Git:分布式框架原理
1.版本控制的分布式和集中式的区别:
CVS及SVN这些集中式的版本控制系统,而Git是分布式版本控制系统
1.1集中式版本控制系统
集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。如下图:

集中式的缺点:集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这还不得把人给憋死啊。
1.2分布式版本控制系统
分布式版本控制系统与集中式版本控制系统有何不同呢?
首先,分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
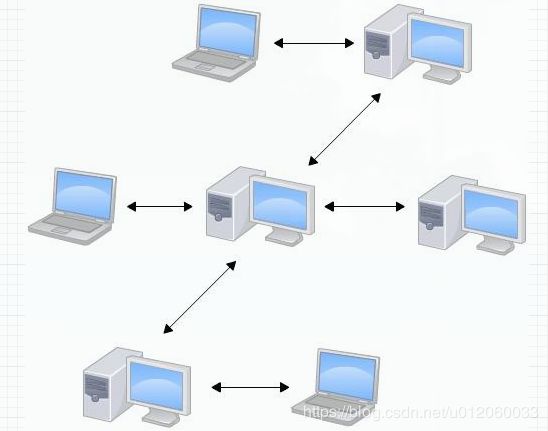
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
如图:
当然,Git的优势不单是不必联网这么简单,后面我们还会看到Git极其强大的分支管理,把SVN等远远抛在了后面。
2.Git工作原理
2.1Git分层操作
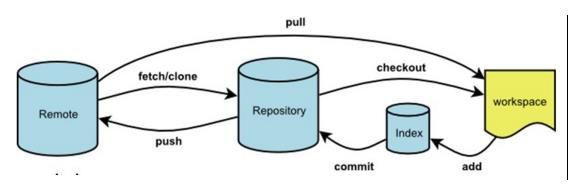
git的工作总共分四层,其中三层是在自己本地也就是说git仓库,包括了工作目录、暂存区和本地仓库。
工作目录(workspace)就是我们执行命令git init时所在的地方,也就是我们执行一切文件操作的地方;
暂存区(index)和本地仓库(repository)都是在.git目录下,因为它们只是用来存数据的。
远程仓库(remote)在中心服务器,也就是我们做好工作之后推送到远程仓库,或者从远程仓库更新下来最新代码到本地。
他们的关系如下:
Git所存储的都是一系列的文件快照,然后git 来跟踪这些文件快照,发现哪个文件快照有变化他就会提示你需要添加到暂存区或是提交到本地仓库来保证你的工作目录是干净的。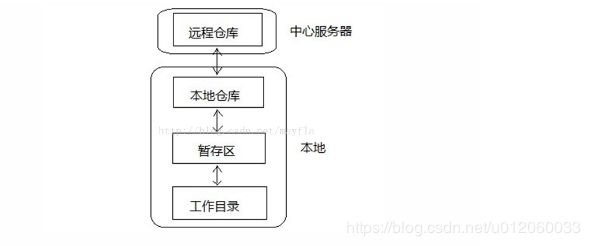
2.2git中的文件有两种状态
2.2.1一种是被跟踪的,也就是提交到本地仓库的文件,因为本地仓库要保管它们当然要跟踪他们,对他们负责,
2.2.2一种就是未被跟踪的,那么当我们添加新的文件时,他不是被跟踪的,因为本地仓库里面没有这个文件,他是外来的,本地仓库目前还不需要对他们负责。但是如果是对仓库已经存在的文件进行修改,那么这些文件就是被跟踪的文件,就可以通过git status查看他们的状态来进行相应的操作。当然我们也可以生成一个.gitignore文件,里面指定要忽略的文件类型,然后这些文件就不会被跟踪,不管怎么改变他们,git status都不会提示你需要做什么操作。
