201,'熊大',120,20,80);
insert into stu values(202,'熊二',50,100,60);
insert into stu values(203,'光头强',200,100,500);
insert into stu values(204,'李老板',300,10,1000);
* 练习:
** 查询表中所有学生的信息。
select * from stu;
** 查询表中所有学生的姓名和对应的英语成绩。
select sname,english from stu;
** 去除重复的记录(要所有数据一样,所以不能有数据设置为primary key)
select distinct * from stu;

(2)别名操作
* 使用 as 别名的名称(只是暂时改为其他名字,如果再用select * from stu会回到原来的样子)(注意as放的位置)
** select sname as n1,english as e1 from stu;

* 练习
* 在所有学生分数上加10分特长分。
select chinese+10,english+10,math+10 from stu;
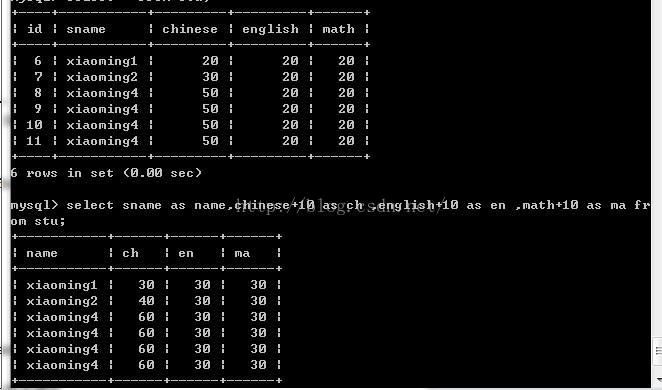
** 统计每个学生的总分。
select chinese+english+math as sum1 from stu;
** 查询姓名为熊二的学生成绩
select * from stu where sname='熊二';
** 查询英语成绩大于90分的同学
select * from stu where english>90;
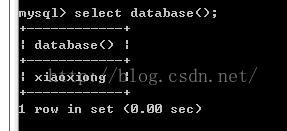
(3)显示当前的数据库 : select database();
(4)select语句里面where条件部分有关键字(取出指定值的数据)
* in:记录在里面值 ()
** 练习:查询数学分数为60,500的同学
select * from stu where math in(60,500);

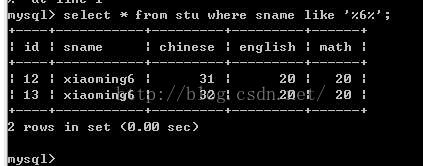
* like:用在模糊查询 (不要忘了引号)
** 练习:查询表里面名字里面包含熊的学生
select * from stu where sname like '%熊%';
* and:表示条件同时满足
** 练习:查询数学分>80和语文分>80的同学
select * from stu where math>80 and chinese>80;

* or: 表示或者
** 练习:查询数学分>80 或者 语文分>50的同学
select * from stu where math>80 or chinese>50;
(5)查询操作排序(默认是升序)
* 语句:order by 要排序的字段
* order by语句要写在select语句的最后
** 默认是升序的排序 order by 要排序的字段 asc(还有一种就是group by 要排序的字段)
** 设置降序排序 order by 要排序的字段 desc

** 练习:对数学成绩降序排序后输出。
select * from stu order by math desc;
8、sql语句中的聚集函数(count sum avg max min)
* 封装了一些固定的功能,可以在sql语句里面直接使用这个函数实现某些功能
* count函数:得到表中有多少条记录
** 语句 select count(*) from 表名 where....
** 练习:
* 统计一个班级共有多少学生?
select count(*) as count1 from stu;
** 统计数学成绩大于90的学生有多少个?
select count(*) from stu where math>500;
** 统计总分大于220的人数有多少?
select count(*) from stu where math+chinese+english>500;
* sum函数: 求和的操作
** 语句 select sum(要求和的字段) from 表名 where.....
** 练习:
* 统计一个班级数学总成绩?
select sum(math) from stu;
* 统计一个班级语文、英语、数学各科的总成绩
select sum(chinese),sum(english),sum(math) from stu;
* 统计一个班级语文成绩平均分
** 平均分:总成绩/总人数
select sum(chinese)/count(*) from stu;
* avg函数:计算平均数
** 语句 select avg(字段) from 表名 where....
** 练习:
* 求一个班级数学平均分?
select avg(math) from stu;
* 求一个班级总分平均分
select avg(math+chinese+english) from stu;
* max函数:计算最大值
* min函数:计算最小值
** 练习
*** 求班级数学最高分
select max(math) from stu;
select min(math) from stu;
9、sql语句的分组的操作
* 使用分组操作
** 语句 group by 要分组字段
* 创建一个orders 订单表
* insert into orders(id,product,price) values(1,'dianshi',900);
insert into orders(id,product,price) values(2,'xiyiji',100);
insert into orders(id,product,price) values(3,'shoudian',90);
insert into orders(id,product,price) values(4,'juezi',9);
insert into orders(id,product,price) values(5,'shoudian',90);
insert into orders(id,product,price) values(6,'dianshi',900);
insert into orders(id,product,price) values(7,'xiyiji',100);