所以当我们在工作目录中进行文件操作后,要先添加到暂存区,然后再将暂存区中刚添加的文件快照提交到本地仓库,然后再将本地仓库的最新状态文件快照推送到远程仓库。这个文件快照其实就是各个文件在被添加到暂存区时的状态,就和照相的一样,留下每个不同时刻的快照,方便以后查询,而git存储的就是这些一系列的快照。说到这个快照就要说说git的对象了。
2.3Git对象
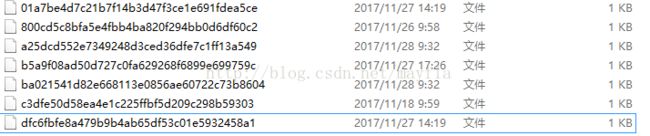
在.git-》Objects文件夹是一个个的git对象,是38位的哈希值,这样就意味着没有两个相同的对象名。
从根本上讲,git是一套内容寻址的文件系统,它存储的也是key-value键值对,然后根据key值来查找value的,说到寻址就会想到指针吧,不错,git也是根据指针来寻址的,这些指针就存储在git的对象中。Git一共有四种对象,commit对象,tree对象和blob对象和tag对象,这里可以理解tag是commit的别名,下面便是这三个对象: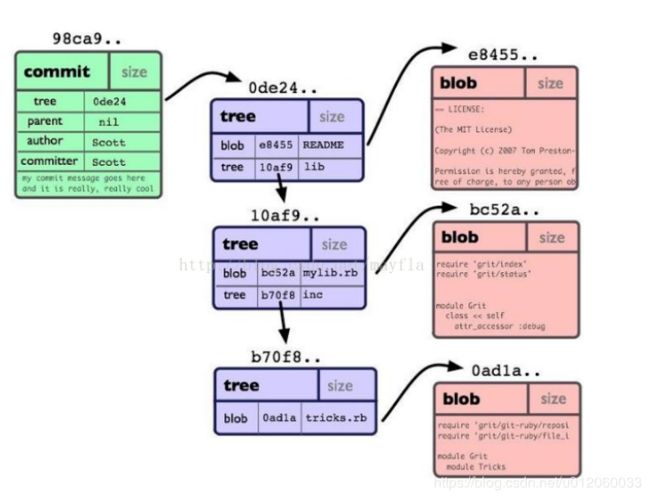
每个目录都创建了“tree”对象, 每个文件都创建了一个对应的“blob”对象。最后有一个“commit”对象来指向根“tree”对象,这样我们就可以追踪项目每一项提交内容。 这个blob对象对应的就是文件快照中那些发生变化的文件内容,而tree对象则记录了文件快照中各个目录和文件的结构关系,它指向了被跟踪的快照,
commit对象则记录了每次提交到本地仓库的文件快照,
从在开发过程中,我们会提交很多次文件快照,那么第一次提交的内容会用一个commit来记录,这个commit 没有指针指向上一个commit对象,因为没有上一个commit,他是第一个,当第二次提交时,又会有另外一个commit对象来记录,那么这次commit对象中就会有一个指针指向上一次提交后的commit对象,经过很多次提交后就会有很多的commit对象,它们组成了一个链表,当我们要恢复哪个版本的时候,只要找到这个commit对象就能恢复那个版本的文件。而我们所谓的HEAD对象其实就是指向最近一个提交的commit对象,也就是最后一个commit对象。
2.3.1查看对象
查看“blob”对象: git show + 对象名(SHA1哈希值)
查看“tree”对象: git show + 对象名 / git ls-tree + 对象名
查看“commit”对象:git show / git log + -s + --pretty=raw +对象名
查看“tag”对象: git cat-file tag v1.5.0
2.3.2git操作流程
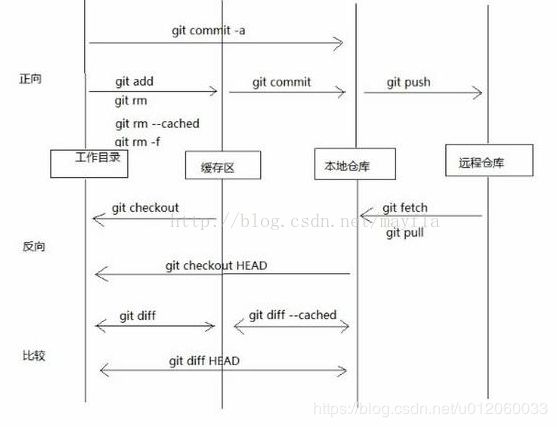
在目录间进行操作的是git命令,其中git rm -f是移除某一个受跟踪的文件。
总结:git就是一个版本控制系统,一般有svn经验的人,稍微学习一下git就可以操作了。