(要显示什么项目就在select后面写什么!!!!)
** 练习:显示每一类商品的总价
*** 总价格 使用sum(price)
*** 每一类商品 group by product
select product,sum(price) from orders group by product;(这个orders是表名)

* having关键字
** 在分组的基础上再进行条件的判断
** group by product having sum(price)>100;
** where后面不能写聚集函数,但是having后面可以写聚集函数
** 练习:查询购买了几类商品,并且每类总价大于100的商品
** 这种写法从逻辑上没有问题的,但是where后面不能写聚集函数
select product,sum(price) from orders where sum(price)>100 group by product;
** select product,sum(price) from orders group by product having sum(price)>100;
10、sql语句里面关键字顺序(是否玩过火)
* select ... from ... where .... group by ... having .... order by...
** S-F-W-G-H-O 组合
==========================================================
1、对数据库表中的记录插入,修改,删除操作
2、对数据库表中记录的查询操作
11、mysql可视化工具的使用
* 通过cmd窗口,向表中插入中文记录,有乱码问题
** 解决方法:找到mysql的安装路径,找到一个文件my.ini
** 注意:如果要修改mysql里面的文件,首先备份
** default-character-set=gbk
* 可视化工具的使用
** 现在不建议使用这个工具,先通过cmd窗口把sql语句熟悉之后再使用这个工具
12、mysql里面limit关键字(不是标准sql的一部分)
** limit使用
** 首先可以写一个参数 limit 3:查询前三条记录
** 也可以写两个参数 limit 2,3 : 第一个参数开始位置,从0开始
第二个参数,从第一个参数位置开始向后取几条记录
* 查询数据库表中前几条记录
** select * from stu limit 2;
* 查询数据库表中的第几条到第几条记录(从当前位置开始算)
** select * from stu limit 1,2;
* 这个关键字一般用在分页功能里面
* limit关键字不是标准sql的一部分,只能在mysql里面使用,在其他数据库里面不能使用
** 在oracle里面:使用 rownum关键字
** 在sqlserver里面:使用top关键字
13、表之间的关系
* 一对多的关系
** 一个学生只能在一个学院,但是一个学院有多个学生
** 一个员工只能在一个部门,一个部门有多个员工
* 多对多的关系
** 一门课程可以被多个学生选择,一个学生也可以选择多门课程
* 一对一的关系
** 在中国,一个男人只能有一个妻子
一个女人只能有一个丈夫
** 一个公司只能有一个注册地址,一个注册地址包含一个公司
14、一对多建表原则
* 一个员工只能在一个部门,一个部门有多个员工
* 首先要确定一对多里面,谁是多的那一边,谁是一的那一边
* 其次在多的那一边创建一个字段,这个字段指向一的那一边的主键

15、多对多的建表原则
* 一门课程可以被多个学生选择,一个学生也可以选择多门课程
* 首先确定表之间的关系
* 其次创建第三张表,在创建两个字段,分别指向那两张表的主键
用第三张表作为两个表关系表

16、一对一建表原则
* 一个公司只能有一个注册地址,一个注册地址包含一个公司
* 在实际开发中,一般都把数据存到一张表里面

17、多表之间的查询的操作
* 创建一个部门表
create table dept (
did int,
dname varchar(40)
)
insert into dept values(101,'丐帮');
insert into dept values(102,'少林');
insert into dept values(103,'血刀门');
insert into dept values(104,'崆峒');
insert into dept values(105,'太极门');
insert into dept values(106,'宣武门');
* 创建一个员工表
create table employee1 (
eid int,
ename varchar(40),
did int
)
insert into employee1 values(2001,'乔峰',101);
insert into employee1 values(2002,'田伯光',102);
insert into employee1 values(2003,'二师兄',102);
insert into employee1 values(2004,'孙二娘',104);
insert into employee1 values(2005,'扈三娘',103);
insert into employee1 values(2006,'苗人凤',103);
insert into employee1 values(2007,'苗若兰',null);
insert into employee1 values(2008,'李寻欢',null);
* 查询员工对应的门派显示出来
select * from dept,employee1
* 得到结果是 笛卡尔积
(1)使用内连接进行操作
* 语法 inner join 表 on 两个表关联的条件
* 最终语句
select dept.*,employee1.* from dept inner join employee1 on dept.did=employee1.did;
* 使用内连接其实实现的是交集操作
* 还有另外一种方式,也可以实现类似于内连接的效果
select dept.*,employee1.* from dept,employee1 where dept.did=employee1.did;
(2)使用外连接进行操作
* 外连接有两种:
** 左外连接:left outer join 表 on 两个表关联的条件
select dept.*,employee1.* from dept left outer join employee1 on dept.did=employee1.did;
*** 左边的表里面的所有内容都显示出来,右边的表只是显示关联的内容
** 右外连接:right outer join 表 on 两个表关联的条件
select dept.*,employee1.* from dept right outer join employee1 on dept.did=employee1.did;
*** 效果;右边的表里面所有内容都显示出来,左边的表显示关联的内容
